基于HHT-MFCC和短时能量的慢性阻塞性肺病患者呼吸声识别
2021-03-07张晓晓
常 峥,罗 萍,杨 波,张晓晓
(重庆邮电大学自动化学院,重庆 400065)
(*通信作者电子邮箱1213884879@qq.com)
0 引言
呼吸系统是身体与外界进行气体交换的器官总称,肺部是系统中重要的组成部分,负责氧气输送和二氧化碳排出[1]。肺作为身体的重要器官之一,人们从未停止对肺部相关疾病的研究。随着年龄增长和环境恶化,60 岁以上老年人的肺部情况较为恶劣,尤其是慢性阻塞性肺病(Chronic Obstructive Pulmonary Disease,COPD),这种疾病具有发病周期长且难以治疗的特点,是老年人主要医疗经济负担和死亡原因。
声音是信息的主要载体,人们可以通过声音来判断事物的某种状态,通过呼吸声信号诊断COPD 能够解决患者到医院就诊所带来的诊断周期长、时间成本高等问题,因此在国内外出现很多关于COPD 呼吸声信号方面的研究。Jaber 等[2]利用改进的随机森林分类器对肺部声音信号进行肺部疾病有效诊断,其中包括COPD、哮喘等肺部疾病;Azam 等[3]采用CEEMD(Complete Ensemble Empirical Mode Decomposition)并结合支持向量机(Support Vector Machine,SVM)的方法区分COPD、哮喘和支气管炎等疾病;Pramono 等[4]通过计算复杂度较低的线性分类器区分健康、哮喘和COPD 呼吸声;Islam 等[5]通过提取功率谱密度子带中特征向量并输入到人工神经网络(Artificial Neural Network,ANN)分类器实现识别健康人、哮喘和COPD 患者;Altan 等[6]采用集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)和深度信念网络的方法区别COPD 患者和健康人呼吸声,EEMD 解决了EMD 中模态混叠问题;Haider 等[7]提取中值频率和线性预测编码特征并结合SVM,实现结合呼吸声测量数据和呼吸声信号特征来区分COPD 患者呼吸声。这些研究用不同方法通过分析呼吸声信号实现分类识别,但特征信号比较单一,基本采用从频域中提取特征向量作为识别诊断的依据,没有考虑到时域中信号的部分信息,达不到理想的识别效果。
本文对采集的呼吸声信号进行预处理,提取信号的短时能量,同时将希尔伯特黄变换(Hilbert-Huang Transform,HHT)代替梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)中的快速傅里叶变换(Fast Fourier Transform,FFT),对信号进行特征提取,再将两者进行融合得到新特征向量。在Matlab R2018a 环境下,本文融合算法与MFCC 和HHT-MFCC 利用SVM 进行实验,通过实验比较证明了该融合算法的合理性和优越性,并完成了COPD 患者和健康人呼吸声的分类识别。
1 特征提取
特征提取的过程就是用较少维数表征音频信号特征的过程,因此COPD 识别率的高低很大程度上取决于对呼吸声信号提取的特征参数是否准确。特征参数既要把呼吸声信号中的特性尽可能提取出来,还需要将COPD 患者和健康人呼吸声的特征参数有效地区分开,从而提高识别率。在特征提取之前,一般都需要进行预处理操作,减少无用信息和噪声的干扰,提高特征提取时的准确性。
1.1 预处理
音频信号是时变信号,但具有短时平稳性的特点,即在短时范围内可以作为稳态信号处理。通常将一段音频信号分为若干等长帧,帧的长度一般为10~30 ms。在音频信号识别系统中的研究与运算都是基于信号短时分析基础上实现的。为更好地提取特征参数,对音频信号进行模数转换(Analogueto-Digital Conversion,ADC)、预加重和分帧加窗等预处理操作。
1)模数转换,即将获取到的模拟音频信号转换为易处理的数字信号。
2)预加重。由于呼吸声的频率为60~1 600 Hz[8],而频率高于800 Hz 时会有6 dB 的衰减,因此通过预加重,提高呼吸声的高频部分,其传递函数为:

