Regression model for civil aero-engine gas path parameter deviation based on deep domainadaptation with Res-BP neural network
2021-03-16XingjieZHOUXuyunFUMinghangZHAOShishengZHONG
Xingjie ZHOU, Xuyun FU, Minghang ZHAO, Shisheng ZHONG
Department of Mechanical Engineering, Harbin Institute of Technology at Weihai, Weihai 264209, China
KEYWORDS Civil aero-engine;Deep domain adaptation;Domain confusion;Neural networks;Transfer learning
Abstract The variations in gas path parameter deviations can fully reflect the healthy state of aeroengine gas path components and units; therefore, airlines usually take them as key parameters for monitoring the aero-engine gas path performance state and conducting fault diagnosis.In the past,the airlines could not obtain deviations autonomously. At present, a data-driven method based on an aero-engine dataset with a large sample size can be utilized to obtain the deviations.However,it is still difficult to utilize aero-engine datasets with small sample sizes to establish regression models for deviations based on deep neural networks.To obtain monitoring autonomy of each aero-engine model,it is crucial to transfer and reuse the relevant knowledge of deviation modelling learned from different aero-engine models. This paper adopts the Residual-Back Propagation Neural Network(Res-BPNN) to deeply extract high-level features and stacks multi-layer Multi-Kernel Maximum Mean Discrepancy (MK-MMD) adaptation layers to map the extracted high-level features to the Reproduce Kernel Hilbert Space(RKHS)for discrepancy measurement.To further reduce the distribution discrepancy of each aero-engine model,the method of maximizing domain-confusion loss based on an adversarial mechanism is introduced to make the features learned from different domains as close as possible, and then the learned features can be confused. Through the above methods, domain-invariant features can be extracted, and the optimal adaptation effect can be achieved.Finally,the effectiveness of the proposed method is verified by using cruise data from different civil aero-engine models and compared with other transfer learning algorithms.
1. Introduction
As the main source of power for aircraft in the current stage,the health state of aero-engines directly affects the safety and economy of aircraft flight.1-3The gas path parameter deviations as crucial parameters can assist each airline in realizing aero-engine performance state trend analysis, life prediction and fault diagnosis. The variations in the gas path parameter deviations fully reflect the health state of the gas path components and units.4Although the gas path parameter deviations play a decisive role in monitoring the aero-engine performance, acquisitions are still subjected to the constraints of the Original Equipment Manufacturer (OEM). Commonly,the airlines first need to transmit the measured gas path parameters back to the OEM.Then,the OEM returns the deviations after analysis through monitoring systems. However, the whole process is extremely dependent on the OEM, which increases the operating cost and restricts airline development.Therefore, it is of great significance for airlines to mine the gas path parameter deviations to monitor the health state of aero-engines and conduct fault diagnosis and then obtain the monitoring autonomy of each aero-engine.
In recent years, many airlines, universities and research institutes have conducted research on the calculation of gas path parameter deviations. For instance, Lin and Fan5established three different types of aero-engine baseline equations for the JT9D using the orthogonal design principle and least squares method. Zhong et al.6solved the baseline equation of the TRENT700 aero-engine and established a model for performance parameter deviations by solving multivariate nonlinear overdetermined equations by the Gauss-Newton iterative method. Huang et al.7established a performance baseline model for the fuel flow of aero-engines by a Stacked Denoising AutoEncoder (SDAE). Yan8designed a multiinput and single-output Radial Basis Function (RBF) neural network with a Gaussian function selected as the hidden layer transfer function and the linear function selected as the output layer transfer function, and input nodes were confirmed by Pearson Correlation Analysis (PCA).
According to the above literature review,a large number of labelled sample sets must be used to obtain the aero-engine gas path parameter deviations. In clinical trials, fault diagnosis,earthquake prediction and other special fields, it is difficult to collect sufficient labelled samples. If the deep learning method is directly used to establish the regression model for the deviations based on a small sample-size dataset, it will inevitably lead to the problem of overfitting and a low regression effect. First, when airlines introduce new aero-engine models,they cannot obtain sufficient cruise data to build models of gas path parameter deviations in a short time, which results in a lack of aero-engine samples.Second,due to the different probability distributions of the cruise data obtained under different aero-engine models, we cannot directly use the regression model established by a large number of labelled samples from old aero-engine models to calculate the gas path parameter deviations of new aero-engine models.
The emergence of transfer learning addresses the limitations of the above two problems. When there exists a certain correlation between the source domain and the target domain, the regression model trained by the target domain dataset can make full use of the knowledge learned from the source domain to realize knowledge transfer between similar domains.9-11Transfer learning changes the model training from zero learning into cumulative learning. While reducing the computational cost of model training, transfer learning can also significantly improve the generalization performance of the model. The common transfer learning method fully mines the domain-invariant features to reduce the discrepancy between the source domain and target domain through a deep neural network and then realizes the transfer and reuse of the learned knowledge. At present, transfer learning can be divided into instance-based transfer learning, feature-based transfer learning, model-based transfer learning and relationbased transfer learning.Transfer learning can help people deal with new scenarios and enable machine learning to be realized without sufficient labelled data, which is widely applied in machine fault diagnosis, image recognition and natural language processing.12-14
To establish a regression model for the gas path parameter deviations of new aero-engine models, a deep domain adaptation regression model based on the Res-BPNN is proposed in this paper. The proposed model includes three modules: a high-level feature extraction module, a deep domainadaptation module and a regression module. The high-level feature extraction module mainly adopts Res-BPNN to deeply mine the high-level features between the gas path parameters and corresponding deviations. The deep domain-adaptation module is mainly designed to realize the optimal domain adaptation between the source domain and target domain by adding MK-MMD domain-adaptation layers and domainconfusion layer, and then the domain-invariant features between different domains can be fully mined. The regression module mainly realizes the regression analysis on gas path parameter deviations. The method proposed in this paper can be used to calculate the gas path parameter deviations of new aero-engine models. Two transfer experiments of mining the gas path parameter deviations are carried out to verify the effectiveness of the proposed model by utilizing two cruise datasets collected from the CFM56-5B2 and the CFM56-7B26.The experimental results show that the regression effect of the proposed method is obviously improved compared with the traditional transfer learning methods.
The remainder of this paper is organized as follows. Section 2 describes the deep domain-adaptation problem, including the concepts of Res-BPNN, distribution discrepancy metrics and domain confusion.Section 3 introduces the whole structure of the proposed model and sets the optimization objective. Section 4 conducts two transfer experiments to verify the regression effect and applicability of the proposed model and analyses the experimental results.Section 5 summarizes the experimental results and concludes the paper.
