基于LSTM的电影评论情感分析研究
2021-03-17梁一鸣赵永翼
梁一鸣,申 莹,赵永翼
(1.沈阳师范大学软件学院,辽宁 沈阳 110034;2.沈阳市艺术幼儿师范学校,辽宁 沈阳 110000)
0 引言
互联网的迅速发展以及通信工具的兴起,导致网络用户的信息交互渠道大量增加。网络用户通过各种方式来表达自己对热点事件的观点,这使得在互联网上充斥着大批的由网民所参与的,对于事物、事件等有重大研究性的评论。但是这些观点以及评论信息大多数都基于个人的主观意见,因此,情感分析的主要目的就是研究如何可以提取与情感相关的信息。伴随着生活水平的逐渐提高以及群众对自己身心的放松,极大多数的人会选择在闲暇时间去观看一场自己喜欢的电影。然而,面对逐渐扩大的电影市场以及众多但质量参差不齐的电影,消费者们通常难以抉择,他们对影片的期望值越大往往失望值也越大,花钱看“烂片”的现象不在少数。因此,在选择电影之前,消费者们通常会关注已经看过该影片观众的评论,这些评论主要涉及到评论者对电影本身表达的情感信息,以及评论者对电影中的人物态度观点等。但是由于每个人的喜好不同,过度的自我观点会对其他消费者造成潜移默化的影响,极大地提高了对有价值信息的获取难度。所以快速并且有效地获取、处理这些电影的评论是极其重要的。
1 相关工作
情感分析又称作观点发掘,隶属于数据挖掘,因其当前的巨大数字量形式记录,文本情感分析的研究工作发展十分迅速。情感分析属于自然语言处理中的一个子领域,且通常是对携带主观性的文本进行处理,并且分析其中所包含的主观意见或者个人态度等。对于情感分析,国外研究起源较早,Riloff等通过构建了一些情感词典为之后的情感分析建立了良好的基础。国内对于情感分析也做了众多的研究,常晓龙等通过融合中文语义特点来构建中文的情感词典;梁军等人尝试使用机器学习的方法进行特征提取,在降低了人工成本的同时也极大地提高了准确率。群众对于各种热点事件有着各自的观点,对其进行情感分析可以有效解决所带来的问题,尤其当前的互联网环境当中充斥着大量的文本数据,对其进行情感分析是十分重要的工作。
2 Word2vec词向量
训练词向量的模型称作为 Word2vec(word to vector)。训练词向量的主要目的就是将词语从高维空间映射到低维空间当中,良好的词向量可以通过在词向量的空间里聚集语义近似词的方式来提高文本分类的效果。Word2vec依赖于 CBOW和Skip-gram两个模型来建立神经词嵌入,其两个模型是根据3层的神经网络语言模型 NNML的基础上提出来的。 CBOW主要是根据前后文来推测当前词,Skip-gram模型和 CBOW模型思路是相侼的,是通过当前的文本来推测前后文,但当两者的前后文相似的同时,目标词汇也是相似的。因 Skip-gram模型不利于大规模数据模型的训练,因此本文采用的是CBOW模型。 CBOW模型结构示意图如图 1所示。
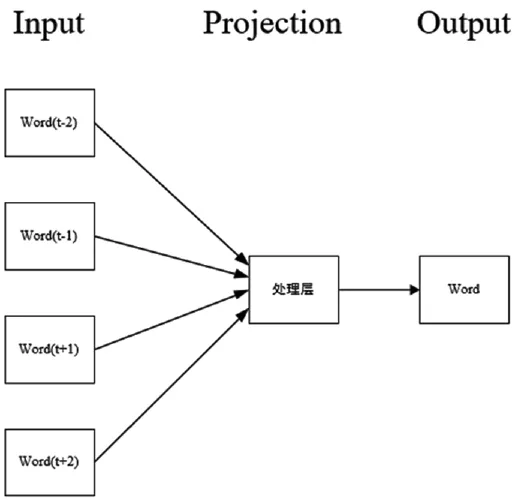
图1 CBOW模型结构示意图
3 长短时记忆神经网络
3.1 数据获取与预处理
在分析极性之前,通过对数据进行预处理可以去除掉对我们判别极性没有帮助的噪声。数据预处理是自然语言处理技术,数据预处理方法可以划分为数据清理、数据集成、数据变换以及数据规约。数据预处理主要将原始的文本数据进行清洗,再去除掉文本数据中的停用词,之后将文本进行分词并且转换成词序列,转换后的词序列转换成为数字序列并且将词的编号序列中每一个词表示成为词向量。信息抽取则是一个标注问题,主要是从文本数据当中使用提取算法来提取信息。
3.2 长短时记忆神经网络
LSTM(Long Short Term Memory)是长短期记忆网络,主要由三个门来控制,分别为遗忘门(Forget Gate)、输入门(Input Gate)以及输出门(Output Gate)。门(Gate)是一种可选的可以让信息通过的方式,LSTM三个门对记忆单元进行更新以及控制细胞的状态。遗忘门可以丢弃无用的信息,主要通过一个遗忘门层完成。遗忘门会读取前一时刻的输入单元 ht-1和当前的输入向量 xt,给每个前一时刻的细胞状态 Ct-1输出一个 0到1之间的数,其中,1代表的是完全保留,而 0代表的是完全舍弃。输入门在被遗忘部分之后,从当前的输入当中添加新记忆,当前的输入向量 xt、前一时刻的细胞状态Ct-1和前一时刻的输入单元 ht-1决定了当前的细胞状态Ct。输出门通过计算后得到一个新的细胞状态Ct,且当前的细胞状态 Ct和前一时刻的输入单元 ht-1以及当前输入向量 xt决定了当前单元的输出 ht。 LSTM单元结构示意图如图 2所示。

