基于GPU的高吞吐量QC-LDPC码编码器实现
2021-03-12段运德
段运德,黎 勇
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.重庆大学 计算机学院,重庆 400044)
0 引 言
1962年,R.Gallager[1]在他的博士论文中第一次提出了低密度奇偶校验(low-density parity-check, LDPC)码。当时由于计算机技术并不发达,LDPC码译码复杂度高,导致其优秀的性能未被发现。直到1996年D.J.C.Mackay等[2]重新研究LDPC码,发现其性能可以接近香农限,LDPC码才重新开始受到重视,并迅速成为信道编码研究中的重要方向。QC-LDPC码是一类具有准循环结构的LDPC码,因为其循环特性可以降低编译码复杂度,目前已被应用在很多标准和系统中,比如IEEE 802.11n(WLAN),IEEE 802.16e(WiMAX)[3],量子秘钥分发[4],ATSC3.0[5]等。2017年,3GPP标准会议将QC-LDPC码确定为5G通信系统的长码标准[6]。
因为实际系统往往选择QC-LDPC码,而不是其他LDPC码,因此,提高QC-LDPC码的编码速率有重要的实际意义。为提高编码效率,大家普遍选择现场可编程逻辑门阵列(field programmable gate array, FPGA)、专有电路(application-specific integrated circuit, ASIC)等硬件解决方案[7],硬件方案通常只针对特定码型或码率的LDPC码有效,通用性差。相比而言,图形处理单元(graphics processing unit, GPU)加速是一种更便宜、更灵活、更高效的软件方案。本文通过把QC-LDPC码的校验矩阵转换为准循环的生成矩阵,再基于编码过程中的并行部分和GPU的内存、线程结构,给出一种吉比特速率的软件编码方案。该方案不仅通过单个码字编码并行化以及多个码字同时编码来提高编码吞吐量,而且通过对片上常量内存和共享内存的合理使用进一步加快了编码速率。仿真结果表明,相较于已有的GPU编码方案,本文的方案通用性更强,编码吞吐量比文献[8]高;相较于其他硬件快速编码方案,本文的编码器在通用性和编码吞吐量上均明显高于文献[9]的FPGA编码器和文献[10]的CMOS编码器。
1 通过校验矩阵计算QC-LDPC码准循环结构的生成矩阵
QC-LDPC码的校验矩阵由具有准循环特性的子矩阵组成,表示为
(1)
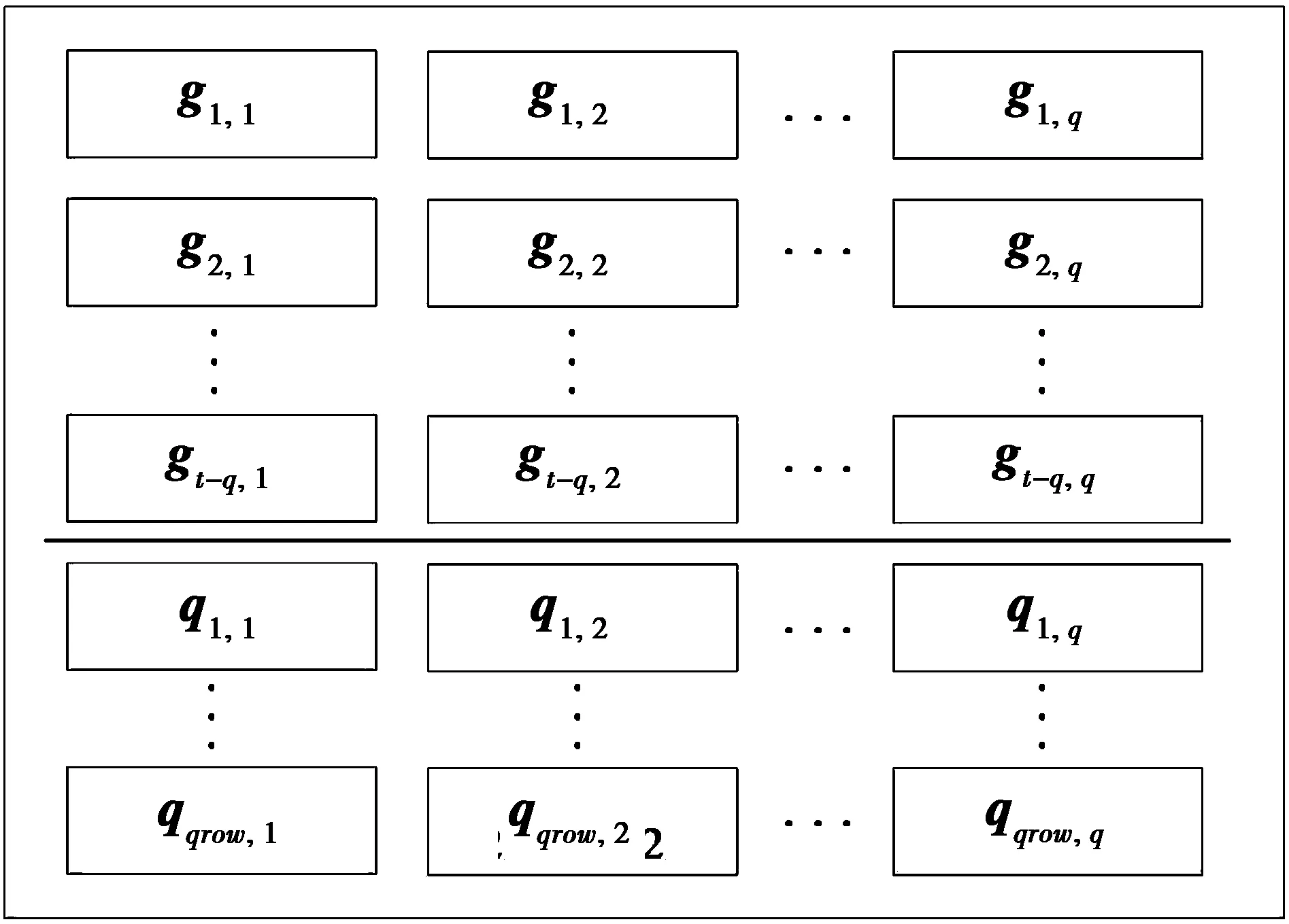
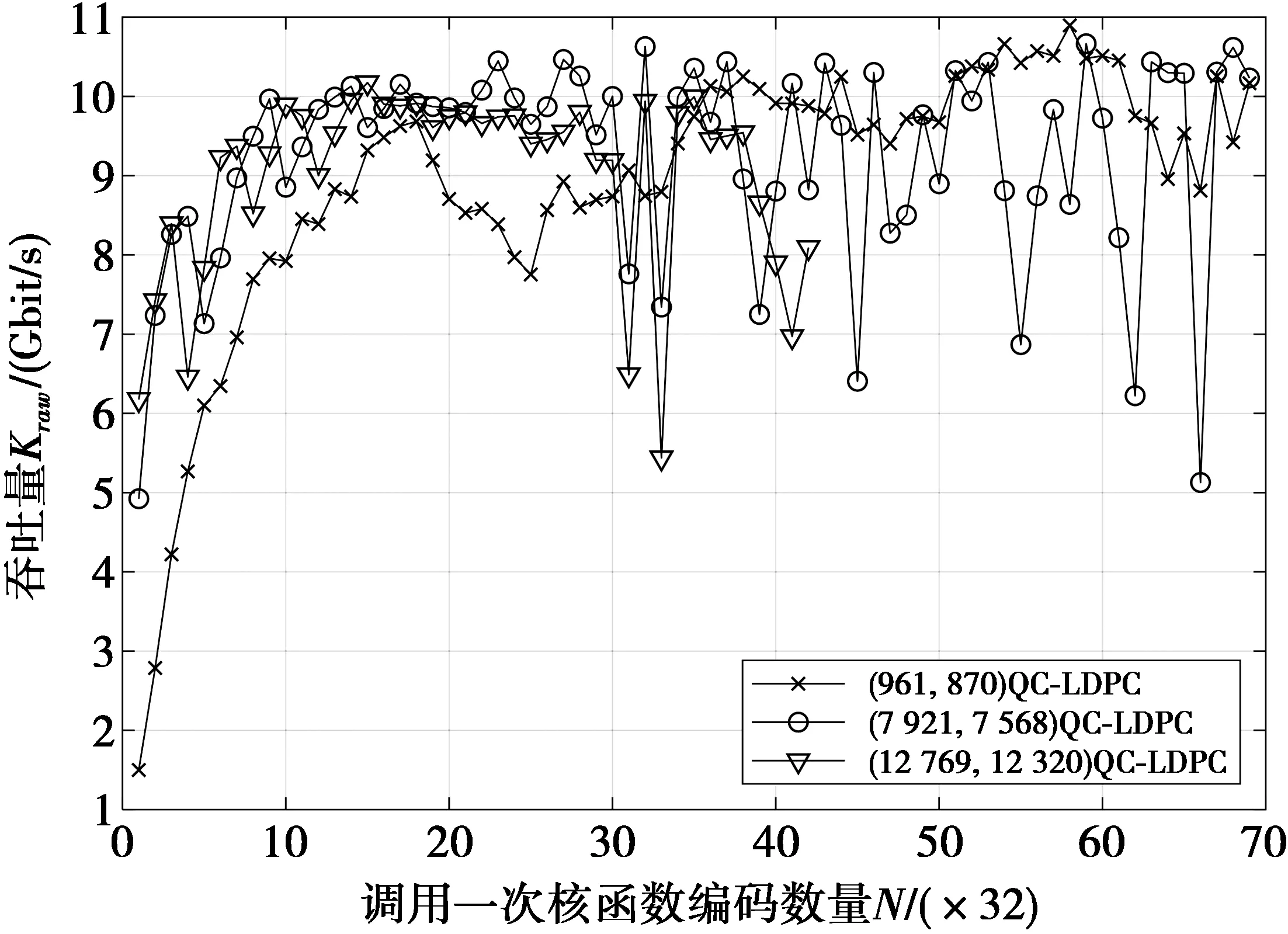
