基于码元密度检测的帧同步码盲识别算法
2021-03-09雷迎科吴子龙
熊 颢,雷迎科,吴子龙
(国防科技大学电子对抗学院,安徽 合肥 230037)
0 引言
现代军事通信技术正处于飞速发展阶段,瞬息万变的战场环境提高了通信对抗实时侦察的难度。为了可靠地获取敌方通信信息,作为非合作方,首先需要有效分帧并最终完成目标通信链路的协议解析[1]。数据传输按照协议规定的帧格式进行发送与接收,为了保证从接收到的信息序列中正确恢复通信信息,必须解决帧同步码识别的问题。因此,研究一种有效的协议帧同步码识别算法具有重要意义。
非合作方需要在未知同步字段内容和帧结构的条件下提取协议同步信息,属于盲识别问题[2-5]。国内外对于链路层协议帧同步码识别的研究,主要分为等帧长和非等帧长同步字识别两种情况。传统算法以高阶统计处理技术为主,文献[5—7]提出了二次搜索法在特定步长下进行搜索同步码;文献[8]提出的模糊匹配算法,分别利用小区域检测和相关滤波估计帧长和帧起始位置;文献[9]推导出基于硬判决的帧同步字盲识别算法,并利用改进的基于软判决的算法提高精度;文献[10]提出了基于数据挖掘的比特流切分算法。
上述算法能够实现对同步码字的准确识别,但都只应用于等帧长问题,算法实用性具有一定的局限性。针对非等帧长的情况,文献[11]提出了基于多重分形谱的帧同步码识别算法,算法较复杂不具备时效性;文献[12]提出了基于相关滤波和离散度分析的帧同步识别算法;文献[13]提出了基于帧结构遍历的帧同步识别算法,需要一定先验信息,不符合盲识别的条件。
针对军事通信对抗领域中传统未知协议帧同步码识别算法应用局限、复杂度高以及盲识别难度大等问题,本文在有偏性分析的基础上提出基于码元密度检测的链路层帧同步码盲识别算法,该算法适用于未知帧结构的盲识别条件。
1 链路层协议帧结构
1.1 帧结构介绍
为了保证通信系统的可靠性和有效性,并且同时兼顾战场信息传输的隐蔽性和安全性,各协议比特流都在链路层封装成帧并进行传输。一段完整的协议帧包括同步字段和信息字段,同步字段用于数据帧同步,信息字段负责承载高层传输数据包,各协议帧无缝连接组成比特流进行传输。同步字段必须使用专门指定的控制字符,来保证透明传输和避免出现帧定界错误的问题。协议帧一般形式如图1所示。
图1 协议帧结构Fig.1 The structure of the protocol frame
1.2 序列码元密度
假设接收序列长度为l,包含p个元素,其中非零元素个数为q。二进制序列的汉明重量等于该序列中非零元素的个数,即m=q。
定义序列的码元密度ρ,其值等于该序列汉明重量与长度的比值。二进制比特流数据包含的元素具有二元性,其中1的出现概率v等于非零元素个数与序列元素总数的比值。因此,二进制序列的码元密度与序列中1出现的概率在数值上相等。
(1)
根据协议帧的结构特点,设同步字段的码元长度为l1,码元密度为ρ1;信息字段的码元长度为l2,码元密度为ρ2。得到全帧的码重为:
m=ρ1l1+ρ2l2
(2)
由此计算出全帧的码元密度:
(3)
1.3 协议帧有偏性分析
二进制序列的有偏性被用来描述反应序列中01比特的分布情况[14]。若二进制序列中1出现的概率为v,则序列的有偏性定义为θ=1/2-v。
为了保证传输数据的可靠性,信息字段必须采用差错控制技术,目前数据链路层广泛使用加入循环冗余码来进行检错。根据协议的不同,使用的编码方式也不同,部分协议子层还会进行伪随机化处理[15-16]。信道编码能够降低序列有偏性,同时序列经过伪随机化之后有偏性进一步降低[17]。因此,在连续的协议帧比特流中,同步字的有偏性大于帧。
假设接收到协议帧数据为R=(r1,r2,…rl1+l2),令同步字段有偏性为θ1,信息字段有偏性为θ2,如图2所示。
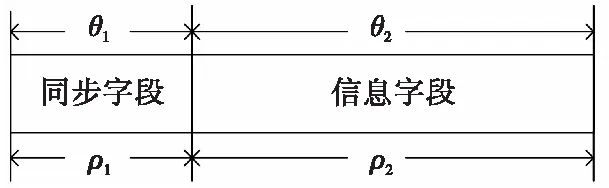
图2 协议帧信息Fig.2 The Information of protocol frame
根据式(1)可求得同步字段的码元密度如式(4):
(4)
同理,信息字段的码元密度如下式:
(5)
由于信息字段有偏性小于同步字段,可知同步字段的码元密度小于信息字段。将式(3)化简得到全帧的码元密度如式(6):
(6)
根据上述分析可知ρ1<ρ2,带入式(6)可知协议帧的码元密度大于同步字段,即ρ>ρ1。
2 基于码元密度检测的帧同步码盲识别算法
2.1 有效性分析
在数据链路层协议帧中,一般来说同步字段的长度与信息字段成正比,传输数据量越大的协议帧,同步字段也相对越长。但实际应用中,待识别序列中信息字段的长度远大于同步字段的长度,因此同步字段在比特流中的浓度很低,导致识别困难。
根据对协议帧有偏性的分析,得到了协议帧的码元密度大于同步字段的结论,以此为依据,对接收序列中的信息字段进行删减,通过对比删减前后协议帧数据码元密度的变化实现提高同步字段浓度的目标,从而完成识别,下面对其进行理论推导与有效性分析实验。