2. Deep domain-adaptation problem
To better illustrate the problems to be solved in this paper,the following definition is first given. Unlike traditional machine learning,transfer learning allows training data and testing data to come from different probability distributions.Therefore,let the source domain beXS={xS1,xS2,···,xSm}subject to distributions, and the target domain beXT={xT1,xT2,···,xTn}subject to distributiont. The target of the deep domain adaptation is to reduce the feature distribution discrepancy betweenXSandXTto learn the domain-invariant features. The socalled domain-invariant features mean that the features learned from both source domain data and target domain data should be subjected to the same or almost the same distribution. If the feature is domain-invariant, the regression model for gas path parameter deviations trained by the source domain data can effectively mine the features learned from the target domain data. Therefore, domain-invariant features are the key to realizing knowledge transfer. To extract the domain-invariant features between the source domain and target domain, the feature extraction method based on the Res-BP neural network, distribution discrepancy metrics and domain-confusion method are described in detail below.
2.1. Feature extraction method
To adapt to the characteristics of aero-engine cruise data and deeply mine the high-level features between the gas path parameters and their corresponding deviations, according to the learning mechanism of the deep residual network,15-17the residual learning blocks are introduced to the Back Propagation Neural Network(BPNN),and then the Res-BP neural network is established. The Res-BP residual learning block mainly consists of three fully connected layers:a Scaled Exponential Linear Unit (SELU) activation functions, Batch Normalization (BN) and a residual shortcut. The SELU activation function is expressed by
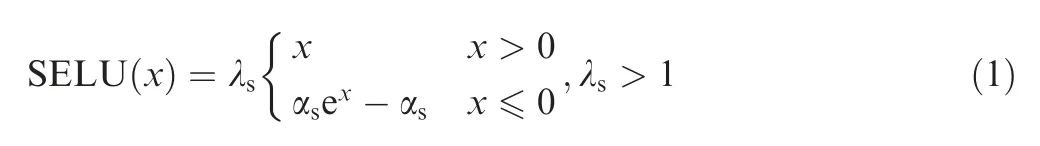
where the SELU activation function is a piecewise function,αsand λsare fixed parameters, andxis input. Unlike the Rectified Linear Unit (ReLU), the slope on the positive axis is greater than 1, and the variance in the function can be increased to prevent the gradient from disappearing. Second,the negative axis is no longer set at zero. The gentle slope not only guarantees the advantage of unilateral suppression but also solves the dead ReLU problem.
The traditional residual learning block and the Res-BP residual learning block are shown in Figs.1 and 2,respectively.
When the error propagates back under the traditional neural network,it is necessary to use the chain rule to calculate the partial derivative of a certain parameter. However, since network learning is a nonlinear superposition, the partial derivative in the deep neural network may result in gradient disappearance or gradient explosion as the layers increase,which can be expressed by
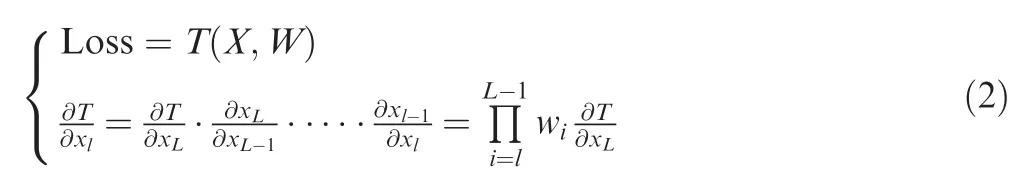
whereW={wl,wl+1,...,wL-1} is a set of weight parameters,andX={xl,xl+1,...,xL}is a set of neural network parameters.
Therefore,the residual learning block is introduced,and the chain rule of the certain parameter can be rewritten as
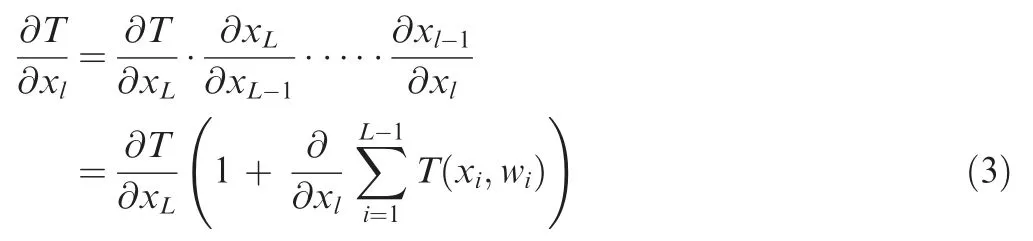
The network learning is no longer nonlinear superposition but linear superposition, which can greatly alleviate the negative impact of the deep neural network.
2.2. Distribution discrepancy metrics
To calculate the probability distribution discrepancy, the following measurements are introduced.
(1) Maximum Mean Discrepancy (MMD): MMD mainly maps two different feature distributions to the Reproducing Kernel Hilbert Space(RKHS)and then measures the distribution discrepancy.18

whereFis a set of continuous functions in the sample space,‖ · ‖Hrepresents RKHS, μsand μtare the mean of theXSandXTrespectively,Es[·] andEt[·] are the expectations of distributionssandt, respectively, and the inner product between feature mapsfand φ is defined as a kernel function.For example, the kernel functionk(x,y) = 〈φ(x),φ(y)〉H=is called the Gaussian kernel function,where σ is the bandwidth,which controls the local range of the function.
For the sake of calculation,the square of MMD is generally applied, which can be written as
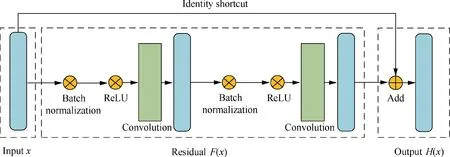
Fig. 1 Traditional residual learning block.
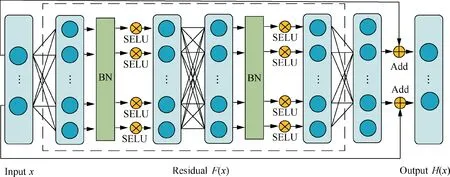
Fig. 2 Res-BP residual learning block.

wheremis the sample size of the datasetXS,andnis the sample size of the datasetXT.The MMD decreases as the distribution discrepancy closes. If and only ifsandtare subjected to the uniform distribution, the MMD distance is equal to 0.
