基于深度学习的高分六号影像水体自动提取
2021-03-07郑泰皓王庆涛李家国郑逢斌张永红
郑泰皓, 王庆涛,, 李家国, 郑逢斌, 张永红, 张 宁
(1.河南大学计算机与信息工程学院, 开封 475000; 2.中国科学院遥感与数字地球研究所, 北京 100020;3.中华人民共和国住房和城乡建设部城乡管理规划中心, 北京 100835)
遥感能动态监测地表信息,被广泛应用于环境检测、资源探测、生态研究、测绘制图和军事指挥等众多领域[1]。近二十年来,遥感技术飞速发展,及时、精确地从遥感影像上提取水体信息已经成为水资源调查监控的重要手段[2]。
目前,中外在水体自动提取方面已经提出了多种方法,如单波段阈值法、水体指数法[3]、多波段谱间关系法[4-5]、决策树法[6]、指数法等,其中对水体指数法、多波段谱间关系法、决策树法的研究较多,应用也比较成熟。但随着影像中地物信息量的增加,传统水体分类方法在精度和效率上渐渐不能满足一些高精度的生产需求。
卷积神经网络(convolutional neural networks, CNN)是在遥感影像领域应用非常成功的一种深度学习网络,它摆脱了人工计算影像特征的步骤,直接从遥感影像中学习光谱、纹理、边缘等特征,有效解决高维、海量数据提取和分类的问题。研究人员基于深度学习对土地利用分类[7-8]、地面目标检测[9-10]、城市建筑提取[11]等方面进行了相关研究。全卷积神经网络将传统的卷积神经网络的全连接层替换为卷积层,在图像分割领域的应用效果,远远超过了传统的图像分割方法[12]。陈睿敏等[13]基于RIT-18数据集,利用全卷积神经网络进行了道路、水体、农田等的提取,取得了较高的精度;刘笑等[14]基于资源三号卫星影像,研究了遥感影像道路提取方法,取得了较好的效果。
高分号(GF-6)卫星是中国2018年发射的国产卫星,关于其应用潜力的研究逐渐成为一大热点。以GF-6卫星PMS遥感影像为数据源,分别构建全卷积神经网络(FCN-8s)、U-Net及U-Net优化(VGGUnet1、VGGUnet2)4种神经网络进行水体提取研究,提出组合损失函数FD-water loss并应用于VGGUnet1,以进一步提高水体识别的效果,减少水体的误分和漏分。
1 研究区概况与数据源
1.1 研究区概况
为了探究高分六号多光谱相机在不同类型地表水体中的应用能力,选择抚仙湖、官厅水库、太湖、黄河(山西段)、深圳市5个区域作为研究对象,涵盖了清洁水体、一般水体、浑浊水体、富营养化水体、黑臭水体、近岸海水6种不同类型的水体。各研究区概况及数据源如表1所示。
1.2 数据源
GF-6卫星具有大角度、高质量成像、高效能成像等特点,能够在较短的时间段内获取大区域多时相遥感影像。GF-6卫星轨道高度760 km,重返周期4d,其多光谱数据空间分辨率为8 m,具有蓝、绿、红、近红外4个波段,波长范围分别为450~520、520~590、630~690、770~890 nm;全色数据分辨率为2 m,波长范围450~900 nm。训练数据集所采用的影像产品序列号如表 1所示。
2 研究方法
研究流程如图 1所示。

表1 研究区概况及数据源Table 1 Research area overview and data source