(7)
选取四组长度相等的GSM协议接入突发协议帧[18]作为删减有效性的对比实验数据,相关参数如表1所示,分别做无删减、只删减同步字段、只删减相同长度信息字段和随机删减的处理。选取50帧共7 800 bit上述协议帧数据,根据删减数量的增加,计算帧码元密度变化,结果如图3所示。

图3 删减有效性实验Fig.3 Validity test
图3中虚线表示无删减的原始序列码元密度。从图中可以看出,当大量删减同步字段时,数据的码元密度增大;对信息字段进行删减时,码元密度下降,但由于信息字段长度远大于同步字段,下降速度慢且删减数量较小时,变化不明显。对序列进行随机删减时,信息字段长度更长,删减点落入其中的概率更大,当删减量较小时,码元密度曲线在虚线下方。

表1 五种待识别协议帧的特征
2.2 算法步骤
本文所提算法利用序列码元密度的分布进行删减,使待识别序列中同步字段的浓度得到有效提高,从而完成识别,其步骤如下:
步骤2 随机选取50个分割段进行删减,计算剩余序列码元密度ρ1,比较ρ0和ρ1的大小,若ρ0>ρ1则在此基础上继续进行删减并计算得到ρ2,反之则重新进行步骤2;
步骤3 重复步骤2和步骤3,直到完成100次删减得到ρ100;
步骤4 将删余的分割段转换成相对应的十进制数,统计各十进制数的数目。浓度最大的十进制数对应的字符串为同步字或同步字的一部分,完成识别。
3 仿真实验与结果分析
实验数据选取自GSM全球移动通信标准中的常规突发协议帧、局域网链路层802.3协议帧、TC空间数据链路协议和采集自数据模拟器的导弹制导数据链前向链路数据帧,相关参数如表1所示。
3.1 理想条件下同步字段识别
对每种数据帧分别仿真产生105bit序列。在实际通信系统中,集中插入式帧同步码的长度一般不会小于2 Byte,设置分割长度为τ=10 bit,每次删减50个分割段,一共删减100次,随着删减次数的上升,每种协议帧数据的码元密度变化如图4所示。
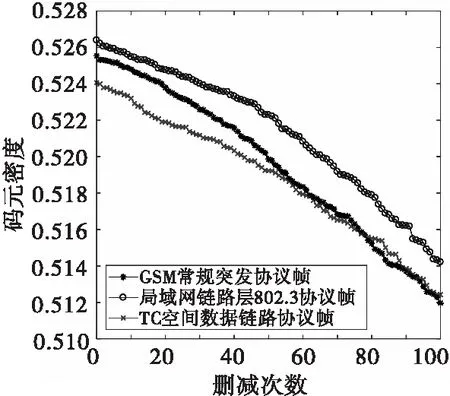
图4 码元密度检测Fig.4 Symbol density detection
删减完成后,将剩下的分割端转成十进制以便于浓度检测,检测结果如图5所示,从上到下依次是GSM全球移动通信标准中的常规突发协议帧、局域网链路层802.3协议帧和TC空间数据链路协议的最大字符串检测结果。