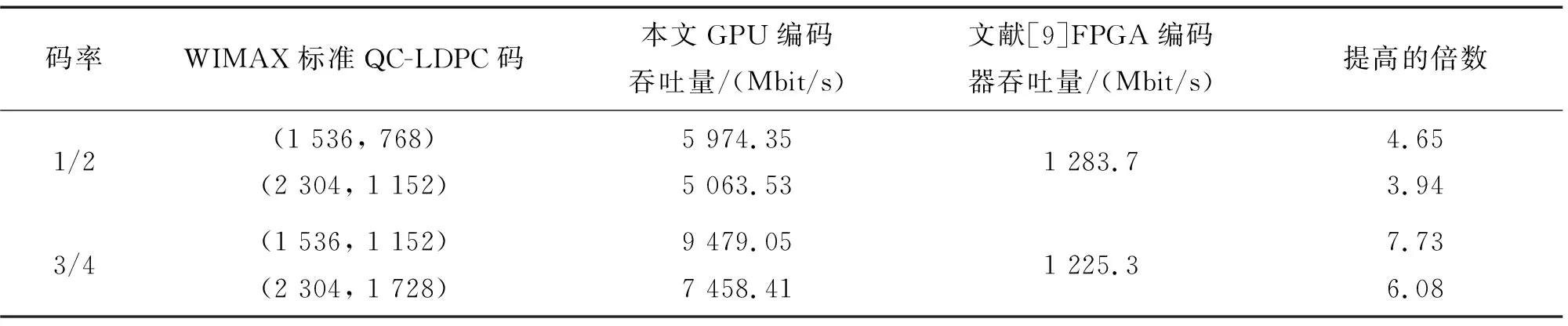
(1)式中:c rank(H)=rank(D)=r (2) 设得到的D矩阵为 (3) H中选择q列后,剩下的t-q列构成矩阵B,表示为 (4) 将H按列重排得到Hqc=[B|D],Hqc同样为该QC-LDPC码的校验矩阵。设该码的生成矩阵为Gqc,则有 (5) (5)式中:Gqc为k×n阶矩阵;n为该QC-LDPC码码长,n=tb;k为信息位长,k=tb-r;O是cb×(tb-r)阶零矩阵。由(5)式和文献[11]中的算法即可解出矩阵Gqc,且Gqc有如下结构 (6) (7) Q= (8) (7)—(8)式中:I为b阶单位阵;O为b阶零矩阵;Gi,j为b阶方阵,且具有准循环结构,即Gi,j中每行向量是其前一行向量向右循环移动一位得到;Oi,j为全零矩阵;qrow代表有qrow行子矩阵。Oi,j,Qi,j列数都为b,在计算Gqc时可以得到Oi,j和Qi,j的行数。本文先将Qi,j的行数保存在数组qNum[qrow]中以备后面程序使用,表示为 qNum[qrow]={qNum0,qNum1,…,qNumqrow} (9) (9)式中,qNumi对应Q的第i行子矩阵Qi,·的行数。这样得到的Qi,j同样具有准循环结构,即Qi,j中每行向量是其前一行向量向右循环移动一位得到的。设gi,j为Gi,j的首行向量,qi,j为Qi,j的首行向量,则通过所有gi,j和qi,j的循环移位即可以得到矩阵G和Q,从而得到Gqc。这里,定义和gi,jqi,j为Gqc的生成向量。 通过上述计算得到的生成矩阵Gqc通常具有(6)式的结构,即由子矩阵G和Q组成。但如果给定的QC-LDPC码的校验矩阵H是非奇异矩阵,且q=c,此时通过上述计算得到的Gqc只由子矩阵G组成,即Gqc=[G]。 在求解Gqc的过程中,需要多次求GF(2)中矩阵的秩。为了加快求秩速度,本文采用了文献[12]中的稀疏矩阵高斯消去算法求秩。 通过以上处理,从QC-LDPC码的校验矩阵H得到了具有准循环结构的生成矩阵Gqc。根据其循环特性,即由首行向量gi,j和qi,j循环移位可得到Gqc。因此,在编码程序中,仅需存储生成向量gi,j和qi,j,节省了存储空间。 基于GPU的并行算法设计通常是一项具有挑战性的工作。必须慎重考虑线程的数量、内存的大小以及寄存器等资源的限制。同时为了获得正确的结果,必须注意线程的同步。CUDA(compute unied device architecture)是NVIDIA的GPU提供并行计算的平台和编程接口,本文将基于CUDA平台编程仿真。在设计编码时,本文将从以下一些方面进行优化。表1给出了下文叙述中用到的一些参数。 