一种改进的SSD网络车载图像检测方法
2021-03-08鲍润嘉侯庆山邢进生
鲍润嘉,侯庆山,邢进生
(山西师范大学 数学与计算科学学院,山西 临汾 041000)
0 引 言
计算机视觉中图像识别技术的发展为无人驾驶领域中的检测识别提供了便捷的通道。当前目标检测技术结合卷积神经网络(convolutional neural networks,CNN)在对车载图像识别等方面的研究也越来越深入。目标检测应用于智能交通是未来进一步的研究热点。
众多国内外学者为了解决目标检测中存在的问题,相继做了大量研究工作。2014年,Ross Girshick等人提出了R-CNN[1]算法,该算法首次将CNN引入目标检测领域。R-CNN通过利用在输入图像上提取的候选框,将候选区域缩放成固定的特征传入CNN中进行特征提取,最后将提取的特征输入到分类检测器中实现图像上目标的检测分类。该算法的检测效果相较于传统的目标检测算法[2]有了明显提高,但是该算法的检测过程较复杂,检测效率和检测速度依旧不够理想。于是,Ross Girshick继R-CNN算法之后,在2015年提出了Fast R-CNN[3]算法,针对R-CNN的缺陷进行了相关优化。在此之后Faster R-CNN被Shaoqing Ren等人提出,该方法通过自适应尺度的池化方法对网络进行了优化,使用了softmax[4]进行分类和回归,使得该算法在检测的精确度和速度上都有了一定程度的提升,但是该算法在检测实时性方面仍有不足。针对Faster R-CNN目标检测模型检测实时性的优化问题,在2016年,Joseph Redmon等人提出了YOLO[5]算法,该算法实现了端到端的检测效果,并在检测速率上有所提升。YOLO算法利用CNN全局特征预测可能的目标,规范图像的输入和输出,将最后的目标检测划分成了一个回归的问题。随后两年,YOLO的优化算法YOLO v2[6]、YOLO v3[7]相继提出,针对检测的速度和精确度问题,基于YOLO算法的研究成果,对算法进行了改进并取得明显进步,成为目前表现最优的目标检测算法之一。单发多框检测器(single shot multibox detector,SSD)[8]算法是继Faster R-CNN和YOLO算法之后又一个出众的目标检测算法,该算法由Wei Liu、Dragomir Anguelov等人在2016年提出,结合了Faster R-CNN与YOLO的部分思想,基于多层卷积的输出特征图进行相关目标的检测,提升了算法的整体检测精确度。但由于采用不同尺寸的先验框对输入图像进行特征提取,这种方式会导致部分信息的丢失,相同的目标会被不同的检测框重复检测,模型的检测精度需进一步提高。
