基于多图神经网络的会话感知推荐模型
2021-03-07杨程屹武志昊
南 宁,杨程屹,武志昊
(1.北京交通大学计算机与信息技术学院,北京 100044;2.中国民用航空局民航旅客服务智能化应用技术重点实验室,北京 100105;3.中国民航信息网络股份有限公司,北京 101318)
(*通信作者电子邮箱cyyang@travelsky.com)
0 引言
随着互联网的发展、因特网的普及,网络中的信息量呈现指数式增长,人们普遍面临信息过载[1]问题。为帮助用户在互联网中筛选有用的信息,推荐系统应运而生。为满足用户需求,许多推荐系统根据用户的历史行为产生推荐。然而在实际应用中,对许多身份未知的用户或新用户,他们的历史行为是不可知的,因此出现了基于会话(session)的推荐。会话指用户在一段时间内的浏览(或其他操作)行为[2],可表示为一个浏览序列,浏览对象称为物品(item)。目前,基于会话的推荐在电商平台[3]、新闻[4]、视频[5]等领域得到了广泛的应用。
基于会话的推荐问题的关键是建模会话中物品之间的关系。现有研究主要基于目标会话中的序列信息,对目标会话进行建模,捕获会话中物品间的关系,产生推荐结果;但仅对目标会话建模,缺乏对物品间全局关系的捕获和利用,模型捕获到的信息非常有限,难以达到理想的预测效果。在传统的推荐系统中,基于用户的协同过滤算法的思想是根据相似用户的喜好进行推荐[6],虽然基于会话的推荐这一研究领域用户的身份是未知的,但依然可以引入其他会话中的全局信息作为协同信息辅助预测。
针对上述问题,本文提出了基于多图神经网络的会话感知推荐(Multi-Graph neural network-based Session Perception recommendation,MGSP)模型。该模型主要由四部分构成:
1)构图模块:根据目标会话、训练集中的所有会话构建物品转移图(Item-Transition Graph,ITG)和协同关联图(Collaborative Relation Graph,CRG)。
2)图神经网络(Graph Neural Network,GNN)模块:对构造的ITG 及CRG 分别应用GNN,汇聚节点信息,生成两类节点表示,分别定义为个性化偏好物品表示及协同信息物品表示。
3)双层注意力模块:考虑到捕获到的两类节点表示中存在隐含的依赖关系,即个性化偏好与协同信息间的隐含关系,而自注意力机制能够捕获节点表示间隐含的依赖关系,具有强大的提取特征的能力,故该模块首先通过自注意力机制同时对两类节点表示建模,捕获个性化偏好与协同信息间的隐含关系;为捕获用户在会话中的长期偏好和当前兴趣,该模块还构造了第二层注意力机制,该注意力机制通过重点关注用户的当前兴趣,聚合节点表示,从而达到同时捕获会话中用户的长期偏好和当前兴趣的目的,得到会话级别的表示。
4)预测模块:考虑到不同特征在预测任务中的重要性不同,该模块使用注意力机制进行信息融合,得到最终的会话表示,预测下一个交互的物品。
本文的主要工作分为三个方面:
1)提出以构造多图的方式引入其他会话中的协同信息,结合个性化偏好信息与协同信息产生推荐,提高了推荐性能。
2)构造双层注意力模块:第一层注意力机制用于捕获个性化偏好与协同信息间的隐含关系;第二层注意力机制强调用户当前兴趣的重要性,可同时捕获会话中用户的长期偏好和当前兴趣,得到会话级别的表示。另外,还提出通过注意力机制进行多图的信息融合。