CUDA核函数初始化比CPU函数初始化需要更多时间,因此编码时,核函数将同时输入N=32×s(s为正整数)个信息序列,然后在运行一次核函数时同时对N个码字进行编码,以加快编码速度。CUDA执行核函数的调度单位为线程束,每个线程束包含32个线程,因此,选择N为32的倍数可以加快线程调度。 表1 文中重要参数 本文将定义结构体Bitset保存长度为b个比特的向量,如gi,j和qi,j向量。本文中Hqc,H,G等矩阵的子矩阵阶数为b,也用该结构体来保存。该结构体伪代码如下。 //一个int变量长32比特 const int g_intLen←32; //g_num为保存长为b的向量需要int的个数 const int g_num←(b-1)/g_intLen+1; struct Bitset{ int val[g_num]; } CUDA常量内存是一种64 KByte的只读缓存,它提供比全局内存更大的访问带宽。编码时生成矩阵Gqc是在第1节中已经求解出来的常量,不会改变,因此,将Gqc的生成向量gi,j和gi,j按图1的格式存储在常量内存的Bitset类型的二维数组generatorMtx中。 图1中,t,q,qrow参数含义见表1。使用CUDA常量内存存储Gqc的二维数组代码为 __constant__ __device__ Bitset generatorMtx[t-q+qrow][q]; 图1 矩阵Gqc在常量内存中的映射Fig.1 Map of Gqc stored in constant memory 编码算法的CUDA核函数原型为 __global__ voidcuEncode(int *mess, int *code); 其中,mess是一个数组指针,保存N个信息序列,该数组包含N×k个比特。code为编码输出的码字数组指针,数组包含N×n个比特。 当调用CUDA核函数编码时需要进行线程分配,本文将分配二维线程块numThread,其维度为(t-q+qrow)×q,numThread和存储Gqc的二维数组generatorMtx具有相同的维度。在同一个线程块中,每个线程将同时读取gi,j和qi,j,同时进行计算。为了充分利用GPU线程,本文还将定义一维的线程网格numBlock,网格包含N个线程块,每个线程块中进行单个码字的编码,核函数运行一次将同时编得N个码字。调用该核函数的代码为 dim3 numThread(t-q+qrow, q), numBlock(N); cuEncode << 此外,在核函数中,本文使用共享内存用于一个线程块中所有线程的通信,共享内存的变量作为中间变量,存储累加和,即将同一个线程块中所有线程的计算结果累加到该变量中。由于核函数访问共享内存的速度比全局内存快10倍,因此,使用共享内存可以减少一个线程块中所有线程的内存访问时间,加快编码。 