基于油菜角果长度图像识别的每角粒数测试方法
2021-03-11姚业浩李毅念陈玉仑丁启朔何瑞银
姚业浩,李毅念,陈玉仑,丁启朔,何瑞银
(南京农业大学工学院,南京 210031)
0 引 言
油菜是中国油料作物的典型代表[1],角果是油菜的重要存储器官[2]。在油菜生长发育后期,叶片已大部分凋零,角果便成了主要的光合作用器官[3]。研究表明角果长度是影响产量的重要因素且与产量和每角粒数呈极显著正相关[4-5]。每角粒数是决定油菜产量的重要因素之一[6],也是育种考种和产量估测的重点研究对象[7]。
社会经济的发展对油菜作物产量和品质的要求不断提高,大量油菜育种和产量估测等相关性状参数的测试成为油菜种植和新品种选育必要的工作内容,目前,油菜育种和产量估测以人工方式获取,测试效率低下。图像处理技术的发展为油菜育种考种和产量估测等提供了有力的技术支撑,徐胜勇等[8]提出了一种基于RGB-D 相机的油菜分枝三维重建和角果识别定位方法,角果数量总体识别正确率不小于96.76%。汪文祥等[9]利用图像处理方法测量了油菜分枝和角果着生角度。史浦娟[10]利用高分辨率的3D 扫描仪获取油菜植株点云数据,对株高、角果数量、角果体积等数据进行了测量。刘仁峰等[11]利用凹点检测技术对平铺状态下交叉黏连的角果进行分割,对分割后的单个角果进行细化得到骨架,计数骨架像素点数并换算成物理长度尺寸,角果长度测量准确度达到了97.1%。
角果长度和每角粒数是2 个重要的油菜产量性状参数,当前,角果长度利用游标卡尺测量,每角粒数的计数方法主要有以下两种,一是直接将角果皮剥开,从角果里取出籽粒后进行计数,该方法破坏了角果的形态且对同一角果样本无法进行重复试验;二是利用角果果皮具有一定透光性的特点,对着光源可以透过果皮看到里面的籽粒从而实现对角果中籽粒的计数,该方法保留了样本的完整性,但长时间的计数会使计数者眼花缭乱,影响计数的准确度且费时费力。
为解决油菜角粒数自动、快速、无损的计数问题,本文利用角果长度与角粒数之间的关系,建立油菜角果长度与每角粒数之间的关系模型,通过图像处理技术获得油菜角果的长度,将角果长度代入关系模型中计算得到该角果中油菜籽粒的个数,以期满足无损、高通量的油菜每角粒数计数的需求。
1 材料与方法
1.1 试验设备
试验设备有PC 机(联想 G50-80,Window10 操作系统,250 G 固态硬盘,12 GB 内存)、中晶扫描仪(型号:Scan Maker E900,上海中晶科技有限公司)。利用扫描仪采集油菜角果图像,Matlab2020 对角果图像进行处理。
1.2 试验材料
试验采用3 个油菜品种,分别为“沣油737”“杨油5 号”“苏油1 号”,试验样本均采自江苏省南京市六合区八百桥,利用剪刀将植株上、中和下部分枝角果剪下后放在实验室自然晾干。3 个品种的供试角果个数分别为206、228、289,其中建模集分别为101、133、199,验证集分别为105、95、90。将角果单层平铺在扫描仪上,在PC 端显示存储油菜角果的图像,扫描参数设置为每英寸300 像素,以“沣油737”为例,其扫描得到的图像如图1a 所示。利用游标卡尺测量角果的长度作为角果实际长度,测量标准为仅测量有籽粒荚果部分,去除果喙和果柄部分,具体如图1b 所示,利用人工计数法获取角果中的籽粒数作为实际每角粒数。
1.3 图像处理方法
单层平铺的油菜角果存在角果间交叉、接触等情况,利用图像处理方法需准确识别出单个角果并测量角果的长度,图像处理算法流程如图2 所示。
1.3.1 图像预处理