3)本文在电商领域两个真实公开数据集上进行了大量的实验,结果表明,本文提出的模型在各项指标上均优于比较的八个基准模型;此外,本文还在民航领域数据集上验证了模型的有效性。
1 相关工作
在推荐系统领域,基于会话的推荐问题自出现以来,始终是一个研究热点,其目标是根据用户在此次会话中与物品的交互记录(如点击行为序列、购买行为序列、出行目的地序列等)预测用户下一个交互的物品。本文将现有基于会话的推荐算法分为传统方法和基于深度学习的方法两大类。
传统方法为基于传统的机器学习思想提出的一系列的方法[7-10]。文献[8]为了解决兼顾计算性能与推荐质量的问题,提出了基于物品邻域的方法(item-based neighborhood methods),其中物品之间的相似性通过在同一个会话中共同出现的频率来衡量。基于矩阵分解(Matrix Factorization)的方法[9]是推荐系统中的通用方法,其基本思想是将一个用户-物品评价矩阵分解成两个低秩矩阵,分别表示用户和物品的潜在因子。由于在基于会话的推荐场景下,用户的身份是未知的,故矩阵分解方法不适用于该研究问题。基于马尔可夫决策过程的思想,文献[10]中提出了FPMCs(Factorized Personalized Markov Chains),将矩阵分解与马尔可夫链两种方法相结合,建模相邻交互物品间的顺序关系。总体上看,上述传统方法均忽略了序列数据中蕴含的物品间的转移模式。
随着深度学习的快速发展,研究人员开始尝试利用深度学习方法解决基于会话的推荐问题[11-19]。文献[13]首次引入循环神经网络(Recurrent Neural Network,RNN)进行基于会话的推荐,提出基于门控循环单元的GRU4Rec(Gated Recurrent Unit for Recommendation)模型。实验结果表明,通过RNN 能够捕获到会话中蕴含的物品间的转移模式,极大地提高了推荐性能。之后,文献[15]中依然采用RNN 的方法,并引入了一系列的优化方法,如数据增广(Data augmentation)、预训练(Pre-training)等,进一步提高了实验效果。基于RNN 的方法虽然对实验效果具有极大的提升,但这些方法忽略了会话中蕴含的用户的购物目的或偏好,对于会话中的信息挖掘仍然不够充分。
文献[16]中为解决基于RNN 的方法只考虑到会话中的转移模式,忽略了用户在会话中的主要目的这一问题,提出了NARM(Neural Attentive Recommendation Machine)模型,结合RNN 与注意力机制,同时捕获用户的序列行为特征及主要目的。之后,文献[17]中提出了STAMP(Short-Term Attention/Memory Priority)模型,该方法使用简单的多层感知机(Multi-Layer Perceptron,MLP)网络设计了一种注意力机制,可以有效地捕获用户的长期偏好和当前兴趣,但该方法抛弃了会话中的序列行为特征。
最近,文献[18]中基于图神经网络(Graph Neural Network,GNN)强大的节点表示学习能力,提出了SR-GNN(Session-based Recommendation with Graph Neural Network)模型,将用户的序列行为建模为图数据,使用强大的图神经网络捕获物品间的转移模式,然后通过一个简单的注意力机制捕获用户的长期偏好和当前兴趣。之后,文献[19]中提出了GC-SAN(Graph Contextual Self-Attention model based on graph neural Network),采用GNN 及自注意力机制相结合的方式,分别捕获会话中相邻物品间的关系及物品间的全局依赖关系。上述方法主要基于目标会话中的信息进行推荐,未显式地建模其他会话中的协同信息。为此,本文提出了基于多图神经网络的会话感知推荐模型MGSP,能够有效地利用个性化偏好信息及协同信息解决基于会话的推荐问题。