以上是本文设计GPU编码时,从变量存储方面做的一些优化。接下来,本文将实现GPU编码核函数。设m为一个信息序列向量,相应的码字为c,由于QC-LDPC码是一种线性分组码,则有 c=mGqc (10) 根据前面的论述及(10)式,GPU编码核函数的伪代码如下。 算法:GPU并行编码。 输入:函数传入N个信息序列保存在CUDA全局内存数组mess[N×k]中。 输出:最后得到的N个码字输出到数组code[N×n]中。 1)定义共享内存数组,即__shared__ Bitset codTmp[q],并将其初始化为全零。 2) __syncthreads(),同步所有线程块。 3)bTmp←generatorMtx[threadIdx.x][threadIdx.y] 4)if threadIdx.x>= t-q then //计算第threadIdx.x个线程块处理的信息 //序列对应的起始位置bitLoc,其中qNum[i]为 //(9)式中得到的数据,k为信息位长。 for j←bitLoc to bitLoc + qNum[i]-1 do loc ← j + k × blockIdx.x; if mess[loc] == 1 then //异或相加 codTmp[threadIdx.y]← codTmp[threadIdx.y]⊕bTmp; end if bTmp向右循环移动一位; end for else bitLoc ← threadIdx.x × b; //计算存放码字的起始位置messLoc, //用于存放信息比特。如果校验矩阵H满秩, //则得到系统码,否则码字中仅前一部分 //比特为信息比特,n为码长。 messLoc←threadIdx.x×b+n×blockIdx.x; for j←bitLoc to bitLoc + b-1 do loc←j+k×blockIdx.x; if mess[loc] == 1 then codTmp[threadIdx.y]← codTmp[threadIdx.y]⊕bTmp end if bTmp向右循环移动一位; if threadIdx.y == 0 then code[messLoc]←mess[loc]; ++messLoc; end if end for end if 5) __syncthreads(),同步所有线程块。 6) if threadIdx.x == 0 then messLoc←blockIdx.x×n+(t-q)×b +threadIdx.y×b; for i←b-1 to 0 do code[messLoc]←codTmp[threadIdx.y][i]; ++messLoc; end for end if 上述核函数中,参数的含义如表1。