基于AP聚类与随机森林的客户流失预测研究
2021-03-08胡永培
胡永培,张 琛
(1.徽商银行 大数据部,安徽 合肥 230601;2.合肥学院 人工智能与大数据学院,安徽 合肥 230601)
0 引 言
随着大数据、人工智能、区块链技术的快速发展,利率市场化进程不断推进,银行利差在逐渐收窄,传统的经营模式已不能满足日益变化的市场需要,各家银行纷纷开展数字化转型[1-2],银行零售业务板块表现的尤为迫切。
各家银行零售客户一直以来都表现出明显的“二八定律”,更有甚者可能出现“一九定律”,即银行20%的零售客户贡献了80%的零售利润[3],20%的客户一般为各家银行的优质客户,是各家银行重点维护的对象,所以各家银行在努力拓展新的优质客户的同时,有效防止存量客户资产下降同样重要。有相关研究表明,客户流失率下降5%,能给银行多带来25%~85%的零售利润[4]。挽回一个老客户所花费的成本远远低于拓展一个新客户,因此如何找出影响客户流失的关键因素,精准预测客户流失的可能性,是各家银行挽回客户的核心。
近年来,随着客户流失预警越来越被关注,国内外相关学者也对此进行了很多的研究,不断提高模型预测的准确性。张宇[5]使用C5.0分析了企业客户流失预测模型。Prasad 和Madhavi[6]分别用CART和C5.0两种方法分析了银行业客户流失情况。丁君美[7]使用随机森林分析了电信业客户流失问题。杨力[8]采用极限学习机分析了电子商务客户流失量预测模型。为了克服客户流失数据集的不平衡性,Lemmens和Croux[9]引入了集成学习;Nikulin和Mclachlan[10]提出用平衡的随机数据集为不平衡的客户流失数据进行分类;Karthik[11]将属性选择引入了客户流失模型中。
为了提高预测的准确率,一般需要进行属性选择,属性约简可以减少样本空间维数,剔除无关的、影响较小的属性,提高预测的准确率。而聚类是属性选择的一种方式,通过聚类将相似的一类属性聚在一起,然后在每一类中选择代表属性,构成属性子集,使用属性子集进行预测。该文拟计算属性区分能力,将其作为相似性度量依据,然后使用Affinity Propagation Clustering(AP)[12-13]聚类方法进行聚类。达到属性选择的目的。
从现有研究来看,各项研究主要集中在针对模型预测准确性的提高,缺乏根据银行实际营销过程中关注的重点客群进行流失研究,因此针对银行实际关注的客群进行流失模型的建立,对流失客户的挽回有着更加重要的意义。
综上,针对银行实际关注的客群进行流失挽回,对各家银行具有重要意义。该文与以往研究稍有不同,以某商业银行为例,根据银行实际营销现状,重新对客户流失进行定义,重点关注银行优质客户,并利用随机森林方法建立客户流失预警模型,预测零售优质客户未来3个月流失的可能性。
1 相关算法
1.1 AP聚类
AP聚类算法是由Freya等人在2007年提出的一种快速、有效的聚类方法,该方法通过消息传递实现聚类,无需事先指定聚类数目。实际上对于很多的实际问题,是无法事先知道聚类个数的。
AP算法用欧氏距离衡量相似性,任意两点xi与xk之间的相似度为:

(1)
AP算法引入两类信息:吸引信息r(i,k),是从xi指向候选代表点xk,反映了xk适合作为xi的类代表点所积累的证据;归属信息a(i,k),是从候选代表点xk指向xi,反映了xi选择xk作为其代表点的合适程度所聚类的证据。迭代中,这两个信息交替更新:
r(i,k)←

(2)
a(i,k')←

(3)
在AP算法中引入阻尼因子λ(λ∈[0,1]),阻尼因子能够提高收敛性,克服迭代中的震荡现象,每一次的迭代更新均由上次迭代结果和本次更新得到。
r(τ+1)(i,k)←
(1-λ)r(τ+1)(i,k)+λr(τ)(i,k)
(4)
a(τ+1)(i,k)←
(1-λ)a(τ+1)(i,k)+λa(τ)(i,k)
(5)
其中,τ为当前迭代时刻,通过a(i,k)和r(i,k)的交替更新,所确定的最优类代表点为:

(6)
1.2 基于AP聚类的属性选择方法
属性选择采用属性的区分能力来度量属性相似性,利用聚类方法将属性区分能力相似的属性聚为同一类簇,然后选取各类簇的聚类中心属性作为代表属性,那么,所有类簇的代表属性集合即为属性集合的约简结果[14]。具体步骤如下:
(1)数据离散化;
(2)计算条件属性对决策属性的重要度作为属性的区分能力;
(3)采用AP算法将相似性属性聚为一类;
(4)将聚类后的类簇聚类中心作为代表属性;
(5)所有类簇的代表属性集合即为属性约简集合。
1.3 随机森林
随机森林RF(random forest)是一种基于集成学习的算法[15],是一个包含多个决策树的分类器,将多棵决策树集成起来,得到最终的分类结果。随机森林从N个样本中采用可放回抽样方法重复抽取N个样本,每个决策树的节点从所有属性m中随机选择p(p≪m)个属性,使用Gini指数生成非剪枝的CART决策树。采用上述方法构造多棵决策树,将这些决策树集合起来构成随机森林。随机森林先采用随机抽样方法抽取样本,然后随机选择分类属性,因此,随机森林不会产生过拟合现象。
随机森林的算法如下所述:
(1)假设存在数据集D={xi1,xi2,…,xim,yi}(i∈[1,N]),采用Bootstraping方法从N个训练样本中有放回地抽取N个训练样本,共进行k轮,得到k个训练集。
(2)在每个训练集上,从m个属性中随机选择p个属性,每个抽样训练集为dj={xi1,xi2,…,xip,yi}(i∈[1,N]),j∈[1,k],共训练生成k棵CART决策树hj(x),j∈[1,k]。
(3)采用多数投票法,对k个决策树的分类结果进行集成,得到最终的分类结果,H(x)=φ(hj(x)),j∈[1,k],其中φ(x)是多数投票法。
具体流程见图1[16]。

