基于最优误差自校正极限学习机的高频地波雷达RD谱图海面目标检测算法
2021-03-04张万栋李庆忠黎明武庆明
张万栋 李庆忠 黎明 武庆明
近几年,高频地波雷达(High frequency surface wave radar,HFSWR) 理论与技术发展迅速[1].与其他海事监测方式相比,HFSWR 利用高频垂直极化电磁波沿海面绕射效应可实现超视距目标探测,具有观测距离远,覆盖面积大,工作全天候等优点.然而,HFSWR 自身存在一定缺陷,处在高频段的雷达具有极其复杂的电磁波环境,这将导致雷达回波中除具有有用信息外,还含有海浪与电磁波谐振产生的海洋表面回波,经电离层反射后被雷达接收而造成的电离层回波,这些干扰回波对HFSWR 目标检测产生严重影响,因此,如何从复杂环境中准确提取海面目标一直是HFSWR 海事监控面临的一个难题.
在高频地波雷达海面目标检测方面,国内外学者提出很多经典算法,最经典的当属Conte 等[2]提出的恒虚警率(Constant false-alarm rate,CFAR)算法,该算法假设在均匀的Rayleigh 分布的杂波背景下,计算出参考单元的估计值,再利用该估计值对和它独立同分布的检测单元的背景模型进行合理评价,该检测算法在有斯特林起伏目标的检测环境下具有较好的识别水平.然而,该算法的检测条件非常局限,在杂波模型未知和背景复杂(尤其是杂波边缘复杂) 的情况下,检测效果并不理想,此时算法的检测虚警率很高.在此基础上,Rohling 等[3−4]提出了OS-CFAR 算法,该算法首先对参考单元内的参考值排序,选取其中的某个参考值作为背景杂波功率的估计值,该算法的优点在于:通过对参考值的排序,可以有效避开“野值”对估计值的干扰,该算法比经典CFAR 算法具有更好的抗干扰能力,且在杂波边缘也对点目标具有较好的目标识别效果.2012 年,桂仁舟[5]提出了一种二维恒虚警算法,该算法在一维CFAR 算法的基础上,针对距离-多普勒(Range doppler,RD) 谱图中噪声和杂波随时间变化的特点,于距离方向和多普勒频移方向分别进行一次CFAR 检测,对点目标具有较好的识别性能.2014 年,梁建[6]在二维恒虚警算法上,结合分段曲线拟合,进一步做出改进,提高了CFAR 对高频地波雷达的检测性能.总之,基于CFAR 的目标检测算法可定量分析检测的结果,应用十分广泛.但在强杂波和复杂背景噪声背景下,海面目标点的信噪比会大大减弱,从而造成CFAR 方法检测性能大大下降.
在恒虚警率算法的基础上,国内外学者提出了很多改进算法体系.Grosdidier 等[7]提出了一种基于RD 谱图形态成分分析的舰船点目标识别算法,该算法结合稀疏表达技术,利用点目标的形状和灰度分布特征进行目标检测.Jangal 等[8−9]通过分析目标点和噪声的几何特征和能量差异,提出了一种基于小波变换的RD 谱图目标点识别算法.Li 等[10]针对Jangal 算法存在的问题,提出了一种改进算法,该算法在提高目标检测率的基础上,显著降低了目标虚警率,具有一定的普适性.除此之外,Wang 等[11]提出了一种基于斜轴投影的空间盲滤波算法,该算法利用目标点和海杂波在空域的回波差异,能快速准确地从富含海杂波的处理环境中提取目标点信息.Zhang 等[12]将逆相变(Reverse phase transition) 的概念引入杜芬振子(Duffing oscillator)中,提出了一个能显著提高目标点检测率的HFSWR 目标检测算法.Dakovic 等[13]结合目标点与其他干扰(杂波,背景噪声) 的时频差异,提出了能多方位识别目标的HFSWR 检测算法.然而,这些算法只注重目标检测率和虚警率且有较高的算法复杂度,实时性差.