2 基于多图神经网络的会话感知推荐模型
本文MGSP 模型的预测流程如图1 所示。模型的输入是用户当前会话。首先需要获取物品级别的表示,方法是基于构图模块构建图结构数据,然后基于GNN 模块,通过GNN 强大的节点表示学习能力学习物品的表示。由于用户的当前会话中蕴含的信息非常有限,本文在根据当前会话构图的同时,用训练集中的所有会话构建全局图并提取出相应的子图,然后分别应用GNN 从两张图中学习获得两类节点表示,即为物品级别的表示。获得物品级别的表示后,需要对物品级别的表示进行聚合,获得会话级别的表示。本文设计了一种双层注意力模块来获取会话级别的表示,该模块的作用在于对两类节点表示的依赖关系进行建模,并从中提取重要的信息,获得会话级别的表示。在获得会话级别的表示之后,通过预测模块获得最终的预测结果。预测模块的主要作用是基于注意力机制对两张图中学习到的信息进行信息融合,并预测下一个交互的物品。基于上述流程分析,本文模型结构如图2 所示,主要由四部分构成:ITG 与CRG 构建模块(见2.2 节),图神经网络模块(见2.3节),双层注意力模块(见2.4节)和预测模块(见2.5节)。

图1 MGSP模型的预测流程Fig.1 Prediction flowchart of MGSP model

图2 MGSP模型的结构Fig.2 Structure of MGSP model
2.1 问题描述
基于会话的推荐是指基于用户在此次会话中与物品的交互记录(如点击行为序列、购买行为序列、出行目的地序列等)预测用户下一个交互的物品或地点。下面给出本文的符号定义。
集合V={v1,v2,…,v|V|}表示在所有会话中出现过的物品的集合,为了将所有物品映射到统一的嵌入空间,每个物品vi对应初始嵌入si∈Rd,d表示嵌入的维度;序列S={v1,v2,…,vn}表示一个会话,其中,n表示会话S的长度,vi∈V,vi在会话S中按照用户交互的时间顺序排列。本文MGSP 模型的目标是已知用户当前会话为St={v1,v2,…,vt},预测用户在第t+1 时刻会与哪个物品发生交互,即预测vt+1。因此,对每个输入的会话,MGSP 模型会输出候选集中每个候选物品的偏好值=,其中表示候选物品vi的偏好值。由于推荐系统一般会向用户产生多个推荐,因此可以从预测结果中选择偏好值最高的N个物品构成推荐列表。
2.2 物品转移图与协同关联图构建模块
在该模块,本文介绍如何通过目标会话、训练集中的所有会话构建物品转移图(ITG)和协同关联图(CRG)。ITG 中蕴含着用户的个性化偏好信息,CRG中蕴含着丰富的协同信息。
ITG 为有向加权图,表示为Gitg=(V,Eitg),其中,V表示在目标会话S中出现过的物品集合,Eitg表示物品间的有向边集合。Gitg的构造方法如下:在会话S中,若用户与物品vi发生交互后又与物品vj发生了交互,则对应的边权加1。