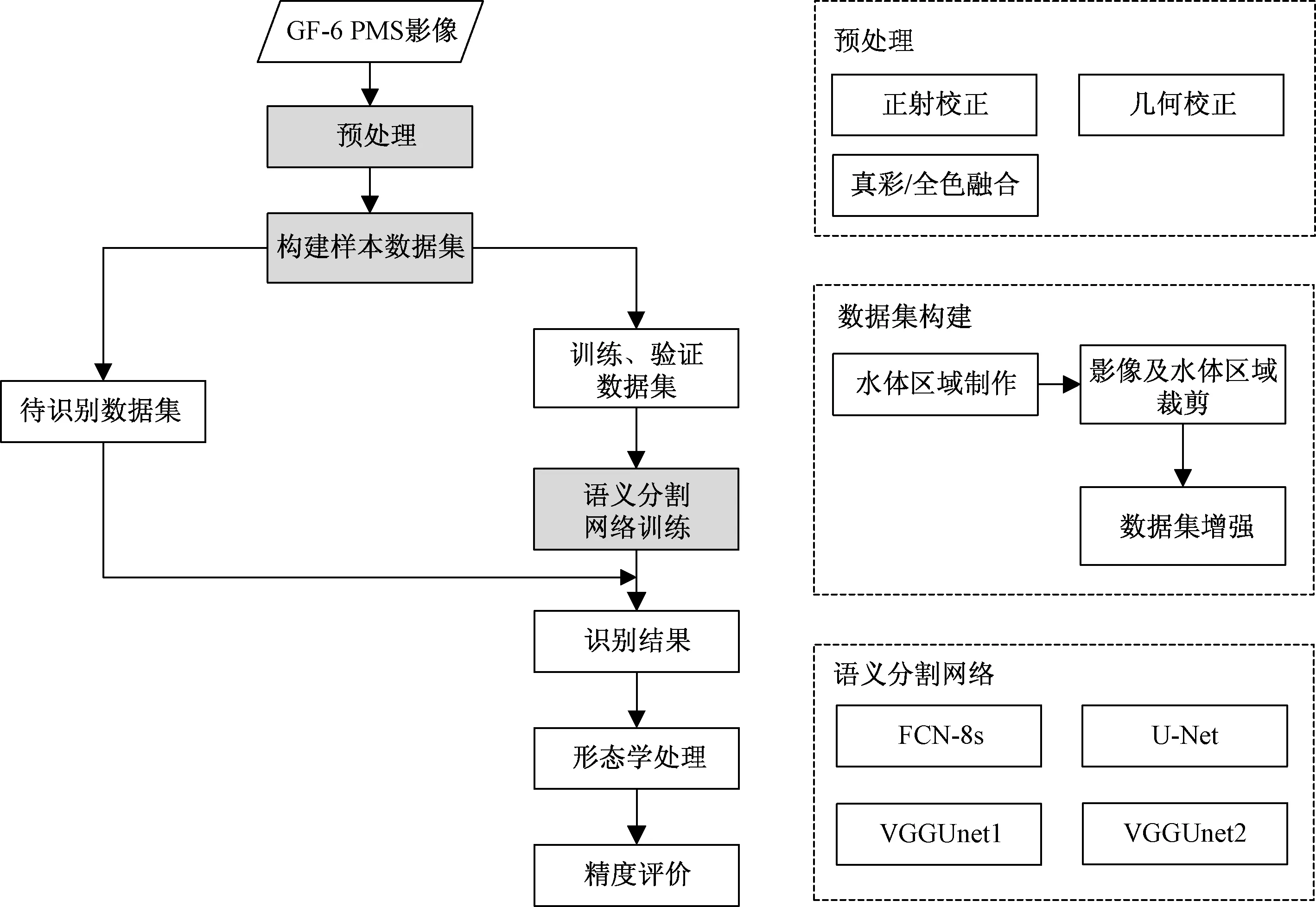
图1 研究流程Fig.1 Research flow
2.1 数据预处理方法
对GF-6卫星影像进行了正射校正、影像配准、多光谱/全色融合等预处理。
采用ENVI正射校正流程化工具对影像进行正射校正。设置多光谱影像分辨率为8 m,全色影像分辨率为2 m,重采样方式为3次卷积内插法(cubic convolution),数字高程模型(digital elevation model,DEM)数据为完整的遥感图像处理平台(the environment for visualizing images,ENVI)自带的“GMTED2010.jp2”;采用ENVI自动配准流程化工具,以全色数据为基准对多光谱数据进行配准;采用ENVI 的NNDiffusePanSharpening工具对配准后的全色/多光谱影像进行融合。预处理后影像分辨率2 m,每景约25 G。
2.2 水体标注与数据集制作
水体标注包含两个步骤:①先使用ENVI的基于特征分类工具(example based feature extraction workflow)进行水体粗提取,设置分类阈值(threshold)为100,对水体进行初步标注;②用目视解译的方式,进行增、删、改等操作,确保所标注的水体边界正确且完整。水体标注结果采用tif进行存储,数据格式为GDAL_BYTE格式,水体值设为1,背景值设置为0,波段数为1。以局部影像(官厅水库)为例,原始影像及对应水体标注结果分别如图2(a)、图2(b)所示。
将影像及水体区域tif,进行224×224随机采样,对采样得到的样本数据进行90°、180°、270°旋转及水平、垂直翻转等数据集增强操作,以增加模型的鲁棒性。最终得到样本数据集161 622对,其中随机取26 937对作为验证数据集,134 685对作为训练数据集。

图2 影像(局部)及对应水体标注结果Fig.2 Image (partial) and water body labeling results
2.2.1 卷积神经网络
卷积神经网络(convolutional neural network, CNN)模型均由输入层、卷积层、池化层、全连接层、softmax层等部分组成,通过局部连接、参数共享等方式大大减少了网络参数量,降低了复杂度,提升了网络的效率和准确度。以AlexNet[15]为例,AlexNet的隐含层包含5个卷积层、3个池化层和3个全链接层,网络结构如图3所示,网络比较复杂,可分为上下两个子网络,两子网络是分别对应两个图形处理器(graphics processing unit, GPU),只有到了特定的网络层后才需要两块GPU进行交互,网络结构上差异不很大,以下层子网络的为例:第一层输入为224×224×3的图像,卷积核的数量为48个,卷积核的大小为11×11×3;步长(stride)为4,采用不扩充边缘方式卷积,卷积后得到55×55×96个像素层;池化方式为最大池化(max pooling),池化尺度为3×3,步长为2,池化后的尺寸为=27;最后为3个全连接层,第一个卷积层通过4 096个6×6×256的卷积核输出4 096个本层的输出结果值,之后类似生成最终的1 000个结果,即为预测种类的概率卷积神经网络得到的是输入图像的一个数值描述的概率值,即从二维矩阵压缩为一维,丢失了空间坐标,并不适用于像素级的分类任务。因此Long等提出了全卷积网络(fully convolutional network,FCN)[16],Ronneberger等[17]提出了U-Net。