通过研究SSD目标检测算法,该文基于传统的SSD目标检测模型,对模型检测精度上的提升做了相关研究及改进,并通过实验表明,改进模型检测精度显著提升。这一改进对无人驾驶领域的未来研究和发展都具有积极意义。
1 SSD网络
SSD算法从结构上可以看作是Faster R-CNN和YOLO算法的结合,借鉴了YOLO算法中基于回归的模式,同时结合了Faster R-CNN的anchor机制。
SSD采用VGG16[9]作为基础骨干网络,并在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。卷积层降低了空间维度和分辨率,为了解决该问题,在多个输出特征图上执行独立的目标检测,并在检测的过程中,使用了许多候选区域作为目标图像中识别出的候选识别区域,最终在实现快速检测的同时也能够较准确的对目标进行定位。SSD算法的网络结构如图1所示。
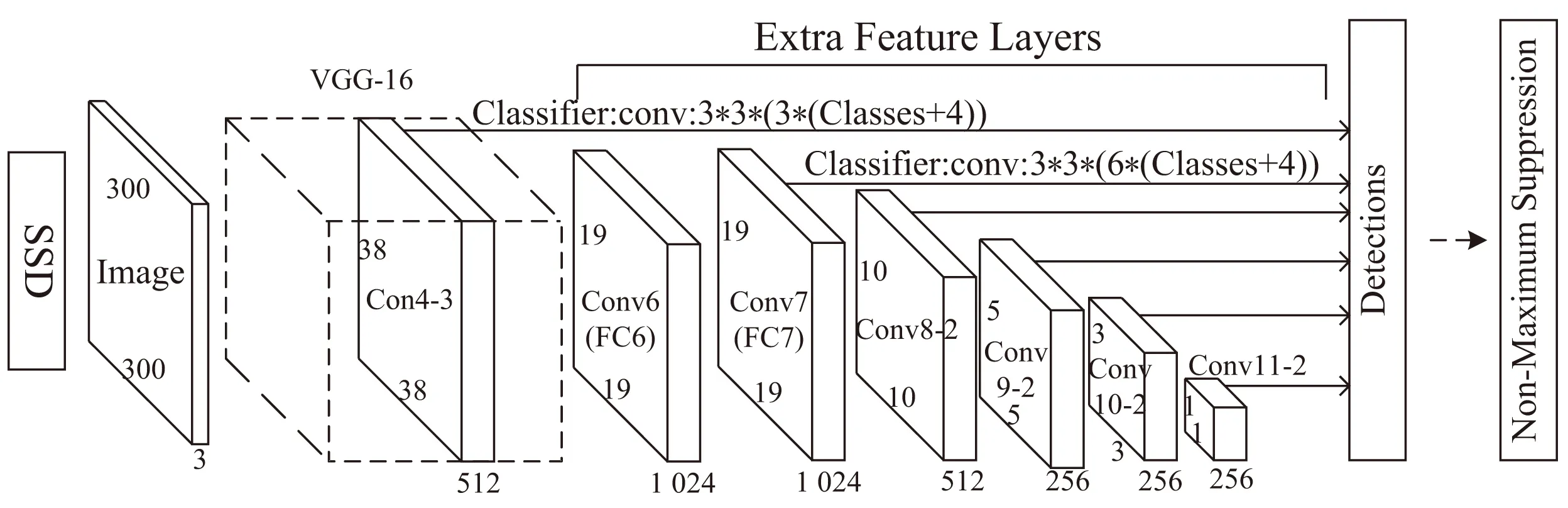
图1 SSD网络结构
2 改进算法模型
针对传统SSD目标检测算法不能充分利用局部特征和全局语义特征、目标定位和识别存在矛盾等缺陷,改进SSD算法将输入图像中待检测目标的低层次细节特征与高层次的语义信息结合起来,降低待检测目标定位与识别间的矛盾,从而重新生成模型的目标检测金字塔。
2.1 改进SSD模型的相关特征融合方法
卷积神经网络对金字塔特征层结构具有良好的特征提取能力,在传统的SSD模型中采用了采样金字塔结构,相关特征层从低到高的表达了输入图像的语义信息。但不足的是,传统SSD模型将位于不同特征层的相关信息作为同一层次的信息,并直接由各检测层产生目标的检测结果和分类,这种方案使检测器缺乏同时捕获局部细节特征和全局语义特征的能力,无法有效提取到相关模型的上下文信息,对输入图像上相关目标的检测极为不利。为改善上述不足,基于传统的SSD目标检测模型,制定了模型相关特征层的融合方法。
目前许多目标检测算法尝试对金字塔特征层结构进行充分利用,如FPN[10]、DSSD[11]等多目标检测算法,方法结构如图2所示,但这种融合方法使得右侧的新特征层只能对左侧相应层次以及更高层次的输出特征进行融合,缺少了底层的特征信息。
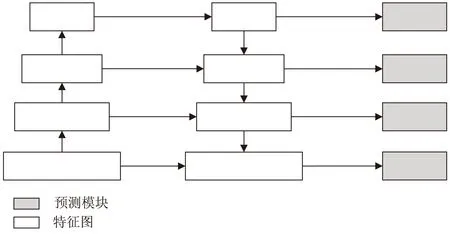
图2 FPN、DSSD等多目标检测算法的金字塔结构
针对传统特征融合方法的不足,改进算法中将不同层次的特征以较为合适的方法进行融合,重新构建目标检测金字塔对输入图像中的相关目标进行检测,改进SSD算法的目标检测算法结构如图3所示。
