基于嵌入式视频流的口罩佩戴检测仪
2021-03-17刘紫馨
刘紫馨
(中国传媒大学信息与通信工程学院,北京 100024)
0 引言
2020年初,“新冠”疫情爆发,为有效阻止疫情的传播与蔓延,国家卫生健康委规定大家日常出行均须佩戴口罩。疫情初期,市民自觉佩戴口罩的意识较弱,曾多次出现人员聚集性感染现象。随着秋冬季节的来临,以及防止境外病例输入带来的影响,在人流密度较大的公共场所,均应设有工作人员对行人进行体温检测以及口罩佩戴的监督提醒工作。由于人工检测存在人力资源浪费、效率低下等问题,可以使用口罩佩戴识别技术,自动识别行人的口罩佩戴情况,实现高效无接触式检测。
口罩佩戴识别技术是由基于特征融合和分割监督的目标检测以及口罩属性类别识别两大模块组成的。目标检测是神经网络中较为重要的一门领域,卷积网络本身具有的权值共享的特点可以降低时间复杂度,提高识别速度。
现阶段深度学习的主要实现方式是在 GPU平台上完成,由于 GPU具有高带宽以及高效率的浮点运算单元等特点,通常被用于进行卷积神经网络的分类和训练。但在实际应用中,仍然面临着高端 GPU价格昂贵、体积巨大、位置固定且仅能在服务器上安装等问题,极大地限制了算法的应用场景;而嵌入式平台体积较小,可拓展性强,部署方便,可接入平台多,具有良好的硬件适应性,方便移植,可以针对特定应用灵活设计。
1 系统整体方案
本文设计的口罩佩戴检测仪可以实现对行人是否佩戴口罩的实时检测,具有实时性、便携性、可拓展性强、识别准确度高等特点。系统前端采用深度相机进行视频流的采集,同时选择嵌入式设备作为硬件平台,并在此基础上搭载卷积神经网络作为基础核心算法,是基于深度学习对图像图形的处理方式和方法。
本系统的工作流程为:由前端摄像头采集目标对象视频流,接着由 Open CV算法对视频流进行处理,并将处理后的图片帧输入到网络中进行识 别,当返回的识别结果显示有人未佩戴口罩时,系统将作出警报、禁止通行等反应。
在研究过程中对目标对象的检测和定位的相关技术进行分析,合理选择适合于口罩佩戴识别系统的算法框架。针对现有开源数据集存在的问题进行修正补充,创建新的数据集,对数据集进行训练,并对训练所得模型进行相关的性能评估。考虑到GPU体积巨大、位置固定、不易移动等问题,选择适宜的嵌入式平台对算法进行移植。
本文将研究并实现基于嵌入式系统的口罩佩戴识别系统,选择卷积神经网络作为核心理论算法。对算法的基本原理进行分析,构建口罩佩戴检测数据集,在初始算法的基础上进行修改优化,并将算法移植于嵌入式系统中来解决应用场景受限等问题。
2 系统设计
2.1 硬件平台介绍
现阶段深度学习的主要实现方式以 GPU为主,口罩佩戴识别系统往往应用于人流量密度较大的公共场所,而传统主机由于存在体积大、移动不方便等缺点,极大地限制了算法的应用场景。而嵌入式平台体积小、扩展性强、便于部署,可以实现并行计算的需要,更加满足对系统的整体要求。
在本次研究中嵌入式平台的作用是完成处理视觉系统采集到的图片,并输出检测结果的任务,其中嵌入式平台的 CPU和GPU性能将极大地决定主机的图像处理性能。考虑到口罩佩戴识别系统需要对输入的图片或视频进行实时的检测和反馈,所以选择在 NVDIA Jetson TX2平台上实现。
NVDIA Jetson TX2是一台基于 NVIDIA Pascal架构嵌入式设备,模型外形小巧,节能高效,长宽87 mm×50 mm,其功耗也仅约为 7.5 W,在大多数场合下都可以实现超长的待机,适用于对带宽和延迟要求高的应用的实时处理过程。 Jetson TX2平台在此基础上具有强大的计算能力,在处理 720 p彩色图像时的每秒帧数可达 30帧以上。
由于口罩佩戴识别系统主要应用于视频目标检测,TX2额外提供的高级高清视频编码器和 1.4 Gpix/s的高级图像信号处理器,可以通过硬件加速静止图像和视频捕获路径,更有利于对动态目标的检测。
2.2 算法选择
