面向电力信息系统日志数据的注入攻击特征提取方法
2021-03-16朱静雯
殷 博 朱静雯 刘 磊 许 静
1(国网天津市电力公司 天津 300010)
2(南开大学软件学院 天津 300350)
3(南开大学人工智能学院 天津 300350)
0 引 言
随着电力信息系统接入互联网,电力信息网络安全变得越来越重要。近年来我国电力行业信息系统发展迅速,与多种业务系统智能互联,如用户用电业务系统、充电桩业务系统等。电力业务相关数据不断积累,提高电网信息系统面对外界恶意攻击时的防控能力对保证电网安全、稳定、高效运行非常重要。在Web应用的所有安全问题中,SQL注入是危害严重且影响范围较广的重要问题之一,据OWASP[1]和CVE[2]统计,近几年SQL注入攻击(SQL-Injection Attacks,SQLIA)在十大Web安全隐患中稳居第一,而且SQL注入在所有被报告的安全漏洞中也是频率增长最快的类型。与传统Web相比,电力信息Web系统具有规模大、业务逻辑实时多样、专用性强等特点,这也导致了针对电力信息Web系统SQL注入攻击的检测难度大。其实现过程中容易产生大量漏洞,并且对此进行的攻击事件越来越多且难以辨别,因而对于电力信息Web系统SQL注入攻击检测技术的研究十分必要。基于Web信息系统访问日志挖掘用户访问行为的研究日益增多,文献[3-5]均是对用户访问日志进行分析,用于检测分布式拒绝服务攻击(DDOS)以及Web爬虫行为。
本文提出一种面向电力信息系统日志数据的注入攻击特征提取方法。首先,分析Web访问日志和SQL注入特征,提出一种从自定义Web访问日志中提取SQL注入语法特征和行为特征的方法;其次,对日志进行预处理和特征提取操作,得到语法特征矩阵和行为特征矩阵;最后,在两类特征数据集的基础上使用4种算法模型进行实验。结果表明,将SQL注入攻击的检测与语法特征和行为特征相结合的方式,可以有效检测SQL注入攻击。使用该方法,电力信息Web系统安全管理员能够及时发现系统的恶意访问用户,从而提前采取防范措施、避免损失。
1 相关工作
针对Web系统的漏洞挖掘技术,国内高校、研究机构和企业积极开展相关技术研究[6-7]。国内外现有的漏洞利用工具,如绿盟推出的Web应用漏洞扫描系统、开源渗透测试框架Metasploit Framework(MSF)等虽各有所长,但是并没有与电力信息Web系统多场景的特点相结合。