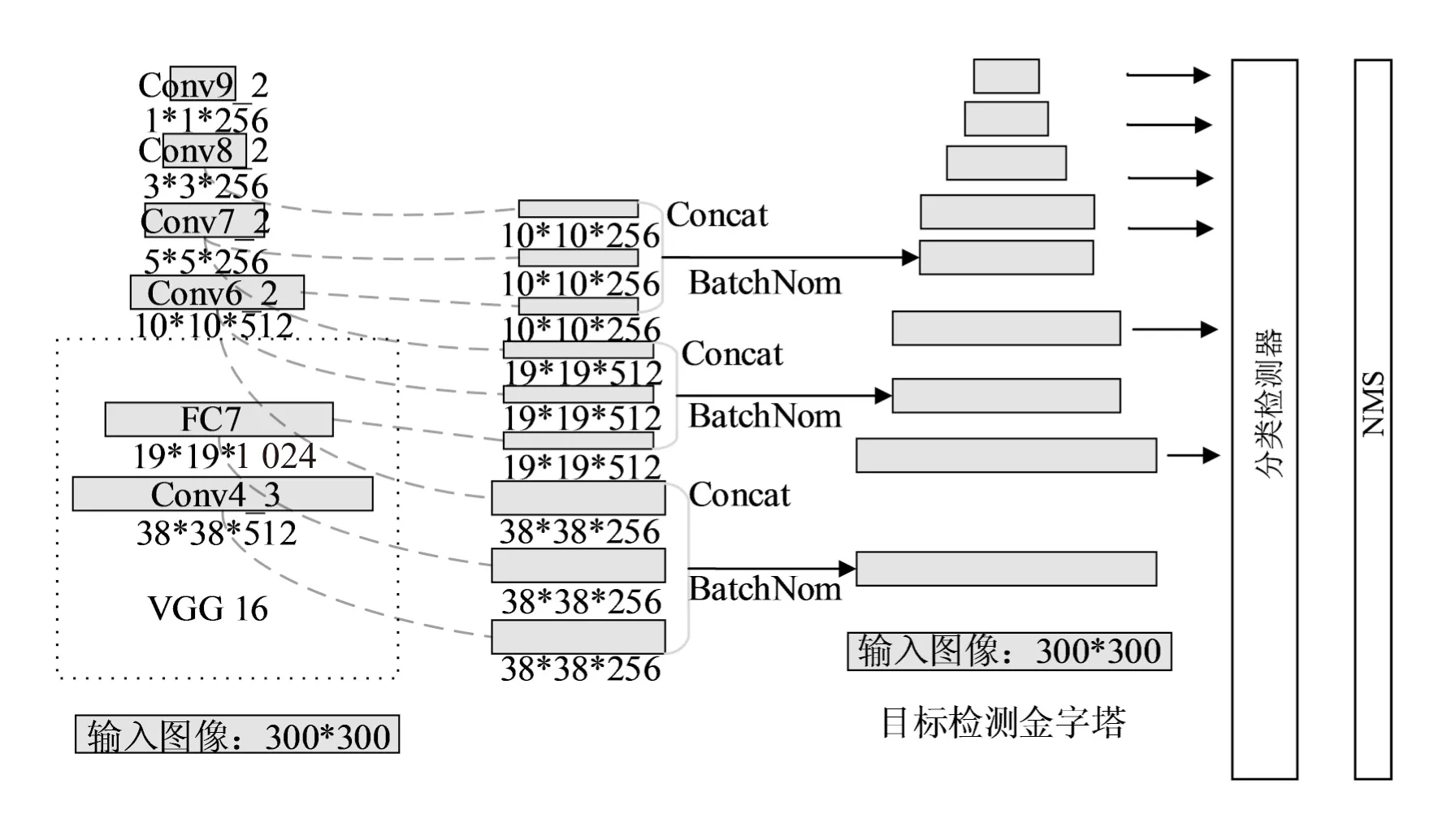
图3 改进SSD算法的特征融合及目标检测金字塔
针对改进算法的目标检测金字塔结构,假设Xi,i∈C表示希望融合的输出特征图,考虑以下几方面因素,具体相关表述如下:
Xf=φf{Ti(Xi)},i∈C
(1)
(2)
(3)
式(1)中C表示参与融合的原输出特征图集合,Ti表示每一个参与融合的输出特征图在进行拼接操作之前的变换函数,即表示对输出特征图进行降采样[12]或上采样[13]处理的方法选择,通过降采样及上采样的处理使模型输出特征图的规模保持一致性,改进模型中采用双线性插值的方法对相关卷积层的输出特征图规格进行统一。φf为相关的特征融合函数,表示对经过统一化操作后的相关特征图进行拼接或元素求和操作,改进模型选用拼接操作将相关输出特征图融合为某规格的输出特征图。式(2)中φp表示改进算法目标检测金字塔的生成函数,P表示参与目标检测金字塔构建的输出特征图集合,即如何运用生成的融合特征图重新构建SSD目标检测算法的相关检测层,也就是目标检测金字塔。式(3)中φc,l表示根据目标检测金字塔进行相关检测的方法。
在传统的SSD目标检测模型中,基于Conv4_3、fc7、Conv6_2、Conv7_2、Conv8_2、Conv9_2的输出特征图进行相关目标的检测。相对应的输出特征图尺寸包括了38×38、19×19、10×10、5×5、3×3和1×1。需要说明的是,由于在Conv9_2的输出特征图中能够被合并的信息太少,因此1×1尺寸的特征输出图并未参与输出特征图的融合,而是直接参与了改进算法目标检测金字塔的构建。
为高效地融合不同尺度的输出特征图,首先,将Conv4_3、FC7、Conv6_2的原输出特征图降维至256,利用双线性插值法[14]将FC7、Conv6_2的输出特征图调整到与Conv4_3相同的38×38尺寸,对处理后的输出特征图进行拼接操作;其次,将FC7的原输出特征图降维至512,Conv6_2输出特征图维度保持不变,Conv7_2维度变换为512,利用双线性插值法将Conv6_2、Conv7_2的输出特征图调整到与FC7相同的19×19尺寸,对处理后的输出特征图作拼接操作;最后,将Conv6_2的原输出特征图降维至256,Conv7_2、Conv8_2输出特征图维度保持原样,利用双线性插值法将Conv7_2、Conv8_2的输出特征图调整到与Conv6_2相同的10×10尺寸,对处理后的输出特征图进行拼接操作。