图像预处理是图像处理过程中的重要步骤,油菜角果图像经过灰度化、二值化[12]、空洞填充、去除小面积处理后即可得到完整的油菜角果二值图像。由于本文测量角果长度的标准中未包含果柄和果喙,故采用开运算去除角果的果柄和果喙,经上述预处理后的油菜角果图像如图3 所示。
1.3.2 图像细化
图像细化就是将物体变成骨骼且该骨骼线(细线)位于物体的中心位置[12],细化后的二值物体和形状仅为单个像素宽的线[13-15]。图像细化后保留了图像原有的基本形状特征并使其他信息得到进一步的简化。由于油菜角果图像的边缘会有少量的粗糙部分,故细化后的油菜角果图像存在一定的毛刺,对每条骨骼线去除5 个像素点,达到去除毛刺的目的。
1.4 端点和交点检测
1.4.1 击中击不中变换
为准确识别出经预处理和细化后角果端点和交叉点,角果图像中的端点和交点是具有像素特定的形状,孤立的前景像素或者是线段的端点像素[15],利用击中击不中变换[16]对其端点和交点进行检测。
1.4.2 使用查找表
当击中或击不中结构元素较小时,计算击中击不中变换较快的方法是使用查找表。要使用查找表就要给每个可能出现的形状分配一个唯一的索引,本文所采用的检测模板为3×3 形状的结构元素,二值图像中每个位置可能的值只有0 和1,所以该检测模板共有512(29)个不同的形状。为了给每个形状分配一个唯一的索引值,将该形状的元素与下面的矩阵相乘:
将乘积累加起来即可为每个 3×3 的形状在[0,511]中分配一个唯一的值。线段的端点在其8 连通域内除其本身外只能存在一个1,即该处模板元素和为2 且模板中心点为1,以此为依据构造一个长度为512 的列向量查找表,计算每个模板的索引值并加1(将索引值变为[1,512]),满足端点条件的在查找表对应位置上置1,反之置0,最终生成的查找表如表1 所示。
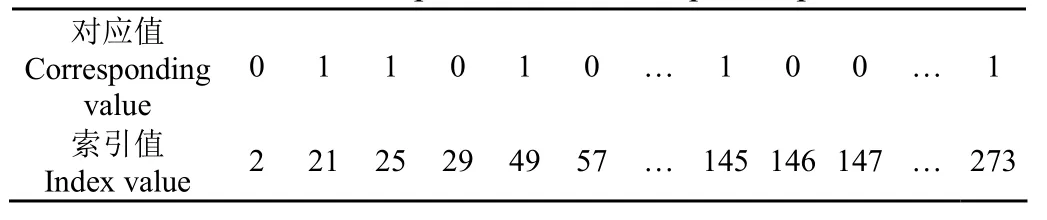
表1 角果端点查找表Table 1 Lookup table for the silique endpoint
1.4.3 端点扫描
扫描是一个寻找的过程,将3×3 形状的结构元素遍历整个油菜角果骨骼图像并计算每个形状内的索引值,然后对应查找表上的值,1 即端点,0 则是非端点。当检测模板采集到某个点的8 邻域时,计算该形状元素所对应的索引值为49,通过查找表可得值为1,所以该点为端点。若计算该形状元素对应的索引值为57,通过查找表可得值为0,则该点为非端点。
端点扫描结果如图4 所示,图中可以看到每个角果的端点均已被识别(“0”所在位置即为识别到的端点位置),表明该方法可准确识别角果的端点。试验发现只需将模板元素的和由2 改为4,即二值图像中线段交点的8 连通领域内像素值的和为4,保持其余条件不变即可有效识别角果之间的交点及其临近的点,在角果交点识别中,该方法识别到的是交点本身及其附近的一簇点,故还需要去除多余的交点。
1.5 DBSCAN 聚类算法
DBSCAN ( Density Based Spatial Clustering of Applications with Noise)聚类算法[17]是一种基于密度的、具有噪声的空间聚类算法,该算法可将具有足够密度的区域划分为簇。与K-means 聚类算法[18]相比,DBSCAN算法具有不需要事先确定聚类中心个数的优点。本文针对油菜角果之间交点的识别结果正是一簇一簇的,故可利用该算法对角果交点进行聚类,从每类簇中选择一个点作为角果的交点并去除该类簇中其余的点即可实现多余交点的去除。
1.5.1 DBSCAN 聚类算法定义
DBSCAN 聚类算法具有以下6 个基本定义[17,19-21]。