其中:μ∈[0.9,1],一般情况下取μ=0.937 5。
3)分帧加窗。由于音频信号在短时是平稳的[9],便于特征分析,需要对信号分帧,同时为保证每相邻两帧可以平滑过渡,需要对帧信号进行叠加,再对信号加入窗函数。帧移公式如式(2)所示,加窗信号yn(m)如式(3)所示。

式中:o为重叠长度;wlen为帧长度;c为帧位移量。

式中:w(k)为一个窗函数,本文采用汉明窗;x(m)为音频信号。
图1(a)、(b)分别为健康人和COPD 患者呼吸声的原始信号(以下呼吸声信号均采用一个呼吸周期内的呼吸声);图1(c)、(d)分别是上述两种呼吸声经过预处理后的信号。

图1 健康人和COPD患者呼吸声的原始信号与预处理后信号Fig.1 Original and preprocessed respiratory sound signals of healthy people and COPD patients
1.2 短时能量
短时能量是对音频信号的时域分析,能量大小能够反映出一段信号的特征。n时刻音频信号的短时能量En为:

式中:w(k)为窗函数,N为窗长,窗函数采用汉明窗,窗长取200个采样点。
图2(a)、(b)分别是经过预处理后的健康人和COPD 患者呼吸声的短时能量。
1.3 HHT-MFCC
希尔伯特黄变换是一种对非线性、非平稳信号的自适应性时频分析方法[10],主要由经验模态分析(Empirical Mode Decomposition,EMD)和希尔伯特谱分析(Hilbert Spectrum Analysis,HSA)两部分构成。EMD 是将预处理后的信号分解成若干固有模态函数(Intrinsic Mode Function,IMF)和残余分量;Hilbert 谱分析是对每个IMF 进行分析得到相应的Hilbert谱,反映了信号的瞬时频率,是傅里叶展开的一般化[11],所有IMF 的Hilbert 谱之和即为原始信号的Hilbert 谱。HHT 具有自适应和能体现信号非平稳特性的优点,克服了FFT 必须选取特定基函数以及只能全局分析的缺陷。
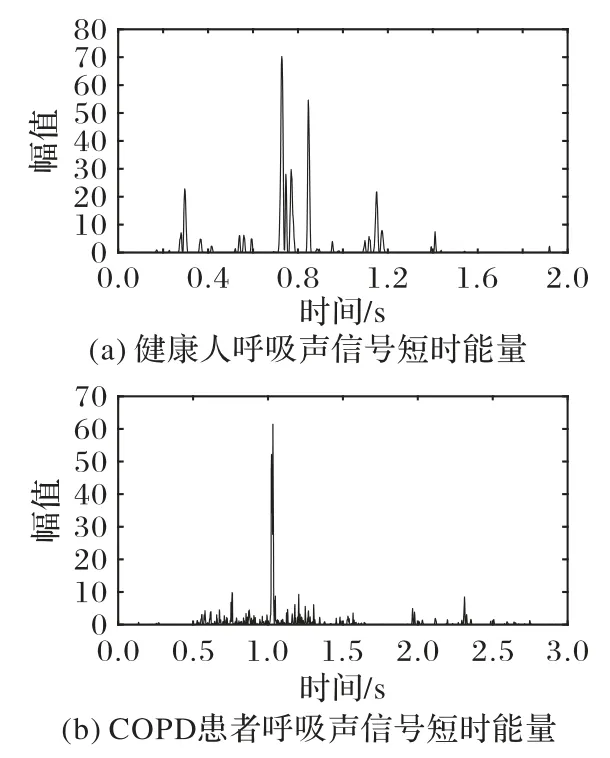
图2 经过预处理后的健康人和COPD患者呼吸声的短时能量Fig.2 Short-term energies of respiratory sound signals of healthy people and COPD patients after pretreatment
无论是线性的、非线性的、平稳的还是非平稳的复杂信号,都可以通过EMD得到若干IMF,但每个IMF需要满足两个条件[12]:
1)在整个数据序列中,极值点和过零点的数目必须相等或至多相差一个;
2)在任意时刻,局部极大值包络与局部极小值包络定义的局部平均包络线必须为零。
对于一个经过预处理后的呼吸声信号x(t),其EMD 步骤如下:
1)求出信号的局部极大值和局部极小值,通过三次样条插值得到由局部极小值构成的下包络线xlow(t)和由局部极大值构成的上包络线xhigh(t),上下包络线通过公式m1=计算局部平均包络线m1。
2)求出原信号x(t)与m1的差值,即h10=x(t) -m10。h10如果满足IMF 条件,则是一个IMF 分量;如果不满足,将其作为新的原信号,重复上述两个步骤,得到h11=h10-m11。每得到新差值,都要判断是否满足条件,若仍不满足则继续重复步骤,直到重复k次 时h1k=k1(k-1)-m1k满足IMF筛选停止原则:

式中:SD的典型值在0.2 到0.3 之间。第一个IMF 分量h1k记为c1。
3)由信号x(t)与c1可得到r1=x(t) -c1,将r1作为新信号重复上述三个步骤,即可得到第二个IMF,记作c2。重复步骤3),直到残余信号rn为单调曲线或第n个IMF 分量小于设定值时,则停止EMD 操作,这样就可以得到n个IMF 分量c1,c1,…,cn。因此得到原信号x(t)与IMF 分量和残余信号的关系:

图3是预处理后健康人呼吸声信号经EMD分解得到的从高频到低频的前五个IMF 分量,横坐标为时间,纵坐标为幅值。

图3 预处理后健康人呼吸声信号经EMD分解得到的从高频到低频的前五个IMF分量Fig.3 First five IMF components from high to low frequency obtained by EMD of healthy people respiratory sound signal after pretreatment
通过EMD 得到IMF 后,需要对分量进行Hilbert 谱分析,但主要信息多集中于高频分量,为减少计算量,选取前五个IMF 进行分析。同样地,由于残余信号属于低频信号,而高频信号的信息较为重要,一般情况会在谱分析中省略残余信号。因此经Hilbert谱分析的信号为:

式(7)的傅里叶变换为:

式(7)表示前五个IMF在时域中的频率和幅值,若在时间和频率平面中表示IMF 的幅值称为Hilbert 谱,用H(w,t)表示,表达式为:

得出Hilbert谱后,便可定义Hilbert边际谱H(w):

Hilbert谱是对每个IMF 在时频平面中求局部幅值并将每一时刻所有幅值加权,而Hilbert 边际谱是对整个信号的幅值的累积,因此它是对信号总幅值或总能量的度量。
在Hilbert 边际谱中,某一频率的幅值是每个IMF 幅值的累加,某一频率存在能量意味着在Hilbert 谱中时频平面上可能存在该频率的振动波,而在傅里叶频谱中某一频率处的幅值意味着信号中存在一个该频率的三角函数,某一频率存在能量意味着时间轴中存在一个正弦波或余弦波。这意味着FFT 只能反映整个时间轴中固定的基函数,而Hilbert 边际谱能更好地体现信号的非平稳性和局部特性。因此,用HHT 代替依据人耳听觉特性分析的MFCC 中FFT 可以提取更好的特征参数。
图4为HHT-MFCC的提取流程详细步骤为:
1)对采集的信号x(t)进行预处理,包括预加重、分帧加窗等操作,使信号x(t)变为较为平滑的信号x(m)并保持其短时稳定性。
2)将处理后的信号x(m)通过EMD 得到若干IMF,本文取前五个IMF进行HHT变换。
3)将变换后的信号幅值累加,得到Hilbert 边际谱H(w),再取平方计算出每帧Hilbert边际谱的能量。
4)通过Mel滤波器,将每帧谱能量转换成在Mel频域中的能量,进而求出n维特征向量。
5)对特征向量取对数和离散余弦变换(Discrete Cosine Transform,DCT),便可得到n维HHT-MFCC特征向量。
HHT-MFCC特征提取公式为:

其中:
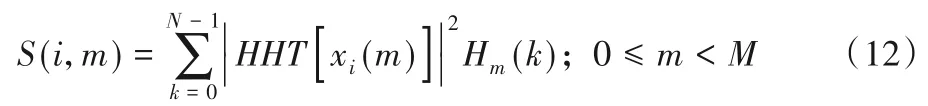
式中:n是DCT 后的谱线;m是指第m个Mel 滤波器(共有M个);k是频率中的第k条谱线;N是信号x(t)的长度;Hm(k)是Mel滤波器的频域响应;xi(m)是经预处理后第i帧音频信号。

图4 HHT-MFCC提取流程Fig.4 HHT-MFCC extraction flowchart
1.4 特征融合
呼吸声信号是一类较为复杂的信号,它包含了呼吸声音、心跳生理音和环境噪声。在经过预处理后,虽然噪声干扰降低了,但仅从频域分析提取信号特征不足以多角度提取信号特征向量,导致部分重要特征丢失,识别率不高。因此,本文采用HHT-MFCC 与短时能量融合算法得到呼吸声信号的新特征矢量,从两个不同角度分析呼吸声信号能更好地反映其特征。同时,由于计算短时能量的运算复杂度低,并不会给融合后的特征带来明显特征矢量维数。
特征融合就是将两种或两种以上音频信号的特征向量通过首尾相连的方式进行组合。通过HHT-MFCC 特征提取算法,可以得到呼吸声信号的特征向量为:

式中:FNM为第N帧、第M维HHT-MFCC;T1为N行M列的矩阵。该段呼吸声信号的短时能量特征向量为:

式中:N为帧数,T2为N行1 列矩阵。混合之前分别把每个特征矩阵进行重组,得到矩阵为:


2 SVM
SVM 是以统计学习理论为基础解决机器学习问题的方法,是从线性可分问题下的最优分类面发展而来的,解决了小样本、非线性和“过学习”等难题[13]。同时,它能根据有限的样本在模型的复杂性和学习能力之间寻求最佳折中。本文通过短时能量和HHT-MFCC 的融合算法提取特征向量,采用SVM进行分类识别,并与MFCC和HHT-MFCC算法进行比较。
假设训练样本集为Z={(x1,y1),(x2,y2),…,(xi,yi)},其中xi∈Rn,yi∈{1,-1},i=1,2,…,n,xi为第i个训练样本特征向量,yi是第i个训练样本分类标签[14]。具体训练步骤如下:
1)给定训练样本集满足式(17)且令Q(λ)为最大值:

式中:λi为拉格朗日乘子,当Q(λ)为最大值,λ取值为λ*。
3)根据w*和b*可得到超平面f(x),表达式为:

式中,K(xi,yi)为核函数,是SVM 的核心算法。核函数能将二维线性不可分的问题转化为高维线性可分问题,本文采用的核函数是径向基核函数(Radial Basis Function,RBF),表达式为:

3 实验与结果分析
本文采用的数据集是由葡萄牙和希腊的两个研究团队为生物医学健康信息学国际联盟(International Confederation on Biomedical Health Informatics,ICBHI)组织的挑战赛而制作的[15],其中包含了健康人和COPD 患者呼吸声。本文选取两类呼吸声来自60 名60~80 周岁的测试人员,共计429 条呼吸声样本,包括187 条健康人呼吸声样本和242 条COPD 患者呼吸声样本。为保证两类数据保持一致,呼吸声信号均选取8 000 Hz 采样率、帧长取20 ms、帧移取10 ms,窗函数采用汉明窗,窗长取200 个采样点。由于每段呼吸声均超过20 s,为方便计算,截取2~17 s 作为呼吸声信号。两类疾病各随机挑选出20、40、60、80 和100 个训练样本,其余作为测试样本使用。在Matlab R2018a 环境下,分别对MFCC、HHT-MFCC 和HHT-MFCC+Energy 三种算法进行比较,并对不同特征矢量的影响进行判断,表1和表2分别表示针对不同维数的三种特征提取算法的识别性能,维数表示HHT-MFCC 的特征矢量也是Mel 滤波器的个数,若为融合特征提取方法,则计算出倒谱系数后还需要加上一维短时能量特征。