此外,融合相关输出特征图时主要有两种方法,拼接法以及元素求和的方法,但由于元素求和的方法要求特征映射具有相同的大小,这意味着需要将特征映射转换为相同的通道,这个需求限制了融合特征映射的灵活性,故采用拼接法进行输出特征图融合。
2.2 改进模型的默认框生成方法
改进模型的默认框生成策略采用了原SSD目标检测模型的默认框生成策略,对每一检测层的各单元格设置了不同长宽比的默认边界框。在对相关模型进行测试时,将所有输出特征图上产生的默认边界框结合起来,通过非极大值抑制算法去除部分重叠或错误的边界框,产生最终的检测结果。默认边界框的生成策略如下:
(1)以各输出特征图上的每个像素点为单位进行相关默认框的生成,将最下层输出特征图的Scale值设置为0.2,最上层输出特征图的Scale值设置为0.95,通过式(4)计算剩余输出特征图的Scale值;
(4)
式中,m表示输出特征图的个数,k∈[1,m],Smin、Smax的值分别为0.2和0.95。
(2)设置不同默认框的长宽比ar∈{1,2,3,1/2,1/3},通过式(5)计算默认框的宽度及高度。
(5)

2.3 改进模型的相关标定策略
在对改进模型进行训练时,需要确认输入图像中的真实边界框与哪些默认边界框匹配,主要包含了以下两个方面:
(1)对于输入图像上的默认边界框,首先找到与其IoU值最大的默认边界框,将该默认边界框与真实边界框匹配,保证输入图像上的真实边界框一定能够匹配到某一默认边界框。与真实边界框相匹配的默认边界框称为正样本,相应的,对于不匹配的默认边界框称为负样本。然而输入图像上的真实边界框往往是很少的,但模型产生的默认边界框很多,这样就会产生大量的负样本,从而导致了正负样本的不均衡问题。
(2)针对样本的不均衡问题[15-16],设定IoU的阈值为0.5,对于(1)中未配到的剩余默认边界框,若IoU阈值大于0.5,也将该默认边界框设定为正样本。因此,正常情况下输入图像上的真实边界框通常对应多个默认边界框。
2.4 改进模型的损失函数
改进SSD模型的损失包含了分类损失和边界框回归损失两部分内容,模型的总体损失基于两部分损失的加权和,相关损失可由式(6)表示。
(6)
式中,Lconf表示分类损失,Lloc表示边界框的回归损失,可分别由式(7)、(8)进行表示,α表示回归损失的权重系数。
(7)
(8)

3 实 验
3.1 相关数据集描述
车载图像数据集源于行车记录仪采集,共60 000张不同场景下的图像。选取55 000张图像作为改进模型的训练集,并对其进行标注,剩余5 000张图像作为测试集。