(2) Multi-Kernel Maximum Mean Discrepancy (MKMMD): Long et al. proposed Deep Adaptation Networks (DAN) and adopted a variant algorithm of MMD, namely, MK-MMD,19which can better realize domain adaptation and enhance the feature representation ability of neural networks.
First, the empirical estimation of the MK-MMD distance between distributionsand distributiontcan be written as

whereHkrepresents RKHS endowed with a characteristic kernelk,f(·)represents a continuous mapping function, andEs[·]andEt[·] are the expectations of distributionsandt,respectively.
The characteristic kernel associated with the mapping functionfis defined as a convex combination ofmPositive Semi Definite (PSD) kernels {ku} , which can be expressed by
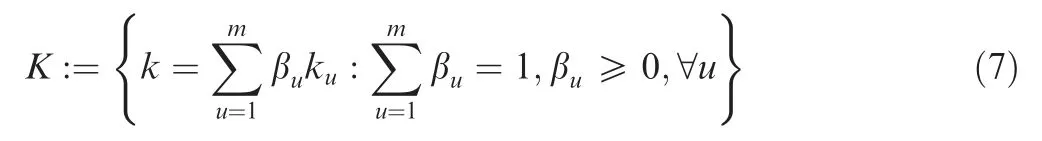
Since the feature distributions will change when a deep neural network is learned, it is difficult to determine which kernel functions can show a stronger mapping ability. However, the multi-kernel can enhance the adaptability between different feature distributions to achieve the optimal and reasonable selection of kernel functions.
2.3. Domain-confusion method
To further reduce the marginal distribution discrepancy between features learned from different domains, a domainconfusion method based on an adversarial mechanism20is introduced in this paper, and its schematic diagram is shown in Fig. 3.
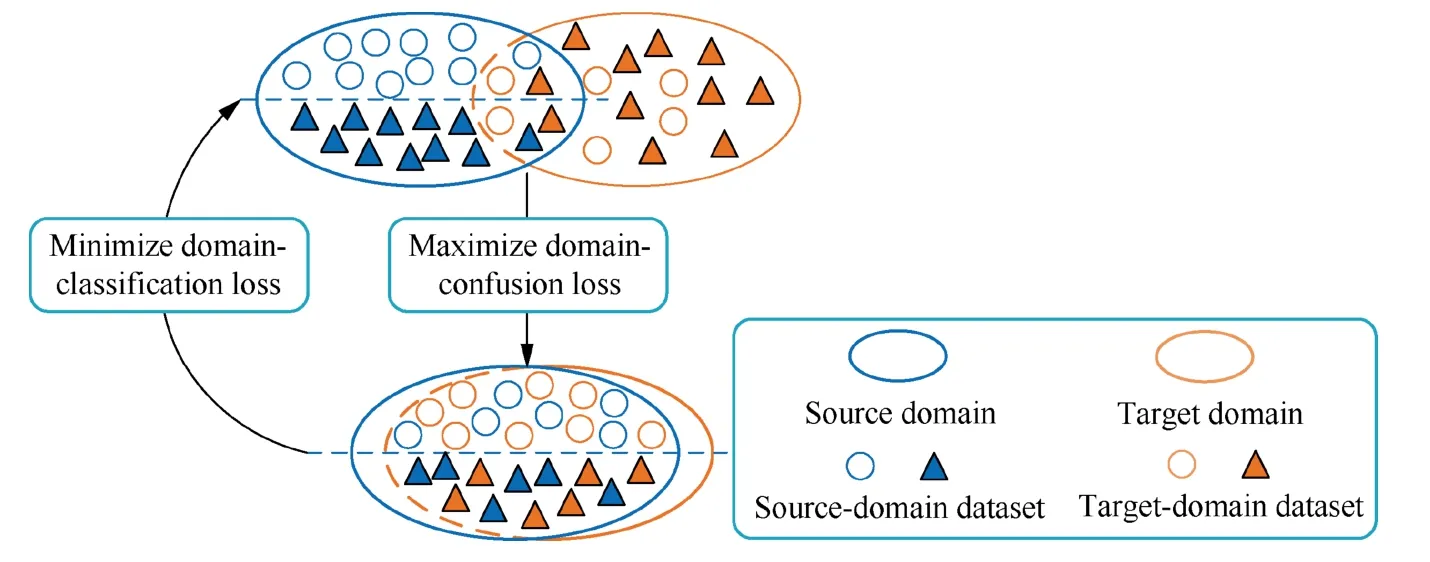
Fig. 3 Maximization of domain-confusion loss.
To maximize domain-confusion loss, this paper adds a domain-confusion layer to determine whether the high-level features originate from the source domain or the target domain. The more extracted high-level features can reflect the commonality between different domains, the better the domain-confusion effect is. If the high-level extracted features by Res-BPNN cannot be distinguished by the trained domain classifier from the source domain or the target domain,the feature can be said to have domain-invariant characteristics. The best domain classifierDcan be obtained by optimizing

wheregiis the actual domain label of theith sample,gi= 0 denotes that samplexioriginates from the source domain,gi= 1 denotes that samplexioriginates from the target domain, andD(·) represents a domain classifier.
3. Model establishment
3.1. Model structure
In this paper, the deep domain-adaptation regression model based on Res-BPNN consists of three modules:a feature extraction module,a deep domain-adaptation module and a regression module. The high-level feature extraction module adopts Res-BPNN to extract the gas path state high-level features through stacked Res-BP residual learning blocks. The deep domainadaptation module is connected to the feature extraction module to learn domain-invariant features. The regression module is added to realize the proposed model,as shown in Fig.4.
(1) Feature extraction module:Feature extraction module is achieved by three stacked Res-BP residual learning blocks with a total of 10 layers including one input layer.Each Res-BP residual learning block mainly consists of three fully connected layers and one residual shortcut.The output of each fully connected layer first adopts batch normalization, and then neurons are activated by the SELU activation function.
(2) Deep domain-adaptation module: The deep domainadaptation module consists of a domain-confusion layer and three MK-MMD adaptation layers.The three MKMMD adaptation layers are connected with the feature extraction module, and the distance between different domains is measured by MK-MMD. The domainconfusion layer includes a domain classifier, of which the output is a binary classifier setting with logistics regression and is connected with MK-MMD adaptation layers.
(3) Regression module: The regression module mainly realizes the mapping of extracted high-level features to the corresponding gas path parameter deviation, which is connected with the domain-confusion layer.