通过上述分析,可知现阶段RD 谱图海面目标检测算法的主要问题有三个方面:首先是检测实时性差;其次是目标检测率低;最后,这些算法中都或多或少存在人为设定的阈值,如CFAR 的检测门限,小波变换的小波尺度,稀疏表达中完备字典集的选取等,这些根据经验选取的因素,对算法的检测性能有极大的影响.因此,本文从全新的机器学习角度,提出一种自适应性强,实时性好,检测精度高的RD谱图海面目标识别算法.一方面,为了提高算法的海面目标识别精度,提出一种全新极限学习机算法网络:最优误差自校正极限学习机(Optimized error self-adjustment extreme learning machine,OESELM),该网络能将RD 谱图中被杂波干扰的“虚弱目标”识别出来.同时,为了提高高频地波雷达RD谱目标检测的实时性能,本文提出了一种基于两级级联分类器的目标识别策略,该策略能从简至繁,逐层将目标从RD 谱中剥离出来.
由黄广斌教授提出的极限学习机(Extreme learning machine,ELM) 网络,具有训练速度快,泛化性能好的特点,在很多领域中应用广泛.然而,该网络仍存在以下缺点:1) 隐层神经元随机确定的权值对网络的分类性能有很大的影响,且隐层神经元个数无法通过一个有效算法计算获得.在相关文献[14−17]中人们虽然提出了一些关于此网络的优化算法,但这类算法将确定隐层神经元个数的步骤转化为优化问题,步骤繁琐,有较高的时间成本.2) 在极限学习机网络的学习训练中,正则系数起到重要作用,需人们在分类识别前手动确定大小.然而当前却没有一种有效的参数选择方式,大多情况下人们采用试错法的方式来选择正则系数的大小[18−19].
针对目前高频地波雷达检测方法存在的问题和标准ELM 存在的问题,本文贡献主要有以下两方面:
1) 本文提出一种改进极限学习机算法:最优误差自校正极限学习机(OES-ELM).该网络具有以下优点:首先,该算法隐层权值矩阵不是随机确定,而是通过输出层误差矩阵的反向回传矩阵更新获得,因此该网络可以更好地学习训练集的内在知识,达到更好的泛化性能.其次,OES-ELM 网络提供了一种隐层神经元自适应确定算法,且可用极少的隐层节点达到其他ELM 网络的识别精度.最后,OES-ELM 算法的正则系数对最终网络的分类性能并不敏感,人们可以在训练前随机设定正则项数值大小.
2) 在工程上,本文提出一种基于两级级联分类器的RD 谱图海面目标识别算法,第一级采用简单的线性分类器,快速将背景成分从RD 谱图中滤除,提高算法的实时性;第二级采用OES-ELM 网络,精准地将目标点从非背景成分中辨识出来,保证目标检测的准确性.同时,整个算法需人为设定的参数较少,算法具有较好的自适应性.
本文第1 节介绍高频地波雷达RD 谱图目标检测算法的总体框架;第2 节给出基于灰度特征的一级线性分类器算法;第3 节介绍Haar-like 高阶特征的提取过程;第4 节介绍提出的最优误差自校正极限学习机算法;第5 节阐述实验评估结果;最后总结全文.
1 海面目标检测算法总体框架
图1 是一幅经典高频地波雷达RD 谱图,其中不仅含有海面目标点,同时还含有各种杂波和背景噪声.其中海杂波与地杂波在距离向上呈脊状结构;电离层杂波在多普勒频移向上呈条形,带状的形态特征;目标点由于幅度局部占优并在处理过程中受窗函数作用,在RD 谱图中表现为具有一定幅度的孤立峰值点.因此,在RD 谱中,海杂波、地杂波、电离层杂波和目标点的边缘形态具有显著差异.若从RD 谱中选取一个大小合适的矩形窗口,海杂波、地杂波在该窗口中为竖直条状,电离层杂波在该窗口呈水平条状,目标为孤立点.故而可首先用一种能描述图像点特征的算子来进行特征提取,再运用分类器对其进行分类,可以将目标点和其他干扰成分有效分离.
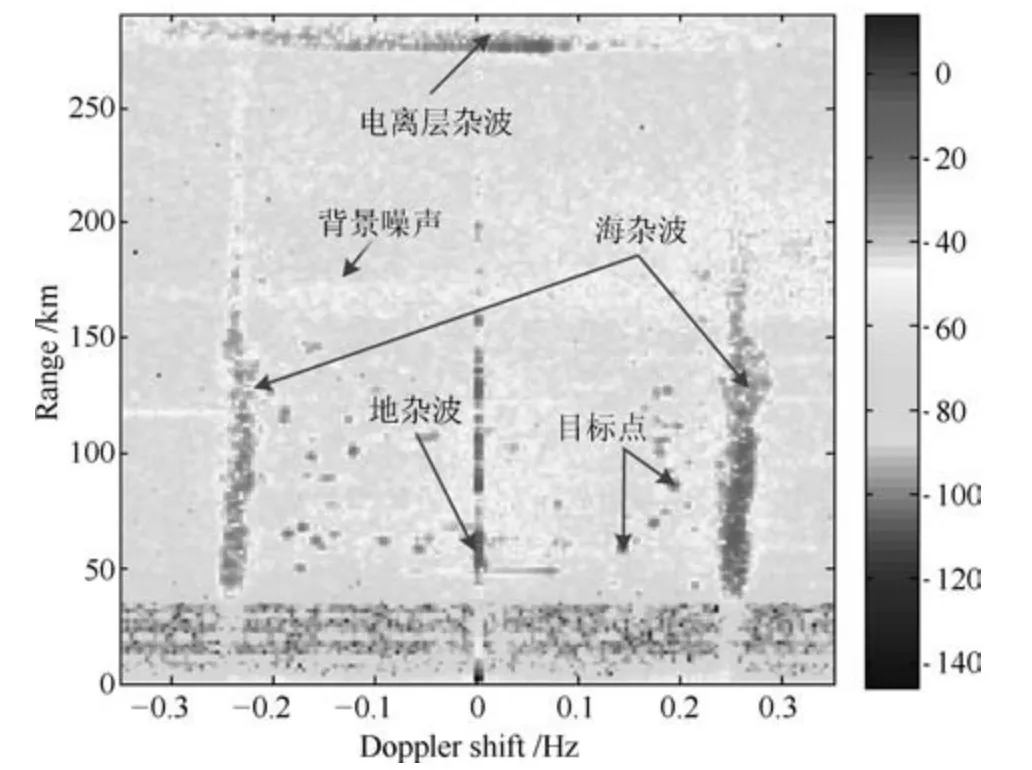
图1 经典RD 谱图Fig.1 A typical RD image
此外,为了提高高频地波雷达RD 谱目标检测的实时性能,本文提出了一种基于两级级联分类器的目标识别策略.根据相关文献[20−21],级联分类器可以在保证分类精度的前提下,大大降低算法所需时间.本文结合OES-ELM 网络和级联分类策略,提出的目标检测算法如图2 所示.