目前对SQLIA的检测主要有基于规则匹配[6]和基于查询语法树[7]的方法。韩宸望等[8]将基于SQL语法树比较的安全策略引入用户输入过滤的设计中,提出了一种新的SQL注入过滤方法,该方法能够有效防止SQLIA,并有较高的拦截率和较低的误报率。王苗苗等[9]对大量SQL注入攻击报文的攻击特征进行总结分析,提出了一种基于通用规则的SQL注入攻击检测与防御的方法,利用SQL注入检测工具SQLMap进行SQL注入攻击模拟,捕捉攻击流量,提取攻击特征,总结通用规则。Kim等[10]提出一种基于内部查询树和SVM的SQLIA检测方法,该方法从数据库级别的日志中收集SQL查询树信息,从复杂和多变的查询树中提取语法特征和语义特征,但是在实现和操作上比较复杂。张志超等[11]提出一种基于人工神经元网络的SQL注入漏洞的分析模型,在识别SQL关键字注入攻击特点的基础上,利用人工神经元网络算法对SQL注入语句进行检测,能够直接分析SQL语句,判断用户输入的SQL语句是否为SQL注入的语句,该模型可提高SQL注入漏洞检测的准确率和执行效率。Singh等[12]提出了一种算法,不仅可以检测SQL注入攻击,而且可以通过机器学习技术,维护审计记录检测未授权用户的访问。
基于规则匹配的方法能够很好地检测出规则库中已知的SQLIA类型,准确率高,误报率小。但该方法过度依赖于规则知识库,不能检测出未知攻击,漏报率高,而当前的SQLIA手段总是在不断更新和变化。基于查询语法树通过比对安全的查询语句语法树和待测语句的语法树,若两个语法树不同,则该查询语句为SQL注入攻击。但该方法漏报率和误报率都比较高,并且也不能检测出未知SQL注入攻击。
电力信息系统规模庞大,对安全性要求较高,目前面向电力信息Web系统特点的SQL注入攻击检测方法的研究较少。为了提高电力信息Web系统的安全性,防止用户通过输入提交恶意SQL语句制造SQL注入攻击,本文提出一种面向电力信息系统日志数据的注入攻击特征提取方法,提高对SQL注入攻击检测的准确性。
2 SQL注入特征提取
首先对用户访问Web系统产生的日志数据进行解码、分析等预处理操作。然后从日志文件中提取语法特征字段以及行为特征字段。由于SQL注入攻击包含一系列Web访问动作,因此提取行为特征字段之前还需要进行用户识别和会话识别,再对提取的特征字段进行类别标注,形成特征字段训练集以及测试集。最后使用分类/聚类算法进行训练建模。本文提出的方法架构如图1所示。
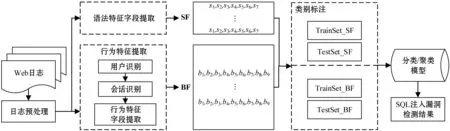
图1 本文方法架构
2.1 自定义Web访问日志
服务器默认的日志字段中记录了用户访问的URL,通过URL字段中的用户输入信息判断是否为恶意输入。然而只能记录GET请求类型的参数,无法记录POST类型的参数以及HTTP HEADER的注入信息。因此若使用服务器默认的日志分析SQL注入攻击行为,则会导致大量攻击无法检测,进而导致漏报率高,无法达到防御攻击的目的。由于Apache服务器日志中包含许多与研究目标无关的记录和字段,这些信息不需要记录在内。此外,为了提高日志处理效率,本文自定义了Web访问日志的格式,根据研究目标,确定6个日志字段信息,日志以文本文件的格式保存在服务器端。日志各字段及含义如表1所示。