定义1Eps邻域:给定数据集D中的某一对象点p,NEps表示为以p为圆心Eps为半径的圆所包含的区域,该区域内所包含的点的集合用公式表示为NEps(p)={q∈D|dist(p,q)≤Eps},其中D⊆Rd,d为空间维度,q为数据集D中的某一个点,dist 表示两点之间的距离。
定义2 核心点、边界点、噪点:假设对象点p∈D,给定的邻域半径为Eps、最小密度点个数minPts,若以p为圆心Eps为半径的圆所包含的区域中点的个数大于等于minPts,则p为核心点。若p不是核心点但是p在另外一个核心点所包含的区域内,则p为边界点,否则p为噪点。
定义3 直接密度可达:给定对象点p∈D、点q∈D,若点q在以点p为圆心Eps为半径的区域内且p为核心点,则称由p到q是直接密度可达的,公式表示为q∈NEps(p),|NEps(p)|≥minPts。
定义4 密度可达:在数据集D中,有对象链p1,p2,…,pn,且p1=q,pn=p,对于任意一点pi∈D(1≤i≤n),若在给定的Eps、minPts条件下,pi+1从pi直接密度可达,则p从q密度可达。
定义5 密度相连:给定对象p∈D、q∈D、o∈D,若在给定的Eps、minPts条件下,p和q都可以从o密度可达,则p和q是密度相连的。
定义6 簇:以核心点为中心,所有密度可达的点构成一个簇。
1.5.2 DBSCAN 聚类算法流程
DBSCAN 聚类算法流程[19]如图5 所示。
利用DBSCAN 聚类算法(Eps=80、minPts=2)对油菜角果交点进行聚类成簇,Eps的初始值可由试验测试的方法选择一个最佳值Eps0,利用公式(1)可获取不同图像的Eps值。
式中S0为选取最佳Eps值Eps0时所使用的图像像素数;S为新输入待测图像的像素数。
从每簇中选取第一个点作为交点,舍弃其余点即可实现去除多余的交点,如图6 所示。
1.6 端点配对
油菜角果的端点和交点已全部被识别出来,接下来就是实现角果两端点之间的配对,配对的结果要求图像中匹配的两端点是某单角果实际的两端点,此时该两端点之间的距离即是该角果的长度。在整幅平铺状态下油菜角果的图像中,由于角果端点众多,正确配对难度过大,故以连通域为单位提取角果子图像,再对子图像中的角果端点进行配对以降低匹配难度,提高配对准确度。按照子图像端点的个数m和交点的个数n来进行分类。
1.6.1 单角果型
m=2 且n=0,此类型的端点配对是最为简单的类型,只需要直接连接两个端点即可实现正确的配对,配对结果如图7a 所示。
1.6.2 双角果交叉型
m=4 且n=1,此类型的角果图像如图7b 所示,角果图像中有4 个端点,分别为a、b、c、d,假设其坐标分别为(x1,y1)、(x2,y2)、(x3,y3)、(x4,y4)。由排列组合可知,此4 点可组成3 种不同的配对结果,分别为(ad,bc)、(ab,dc)、(ac,bd),显然只有(ac,bd)组合才是正确的配对结果。要使配对结果只能是(ac,bd)组合,需求出配对后两直线之间的交点,交点在4 个端点所围成的四边形内部的组合即为(ac,bd)组合。以(ac,bd)组合为例,交点的求法由公式(2)实现,通过求解方程组可以得到交点(x,y)。
交点在4 个端点所围成的四边形内部的条件为xmin≤x≤xmax且ymin≤y≤ymax,其中xmin为4 个端点中横坐标最小值、xmax为4 个端点中横坐标最大值、ymin为4 个端点中纵坐标最小值、ymax为4 个端点中纵坐标最大值。配对结果如图7c 所示。
1.6.3 普通型