3.2. Optimization objective
Considering that the airline introduces a new civil aero-engine model and only has the small sample-size labelled data of this new model, to establish the gas path parameter deviation model of this new aero-engine model in the short term, it is necessary to make full use of the labelled data resources.Therefore, the regression loss of small sample-size labelled data of the target domain is introduced into the final optimization objective.To facilitate the comparison with other transfer learning methods,the proposed method is divided into the proposed method (supervised) and the proposed method (unsupervised) according to whether the labelled data of the target domain are introduced into the final optimization objective.
Therefore, the deep domain-adaptation regression model based on Res-BPNN has the following three optimization objectives:
(1) The first optimization objective of the deep domainadaptation regression model is to minimize the regression errors of the gas path parameter deviations on the source domain dataset and the target domain dataset.The loss function of the regression error is defined as the standard Mean Square Error (MSE) loss function,which can be expressed by
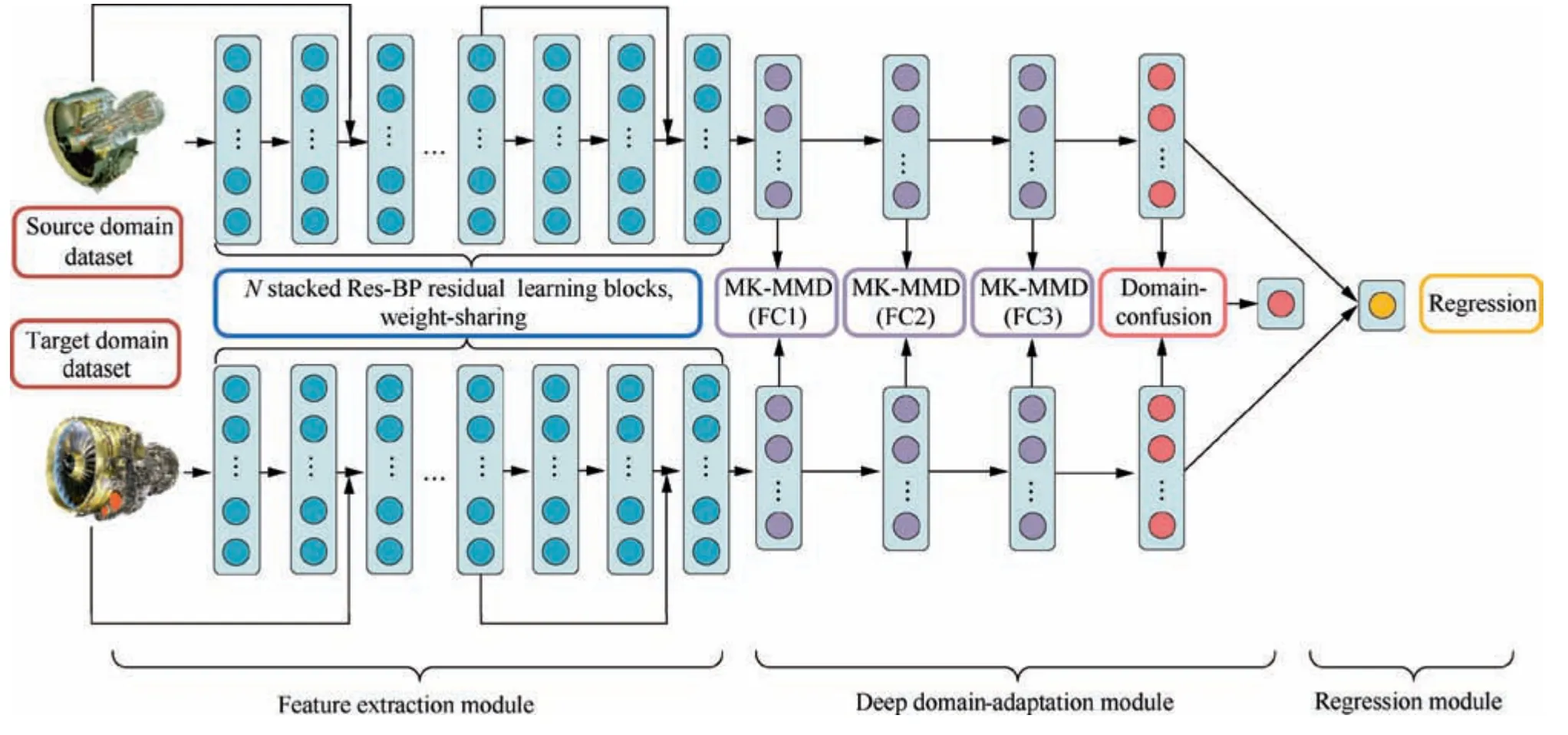
Fig. 4 Framework of proposed model.

where a batch size of the training dataset is constructed bynSsource domain data samples andnTtarget domain data samples,yiandyjare the actual values of the gas path parameter deviation of the source domain dataset and the target domain dataset,respectively, ^yiand ^yjare the corresponding predicted values, and τ is the training weight on the target domain labelled data. When and only when τ is equal to 0, the target domain labelled data are not introduced into the final optimization objective.
(2) The deep domain-adaptation module is used to learn domain-invariant features, as shown in Fig. 4. The MK-MMD domain-adaptation layer is mainly used to measure the distribution discrepancy between features learned from different domains. Therefore, the second optimization objective of the deep domain-adaptation regression model is to minimize distribution discrepancy. In the deep domain-adaptation module, MKMMD is used to calculate the distribution distance between high-level features learned from the source domain and target domain, which can be written as
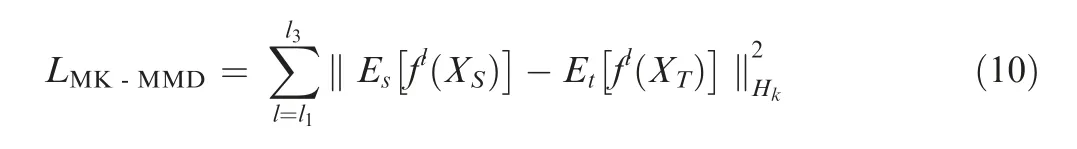
whereXSandXTare the datasets of the source domain and target domain, respectively,liis theith domain-adaptation layer,fli(·) is the feature representation of theith adaptive layer, and ‖ · ‖Hkrepresents RKHS with kernelk.