表1 日志字段及含义
Time记录服务器完成请求处理时的时间,IPAddr表示访问用户的IP地址,RemoteHost记录用户访问的主机名,UserAgent记录用户操作系统和浏览器信息,以上4个字段用于确定SQL注入行为特征。IPAddr、RemoteHost和UserAgent字段可以进行用户识别,之后根据访问时间进行会话识别。
ReqMethod字段表示用户发送请求使用的方法,主要有get、post、head和put方法,其中get和post方法最为常用。
InputPara记录用户请求的输入参数。SQL注入攻击就是由于不安全的用户输入导致的。通过InputPara可初步判断用户输入数据的安全性。SQL注入语法特征的提取主要是从InputPara字段获得。
2.2 语法特征提取
SQL注入攻击发生时输入的参数在语法方面具有共同特征,都是将输入参数直接拼接到SQL语句中,从而改变SQL语句功能,窃取数据。根据SQL注入攻击参数的一般形式和语法特征,可将SQL注入攻击参数分为7部分,每个字段拥有相应功能并完成相应的注入目的。按照在SQL注入语句中出现的顺序,7个字段分别为:(1) 前终结符,用PreTerm表示;(2) 注入前缀,用InjecPrefix表示;(3) 注入关键词,用InjecKey表示;(4) 常量参数,用ConstPar表示;(5) 大写字母,用UpLet表示;(6) 其他特殊字符,用SpecLet表示;(7) 后终结符,用SufTerm表示。SQL注入语法特征字段含义及实例说明如表2所示。

表2 SQL注入语法特征字段
图2所示为生成语法特征矩阵的工作流程。图2(a)为SQL注入语句的提取流程,其中日志文件为经过解码处理后得到的日志文件,这是由于服务器记录的用户访问日志的输入参数字段是经过编码的字符串,所以首先需要对日志的输入参数字段进行解码等预处理。经过解码处理后,对每条日志进行分析,判断其是否符合SQL注入特征。对于符合SQL注入特征的语句提取形成SQL注入语句文件,然后根据提取结果,在字段分析时采取分支结构判断SQL语句中是否有符合上述7个字段的字符,如图2(b)所示。每个字段的值均为BOOL类型,0值表示该条日志记录不包含此字段,1值表示该条日志记录包含此字段。对所有的日志记录处理之后,形成大小为n×7的矩阵,其中n为日志记录个数,7为每条日志记录的特征字段个数。由此得到SQL注入语法特征矩阵。
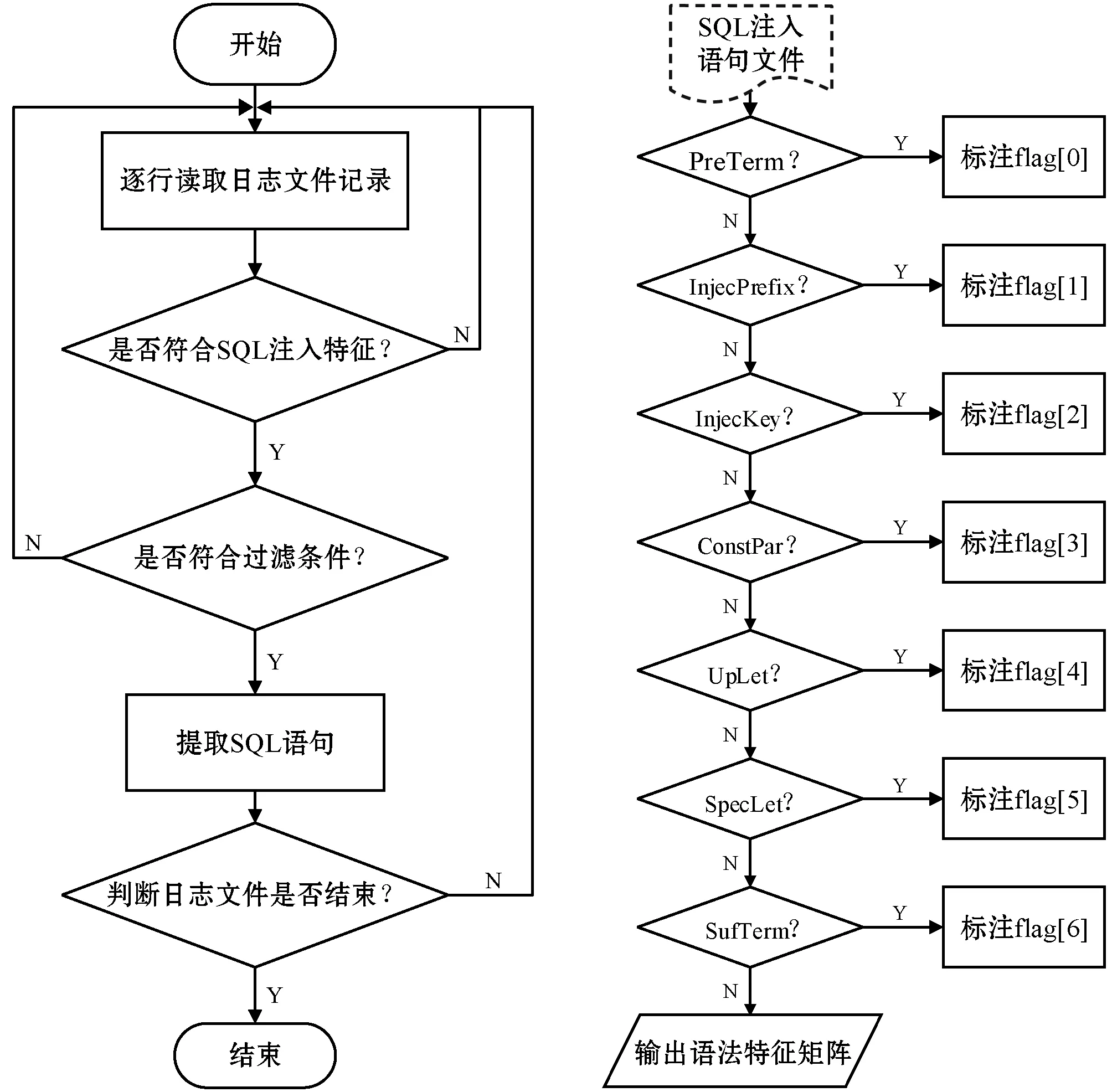
(a) SQL注入语句提取流程 (b) 语法特征矩阵生成流程