图2 算法总体框架Fig.2 The framework of the proposed method
本文提出的目标检测算法主要由两个分类器构成:一级分类器和二级分类器.前者是一个输入特征为灰度值的线性分类器,主要负责目标点潜在区域的提取,用以区分非背景成分(目标、杂波) 和背景成分,详情请见第2 节;后者为本文提出的OESELM 分类器,其输入特征为49 维的Haar-like 高阶特征,主要任务是进行目标点的精确检测,从非背景成分中区分目标点和非目标点,该部分的详细情况见第3 节和第4 节.
2 线性分类器
在一幅灰度RD 谱图中,通过观察可发现背景区域像素的能量强度比目标点和杂波低,即RD 谱图中较小的灰度值对应的像素点是背景成分;较大的灰度值所属像素属于目标或杂波区域.因此,可利用一个简单的线性分类器,通过像素灰度值,将RD谱图的背景区域和非背景区域分开,提高算法的检测效率.
若训练集X 中包含N个训练样本,本文设计的线性分类器为:

其中,T是线性分类器的阈值,xi为第i个训练样本,g(·) 是训练样本在RD 谱图的灰度值,h(·) 是经分类器判定的类别,阈值由以下几个步骤确定:
1) 获得每个训练样本的特征值(灰度值)ti,并升序排序.
2) 对每个样本分配权重wi,并分别计算出非背景样本和背景样本的加权和,分别用T+和T−表示:
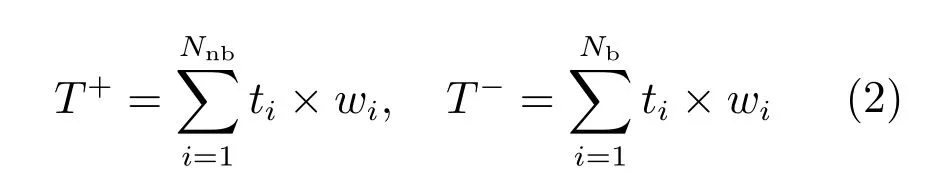
其中,Nnb是非背景样本个数,Nb是样本集中背景样本个数.
3) 对于已经排好序的特征值序列,依次选取其中的一个特征值ti为阈值,进行以下操作:
a) 计算特征ti前,所有非背景样本和背景样本的加权和,标记为Si+和Si−:

其中,nnb是ti前非背景样本的个数,nb是ti前背景样本的个数.
b) 计算此时分类器的权重误差,即将阈值ti前非背景样本的加权和与ti后背景样本的加权和相加.
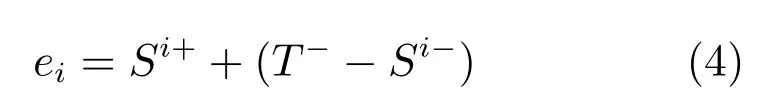
4) 误差最小时的特征值ti就是算法求出的最佳阈值T.此时能最大限度的保证ti前的样本为背景,ti后的样本为非背景.通过式(5) 确定此线性分类器的最佳阈值:

在高频地波雷达RD 谱处理中,目标点检测的原则是在保证最高检测率的前提下尽可能保证算法实时性.因此,在本文RD 谱目标检测算法中,非背景样本的权值统一取值为1,背景样本的权值统一设置为0.01,这样选取的优点为:经线性分类器处理的RD 谱图可充分保留其中的海面目标点.通过计算可获得背景样本加权和T−为514.73.
图3(a) 给出了线性分类器的权重误差e在不同灰度值下的变化曲线,其中横轴代表样本排序后的灰度值,纵轴代表以此灰度值为阈值时该线性分类器的权重误差值.图3(b) 为以某一灰度值为阈值时,该阈值前非背景样本的权重和,该阈值后背景样本的权重和T−-S−不同灰度值下的变化曲线.两者的和即为该线性分类器的权重误差.观察图3(a)可知,阈值选取为161 时(图3(a) 圆圈所示),训练获得的网络误差最小,此时线性分类器的加权误差为43.99.

图3 线性分类器的权重误差e, S+, T−−S−和灰度级间关系曲线Fig.3 The weighted error e, S+ and T−−S−,when training linear classifier on RD image data set,where the x-axis show the different gray-value
3 Haar-like 特征
在RD 谱图中,目标点是一种具有一定幅值的孤立峰值点,杂波分别在距离方向或多普勒方向变化缓慢.因此,若在RD 谱图上构建一个矩形窗口,目标点在形态上类似于圆形,而杂波为长条形.所以,目标点和杂波在RD 谱图上具有不同的几何特征.本文用Haar-like 算子提取图像高阶特征,以便进行目标点的精确检测.
Haar-like 首先由Papageorgiou 等[22]提出,近几年,大量学者将Haar-like 特征应用到各种工程实践中[22−24],目前常用的Haar-like 特征主要有三类:线性特征、边缘特征、中心特征,具体如图4 所示.
在本算法中,用竖直方向中心特征(如图4 中3(a) 所示) 构成Haar-like 特征算子.
通过第2 节设计的线性分类器,可获得RD 谱图的目标潜在区域(即图5(a) 的黑色区域),对该区域中的每个像素,在原始RD 谱图中分别生成以每个像素(称为参考像素) 为中心的7×7 大小的滑动窗口,如图5(b) 所示,利用Haar-like 特征算子可对该滑动窗口提取相应的高阶特征.