CRG 为无向加权图,表示为Gcrg=(V,Ecrg),其中,V表示在目标会话中出现过的物品集合,Ecrg表示物品间的无向边集合。为引入其他会话中的信息作为协同信息,根据训练集中的所有会话S构建全局的无向加权图。首先以训练集中出现过的所有物品为节点,然后根据物品在会话中的共现关系构边,即对训练集中的每一个会话S,若物品vi与vj共同出现在S中,则(vi,vj)对应的边权加1。最后,根据目标会话中出现的物品集合,从全局图中抽取出相应的子图,得到Gcrg。
2.3 图神经网络模块
在该模块,本文介绍如何通过GNN 学习节点的表示。文献[20]中基于RNN 的思想,在GNN 中引入了门控单元,提出了门控图序列神经网络(Gated Graph Sequence Neural Network),该方法极大地增强了GNN 处理序列数据的能力。下面以ITG 为例,介绍如何通过门控图序列神经网络学习节点的表示。
在图Gitg中为节点vi在t次更新之后的表示,其更新函数如下:

2.4 双层注意力模块
在该模块,介绍如何对Sitg和Scrg进行处理,生成不同意义的会话级别的表示。该模块设计双层注意力机制:第一层注意力机制捕获个性化偏好与协同信息间的隐含关系;第二层注意力用于捕获用户的长期偏好和当前兴趣,最终得到会话级别的表示。
自注意力机制能够捕获节点表示间隐含的依赖关系,具有强大的提取特征的能力。故该模块首先通过自注意力机制同时对两类节点表示建模,捕获个性化偏好与协同信息间的隐含关系。将图神经网络模块的输出Sitg与Scrg并入一个列表,得 到Sall=[sitg,1,sitg,2,…,sitg,n,scrg,1,scrg,2,…,scrg,n],之 后Sall的更新函数如下:
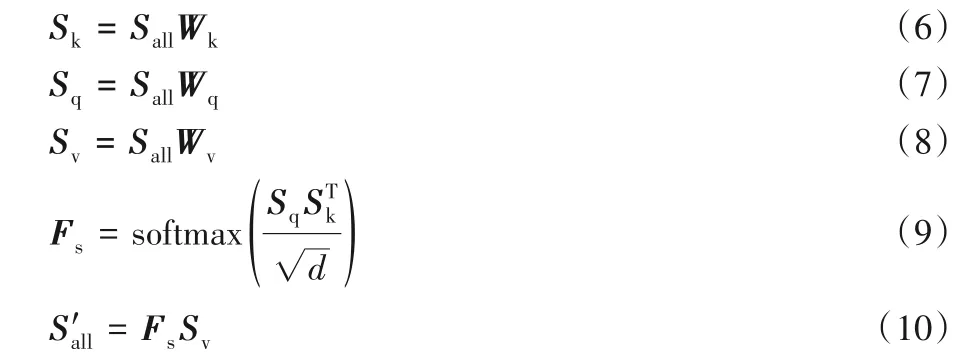
式(6)~(8)中,Wk、Wq、Wv∈Rd×d均为可训练参数,用于将Sall投射为三个矩阵,作为自注意力模块的输入;式(9)中,Fs∈Rd×d为自注意力评分矩阵,除以d的平方根是为了避免向量内积的值过大,softmax 函数对自注意力评分进行正则化处理;式(10)根据自注意力评分矩阵更新物品表示,得到虽然自注意力机制能够通过合适的权重聚合节点的信息,但它仍然是一个线性模型。本文引入带ReLU 激活函数的两层前馈神经网络,赋予模型非线性的能力,并且在前馈神经网络之后添加一个残差连接操作,这样可以有效利用低阶特征,使模型效果更加稳定[21],具体形式如式(11)所示。
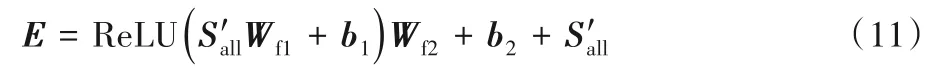
其中:Wf1,Wf2∈Rd×d为可训练的参数矩阵;b1,b2∈Rd为可训练的偏差向量;ReLU(•)为ReLU激活函数。
自注意力模块之后,从E中可得到经过自注意力机制处理之后的两类物品表示:个性化偏好物品表示取E的前n行,记为Hitg=[hitg,1,hitg,2,…,hitg,n];协同信息物品表示取E的后n行,记为Hcrg=[hcrg,1,hcrg,2,…,hcrg,n]。
为捕获用户在会话中的长期偏好和当前兴趣,该模块构造第二层注意力机制。该注意力机制通过重点关注用户的当前兴趣,聚合节点表示,从而达到同时捕获会话中用户的长期偏好和当前兴趣的目的,得到会话级别的表示。下面以Hitg为例,介绍聚合流程。考虑到列表中每个物品具有不同的重要性,而用户当前交互的物品可表示当前兴趣,应重点关注,将列表中的每个物品与用户当前交互的物品计算相似度,以此衡量每个物品在会话中的重要性。计算过程如式(12)和式(13)所示:

其中:W1,W2∈Rd×d;u,b∈Rd均为可训练参数;σ(•)表示sigmoid 函数。通过上述注意力机制,得到Hitg和Hcrg对应的会话级别的表示,分别记为hitg和hitg。