threadIdx,blockIdx为CUDA中索引当前线程和当前线程块的变量。__syncthreads()为CUDA中同步所有线程的函数。 调用上述核函数产生N个码字保存在数组code[N·n],code数组中码字的排列方式如图2。 图2 数组中N个码字的排列方式Fig.2 Arrange of the N codes in the array 本文仿真采用Nvidia TITAN Xp显卡平台,使用英伟达官方工具集CUDA Toolkit 9.2,在Visual Studio 2017下编译程序,平台其他参数如表2。 表2 仿真电脑配置 实验中测试了码长从几百到一万多比特的几种高码率QC-LDPC码。相应校验矩阵大小及Tanner图的边数如表3。 表3 仿真用的QC-LDPC码 为了评估编码算法的性能,本文计算了编码吞吐量Kraw,其粗略计算式为 (11) (11)式中:tim为对一个码字编码平均所用时间,单位为s;messLen为该QC-LDPC码的信息位长,单位为bit。 在进行GPU编码时,本文为核函数分配N个线程块,N为32的倍数,运行一次核函数编得N个码字。本文测试了随着N的增加,GPU编码吞吐量的变化情况,仿真结果如图3。 图3 核函数分配不同线程块后的编码性能Fig.3 Encoding performance with kernel function assigneddifferent number of thread blocks 从仿真结果来看,随着N的增大,这几种QC-LDPC码的吞吐量在前期增加较快,但在N大约增加到20×32后,编码吞吐量不再增加,且在一个范围中波动。这是由于前期GPU存在很多空闲资源,随着N的增大,分配给核函数的线程增多,核函数运行一次同时编得的码字增加,吞吐量增加,编码效率明显提高。但后期,GPU中使用的常量内存、全局内存、共享内存等资源达到上限,因此,编码吞吐量停止增加。 实验中也将传统的LDPC码近似下三角矩阵编码算法[13]与该GPU加速的编码算法进行了对比。该传统算法是一种串行的CPU编码算法,算法复杂度为O(n),实验结果如表4。 表4 与传统的编码算法对比 从表4可以看出,本文提出的GPU编码算法对于3种不同长度的QC-LDPC码,其编码吞吐量均超过了10 Gbit/s,传统编码算法最高吞吐量为12.1 Mbit/s,远不及本文GPU加速的算法。 目前GPU加速的LDPC码译码器很多,但编码器不多。现有的LDPC码快速编码方案大多是基于FPGA、集成电路的硬件编码方案,接下来本文将分别讨论。 在文献[14]中,作者提出了针对DVB-S2系统中的LDPC码的GPU编码器。该LDPC码的校验矩阵具有图4中的形态结构,其中,黑点处为非零元素,空白处为零元素。