(3) To further reduce the marginal probability distribution discrepancy between the features learned from different domains, the domain-confusion method based on an adversarial mechanism is adopted to make the feature distributions between different domains as close as possible to further mine the domain-invariant features.Therefore, the third optimization objective of the deep domain-adaptation regression model is to maximize the domain-confusion loss, and Eq. (8) can be rewritten as
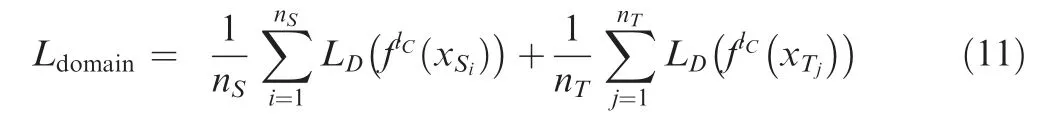
whereflCis the feature representation learned on the confusion layer.
By combining regression loss,MK-MMD loss and domainconfusion loss, the final optimization objective of the deep domain-adaptation regression model based on Res-BPNN can be written as
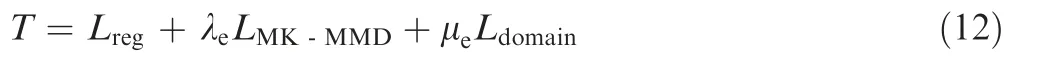
whereLregis the regression loss,LMK-MMDis the MK-MMD loss,Ldomainis the domain-confusion loss, and hyperparameters λeand μecontrol the strength of deep domain adaptation.
In this experiment,the Stochastic Gradient Descent(SGD)algorithm is used to train the proposed model. Let θf, θdand θregrespectively be the parameters of the feature extractor,domain classifier and regressor. Eq. (12) can be rewritten as

Based on Eq.(13)and the SGD algorithm,the update process of parameters θf, θdand θregcan be expressed by

whereris the training progress that changes linearly from 0 to 1, epoch is the current number of completed training, and epochs is the number of training that needs to be completed in advance. The parameters α0, β and δ are 0.01, 0.75, and 10, respectively.
The adjustment process of the hyperparameters λeand μecan be written as Eq. (16), which allows the domain classifier to be less sensitive to noisy signals at the early stages of the training procedure.
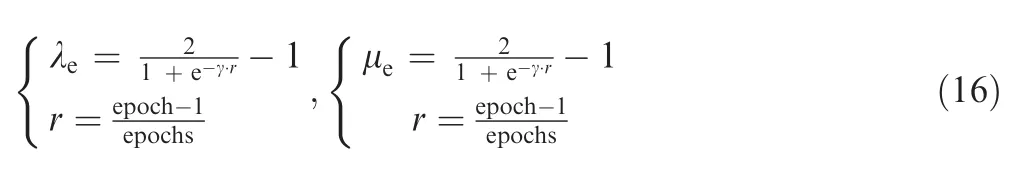
where γ is a constant and γ is equal to 10.
When the model training is completed, if the learned highlevel features have fuzzy domain labels and poor domain discrepancy, the proposed model can accurately mine the deviation of the new aero-engine model.
4. Experimental validation
4.1. Optimization objective
To fully verify the proposed method on mining gas path parameter deviations of the new aero-engine model,we collect two datasets from the CFM56-5B2 aero-engine and CFM56-7B26 aero-engine and apply them to two gas path parameter deviation transfer experiments. Two groups of transfer learning tasks are A (CFM56 - 5B2 →CFM56 - 7B26) and B(CFM56 - 7B26 →CFM56 - 5B2)
Transfer Task A (CFM56 - 5B2 →CFM56 - 7B26) means that we first train the regression model with labelled data collected from the CFM56-5B2 aero-engine and assist the small sample-size data collected from the CFM56-7B26 civil aeroengine to transfer learned relevant knowledge.
Transfer Task B (CFM56 - 7B26 →CFM56 - 5B2) means that the source domain dataset and the target domain dataset in transfer Task A are exchanged,and the transfer experiment is carried out again to verify the proposed model.
Partial datasets of the two aero-engines are shown in Table 1, and the allocation proportions of the datasets in the two transfer experiments are shown in Table 2.
As summarized in Table 1, the flight parameters have different orders of magnitude.To eliminate the dimensional influence,the row flight data need to be standardized to make them comparable.In this paper,the Z-score standardization method is adopted to ensure that the processed data conform to the standard normal distribution. The conversion equation is expressed by

where μiis the mean of theith parameter and σiis the standard deviation of theith parameter.
The corresponding relationship between the input and output of the regression model for the gas path parameter deviations is shown as
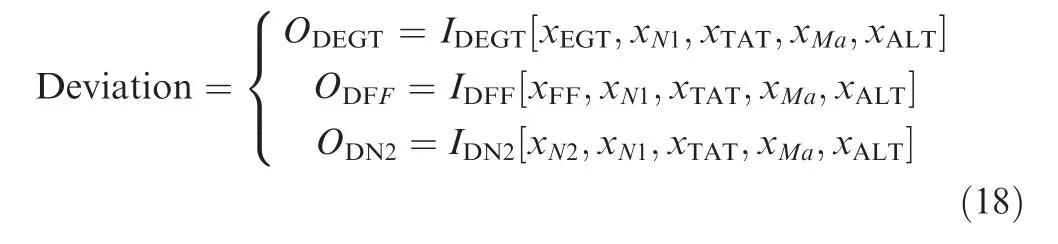
whereOD-is the output,ID-[·]is the input,andxiis the measured value of theith flight parameter.
4.2. Hyperparameter setting
The transfer experiment for the unlabelled aero-engine dataset from the target domain is first carried out. To fully prove the effectiveness of the proposed method, the experiment is also carried out when the aero-engine from the target domain is labelled.To distinguish two groups of experiments,the former is called the unsupervised method, and the latter is called the supervised method. Two groups of experiments use the same hyperparameters to ensure fairness of comparison except for τ in Eq. (9). Similarly, while the setup of hyperparameters remains a challenge that requires considerable research, the focus of this research is to develop a new deep learning approach with a specifically designed architecture rather than optimizing hyperparameters. The hyperparameter settings are as follows.
Mini-batch is a group of randomly selected parameters that are propagated into a network at the same time. The minibatch size is 100. The training step is set to 1000. Momentum is a training technique that makes use of the updates in the last iteration to accelerate the optimization process. In this study,the momentum ratio is 0.9. The model adopts the SGD optimization algorithm and SELU activation functions.
In this experiment, the feature extraction module is composed of three Res-BP residual learning blocks, and the deep domain-adaptation module is composed of three MK-MMD domain-adaptation layers and one domain-confusion layer to fully minimize distribution discrepancy.

Table 1 Partial datasets of two aero-engines.