除上述两种类型外,其余皆按普通型处理,普通型角果图像的特点表现为角果交点多且分布无序,故而配对难度高。首先,选择任意角果交点o为原点,从o点向任意两端点a、b作oa、ob(如图8a 所示),并计算oa、ob之间的夹角θ(0°≤θ≤180°)。
根据角果本身笔直的特性,若端点a、b满足θ≥170°且ξ≥0.90,则端点a、b即为某角果的两个端点,连接两端点即可得到该角果的长度。配对结果如图8b 所示,由此可见,该条件并不适应于所有的角果,因为不是所有的角果都是笔直的,但该条件可以实现优先对端点明显且笔直的角果的正确配对,从而降低后续配对的难度。对未配对的端点进行再一次的配对时,需要降低配对条件,降低的标准为θ每次减少10°,ξ每次减小0.1,即第二次配对时,未配对的两端点只需满足θ≥160°且ξ≥0.80。以此类推直至条件降至θ≥120°且ξ≥0.40 时,结束端点配对。配对结果如图8c 所示,通过多次配对之后,两端点全被识别出来的角果均已完成正确配对,但仅识别到一个端点的角果仍未配对。此类角果的端点与其他角果相交后形成了交点,故此类角果的配对方式应为端点与交点的配对,配对条件为ξ≥0.95,在所有满足条件的交点中,选择距离端点最远的交点配对。若一次配对后仍有未配对的端点,降低配对标准后进行二次配对直至所有端点均被配对时,结束配对,配对结果如图8d 所示,整幅平铺状态下油菜角果图像端点配对结果如图9所示。
1.7 角果长度及籽粒数计算
1.7.1 角果长度计算
假设已配对的角果两端点的坐标为(x1,y1)、(x2,y2),通过公式(4)即可得到该角果的长度像素数d。
在建模集中油菜角果的长度为物理尺寸长度,故需将长度像素数d转化为物理尺寸长度d′。首先,在同等扫描条件下扫描一张A4 纸张并对其拟合最小外接矩形,求出该矩形的长和宽(l、w)即为A4 纸的长和宽像素数,利用公式(5)即可求出转换比例k。
角果的物理尺寸长度即为d′=kd(mm)。
1.7.2 角果籽粒数计算
将得到的角果长度d′代入油菜角果长度与籽粒数之间的线性关系模型中即可得到油菜角果中的籽粒数。在验证算法准确度时,扫描后的角果先留在扫描仪内保留其位置不发生变化,待图像处理完成后,在同一位置找到图像上的角果和实际对应的角果,记下测量值和实际值。
2 结果与分析
2.1 角果长度与每角粒数之间的关系
利用建模集角果长度和每角粒数数据建立相关性模型,角果长度与每角粒数之间的关系如图10 所示,3 个品种的油菜角果的长度与每角粒数之间相关性决定系数(R2)分别为0.891、0.881、0.887,表明油菜角果每角粒数与其长度具有相关性。此结果可为通过角果图像来获取角果粒数提供依据,即获取图像中角果的长度并代入角果长度与每角粒数之间的相关性模型中即可得到对应的每角粒数。
2.2 角果长度识别结果分析
利用验证集角果长度数据对角果图像识别角果长度数据进行检验,通过角果的长度来预测每角粒数,故角果长度识别的准确度直接影响预测每角粒数的准确度,以人工测量长度为角果的实际长度,利用本文所提出的图像识别方法,对3 个品种的油菜角果长度的识别结果与角果实际长度对比分析,如图11 所示。3 个品种的油菜角果识别长度与实际长度决定系数(R2)均在0.97 以上,最大RMSE 仅为2.637 mm,说明本文提出的油菜角果长度识别方法能准确的识别平铺状态下油菜角果的长度。
由表2 可知,3 个品种的油菜角果长度识别平均绝对误差分别为1.35、0.78、2.13 mm,平均相对误差分别为2.60%、2.35%、3.29%,3 个品种的油菜角果长度识别平均准确度为97.25 %。表明本文提出的端点检测配对方法能实现油菜角果长度高通量、准确、自动的识别要求。