2.5 预测模块
在预测模块,虽然会话级别的表示hitg和hitg中蕴含着用户的长期偏好和当前兴趣,但为了进一步强调用户当前兴趣的重要性,引入会话中最后一个交互物品的表示增强用户的当前兴趣信息,即引入物品表示hitg,n、hcrg,n。四个表示合并得到一个维度为4 ×d的数组,为便于表示,将该数组记为H=[h1,h2,h3,h4]=[hcrg,hcrg,n,hitg,hitg,n]。考虑到四个表示在预测时发挥的重要性不同,借鉴2.4 节中的第二层注意力机制,计算H中每个嵌入与hitg,n的相似度,以此衡量四个表示的重要性,实现信息融合。计算过程如式(14)、(15)所示。

对候选集中的每个候选物品vi,其偏好值计算公式如式(16)所示;之后用softmax 函数将偏好值向量正则化为0 到1的值,如式(17)所示;损失函数如式(18)所示。

其中:yi为one-hot 向量,表示用户真实交互的物品;θ为可训练的参数集合;λ为正则化系数。
3 电商领域实验与结果分析
3.1 实验数据集
为验证MGSP 模型的有效性,选择Diginetica 和Yoochoose两个公开数据集进行评估实验。Yoochoose 数据集(http://2015.recsyschallenge.com/challege.html)由RecSys’2015 挑战赛提供,其数据为电子商务网站六个月的用户点击会话记录;Diginetica 数据集(http://cikm2016.cs.iupui.edu/cikm-cup)由CIKM’2016提供,本文只用到了其中的交互型数据。
对两个数据集,仿照文献[10]的数据处理方式,首先过滤长度为1的会话及出现次数小于5次的物品,并过滤仅出现在测试集中的物品。经过上述预处理:Yoochoose 数据集中剩余7 981 580 个会话,37 483 个物品;Diginetica 数据集中剩余204 771 个会话,43 097 个物品。仿照文献[15]的方法,对Diginetica 数据集会话中的物品按时间戳排序,构成用户按时间顺序排列的交互序列。仿照文献[11]中的方法,对两个数据集按照如下方法进行扩充:对于会话S={v1,v2,…,vn},可以获得子序列S={v1,v2},S={v1,v2,v3},…,S={v1,v2,…,vn},其中每个子序列的最后一个物品作为标签数据,其余物品序列作为输入数据,构成一个样本。在Yoochoose数据集中,选择最后一天的数据作为测试集;在Diginetica 数据集中,选择最后一周的数据作为测试集,余下的数据作为训练集。另外,对Yoochoose 数据集,仿照文献[16]和文献[17]中的方式,对训练集中的会话按时间排序,选择最后1/64的数据作为实际的训练集。有关两个数据集的统计数据如表1所示。

表1 数据集的统计信息Tab.1 Statistics of datasets
3.2 实验结果度量标准
本文选用精确率(Precision)、平均倒数排名(Mean Reciprocal Rank,MRR)和归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)作为模型评测标准。
P@N用于衡量推荐系统的预测准确性,表示推荐排名列表中前N个推荐物品包含正确的物品的样本数占总样本数的比例,计算公式为:

其中:n表示测试集中样本总数;nhit表示在前N个推荐物品中包含正确的物品的样本数。