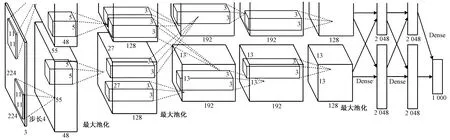
图3 AlexNet结构Fig.3 AlexNet structure
2.2.2 全卷积网络
FCN是在卷积神经网络的基础上提出的,基于像素级别的图像分类网络,解决了语义级别的图像分割问题。FCN将传统的CNN 模型的全连接层转化成一个个卷积层,这样所有的层都是卷积层,故称为全卷积网络。FCN包括卷积化、上采样(反卷积) 和跳层结构,网络结构如图 4所示。
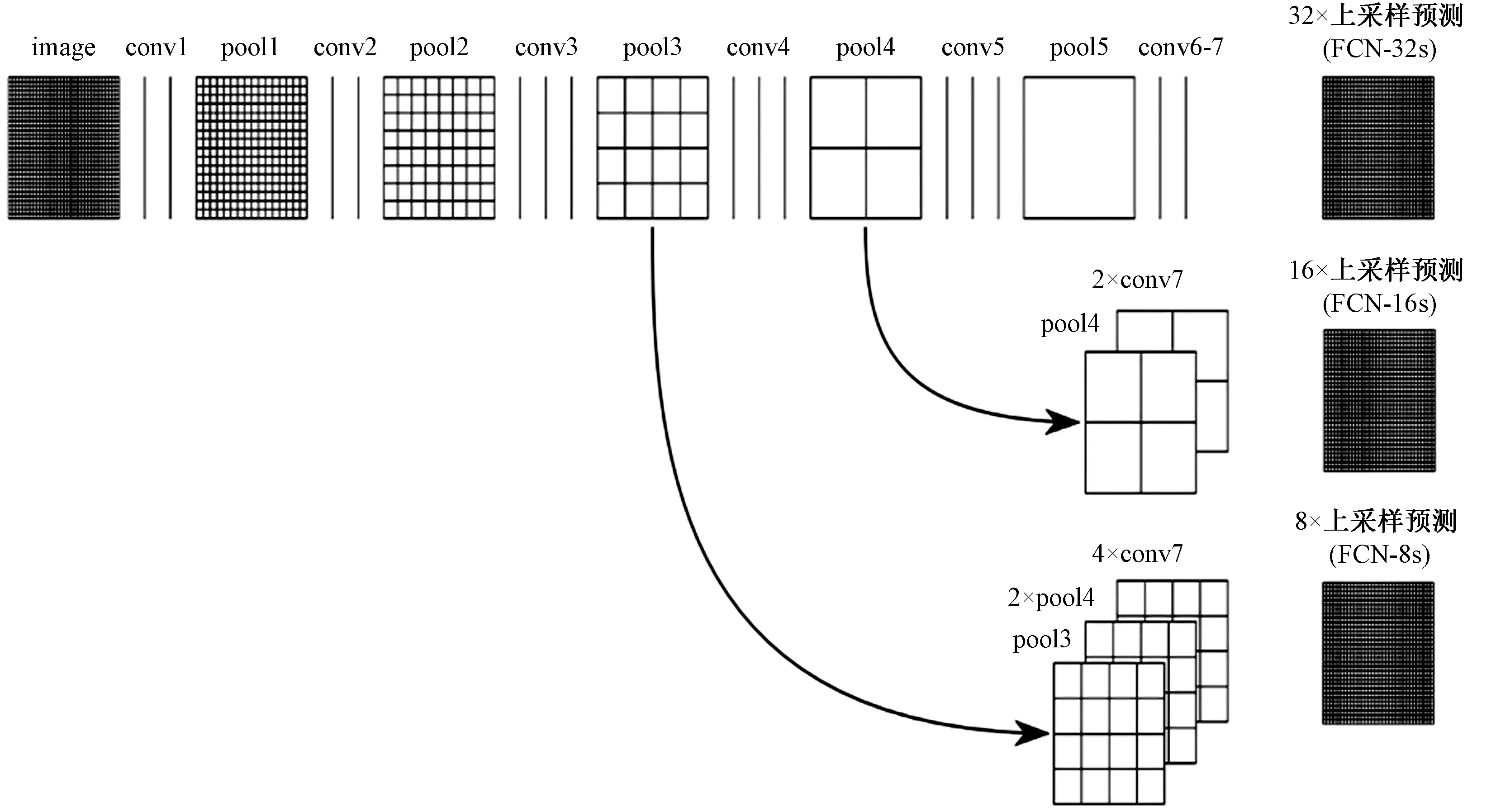
图4 FCN结构Fig.4 FCN strcture
(1)卷积化。在AlexNet结构中,前5层是卷积层,第6层和第7层分别是一个长度为4 096的一维向量,第8层是长度为1 000的一维向量,分别对应1 000个不同类别的概率。FCN将传统CNN模型中的全连接层改为卷积层,将第6、7、8层分别表示为卷积层,卷积核(通道数、宽、高)分别为(4 096*1*1)、(4 096*1*1)及(1 000*1*1)。
(2)上采样。FCN-8s模型经过多次卷积和池化之后,得到的图像越来越小,分辨率越来越低。FCN为了得到原始影像像素的分类信息,使用上采样(deconvolution)实现尺寸还原,输出同分辨率的分割图像。上采样选用双线性插值反卷积[18]方法。
(3)跳层结构。从32 倍下采样的图像直接上采样插值到原始图像大小,信息量损失较大,结果较粗糙,只能表示出对象的大致形状。Long等[16]将第4层的输出和第3层的输出依次进行反卷积,分别为16倍和8倍的上采样,从而得到了更加精细的分割结果。如图 4所示,将conv7层的输出经过N*1*1卷积后直接上采样至image大小,得到32倍上采样预测(32×upsampled prediction,FCN-32s);将conv7层的输出经过N*1*1卷积后进行2倍上采样,并与conv4层的输出经过N*1*1卷积后进行相加操作,得到16倍上采样预测(16×upsampled prediction,FCN-16s);同理可得到8倍上采样预测(8×upsampled prediction,FCN-8s)。
FCN可接受任意大小的输入影像,不要求所有的训练图像和测试图像具有同样的尺寸,且避免了由于使用像素块而带来的重复存储和计算卷积的过程,更加高效。采用效果较好的8×upsampled prediction(FCN-8s)进行水体提取试验。
2.2.3 U-Net网络