图2 LSTM单元结构示意图
LSTM在实践中存在着大量的变动,GERS提出了增加了“peephole connection”,让门也接受当前状态的输入。LSTM单元的计算公式如下:

式中,Ct为前一时刻的细胞状态;ft为遗忘门,用于来决定哪儿些信息要增加到LSTM的记忆细胞状态;it为输入门,用于来决定哪儿些信息从LSTM的记忆细胞状态删掉;ot为输出门,用于来决定哪儿些信息从LSTM的记忆细胞状态输出;Wf、Wi、Wo为各自的链接;bf、bi、bo为各自输入链接的权重。
4 实验与分析
4.1 数据集资源
本文采用了大规模的电影评论数据集IMDB,该电影评论数据集 IMDB中包含了 5万条电影评论。将 5万条电影评论平等地划分为训练数据以及测试数据,表 1统计了训练数据以及测试数据的划分分布。将其划分为“positive”和“negative”两个标准,表 2展示出了“positive”和“negative”两个标准的数据集样例。因将中性评论去掉,所以划分的准确率为一半。

表1 训练数据以及测试数据统计结果

表2 数据集样例
4.2 实验结果与分析
本文使用了Keras,通过Word 2vec将词语转换成为词向量并进行特征提取之后,再将提取到的特征添加到LSTM的模型当中,其输出是经过Softmax层计算得到的。将 IMDB划分为训练数据以及测试数据,然后把训练数据分批次输入到模型中,再将训练好的模型以及参数保存下来并且输入到已经完成训练的模型当中,得到准确率。准确率如图3所示。
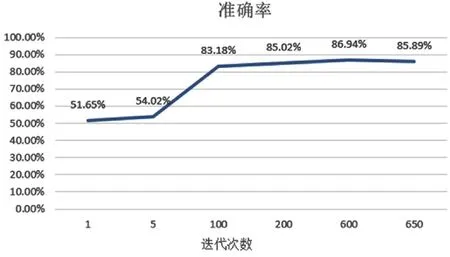
图3 模型准确率
由图3可知,模型的准确率随着迭代次数增长而增长,在达到最高点 86.94%之后开始下降。本文使用同一个数据集,与不同的模型进行实验对比,实验结果如表 3所示。

表3 实验结果对比
由表3可知,LSTM模型实验效果较好。
5 结束语
本文通过基于 LSTM模型对电影评论文本实行情感分析,通过实验结果我们发现,LSTM模型在对电影评论文本的情感分析中的可行性以及有效性,望之后可以进一步研究如何构建更为复杂的模型对情感进行分析。