MRR@N用于衡量样本中正确物品在推荐排名列表中的排名,排名越靠前,MRR 的值越大;若正确物品未包含在推荐列表中,则对MRR的增益为0。计算公式为:

其中:n表示测试集中样本总数;M表示前N个推荐物品中包含正确的物品的样本集;ranki表示物品i在推荐排名列表中的排名。
NDCG@N综合衡量推荐结果的准确性以及正确物品在推荐排名列表中的排名,是一种全面的Top-N推荐准确率评价指标,计算公式为:

其中:R(s,p)的值为0或1,针对会话s,若推荐列表中的第p个物品为正确预测物品,则R(s,p)为1,否则为0。IDCG@N(s)是进行归一化的参数,其取值是DCG@N(s)能达到的最大值,即正确预测的物品在推荐列表中排第一名时对应的DCG@N(s)值。
本文实验中取N=20。
3.3 对比模型
为了验证MGSP 模型的有效性,本文选择以下模型作为对比模型:
1)POP(Popularity):根据物品在训练集中出现的频率进行推荐。
2)Item-KNN(Item Based K-Nearest Neighbor)[8]:根据会话中点击过的物品推荐相似的物品,其中物品间的相似度通过物品在训练集所有会话中共同出现的次数来衡量。
3)FPMC[10]:结合矩阵分解与马尔可夫链两种方法,建模相邻交互物品间的顺序行为关系。该方法不仅减少了参数,还能够同时捕捉时间信息和长期的用户喜好信息。
4)GRU4REC[13]:首次引入RNN 来解决基于会话的推荐这一领域的问题,采取一定的策略提高训练效率,并设计了一种基于排名的损失函数。
5)NARM[16]:采用RNN 与注意力机制相结合的方法,使用RNN 捕获用户的序列行为特征,使用注意力机制捕获用户的主要目的。
6)STAMP[17]:抛弃会话中的序列行为特征,强调用户当前兴趣的重要性,设计了一种注意力机制,有效地捕获用户的长期偏好和当前兴趣。
7)SR-GNN[18]:将用户的序列行为建模为图数据,通过GNN 捕获物品间的转移模式,然后通过注意力机制捕获用户的长期偏好和当前兴趣。
8)GC-SAN[19]:在SR-GNN的基础上将普通注意力机制改为自注意力机制,通过GNN 捕获物品间的局部依赖关系,通过自注意力机制捕获物品间的全局依赖关系。
对比模型的维度均设为100,取训练过程中的最优结果,每个实验重复10次,并取平均值作为最终结果。
3.4 实验参数设定
本文设定隐向量的维度d=100,学习率lr=0.001,每迭代3 次学习率衰减10%,正则化系数λ=10-5,训练批量设定为128,使用Adam 算法优化模型参数,迭代次数设定为30,并设计了早停策略。使用均值为0、标准差为0.1的高斯分布初始化所有参数。
3.5 结果分析
为验证MGSP 模型的性能,本文设计了4 组实验,并对实验结果进行了分析。
第一组实验将MGSP 模型与其他对比模型进行对比,表2给出了MGSP 模型与其他对比模型在两种数据集上的实验结果。从表2可以看出:
1)GRU4REC 在性能上远优于Item-KNN、FPMC 等传统方法。这表明传统方法难以捕获到序列数据中蕴含的丰富的信息,而RNN 能够有效地捕获物品序列中物品间的转移模式,给出更精确的推荐。
2)基于注意力机制的NARM、STAMP 在效果上要优于GRU4REC,表明引入注意力机制有利于捕获会话中蕴含的用户偏好。STAMP 提出基于用户最后一次交互的物品捕获用户的当前兴趣,结合用户的长期偏好给出推荐,且取得了不错的效果,这表明会话中的信息具有时效性,用户的当前兴趣对于精确推荐非常重要。