2.3 行为特征提取
SQL注入攻击是逐步尝试进行完成,包含一系列Web访问动作。若只考虑每条日志的SQL注入语法特征,在标注标准严格的情况下,偶尔一次的输入错误当作攻击行为,会出现误报;反之,容易出现漏报。SQL注入攻击步骤如图3所示。
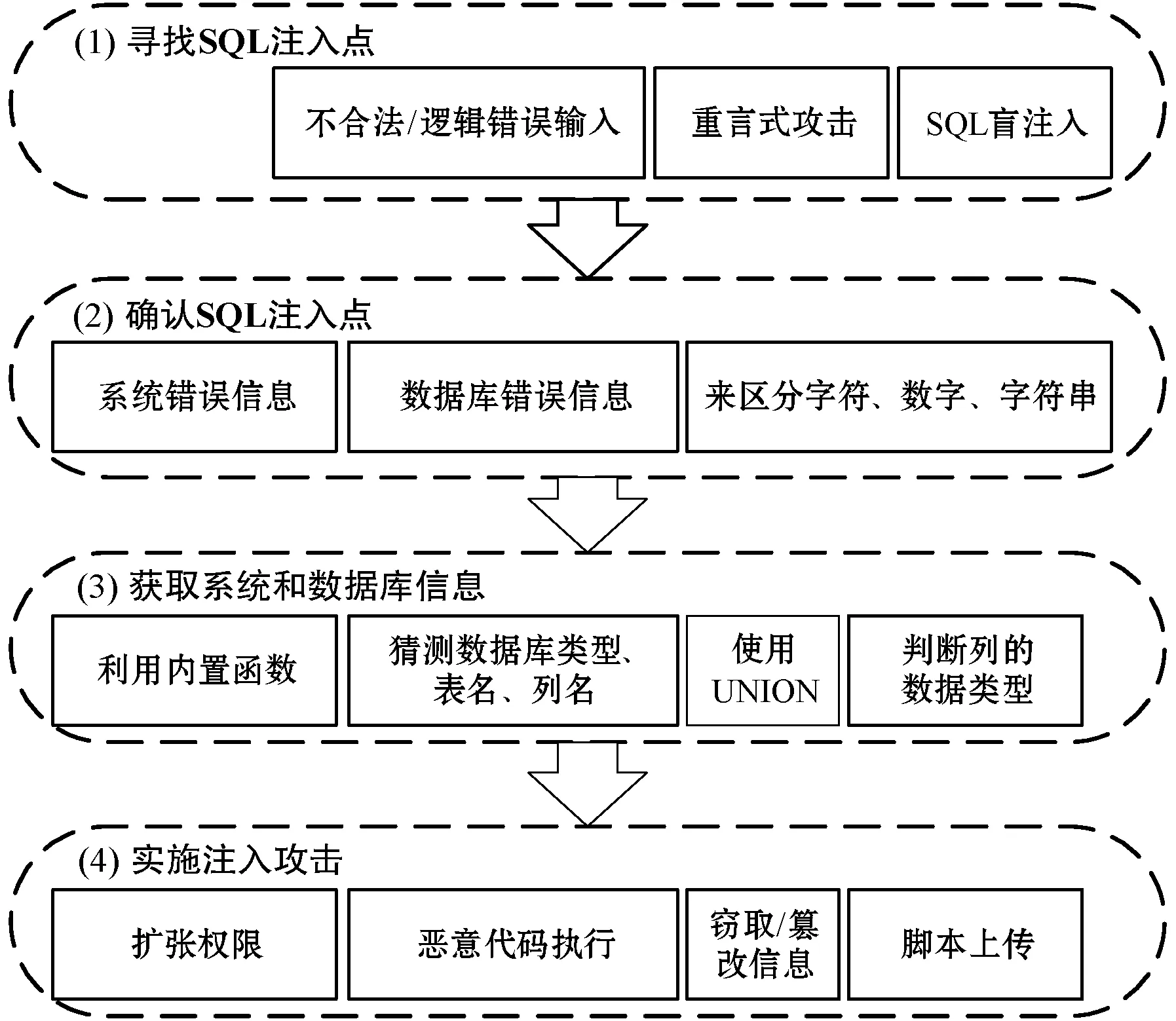
图3 SQL注入攻击步骤
(1) 寻找SQL注入点。在动态网页输入参数的位置,通过不合法或逻辑错误的输入、推断攻击、重言式攻击和SQL盲注入的方式判断是否存在SQL注入。
(2) 确认SQL注入点。在找到SQL注入点后,还需进一步确认SQL注入点的真实性和注入类型。一般需要多次尝试,根据系统错误信息和数据库错误信息来区分是字符、数字还是字符串类型的注入。
(3) 获取系统和数据库信息。由于不同数据库具体的注入方式不同,所以还需要进一步获取系统和数据库相关信息。该过程可以使用UNION联合查询、多语句命令执行,利用内置函数实现,猜测数据库的类型、表名、列名、判断列的数据类型等。
(4) 实施注入攻击。在确定数据库信息之后,利用SQL注入漏洞进行真正的攻击,包括扩张权限、窃取/篡改信息、恶意代码执行、脚本上传等。
SQL注入攻击特征不仅体现在SQL语句的语法特征上,在用户访问行为上同样具有异于正常访问行为的特征。例如用户在同一个会话内重复多次请求同一个网页、在一定的时间内发生大量的会话等。因此,分析SQL注入行为特征时,也需要进行用户识别和会话识别。
本文根据Web访问日志的IPAddr、RemoteHost和UserAgent字段进行用户识别。如果两条Web访问日志记录的IPAddr、RemoteHost和UserAgent三个字段对应相等,则认为这两条日志属于同一用户的操作记录,否则属于不同用户。
设置会话持续时间阈值T,把T时间段内的访问记录作为一个会话,本文使用启发式方法动态确定阈值,以自适应的阈值识别会话。设最大请求数Rmax,如果当前会话的请求数小于Rmax,设置阈值为T1;如果请求数达到Rmax,设置阈值为T2,T2>T1。在实验中,Rmax取值为100,T1为30分钟,T2为60分钟。会话识别中,每个会话中有多个日志访问记录,定义每个会话中含有的记录数目称为该会话的长度,用len_session表示。SQL注入行为特征字段如图4所示。

图4 SQL注入行为特征字段
各字段含义如下:
(1) PPT(Percentage of PreTerm):含有前终结符的记录数目与会话长度的比例,即PPT=npt/len_session,npt为该会话中含有前终结符的记录数目。
(2) PIP(Percentage of InjecPrefix):含有注入前缀的记录数目与会话长度的比例,即PIP=nip/len_session,nip为该会话中含有注入前缀的记录数目。