U-Net网络是基于FCN改进得到的一种全卷积网络,其结构类似于U型,因此称为U-Net。U-Net网络结构由收缩路径和扩张路径两部分组成,收缩路径部分进行特征提取,扩张路径部分进行反采样。收缩路径部分由2个3*3卷积层和1个2*2最大池化层组成的块重复搭建完成;扩张路径部分先进行2*2的反卷积,使特征图的维数减半,然后与对应的特征图(裁剪后)串联起来,再接2个3*3卷积层,并重复这一结构;在最后一层及输出层,通过1*1卷积核及softmax激活函数将特征图映射成所需的种类。U-Net在上采样部分加入了复制和裁剪通道,使网络能够将上下文信息从浅层传递到更高分辨率的层。这种结构使得U-Net和全卷积神经网络同样得到一幅分割图,但是前者的每个像素都包含了原图的上下文信息,使其对小目标分割具有更佳的效果。Ronneberger提出的U-Net采用VGGNet13的前10层作为U-Net的收缩路径部分[17-18],网络模型结构示意图如图 5所示。
2.2.4 U-Net网络优化
为了更有效地挖掘数据的特征,并减少模型的参数量,对U-Net模型进行优化,构建VGGUnet1模型,采用更深层次VGGNet16的前13层作为U-Net的收缩路径部分,同时扩张路径部分减少了反卷积层数。构建的VGGUnet1网络模型结构如图6所示。

input image为输入图像;channels为通道;prediction为预测图5 U-Net结构Fig.5 U-Net structure
为对比低层次特征对分割结果的影响,构建VGGUnet2模型,该模型取消了VGGUnet1中第4层连接层。
2.2.5 损失函数
基于像素的交叉熵损失函数(pixel-wise cross-entropy loss)是图像分割任务中最常用的损失函数,被采用在原始U-Net网络结构中。该损失单独地检查每个像素点,将类预测(深度方向的像素矢量)与one-hot编码的目标矢量进行比较,定义为

图6 VGGUnet1结构Fig.6 VGGUnet1 structure

(1)
式(1)中:yi,j为预测结果;ti,j为真实值;i表示第i个像素点;j为类别信息。交叉熵损失函数可以衡量yi,j与ti,j的相似性,当yij与ti,j接近时,loss接近于0。
交叉熵损失函数单独评估每个像素矢量的分类预测,然后对所有像素求平均值,所以如果各种类在图像分布不平衡时,这会使训练过程将受像素最多的类所支配。
构建FD-water loss损失函数,以改善正负样本不均衡带来的损失函数收敛缓慢甚至无法优化至最优的问题。
FL(focal loss)[19]是解决分类问题中类别不平衡、分类难度存在差异的损失函数。
对于2分类语义分割中的FL,可表示为
(2)
式(2)中:pn为预测值;rn为样本真值;α、γ均为参数;α为平衡因子,用来平衡正负样本本身的比例不均。
当一个样本被错误分类且pn很小时,认为它是难区分样本,调节因子(1-pn)接近于1,此时loss可认为不受(1-pn)影响;当pn→1,认为它是易区分样本,调节因子(1-pn) →0,此时loss将降低易区分样本的权重。γ参数调节简单易分样本权重下降的速度。当γ=0,FL2就是交叉熵损失函数,随着γ的增大,调制因子(1-pn)的作用也随之增大。
Dice loss是针对前景比例太小的问题提出的,dice系数源于二分类,本质上是衡量两个样本的重叠部分[20]。对于2分类语义分割中dice loss(DL2)表达式为
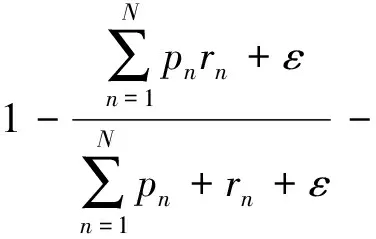