Table 2 Allocation proportion of datasets on two transfer experiments.
4.3. Performance comparison
To further prove the validity of the deep domain-adaptation regression model based on Res-BPNN, nine different transfer learning algorithms are used to establish three key gas path parameter deviation regression models on transfer Task A and transfer Task B and to conduct performance comparison.The comparison methods used in this paper are shown in Table 3: Transfer Component Analysis (TCA),21Joint Distribution Adaptation (JDA),22Balanced Distribution Adaptation (BDA),23Deep Domain Confusion (DDC),18Deep Adaptation Networks (DAN),19Domain-Adversarial Neural Network (DANN)20and the proposed method (unsupervised)are all unsupervised transfer learning algorithms. Considering the actual situation of introducing a new aero-engine model into airlines, to make full use of the existing labelled target domain dataset resources,the regression error of these datasets should be incorporated into the final optimization objective and compared with Res-BPNN and fine-tuning.24,25
The above supervised and unsupervised learning methods are used to establish regression models for three key gas path parameter deviations (DEGT, DFF and DN2). The performance comparison results of transfer Task A and transfer Task B are shown in Tables 4-6 and 7-9, respectively. The value in bold represents the best fitting method for the current sample.
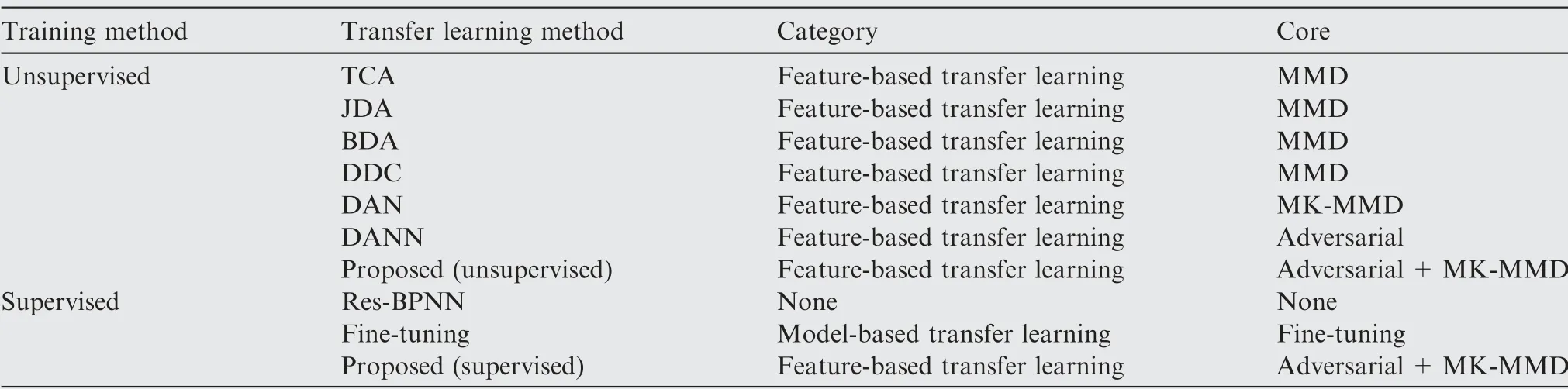
Table 3 Comparison of transfer learning methods.
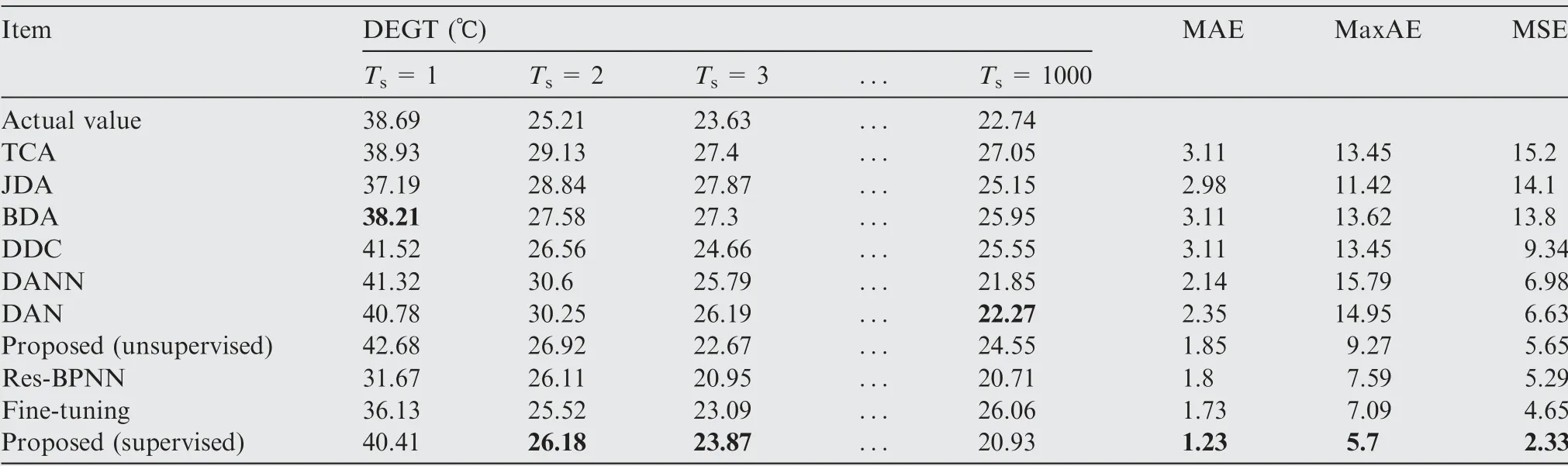
Table 4 Regression effect of DEGT on transfer Task A.
As shown from Tables 4-9,the regression effect of the proposed model in this paper is the best among the traditional transfer learning algorithms on both transfer Task A and transfer Task B.
(1) By analysing and comparing the experimental results of(TCA, JDA and BDA) and (DDC, DAN, DANN and the proposed method (unsupervised)), we can see that the experimental results of the second group are better than those of the first group.The three transfer learning algorithms of the first group need to select the firstmeigenvalues in the process of dimension reduction, and useful information between flight parameters may be lost in the intermediate process,leading to a poor transfer effect.However,the four transfer learning algorithms in the second group use a deep neural network to extract high-level features,so they can better represent the accurate mapping relationship between the gas path parameters and corresponding deviations and then fully reduce the distribution discrepancy.