(3) PIK(Percentage of InjecKey):含有注入关键词的记录数目与会话长度的比例,即PIK=nik/len_session,nik为该会话中含有注入关键词的记录数目。
(4) PCP(Percentage of ConstPar):含有常量参数的记录数目与会话长度的比例,即PCP=ncp/len_session,ncp为该会话中含有常量参数的记录数目。
(5) PUL(Percentage of UpLet):含有大写字母的记录数目与会话长度的比例,即PUL=nul/len_session,nul为该会话中含有大写字母的记录数目。
(6) PSL(Percentage of SpecLet):含有其他特殊字符的记录数目与会话长度的比例,即PSL=nsl/len_session,nsl为该会话中含有其他特殊字符的记录数目。
(7) PST(Percentage of SufTerm):含有后终结符的记录数目与会话长度的比例,即PSE=nst/len_session,nst为该会话中含有后终结符的记录数目。
(8) PRT(Percentage of Max Request Times):请求次数最多的页面被请求的次数与会话长度的比例,即PRT=nrt/len_session,nrt为该会话中被请求次数最多的页面被请求的次数。
(9) DT(Duration Time):会话的持续时间,即会话最后一条记录的时间与第一条记录的时间差。
日志预处理、用户识别和会话识别后进行行为特征字段提取,提取每个会话中的上述9个特征字段值,每个字段值的范围是0~1。对所有会话记录进行SQL注入行为特征提取之后,形成大小为n×9的矩阵,其中n为会话记录的个数,9为每个会话的特征字段个数。由此得到SQL注入行为特征矩阵。
3 实 验
3.1 实验对象
通过分析电力信息系统特点,本文搭建相应的Web应用系统,并将其部署于模拟电力信息系统的实验环境中。在系统源代码中人工添加GET、POST、HTTP Cookie、HTTP Referer和HTTP Header “X-Forwarded-For”5大种类共计13个SQL注入漏洞,如表3所示。

表3 Web系统SQL注入漏洞列表
针对SQL注入攻击的需求,本文在模拟实验环境中部署的Web系统上增加了相应的SQL注入漏洞入口。采用多用户以及SQL注入工具的方式进行多次正常访问和尝试攻击,记录下用户访问日志,其中部分日志InputPara信息如下:
controller=site&action=pro_list&cat=57
controller=site&action=pro_list&cat=