(3)
式(3)中:N为总像素个数;pn为预测结果;rn为样本真值;ε为调节参数,避免分母为0。
构建的FD-WL(FD-water loss)表达式为
FD-WL=FL2+DL2
(4)
函数结合了FL与DL优势,降低了简单负样本(背景)在训练中所占的权重,同时增强了模型对于小区域水体的提取能力。经多次实验,α=0.25,γ=2.0,ε=0.000 05时,提取效果较优。
2.3 斑块与噪声处理
由于采用面向像素的语义分割网络,水体提取的结果难免存在小范围的噪声,比如孤立的像素点及孔洞等,这可能是影像本身存在数值异常的像素或模型本身等造成的。通过应用形态学的知识,对小于一定阈值的孤立像素点进行抹除,对小于一定阈值的孔洞进行填充,可改善噪声带来的影响。经实验及观测,阈值选择8个像素面积时较为合适,可进一步提高水体提取的精度。
形态学中腐蚀的表达式为
XΘB={x|(B)x⊆X}
(5)
形态学中膨胀的表达式为
X⊕B={x|(Bv)x∩X≠∅}
(6)
式中:X为目标图像;B为结构元素;Bv为B的对称集;x表示集合平移的位移量;Θ为腐蚀运算的运算符;⊕为膨胀运算的运算符。
形态学中开运算为先腐蚀再膨胀,闭运算为先膨胀再腐蚀。对图像进行开运算和闭运算的效果如图7所示。
2.4 精度评价

图7 开运算与闭运算效果Fig.7 Effects of open and close operation
实验采用Jaccard指数(JAC)、精确率(Precision)及召回率(Racall)进行精度评价。Jaccard指数表达式为
(7)
精确率表达式为
(8)
召回率表达式为
(9)
式中:A表示模型提取水体的结果;B表示水体标注的结果,二者均为二值栅格;Jaccard指数越接近1,说明集合A与B的交集越大、A与B越相似,提取效果越好;TP为提取为水且水体标注结果也为水的像素集合;FP为提取为水但水体标注结果为背景的像素集合,即水体错分集合;FN为提取为背景水体标注结果为水的像素集合,即水体漏分集合。水体提取的Precision越高说明提取的精度越高,Racall越高说明提取的丢失率越小,漏分越少。
3 实验结果与讨论
实验基于Windows Server 2016操作系统,内存16G,显卡为NVIDIA Quadro P2000,显存5G。
3.1 验证区数据
选取三景预处理后的GF-6 PMS影像作为验证区影像,景号分别为L1A1119837349(山东烟台市地区)、L1A1119844867(云南昆明市地区)、L1A1119839138(云南大理市地区)等。验证区影像及对应的水体标注结果如图 8所示,其中L1A1119837349大小为57 820×55 008像素,L1A1119844867大小为55 928×53 088像素,L1A1119839138大小为55 836×52 800。图8(b)中黑色部分为背景,白色部分为水体。
3.2 结果及讨论
由于预处理后影像较大,将每幅验证区影像裁为了4块,每块大小约23 000*23 000像素,上下或左右相邻的块之间保留60行或60列像素的重叠部分。