具有这种校验矩阵结构的DVB-S2 LDPC码在设计GPU编码器时可以节省更多的存储空间,因而可以同时对更多码字进行编码。 在同样的Nvidia TITAN Xp显卡平台上,文献[14]中的编码器对码长16 200,码率8/9的DVB-S2 LDPC码一次性可以编8 000个码字,编码吞吐量可以达到20 Gbit/s;由图3可知,本文提出的GPU编码器同时对480个(12 769, 12 320)QC-LDPC码字进行编码时,吞吐量为10.174 Gbit/s;最多可同时编码1 344个码字,此时的吞吐量约为8.0 Gbit/s。虽然本文提出的GPU编码器编码速度没有文献[14]快,但本文针对的是一般QC-LDPC码的编码方案,而文献[14]针对的是DVB-S2 LDPC码这种特定码型LDPC码的编码方案。 文献[8]提出了针对任意LDPC码的GPU编码方案。它假设LDPC码生成矩阵为q×s维矩阵,然后直接简单地分配q个GPU线程进行并行编码。该方案没有充分考虑对单个码字编码时的并行处理,导致其编码速度不快。该文献仿真GPU为Tegra K1,在和传统的编码算法[13]进行仿真对比时,文中给出了不同数量码字同时编码的运行时间曲线图,它的编码器仅比传统的编码算法快2~4倍。但从表4可以看出,本文提出的编码器比传统算法[13]快900~40 180倍。 在同其他硬件快速编码器对比时,本文选择了2种较快的硬件编码器:①基于CMOS技术的编码器[10];②基于FPGA的编码器[9]。 文献[10]中提出了一种基于130 nmCMOS技术实现的编码器,是目前针对802.11ac标准的最快的一种CMOS编码器。编码时,该编码器主要通过在QC-LDPC码校验矩阵的列方向上并行化和在电路中引入循环移位寄存器来提高编码吞吐量。该文的仿真结果表明,对于标准中的(1 944, 1 620)QC-LDPC码在100 MHz的频率时可以达到最高7.7 Gbit/s的编码吞吐量。 为了便于对比,本文同样选择了802.11ac标准中的码字进行仿真。802.11ac标准中规定了一系列具有特殊结构的不同码长、不同码率的QC-LDPC码。本文仿真选择了该标准中1/2码率的(648, 324)QC-LDPC码和(1 944, 972)QC-LDPC码,以及3/4码率的(1 944, 1 458)QC-LDPC码和5/6码率的(1 944, 1 620)QC-LDPC码,仿真结果如表5。 表5 与CMOS编码器对比 文献[10]的CMOS编码器可以对802.11ac标准中的所有QC-LDPC码进行编码,但不能对其他QC-LDPC码编码。文献[10]对标准中不同码率的码进行了仿真,但只给出了编码最快的(1 944, 1 620)QC-LDPC码的吞吐量数据。