从目前的研究情况来看,不论国内还是国外,对于水在终端使用过程中的能耗特征都缺乏深入、全面的研究,而这一环节的能源强度实际上超过了其他所有环节的能源强度,在这一环节节约用水将有可能以最小的成本带来最大的节水节能效应,这也是需求侧管理思想的核心。因此,水系统水—能关系未来的研究重点应该放在水资源的终端消费领域,探讨家庭、行业节水与节能的相互关系,从而通过需水管理达到水资源和能源的可持续利用,促进城市节能减排与可持续发展。
数据的读取及预处理:
一个网络训练的结果受多因素影响,在训练相关改进模型之前对图像进行预处理。预处理过程如下:
(1)通过TFrecord读取数据集以减少内存消耗,加速模型相关数据集读取。
(2)利用最大值法对图像数据集进行灰度化处理。灰度最大值法可由式(9)表达:
Gray(i,j)=max{R(i,j),G(i,j),B(i,j)}
(9)
(3)对灰度化后的数据集进行图像增强[17]。
改进算法主要研究图像识别在精度上的提升,所以图像质量的好坏直接影响识别算法速率提升的效果,对图像数据集进行上述预处理过程之后,可减少数据集图像中的无关信息。图像预处理效果如图4所示。

图4 图像预处理效果
3.2 相关参数设定
对于改进的SSD检测算法,基于实验采集的相关训练集,在Nvidia 2080Ti GPU的硬件条件下对相关模型进行训练。设置批量大小为32,权重衰减值为0.000 5,随机梯度下降算法[18]的动量值为0.9,改进模型的初始学习率为0.001,训练迭代300 000次;之后将学习率下降至0.000 1,训练迭代600 00次;最后将学习率再次下调至0.000 01训练改进模型,直到模型达到收敛。
另外,在相同的条件下,选取一系列的对比模型进行训练,用于改进模型测试阶段的相关对比。
3.3 实验训练方法描述
针对改进的SSD目标检测模型,可以选择以下三种主流的训练方案:
方案一:改进模型基于传统的SSD目标检测模型,因此可以使用训练好的SSD模型相关参数作为改进模型的初始参数,即将训练好的传统SSD检测算法作为改进模型的预训练模型。对改进模型进行训练时,学习速率可以适当增加,从而加快改进模型的训练。
方案二:与传统SSD目标检测模型的训练方法相同,改进模型不采用任何预训练模型。
方案三:以训练好的VGGNet为基础,对原SSD算法及改进算法进行训练。
观察图5,基于VGGNet预训练网络的改进算法略优于基于传统SSD预训练网络的改进算法。以原SSD算法为预训练网络对改进模型进行训练时,改进SSD模型的收敛速度更快。此外,在相同的训练条件下(传统SSD算法与相关改进算法都基于VGGNet预训练网络进行训练),相较于传统的SSD算法而言,改进算法检测精度更高。此外,为了保证实验结果的准确性,训练目标与原SSD算法保持一致,对原SSD算法采用相同的硬件环境和训练策略。