采用滑动窗口对分块后影像进行水体提取,滑动窗口的大小为224*224像素,步长为164*164像素。当像素处于分块后影像的边缘或分块后影像所剩不足滑窗大小时,对分块后影像进行边缘镜像扩充。将滑动窗口内的影像依次读入网络进行预测。

图9 建筑阴影混合条件下水体提取结果Fig.9 Water extraction under mixed conditions of building shadow
3.2.1 基于交叉熵损失函数的模型优选
将每个滑窗内影像的提取结果舍弃四周30像素后进行拼接,得到每块影像的提取结果;然后对每块提取结果的重叠部分取交集得到整张影像的水体提取结果;最后进行形态学处理得到最终水体提取结果。
为方便观察对比,对最终提取结果进行了矢量化处理。图9~图11给出各模型提取后的局部结果对比。

图10 不同水深影响条件下水体提取结果Fig.10 Water extraction under different water depths
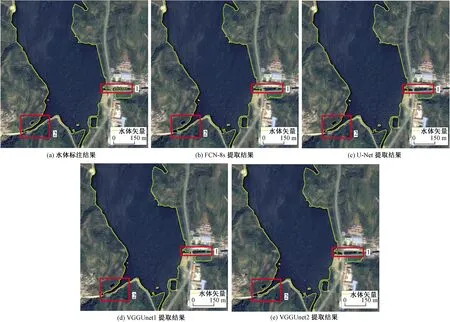
图11 不同大小水体斑块混杂条件下水体提取结果Fig.11 Water extraction under mixed conditions of water bodies in different areas
从图9可以看出,FCN-8s的提取结果中存在较多的建筑阴影被误判为水体,U-Net的提取结果中阴影的误分已经大为减少,改进后的VGGUnet1、VGGUnet2中阴影的误分进一步减少,此外FCN-8s在框2处河道水体处在较多的漏分,VGGUnet1的提取结果较为理想。图10中,由于河流深度的不同,影像水体部分存在着一定的色差,从结果来看,本文所用的各模型的对于水体与河堤、桥梁的边界识别比较清晰,对于不同颜色水体的提取效果较好,但在沙滩与水体(框1处)的交界处提取能力存在差异,VGGUnet1的提取结果较好。图10框2处、图11框1处可以发现,即使提取效果较好的VGGUnet1,对于小面积水体扔存在漏分的现象。
使用Jaccard指数、精确率、召回率对各模型的水体提取结果进行精度评价。各模型提取结果精度如表2所示。综合对识别示例的分析,VGGUnet1对于水体提取的效果较优,提取水体结果的Jaccard指数为0.939 787,精确率为94.66%,召回率为94.25%。
3.2.2 FD-Water loss对水体提取的提升
从VGGUnet1的水体提取结果中发现,采用交叉熵损失函数的VGGUnet1对于小面积水体存在漏分。因此构建了FD-water loss,减少简单负样本的权重,提升小面积水体对损失函数的贡献。图12为采用FD-water loss 的水体提取结果对比,同时选择了阈值法(NDWI阈值法)、监督分类法(最大似然分类法、支持向量机分类)等方法进行了实验结果的对比分析,对比结果如表3所示。

表2 各模型水体提取对比Table 2 Comparison of water extraction of each model
从图12框1处可以看出,采用FD-water loss后的VGGUnet1对于小面积水体的识别能力有着明显的改善,但是仍有部分小面积水体没有得到识别。经统计分析,当VGGUnet1+FD-water loss模型提取的水体像素面积大于164时,提取水体与水体标注结果较为一致,此时水体实际面积为656 m2。