由于口罩佩戴识别系统对检测的实时性要求较高,因此处理速度快,计算精度准是在选择合理的算法框架时主要的评价指标。现阶段基于深度学习技术的目标检测算法分为两类:一类是双阶段目标检测算法,另一类是单阶段目标检测算法。其中,双阶段目标检测算法在对特征进行提取的基础上,需要有额外的网络产生候选区域来确定目标所在的具体位置,处理时间较长,不满足对实时性检测的要求,而单阶段目标检测算法则可以在产生候选区域的同时进行分类和回归。所以在本次研究中选用单阶段目标检测算法。
本系统采用的 YOLOv3是一种以 Darknet-53结构为基础的网络,通过 FPN(Feature Pyramid Network)进行多尺度特征融合的端到端目标检测方法。其中,Darknet-53结构是用来对输入图像进行特征提取的,Darknet网络由 C语言实现,没有依赖项,容易安装,便于移植,十分适合在嵌入式系统中使用。
目标检测需要完成目标识别和目标定位两个任务,为了评价预测的准确程度,YOLOv3的损失函数包括置信度损失函数,中心坐标损失函数,宽高大小损失函数和类别损失函数。
3 模型训练结果与分析
3.1 模型训练
初始的口罩佩戴识别数据集来自于网络爬虫,共6,120张图片。通过对人脸口罩佩戴照片的观察发现,围巾、头纱、手等对于面部的遮挡情况和口罩类似,图片所处环境的光照和明暗变化都容易对预测结果产生相应的干扰,所以额外添加 1,000张图片针对遮挡和光照情况对现有的开源数据集进行相应的补充,累计共 7,120张图片。利用图片标注工具对图片进行标注,利用矩形框将人脸标出,并标注类别:wear(佩戴口罩)、 unwear(未佩戴口罩)。将数据集图片拷贝到 JPEG Images目录下,将标注好的数据集拷贝到 Annotations目录下。
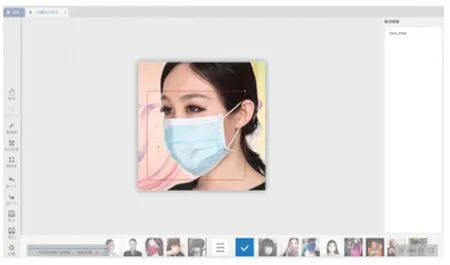
图1 标注图片
在数据集中随机选取 90%(6,408张)的图片作为训练集,10%(712张)的图片作为测试集,生成 train.txt,val.txt,est.txt,trainval.txt共4个文件。训练时安装并编译 darknet源码,并加入已创建好的数据集进行训练。训练设置如下:学习率设置为 0.001,动因子设置为 0.9,重衰减正则系数设置为0.0005。
3.2 识别结果
在19,000次迭代后,损失值基本保持稳定。使用20,000次迭代后的权重文件在测试集上进行测试。使用 TP表示正确检测到是否佩戴口罩的人数,FP表示错误检测是否佩戴口罩的人数,FN表示漏检测行人的人数。引入准确率和召回率来对检测结果进行评价,其中准确率用于评估预测的准确程度,召回率用于评估预测的全面程度。

图2 识别结果
对于准确率 Precision与召回值 Recall的定义如下所示:

最终可以得出检测准确率为 96.4%,召回率为95.8%,识别准确度较高,基本满足对口罩佩戴的识别要求。
3.3 分析
在对原始数据集进行相应的处理和补充后,通过与初始数据集的测试结果进行比对,有面部遮挡的易混淆图片的检测准确率有了明显提高,对于照明环境较差,面部光线较暗的图片在召回率上也有了明显改善。
在TX2平台上进行训练,检测精度与在传统主机上的结果近似,能够满足在不损失精度的基础上实现便携式口罩佩戴识别系统的要求。同时实验结果证明,在TX2平台上的运行效率高于在传统主机上的运行效率,能够实现高效率高精度的佩戴检测结果。而对于视频内容的识别,也能够更好地进行动态捕捉,适用于在人流量密度较大的公共场所进行快速准确的人脸口罩佩戴识别。
4 结束语
本文通过设计一款针对口罩进行检测的系统,前期在对现有数据集的处理和补充后,改善了系统对于面部遮挡以及光线变化下的口罩佩戴识别的检测效果。在算法上对 YOLOv3卷积神经网络进行改进,在 TX2平台上对修改后的数据集进行训练,最终在检测任务上取得了较为理想的检测效果,说明此方法具有一定的实用价值。但是同时发现当处于复杂场景下,若同时出现多个目标且目标面积较小时,检测的效果较差。未来将针对该场景进行下一步的改进,提升检测精度。