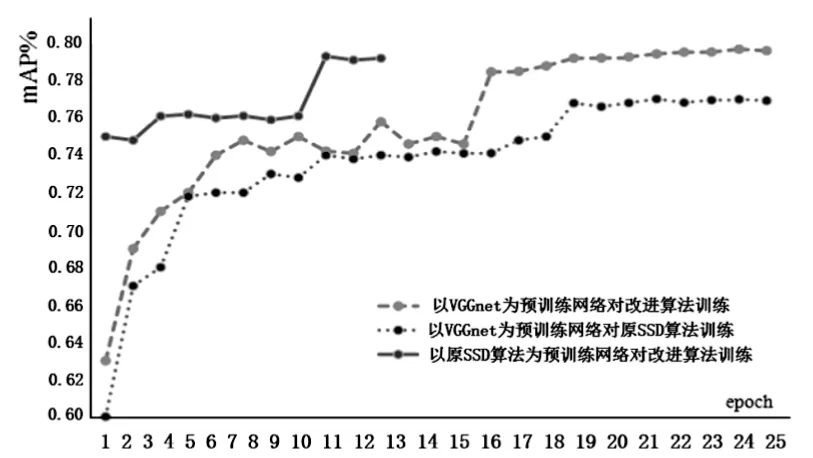
图5 原SSD模型及相关改进模型的训练
3.4 相关算法对比
基于相关测试集对训练好的模型以及相关对比模型进行测试,测试结果如表1所示。

表1 改进模型及相关对比模型的测试结果
由表1中数据可知,改进的SSD 300算法(加入OPD机制的SSD300算法)在相关测试集上可以达到79.2%的精确度,与传统的SSD 300算法相比精确度提高了2.3%。与DSSD 321检测模型相比,虽然DSSD 321检测模型使用性能优于VGG 16的ResNet-101作为基础网络,但改进SSD 300算法的精确度仍有0.5%的提升。与DSSD 513算法相比,改进的SSD 512算法在检测精度上略显不足,可以认为基础网络在此起到关键作用,但就算法检测实时性而言,改进的SSD 512算法要比DSSD 513算法快得多。
传统的SSD算法在未进行预训练处理时,模型的性能只能到达69.2%。基于同样的条件,对改进的SSD算法从零开始训练,改进算法的模型精度达到73.2%,模型性能明显提升。在单Nvidia 2080Ti GPU环境下,分别测试了原SSD检测算法以及改进检测算法的FPS值,由于改进算法加入了相关的特征融合机制,消耗了约8%的额外时间,模型检测FPS值相较于原SSD算法大致相同。但对比DSSD与Faster RCNN模型,改进模型的检测速度要快许多,同时也保持了较好的精度。
4 结束语
重点研究了特征融合机制对SSD模型性能的影响,基于相关实验数据集,对加入了特征融合机制的SSD算法进行了相关训练和测试,与Faster RCNN、DSSD、原SSD以及YOLO v2算法进行实验对比。实验结果表明,特征融合机制的引入,有效提升了SSD目标检测算法的效率。
特征融合机制的加入使得SSD检测算法得到两方面的提升,一方面,降低了重复检测同一目标或将多个目标检测为同一目标的机率,从而使模型效率得到提升。另一方面,针对传统SSD模型将位于不同特征层的相关信息作为同一层次的信息问题,通过输出特征图的融合机制重新构建目标检测金字塔,使得SSD算法能够更充分地利用局部特征和全局语义特征,将输入图像中待检测目标的低层次细节特征与高层次的语义信息相结合,使得模型能够成功地检测到更多的目标对象,进而将模型检测精确度提升约2.3%。这一改进对无人驾驶领域[19]的精确检测具有较高的参考价值。