图1 随机森林模型构造流程
2 基于随机森林的银行优质客户流失预测方法研究
2.1 随机森林在UCI数据集上的验证
为了验证随机森林方法优于一般的分类算法,该文在UCI标准数据集上进行验证。
数据集如表1所示。

表1 实验所用数据集情况
分别使用CART算法和随机森林(RF)在上述数据集上进行验证,结果如表2所示。

表2 CART与随机森林在UCI数据集上的实验结果
从表2可以看出,采用随机森林方法在准确率、精确率、召回率和F值上均优于单个分类算法CART,因此该文采用随机森林方法来搭建银行客户流失模型。
2.2 基于随机森林的银行优质客户流失预测方法研究
该文将AP聚类算法和随机森林用于某商业银行的零售优质客户流失预警,预测未来3个月客户流失的可能性,并与CART决策树方法进行对比分析。其中优质客户指月日均资产大于等于5万元以上的客户。
2.2.1 构造数据集
本次研究以某商业银行零售客户流失预警数据进行实证研究,数据时间窗口为2018年7月到2019年3月。2018年7~12月设定为观察期,2019年1~3月设定为表现期。流失客户的定义:客户T月月日均资产达到5万及以上,后三个月(T+1,T+2,T+3)月日均资产均较T月下降30%以上。
为保证模型数据的有效性,该文从某商业银行所有样本中随机挑选了10万条样本数据,并保证样本的正负样本与商业银行总体样本分布一致。由于流失客户数据集是不平衡数据集,而不平衡数据集对模型预测效果是有影响的,为了消除不平衡数据集对模型的影响,采用随机向上(过)采样技术(random over sampling,ROS)平衡训练样本集中不同类别的样本数量。
2.2.2 模型指标构建
从业务的角度出发,根据影响零售客户流失的因素,结合指标的数据质量,从客户基本信息、交易信息、资产负债信息、签约信息、偏好信息、渠道信息以及其他关联信息等角度选取了181个影响指标,作为本次模型构建的初始指标。
在使用随机森林建模之前,需要先对数据进行预处理,首先对缺失值和异常值进行预处理,例如产品类指标,针对理财余额、定期存款余额存在缺失值的情况取0处理,年龄超过100岁的按100处理,因客户群体本身为优质客户,数据质量相对较好,缺失值处理较少。其次将字符型变量转化为数值型标量,并采用Z-score方法对数据进行标准化处理。
在标准化处理以后,采用基于AP聚类的属性约简方法进行属性选择,通过对原始的181个指标进行筛选后,最终得到16个指标用于构建随机森林模型,具体见表3。

表3 影响客户流失的相关指标
2.2.3 模型评价指标
为了验证随机森林模型的实际效果,采用常用的准确率(accuracy)、精确率(precision)、召回率(recall)、F值(F-measure)作为客户流失模型的评价标准。
设预测为流失的客户中,tt为实际流失客户数,tf为实际未流失客户数;预测为未流失的客户中,ft为实际流失客户数,ff为实际未流失客户数。
准确率为预测正确的客户数占全部样本的比例:
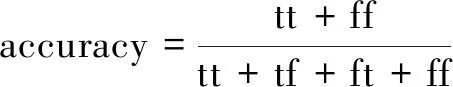
(7)
精确率为预测正确的流失客户占预测为流失客户比例:
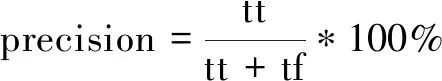
(8)
召回率为预测正确的流失客户占实际流失客户的比例:
(9)
F统计值为:

(10)
2.3 实验结果
该文采用5-fold交叉验证来评估构造的模型。总共进行5次5-fold交叉验证,验证结果取平均值作为5次5-fold交叉验证的结果,具体见表4。

表4 5次5-fold交叉验证结果 %
同时运用传统的CART决策树算法对数据进行预测,与随机森林进行对比,具体评价指标见表5。从表5中可以看出,随机森林算法具有较高的准确率,以及较好的精确率、召回率和F值,远好于CART算法,说明随机森林模型更加可靠,预测性更好。

表5 随机森林方法与CART决策树的对比结果 %
3 结束语
针对银行实际关注的零售优质客户群体,重新定义零售流失客户,并构建了基于AP聚类算法和随机森林算法的零售客户流失模型,在银行零售流失预警的评估结果中表现出较好的效果,在银行实际运用中具有更加重要的意义。