57 and(select count(1) from sysobjects)>0 And 1=1
controller=site&action=pro_list&cat=
57 and len(@@version)>0 And 1=1
controller=site&action=pro_list&cat=
57 and(select count(table_name) from user_tables)>0 And 1=1
controller=site&action=pro_list&cat=
57 and 1=1-- And 1=1
controller=site&action=pro_list&cat=
57 and 1=1/* And 1=1
controller=site&action=pro_list&cat=
57 and 0<=(select count(*) from master..syslogins) And 1=1
对Web访问日志进行去除无效访问日志、解码等预处理操作步骤,然后进行特征提取,形成语法特征(Syntactic Feature,SF)矩阵与行为特征(Behavioral Feature,BF)矩阵两类实验数据集。SQL注入攻击数与正常访问日志数比例如图5所示,其中TrainSet为训练集,TestSet为测试集。

图5 SQL注入攻击数与正常访问日志数比例
3.2 评估指标
在入侵、攻击检测等研究中,常用漏报率和误报率评价检测方法的有效性[10,13]。漏报率即没有检测出来的攻击记录数与总攻击记录数的比例,用FNR(False Negative Rate)表示;误报率即被检测出来是攻击但实际上是正常的记录数与总的正常记录数的比例,用FPR(False Positive Rate)表示。本文使用FNR和FPR评估检测算法的有效性,通常具有较低漏报率和误报率的模型检测效果较好。误报率和漏报率的计算分别如下:
FPR=FP/(FP+TN)
(1)
FNR=FN/(TP+FN)
(2)
式中:FP表示实际是正常的日志记录,但检测结果是SQLIA的日志记录个数;TN表示实际与检测结果均是正常的访问日志记录;FN表示没有检测出来的SQLIA日志记录个数;TP表示实际与检测结果均是SQLIA的访问日志记录数目。
3.3 实验结果
实验平台为Windows 7,系统内存4 GB,CPU为Core i3,使用Firefox浏览器,在模拟电力信息系统实验环境下运行Web应用。
使用K-means、朴素贝叶斯(Naive Bayes)、支持向量机(Support Vector Machine, SVM)和随机森林(Random Forest,RF)算法分别对SQL注入语法特征矩阵和行为特征矩阵建模和预测,计算FPR和FNR。使用这两种特征矩阵目的是评估语法特征和行为特征在SQL注入攻击检测中的效果。