3)SR-GNN 和GC-SAN 引入GNN 来捕获物品间的转移模式,并通过注意力机制捕获用户的偏好,取得了不错的效果,且其效果在较大程度上优于GRU4REC、NARM,体现了GNN捕获物品间的转移模式的强大能力。
4)对比本文MGSP 模型与其他模型可以看出,MGSP 模型在每一个数据集的每一项指标上均具有至少1 个百分点的提升,表明引入其他会话中的协同信息进行信息扩充是非常有必要的,也表明本文MGSP 模型可以有效地建模个性化偏好信息及协同信息。

表2 不同模型在两个数据集上的性能对比 单位:%Tab.2 Performance comparison of different models on two datasets unit:%
第二组实验针对MGSP 模型进行消融实验,验证模型中主要组成部分的有效性。MGSP_1表示只对ITG 建模,即只建模用户的个性化偏好信息;MGSP_2表示只对CRG 建模,即只建模用户的协同信息;MGSP_3 表示去掉双层注意力模块的第一层自注意力模块,即不考虑个性化偏好信息与协同信息间的隐含关系;MGSP_4 表示去除模型中预测模块的注意力机制,使用mean-pooling 操作来进行信息融合。各模型实验结果如表3所示,从表3中可以看出:
1)MGSP_1在各项指标上均优于MGSP_2,表明在产生推荐时用户的个性化偏好信息比协同信息重要,体现了个性化推荐的重要性。
2)对比MGSP_2 与MGSP 可以看出,当对两个图同时建模时可以取得更好的效果,表明引入其他会话中的协同信息,可以起到很好的信息补充作用。
3)对比MGSP_3 与MGSP,前者的性能明显下降,表明自注意力模块能够有效地捕获个性化偏好信息与协同信息间的隐含关系,提高推荐准确性。
4)对比MGSP_4 与MGSP,前者的性能明显下降,表明本文提出的注意力机制可以有效地进行信息融合,提高模型的性能。
通过上述分析可以得出,MGSP 模型中的各个主要组成部分都是有效的。
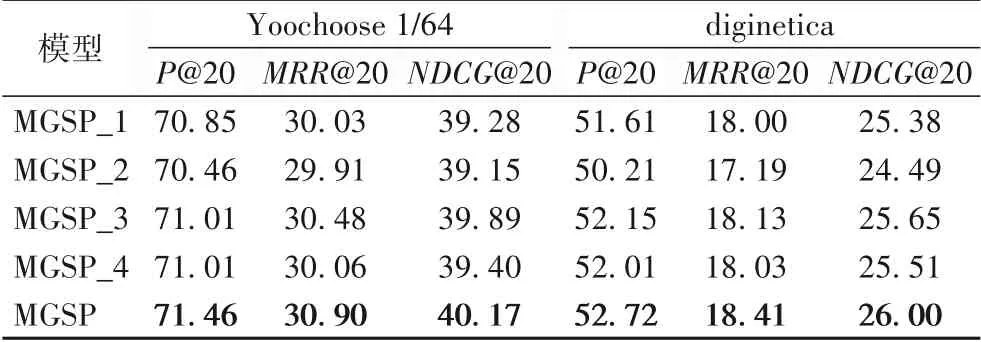
表3 MGSP模型的消融实验结果 单位:%Tab.3 Ablation experimental results of MGSP model unit:%
第三组实验测试在不同会话长度下的MGSP 模型性能。由于SR-GNN 和GC-SAN两个模型在对比模型中表现最好,所以本组实验选择SR-GNN 和GC-SAN 作为对比模型。设定会话长度范围为1 到20,选择P@20 为评估指标,在两个数据集上进行实验,实验结果如图3 所示。对比三个模型在长会话和短会话上的表现,可以发现在Diginetica 数据集上会话长度为2 时预测效果最好,在Yoochoose 1/64 数据集上会话长度为3 时预测效果最好;而随着会话长度的增加,三个模型的预测效果呈下降趋势,但MGSP 模型的下降趋势最为平缓,且在会话较长时效果明显好于SR-GNN 和GC-SAN。原因可能是由于会话长度较长时,很难捕获到用户的兴趣转移模式或意图,导致模型效果降低。另外,可以很明显地发现,在大部分会话长度下,MGSP模型的性能明显优于SR-GNN和GC-SAN。
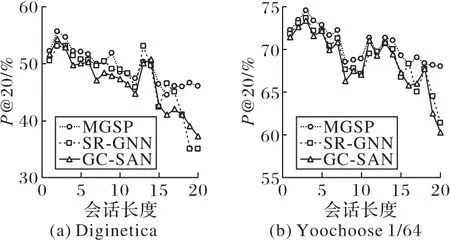
图3 不同会话长度下的模型性能对比Fig.3 Performance comparison of different models under different session lengths