图12 不同损失函数条件下VGGUnet1水体提取结果Fig.12 Water extraction of VGGUnet1 under different loss functions

图13 建筑阴影混合条件下3种对比算法水体提取结果Fig.13 Water extraction of three comparison algorithms under mixed conditions of building shadow
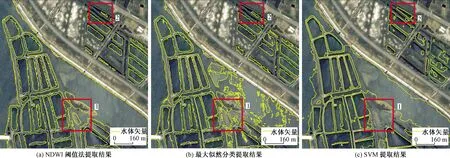
图14 不同水深影响条件下3种对比算法提取结果Fig.14 Water extraction of three comparison algorithms under conditions of different water depths

表3 各模型水体提取对比Table 3 Comparison of water extraction of each model
从图13、图14可以看出,NDWI阈值法的水体提取精度较差,主要表现为NDWI阈值法将大面积的阴影误分为水体,且在整副影像中的水体提取中,几乎难以确定一个合适的阈值,精确率仅为75.76%,但是当阈值设置比较大时,NDWI漏分较少,召回率达到了93.76%;最大似然分类仍存在较多阴影的误分,但是漏分情况较NDWI阈值法有所增加,精确率为86.21%,召回率为89.32%;支持向量机(support vector machine,SVM)分类法的阴影误分较少,且漏分情况也有所改善,精确率为92.01%,召回率为91.72%;构建的基于FD-water loss损失函数的VGGUnet1网络模型精确率为98.06%,召回率为97.81%,大大减少了阴影的误分以及水体的漏分,可获得较优的提取结果。
4 结论
制作了GF-6卫星 PMS影像水体数据集,通过FCN-8s、U-Net、VGGUnet1、VGGUnet2这种模型对GF-6卫星PMS影像进行了水体自动提取的研究,提出了基于FD-water loss的VGGUnet1网络模型。经实验结果对比分析,得到如下结论。
(1)基于像素的交叉熵损失函数的FCN-8s、U-Net、VGGUnet1、VGGUnet2这4种模型中,VGGUnet1水体提取结果的Jaccard指数、精确率、召回率较高,提取结果较好,是上述四种模型中的较优模型,但是对小面积水体存在较多的漏分现象。
(2)基于FD-water loss 损失函数的VGGUnet1对小面积水体的识别能力得到提高,当水体像素面积大于164时,提取水体与水体标注结果较为一致,此时水体实际面积为656 m2。
(3)与NDWI阈值法、最大似然分类法、支持向量机分类等方法相比,基于FD-water loss 损失函数的VGGUnet1模型对水体提取精度较高、水体边界提取清晰,错分、漏分现象大大减少,具有较大的应用潜力。
仅进行了水体的提取研究,对于不同类型水体提取尚未深入。未来可以尝试利用GF-6卫星的8波段宽幅影像,进行浑浊水体、黑臭水体等不同类型水体提取的研究。