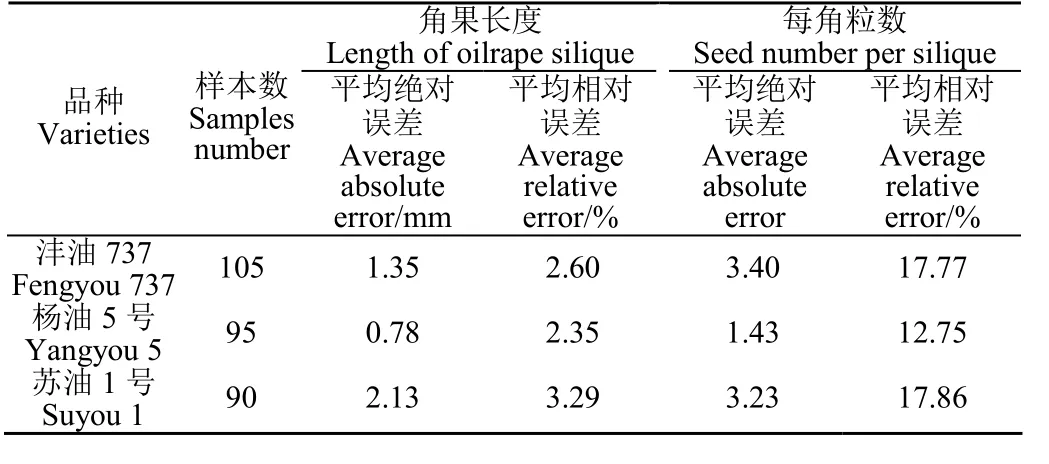
表2 油菜角果长度和每角粒数识别结果误差分析Table 2 Error analysis of recognition results for length of oilrape silique and seed number per silique
2.3 角果每角粒数预测结果分析
利用验证集角果每角粒数数据对图像识别角果籽粒数数据进行检验,通过将识别到的油菜角果长度信息代入对应品种的油菜角果长度与每角粒数之间的相关性模型中即可得到每角粒数,以人工计数为实际每角粒数,3 个品种的油菜每角粒数预测结果与实际每角粒数对比分析如图12 所示。3 个品种的油菜角果图像预测每角粒数与实际每角粒数之间的决定系数(R2)均在0.84 以上,最大RMSE 为4.174 粒,说明本文提出的油菜每角粒数图像识别方法可行。
由表2 可得,3 个品种的油菜每角粒数预测平均绝对误差分别为3.40、1.43、3.23 粒,平均相对误差分别为17.77%、12.75%、17.86%,3 个品种的油菜每角粒数总体平均相对误差为16.13 %,平均预测准确度为83.87%。
3 讨 论
目前研究表明油菜角果性状参数长度与单株油菜产量、籽粒数量等存在一定的相关关系,有文献分析了单株油菜部分角果长度平均值或者一个种类油菜角果长度与其平均角果籽粒数量之间的相关性[4,22],本研究从油菜植株单个角果长度与其籽粒数量之间相关关系的角度进行分析,因此本研究中的油菜品种角果长度与每角粒数之间的决定系数值(R2)均较相关文献[4,22]报道的大。
本文在对油菜角果性状参数长度与籽粒数量存在一定的相关关系研究的基础上提出了利用图像识别角果长度并计算出角果每角粒数的测试方法,通过本研究发现每角粒数预测平均准确度为83.87%,能够满足目前育种和估测产量时对每角粒数测量的精度需要。
本研究中将油菜每角粒数计数中人工剥角果荚壳、籽粒计数等工作采用图像方法批量一次性获取,大大降低每角粒数数据获取的时间和人工成本。图像获取方法能够快速准确获取油菜每角粒数,同时节约大量人工,有利于满足现阶段油菜育种和产量预测大量样本测量的需求。从本研究结果来看,油菜角果长度尺寸预测每角粒数有一定的优势,但预测精度仍然有提升的空间。
4 结 论
通过人工测量了角果的长度与每角粒数并建立了角果长度与每角粒数之间的关系模型,结果表明,3 个品种的决定系数均大于0.88,说明可利用角果的长度来预测角果中的籽粒数。
通过扫描仪获取平铺状态下油菜角果的图像,对图像预处理后识别角果的端点和交点并利用DBSCAN 聚类算法去除了多余的交点,根据每个子图像中角果的类型选择对应的端点配对法则识别出对应的角果,利用两点之间的距离公式求出角果的长度,再将角果长度代入角果长度与每角粒数之间的关系模型中得到对应角果的籽粒数,结果表明:3 个品种的油菜角果长度识别平均准确度为97.25%,说明本研究提出的角果长度图像识别方法是可行的,且与人工测试角果长度结果非常接近。
经图像识别方法获取角果长度尺寸,利用角果长度与每角粒数之间的关系模型可对油菜角果每角粒数进行预测,每角粒数预测平均准确度为83.87%,表明本文提出的油菜角果长度识别算法和油菜每角粒数预测算法准确、可行。通过获取整株油菜单个分枝上油菜角果平铺状态下的图像,利用图像处理方法可快速获取角果的长度尺寸,并利用角果长度与每角粒数之间的关系模型计算出角果每角粒数,可快速估测出分枝上所测角果的角果籽粒数量,依次获取整株油菜各分枝角果图像,可快速获取整株角果籽粒数量。