(2) By analysing and comparing the four unsupervised transfer learning algorithms DDC, DAN, DANN and the proposed method (unsupervised), we find that the proposed method (unsupervised) has the best transfer effect. DDC introduces the MMD domain-adaptation layer to learn the domain-invariant features. On the basis of DDC, DAN learns domain-invariant features better by introducing three MK-MMD domainadaptation layers without increasing the extra training time. DANN deeply extracts the common features between the source domain and the target domain by introducing the domain-confusion layer based on an adversarial mechanism. Combining the advantages of DANN and DAN, this proposed method can better mine the domain-invariant features and effectively reduce the feature distribution discrepancy between different domains.

Table 6 Regression effect of DN2 on transfer Task A.

Table 5 Regression effect of DFF on transfer Task A.
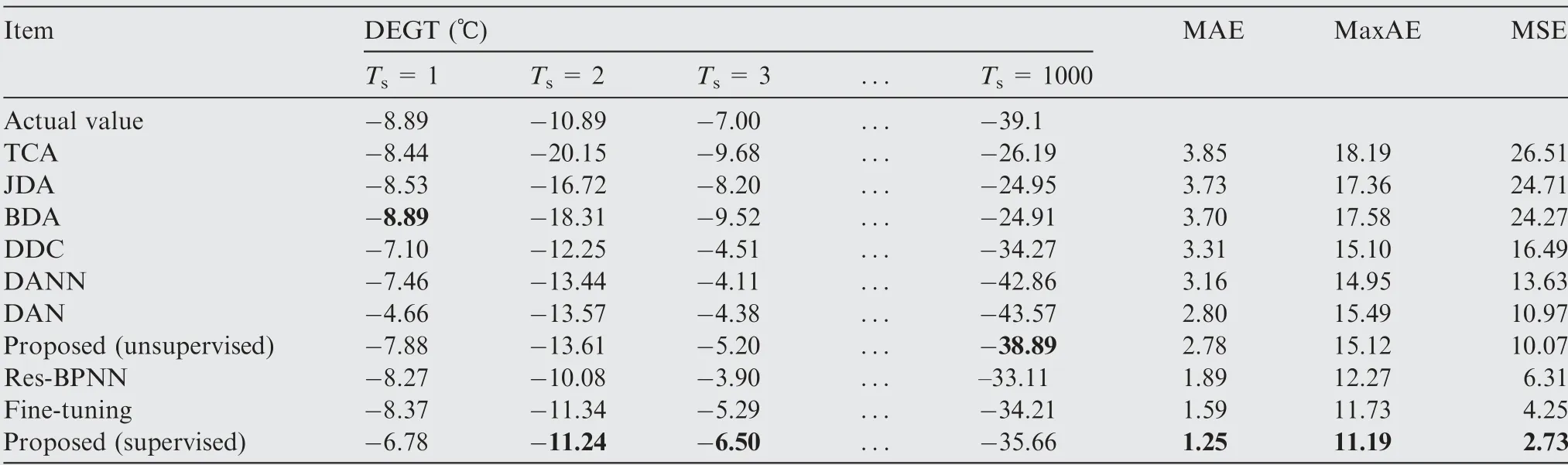
Table 7 Regression effect of DEGT on transfer Task B.
(3) By analysing and comparing the three supervised transfer learning algorithms, the Res-BPNN regression model, fine-tuning, and the proposed method (supervised), we find that the proposed method (supervised)has the best transfer effect. Due to the small samplesize labelled data of the new aero-engine model,directly using the Res-BPNN regression model for training inevitably leads to a poor regression effect under a deep neural network,resulting in the problems of overfitting and poor regression accuracy. The fine-tuning method is adopted to pretrain the regression model with the source domain dataset and then freeze the parameter weights of the firstnlayers of the pretrained neural network. The target domain dataset with a small sample size is used to fine-tune the parameters of the last several layers,learn the high-level features of the gas path state, and then realize the establishment of a regression model for aero-engine gas path parameter deviations. In this paper, the proposed method (supervised) transforms the unsupervised transfer learning problem into a supervised transfer learning problem by introducing the regression loss of the labelled target domain dataset with a small sample size to the final optimization objective,fully mines the domain-invariant features between the source domain and the target domain, and then further reduces the feature distribution discrepancy. The proposed method significantly improves the transfer effects.
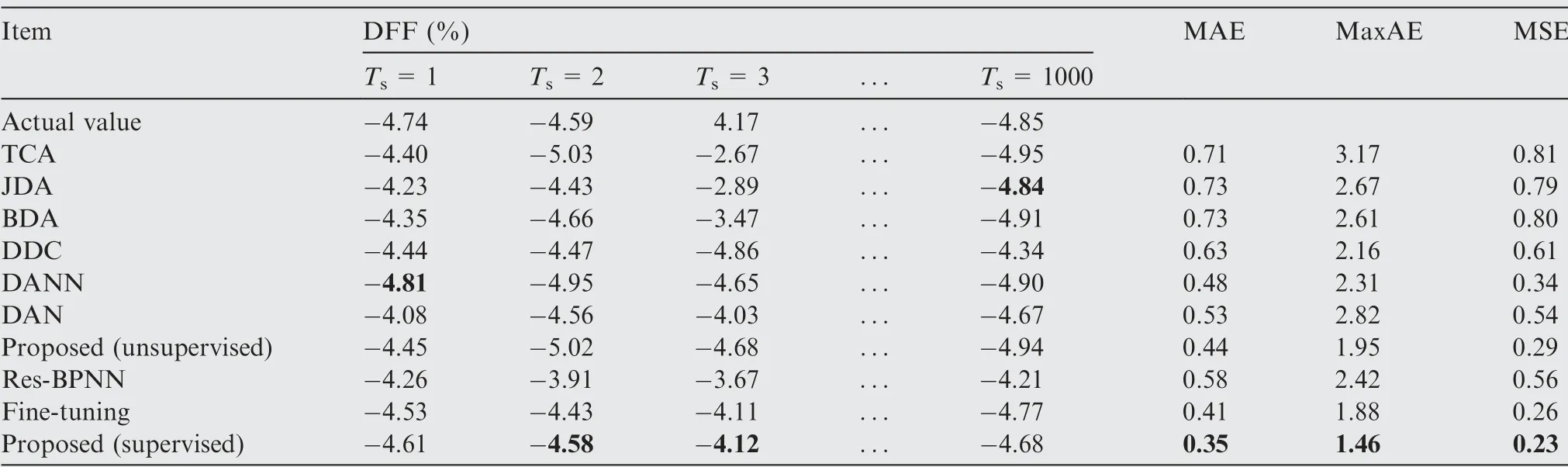
Table 8 Regression effectof DFF on transfer Task B.