本文中的GPU编码器可以对任意QC-LDPC码编码,本实验中选择了802.11ac中3种码率的QC-LDPC码进行仿真。从表5可以看出,本文的编码器吞吐量最低为5 Gbit/s,最高为9.6 Gbit/s。且对于(1 944, 1 620)QC-LDPC码,本文的编码器比文献[10]的CMOS编码器提高了1.9 Gbit/s的吞吐量,效果明显。 FPGA是编码领域中常用的硬件实现技术,目前有很多LDPC码的FPGA编译码器方案,但其中速率较快的方案同样只针对特定的码型或码率的LDPC码,不具有通用性。本文讨论一种2017年提出的FPGA编码方案[9],该方案可以对WIMAX标准(即IEEE 802.16标准)中不同码长、不同码率的QC-LDPC码进行快速编码。 本文选择了WIMAX标准中1/2码率的(1 536, 768)QC-LDPC码和(2 304, 1 152)QC-LDPC码,以及3/4码率的(1 536, 1 152)QC-LDPC码和(2 304, 1 728)QC-LDPC码,文献[9]仿真平台为117 MHz的FPGA平台,仿真结果如表6。 表6 与FPGA编码器对比 文献[9]的FPGA编码器是目前针对WIMAX标准中所有QC-LDPC码通用的最快的FPGA编码器之一,但从表6的仿真结果来看,本文提出的GPU编码器吞吐量是该FPGA编码器的3.94~7.73倍。而且本文提出的编码方案可以对任意QC-LDPC码进行快速编码,通用性更好。 本文首先引入QC-LDPC码具有准循环特性的生成矩阵,用这样的生成矩阵编码,其编码过程中许多步骤可以并行化。同时,GPU具有高速并行运算的特点。因此,本文基于GPU加速,给出了一种针对QC-LDPC码通用的并行编码方案。编码时,GPU一个线程块中多个线程并行编码得到一个码字,本文方案分配了多个线程块同时进行多个码字的编码。此外,在编码过程中使用了共享内存、常量内存等高速片上存储器,缩短了数据访问时间,提高了编码吞吐量。从仿真结果可以看出,目前无论是基于CMOS,FPGA等硬件技术的QC-LDPC码编码方案,还是已有的基于GPU或CPU的软件编码方案都有一定的局限性,它们局限于特殊的码型、码率等,通用性不好。本文提出的GPU编码方案不仅可以针对不同码型、不同码率的QC-LDPC码实现快速编码,通用性好,而且编码速度也有明显的提升。因此,本文提出的GPU加速编码器在实际的高速编码系统中有很好的应用前景。2 QC-LDPC码的GPU编码

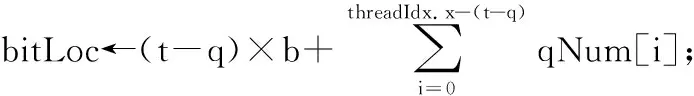

3 GPU编码的仿真分析



4 同其他GPU加速的编码器对比
5 同硬件快速编码器比较

6 结 论