表1 不同特征提取方法识别率(24维)Tab.1 Recognition rates of different feature extraction methods(24 dimensions)
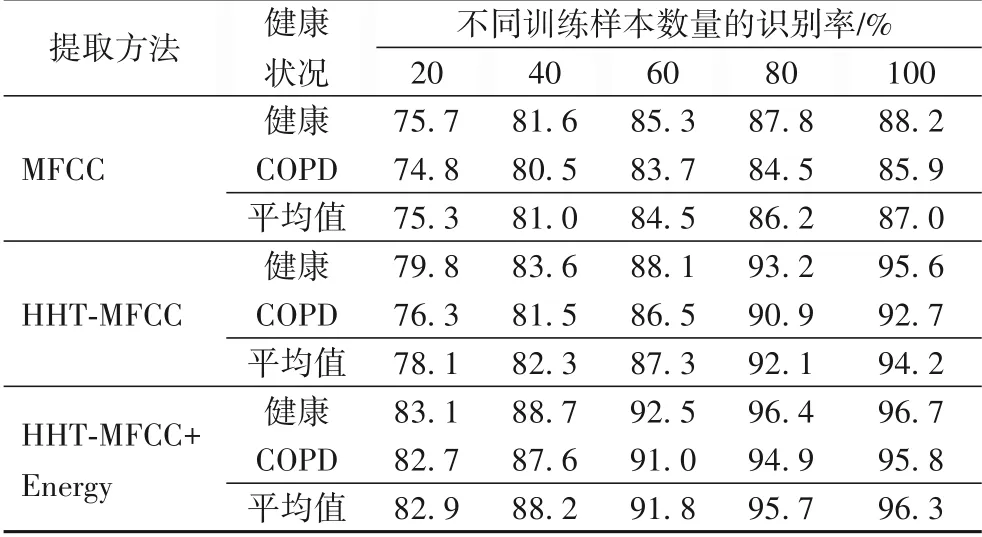
表2 不同特征提取方法识别率(12维)Tab.2 Recognition rates of different feature extraction methods(12 dimensions)
从实验结果来看,当特征提取的维数相同时,HHTMFCC+Energy 的融合算法识别率最高,这是因为该算法既能从多方面获取信号特征,同时包含时域和频域中的特点,使得特征描述更完整,也能改善MFCC 中只能全局分析的缺陷,因而识别率更高;对于融合算法,维数增加意味着获取到更多信号细节,两类声音能更好区分,因此24 维的特征提取方法要比12维的识别率高。同样地,相较于文献[6]中93.67%的识别率和文献[7]中83.6%的识别率,本文提出的方法分别提升了4.13 个百分点和14.2 个百分点。实验结果表明,HHTMFCC+Energy 特征提取算法结合SVM 的识别率最高,对COPD 患者呼吸声的识别更准确,特别是当特征矢量为24,且样本数量为100时,对COPD患者和健康人呼吸声的识别率分别能达到97.5%和98.1%,基本实现了利用呼吸声信号诊断被测人员是否患有COPD的目标。
4 结语
为了提高呼吸声信号识别率,增加COPD 疾病的识别率,本文提出了一种融合短时能量的HHT-MFCC 特征提取算法HHT-MFCC+Energy。该算法能准确地反映呼吸声信号非平稳特性和局部特征,也解决了仅从频域中提取特征的方法不能较为全面捕获音频信号特征的问题,基本实现了COPD 患者与健康人呼吸声的识别。本文预处理部分未能彻底分离呼吸声和心跳生理音,导致特征提取的过程中仍存在部分噪声,若能去除心跳声的干扰,则可以进一步提高特征向量表述信号的准确性,实现更好的识别效果。