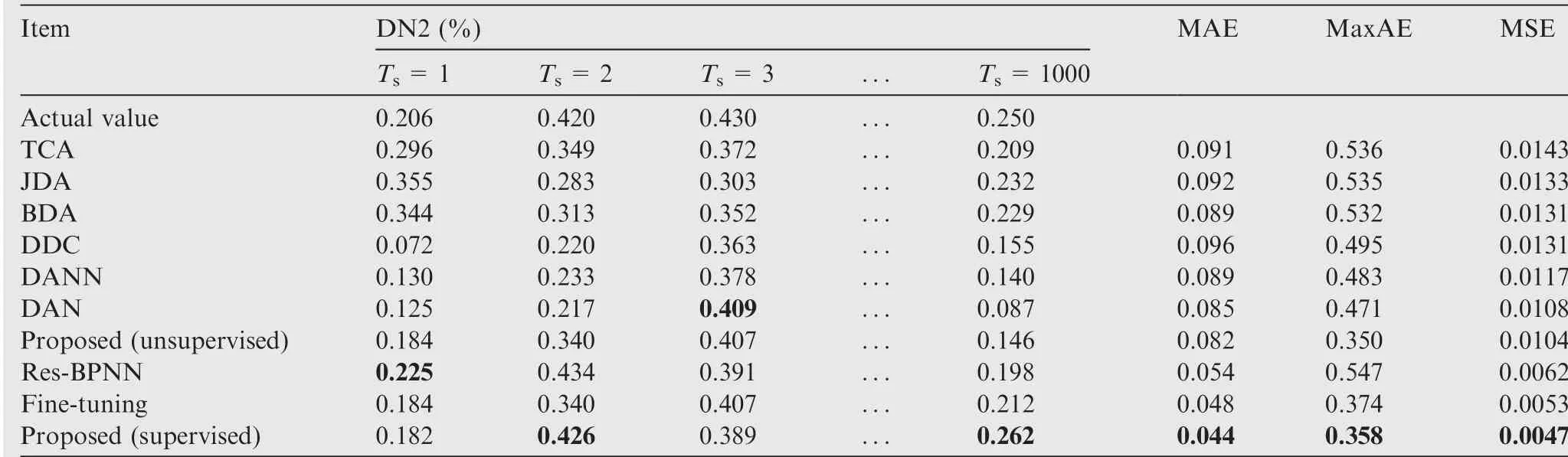
Table 9 Regression effect of DN2 on transfer Task B.

Fig. 5 MK-MMD and training loss in training process.
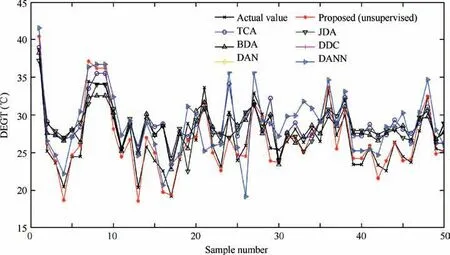
Fig. 6 Regression result of DEGT in transfer Task A (unsupervised).
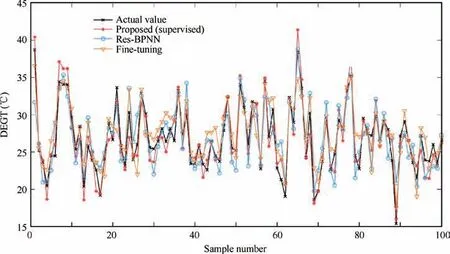
Fig. 7 Regression result of DEGT in transfer Task A (supervised).
To intuitively reflect the superiority of the deep domainadaptation regression model based on Res-BPNN proposed in this paper, the regression effect of DEGT in transfer Task A is selected as an example for illustration. The change in MK-MMD and training loss with increasing iterations is shown in Fig. 5. Because the various unsupervised transfer learning algorithms are compared, to clearly and intuitively reflect the regression results, only 50 test results are presented here, as shown in Fig. 6. The 100 test results of the three supervised transfer learning algorithms are shown in Fig. 7.
5. Conclusions
In this paper, the regression model for aero-engine gas path parameter deviations is established under different working conditions and different engine models. First, aimed at the deep domain adaptation problem, this paper introduces MKMMD to measure the distribution discrepancy between features learned from different domains and the domainconfusion method based on an adversarial mechanism.In view of the actual mapping relationship between the civil aeroengine gas path parameters and their corresponding deviations,NRes-BP residual learning blocks are stacked to extract the high-level features of the gas path state, multiple MKMMD domain-adaptation layers and domain-confusion layers are used to deeply mine the domain-invariant features between the source domain and the target domain, and then the establishment of a regression model for civil aero-engine gas path parameter deviations is realized.Based on the above methods,a deep domain-adaptation regression model based on the Res-BPNN is proposed.To make full use of the labelled data in the target domain, the regression loss of labelled data of the new aero-engine model is introduced into the final optimization objective. The proposed method is divided into supervised and unsupervised methods according to whether the regression model introduces labelled target domain data and compared with traditional transfer learning algorithms.The experimental results show that the proposed model can efficiently mine the domain-invariant features between the source domain and the target domain, further reducing the distribution discrepancy and effectively improving the transfer effect.
Compared with the traditional transfer learning algorithm,the regression effect of the proposed method has been improved. However, it also can be improved more because of the insufficient domain-invariant features. Thus an advanced approach needs to be introduced to fully mine the domain-invariant features.In addition,further study is needed to establish the transfer mechanism between different aeroengine models to ensure transfer rationality.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This work is supported by the Shandong Provincial Natural Science Foundation (No. ZR2019MEE096) and the Key National Natural Science Foundation of China (No.U1733201).
杂志排行

CHINESE JOURNAL OF AERONAUTICS的其它文章
- Tangling and instability effect analysis of initial in-plane/out-of-plane angles on electrodynamic tether deployment under gravity gradient
- Aerodynamic periodicity of transient aerodynamic forces of flexible plunging airfoils
- Effects of swirl brake axial arrangement on the leakage performance and rotor stability of labyrinth seals
- Experimental and computational investigation of hybrid formation flight for aerodynamic gain at transonic speed
- Tomography-like flow visualization of a hypersonic inward-turning inlet
- Hypersonic reentry trajectory planning by using hybrid fractional-order particle swarm optimization and gravitational search algorithm