图5 字符串浓度检测Fig.5 String concentration detection
由图4可知,随着删减次数的增加,三种不同协议帧的码元密度逐渐下降,因此数据序列中的信息字段被删减,同步字段的浓度得到有效提高。由图5可知,GSM全球移动通信标准中的常规突发协议帧、局域网链路层802.3协议帧和TC空间数据链路协议中浓度最大的字符串分别为151、682和92,对应的二进制序列分别为0010010111、1010101010和0001011100。由表1可知,上述实验的识别结构能够正确匹配三种协议帧同步字段。
3.2 误码条件下同步字段识别
在误码率为5%的条件下,再次对GSM全球移动通信标准中的常规突发协议帧、局域网链路层802.3协议帧和TC空间数据链路协议分别仿真产生105bit序列。分割长度设置为10 bit,每次删减50个分割段,一共删减100次。删减完成后将分割段进行十进制转化,统计不同十进制数出现的次数作为浓度值检测的依据,检测结果如图6所示。
在其余仿真参数相同的条件下,误码率的提高直接影响十进制数的浓度检测值,从图6中可以看出尽管字符串的检测浓度峰值有所下降,但检测结果仍与无误码条件一致,说明识别结果正确。

图6 误码条件字符串浓度检测Fig.6 String concentration detection under error code condition
3.3 切分长度性能分析
分别选取105bit的TC空间数据链路协议帧序列和导弹制导数据链前向链路协议帧序列,研究不同切分长度对于检测算法的影响,其中TC空间数据链路协议帧数据由仿真产生,导弹制导数据链前向链路协议帧数据采集自数据链模拟器,如表1所示。
分别进行分割段长度为10 bit和16 bit的同步字段检测实验,每次删减50个分割段,控制删减比特总量一致,随着删减次数的增加,不同协议码元密度的变化如图7所示。

图7 切分长度对性能的影响Fig.7 The effect of cutting length on performance
删减完成后将分割段进行十进制转化,统计各十进制数出现的次数作为浓度值检测的依据,检测结果如图8,从上到下为分割段长10和16bit下的TC空间数据链路协议帧、分割段长10和16 bit下的制导数据链前向链路协议帧的字符串浓度检测结果。

图8 字符串浓度检测Fig.8 String concentration detection
由图7可知,随着删减次数的上升,两种协议帧的码元密度呈现下降趋势,并且分割段长度越长,码元密度下降越快,同步字段浓度提高的越快。由图8可知,在分割段长度较长时,字符串浓度检测中出现的浓度峰越少且峰值提高,越有利于同步字段的检测,可以有效地提高检测精度。
3.4 算法性能对比
现有的协议帧同步字段识别算法主要有模糊匹配算法、基于分层的矩阵秩算法和多重分形谱算法,对比本文算法和上述三种算法在不同误码条件下对协议帧同步字段的识别性能实验,选取105bit GSM全球移动通信标准中的常规突发协议帧序列作为实验数据各进行1 000次蒙特卡洛实验,实验结果如图9所示。

图9 算法对比实验Fig.9 Contrast experiment
如图9所示,在误码率达到2%时,模糊匹配算法抗误码性能较差,识别概率显著下降,其他三种算法的识别率仍能保持在75%以上;在误码率达到2%时,模糊匹配算法的识别概率几乎为0,高阶统计处理技术的识别概率下降到40%,多重分形谱算法和本文算法的识别结果相对较高;随着误码率的进一步增大到10%,模糊匹配算法、高阶统计处理技术合多重分形谱算法的识别概率均低于5%且趋近于0,本文算法的识别概率仍保持在在10%以上。因此随着误码率的升高,本文算法的识别率均高于模糊匹配算法、高阶统计处理技术和多重分形谱算法。
4 结论
本文提出一种基于码元密度检测的链路层协议帧同步码盲识别算法。该方法首先分析协议帧的有偏性,给出序列码元密度的定义,然后通过理论推导得到了协议帧的码元密度大于同步字段码元密度的结论并通过算例验证正确性,最后利用这一结论,对未知协议帧序列进行删减,达到增大序列中同步字段的浓度的目的,完成特定长度字符串的浓度检测,实现对未知协议帧同步字段的准确识别。仿真实验结果表明,该算法在理想条件和误码条件下均能准确识别未知协议帧同步字段,对比传统算法识别效果更好,对误码率有较高的容错性能,具有可靠性和有效性。