第四组实验测试在嵌入维度d取不同值时,MGSP 模型的性能。本组实验仍然选择SR-GNN 和GC-SAN作为对比模型。设定嵌入维度d的取值范围为10 到120,选择P@20 为评估指标,在两个数据集上进行实验,实验结果如图4 所示。从图4可以看出,随着嵌入维度d的增加,三个模型的性能均有所提升,但当嵌入维度d达到60时,三个模型的性能不再随着嵌入维度d的增加而提升。另外,可以很明显地发现,在各个嵌入维度下,MGSP模型的性能均优于SR-GNN和GC-SAN。
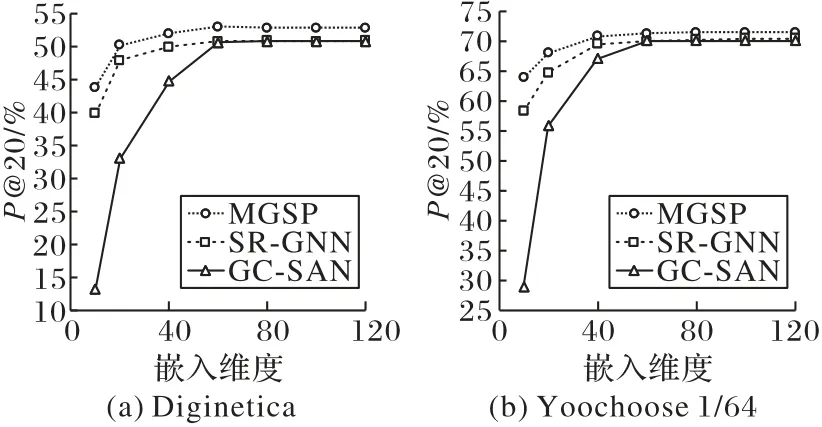
图4 不同嵌入维度下的模型性能对比Fig.4 Performance comparison of different models under different embedding dimensions
4 民航出行领域实验结果
为验证MGSP模型在应用上的可扩展性,将MGSP模型迁移至其他领域,验证它在其他领域的数据集上是否仍然具有非常好的性能。在民航领域,旅客出行记录通常较少,与基于会话的推荐场景类似,因此本文将MGSP 模型应用于民航旅客出行目的地预测问题来测试模型的性能。该实验模块会话由旅客历史出行序列数据构成,目标为预测旅客下一次出行的目的地城市。由于本实验将旅客出行目的地预测问题视为会话推荐问题,故实验中未涉及其他特征信息,如年龄、性别等,在实际应用中可以通过引入额外特征信息进一步提升预测准确性。本实验使用的数据为经过脱敏处理的旅客出行记录,本文将该数据集称为HVR(Historical Voyage Records)。HVR 为10 万旅客在三年零六个月的出行记录,涉及机场426个,完整航程记录264 647条,航段470 239个。首先筛选历史总航段数不低于3 的航程记录,然后按照如下规则划分训练集、测试集:对每一位旅客的历史行程序列,将最后一次出行构成的样本作为测试集,之前的样本作为训练集。最终获得训练集155 179条,测试集34 535条。
本实验仍选用P@N、MRR@N和NDCG@N作为模型评测标准,由于机场的数量较少,故展示N为3 和5 的情况下的实验结果。本实验选择的对比模型为两个前沿模型SR-GNN 和GC-SAN,实验结果如表4 所示。从表4 可以看出,SR-GNN 和GC-SAN 在该数据集上表现良好,但MGSP 模型通过多图的构造,利用了更加丰富的信息,在各项指标结果上均明显优于SR-GNN 和GC-SAN 模型,具有约3 个百分点的提升。通过本实验也验证了MGSP 模型在不同领域都具有较好的预测性能。

表4 不同模型在HVR上的性能对比 单位:%Tab.4 Performance comparison of different models on HVR unit:%
5 结语
本文提出了基于多图神经网络的会话感知推荐模型MGSP,该模型通过构造多图引入其他会话中的信息作为协同信息,并设计了一种图神经网络与注意力机制相结合的方法,同时对用户的个性化偏好信息以及协同信息进行建模,最后通过注意力机制对两类信息进行融合,生成精确的推荐结果。分别在电商和民航两个场景下进行了对比实验,实验结果表明,本文的MGSP 模型在各项指标上均优于SR-GNN、GC-SAN等基准模型。另外,本文还通过消融实验验证了模型中各组成部分的有效性。在下一步的研究工作中,将研究如何在引入协同信息时对会话进行筛选,希望通过引入相似度或相关性较高的会话来进一步提升推荐准确性。