另外,对SQL注入语法特征的每个样本类型进行重新标注设计一组对比实验。进行重新标注是因为语法特征是以每个日志作为一个样本,单独从每个日志的语法特征分析该样本是否是攻击往往具有一定的偏差。标注标准严格会导致误报,标准宽松则会导致漏报。而行为特征是以用户的一次会话作为一个样本,其标注一般不存在此问题。因此,为了增加实验结果的充分性,本文考虑对语法特征进行重新标注。
首先将两类实验数据训练集TrainSet_SF(340条SQLIA记录,25 040条正常访问记录)和TrainSet_BF(260条SQLIA记录,1 590条正常访问记录)分别代入上述4种算法模型进行训练,并不断调整参数选出效果更优的训练模型,采用十折交叉验证方法对模型进行综合验证评价。然后将TestSet1_SF(290条SQLIA记录,1 470条正常访问记录)、TestSet2_SF(130条SQLIA记录,20 380条正常访问记录)和TestSet1_BF(110条SQLIA记录,120条正常访问记录)、 TestSet2_BF(130条SQLIA记录,990条正常访问记录)代入4种训练模型进行预测。上述模型对SQL注入攻击检测结果的漏报率和误报率如表4所示。按照同样的实验过程对重新标注后的语法特征数据集SF进行实验,漏报率和误报率结果如表5所示。其中TestSet1_SFR和TestSet2_SFR分别表示重新标注后SF的两个测试集。

表4 各模型在SQL注入语法特征和行为特征数据集的预测结果 %

表5 SQL注入语法特征数据集重新标注前后预测结果对比 %
3.4 实验结果分析
(1) SQL注入语法特征和行为特征对漏报率FNR的影响。图6为各模型在语法特征测试集和行为特征测试集上检测结果的漏报率。可以看出,每个模型在语法特征数据集和行为特征数据集上的检测结果的漏报率差距明显,使用SQL注入行为特征数据集进行SQL注入攻击检测,可以有效降低漏报率。

图6 各模型在SF和BF上的FNR结果
(2) SQL注入语法特征和行为特征对误报率FPR的影响。图7为各模型在语法特征测试集和行为特征测试集上检测结果的误报率。可以看出,每个模型在语法特征数据集和行为特征数据集上的检测结果的误报率差距不是特别明显,多数模型在行为特征数据集上测试结果的误报率略高于在语法特征数据集上的结果。这是由于语法特征数据集在标注时标准不太严格,导致漏报率较高,但是误报率低。

图7 各模型在SF和BF上的FPR结果
综合考虑FNR和FPR两个因素,行为特征在SQL注入攻击检测中具有更好的效果。
(3) 各模型检测效果分析。本文实验数据的特点是小数据量和低维度。通过比较各模型在数据集上的分类效果,K-means无监督聚类相比其他分类算法,FNR和FPR偏高。Naive Bayes适合属性相互独立的数据集,在本实验中的结果比SVM、RF稍差。RF适合较高维度和大数据量的数据集,SVM适合小样本和高维数据,在本文实验中的检测结果相差不大,均能得到可以接受的分类结果。
(4) 数据集规模以及攻击样本所占比例对实验结果的影响。实验中TestSet1和TestSet2在数据集规模和攻击样本所占比例上都有很大差异。TestSet1是攻击样本比例高的规模较小的数据集;TestSet2是攻击样本比例低的规模较大的数据集,更符合真实环境中用户访问日志情况。可以看出,在TestSet2数据集下的预测结果更为稳定,预测结果更加准确。
(5) 语法特征数据集的标注与否对SQL注入攻击检测漏报率FNR和误报率FPR的影响。图8、图9分别为各模型在语法特征数据集重新标注前后FNR、FPR的实验结果。可以看出,语法特征数据集样本重新标注后,各模型漏报率明显降低,误报率维持在可接受的较低范围内。由此可见,语法特征数据集的标注标准对SQL注入攻击检测结果的影响较大。
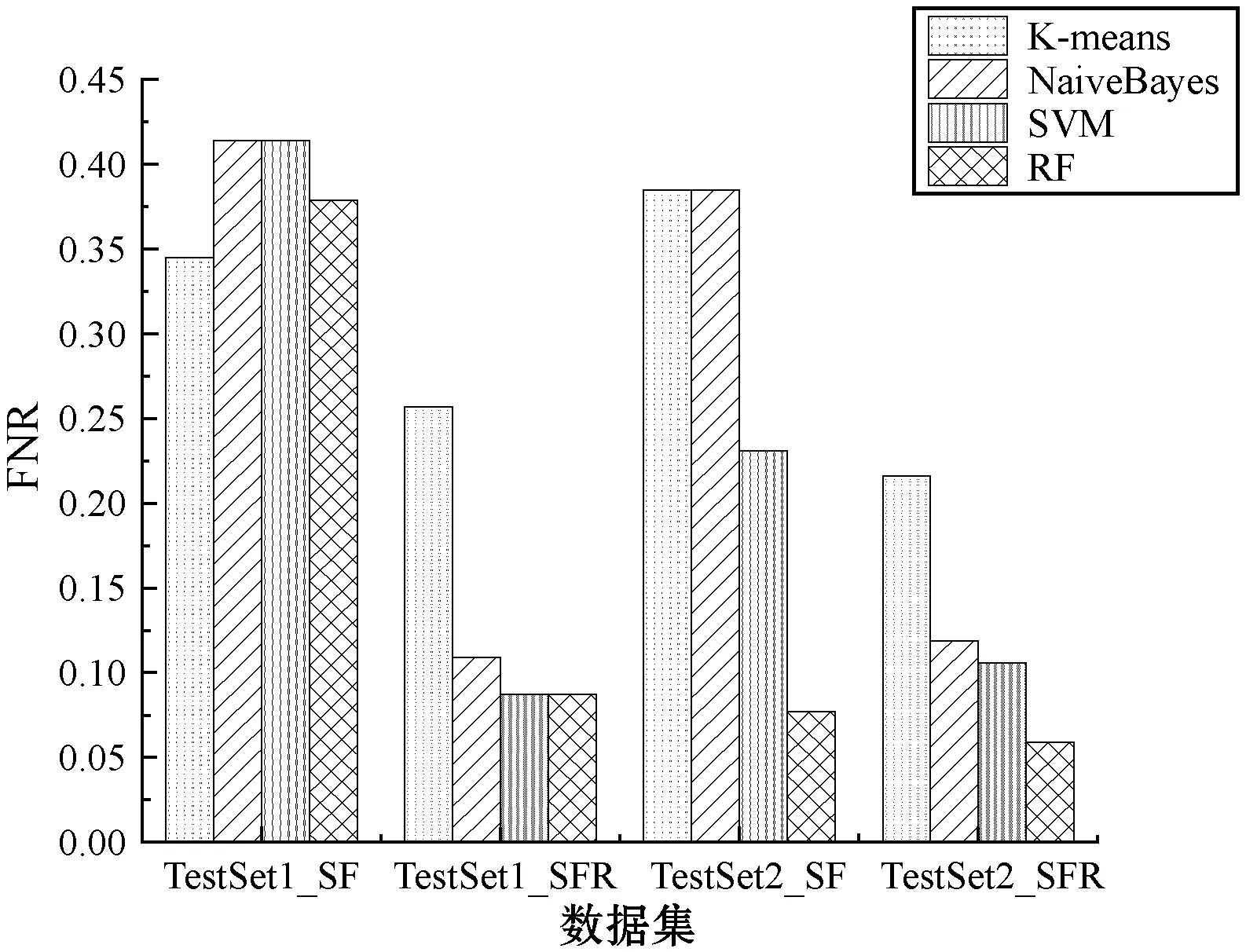
图8 SF重新标注前后FNR对比

图9 SF重新标注前后FPR对比
通过上述结果分析可知,基于电力信息系统日志数据提取SQL注入攻击语法特征和行为特征,用于注入攻击检测,能够有效检测出注入攻击,且检测结果具有较低的漏报率和误报率。本文实验结果虽然依赖于日志定义、攻击特征提取以及攻击行为的认定,但在SQL注入攻击检测方面具有非常好的通用性和易用性,经过简单的调整就可以对某类技术搭建的系统获得很好的检测效果。用于电力信息系统的SQL注入攻击检测中,可有效防止恶意用户的SQL注入攻击,保障电网信息系统的数据安全。
4 结 语
本文首先对Web应用日志数据进行分析,结合SQL注入攻击特点,从中提取注入攻击语法特征与行为特征,得到语法特征矩阵SF和行为特征矩阵BF两类实验数据集。然后使用K-means、Naive Bayes、SVM和RF算法进行建模和预测。通过实际的电力信息系统访问日志数据分析各算法模型在SF和BF数据集下对注入攻击检测的误报率和漏报率。实验结果表明,面向电力信息系统日志数据的注入攻击检测方法可有效检测对系统的SQL注入攻击。与语法特征相比,行为特征在注入攻击检测中具有更好的检测效果。SVM和RF算法的检测效果较好,具有较低的漏报率和误报率。未来工作将会在增加数据规模和安全攻击数据类型的基础上,基于多种数据挖掘模型进行综合研究分析,以进一步提高面向电力信息系统安全相关数据特征的挖掘与分析能力。