图4 Haar-like 特征Fig.4 Haar-like feature descriptor

图5 滑动窗口的选取Fig.5 The chosen of reference window
4 最优误差自校正极限学习机
经第3 节Haar-like 高阶特征提取后,需设计一个合适的神经网络,将RD 谱图中的海面目标从非背景区域中检测出来.
受子网络极限学习机的启发[25−28],本文提出一种新的最优误差自校正极限学习机(OES-ELM) 算法,该网络训练过程主要分为两阶段,初始化阶段和权值更新阶段.初始化阶段的目的是获得恰当的隐层特征映射空间(包括隐层权值和隐层神经元个数),结合L1/2正则化找到合适的隐层结构.更新阶段目的是结合L2正则化更新隐层权值,使网络获得权值最小解,提高网络的泛化性能.
4.1 初始化阶段
为了让OES-ELM 网络获得能最佳表达输入数据的隐含层,本文将神经网络隐层节点选取的过程同寻找最优化问题稀疏解的过程联系起来,求得的最优稀疏解能使隐层特征数据间的冗余性最小.换句话说,本文初始化阶段是使OES-ELM 网络根据训练集的特性找到能更好表达不同类别样本的特征映射空间,映射后的隐层能用合理的维度清晰地表达不同模式,进而使训练得到的网络具有较低的复杂度.
具体来讲,隐层节点个数的多少体现于与其连接神经元的权值是否为零,若与某一神经元连接的所有权值均为零,则该神经元可去掉,该层的神经元个数就可减少,而稀疏化求解过程就是在学习训练过程中找到尽可能多的零解.L1/2正则化具有求解容易,稀疏性好的特点,已经广泛应用于多种神经网络如支持向量机(Support vector machine,SVM)[29]、ELM[30−31]以及多种前馈神经网络中[32−33].因此,在初始化阶段,本文用L1/2正则化作为其网络正则项,保证网络的稀疏性:
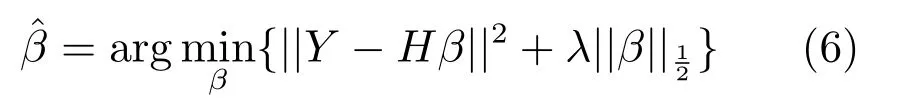
算法首先会设置隐层神经元L的个数,且会是一个较大的值,经式(6) 训练后网络仍可能含大量权值微小的隐层神经元,这些神经元对网络影响甚微却会提高网路的复杂度,不利于保证网络的泛化性能.因此在采用L1/2正则化的基础上还需要采用一种神经元裁剪算法,去掉这些“微弱”神经元,增强网络鲁棒性.具体过程如下:
1) 对输出权值进行排序:
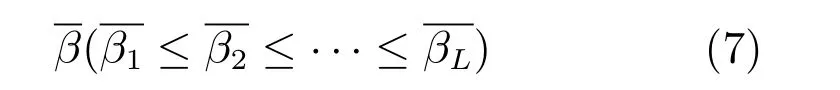
2) 前l个神经元权值的系数比为:

3) 设定阈值λ,裁剪的隐层神经元个数为个,必要隐层神经元个数Lopt为:

通过以上三步,可将隐层神经元中输出权值较小和权值为零的神经元有效去除,在保证隐层网络稀疏性的同时提高网络泛化性能.
图6 为按照本文提出的初始化阶段算法进行隐层神经元个数自适应确定时,神经元权值系数比随隐层神经元个数变化的变化曲线图.本文采用数据集BCW (Original) 进行相关实验仿真,该数据集输入为10 维,训练集有300 个样本.由于此时输出层权值已经由小到大排序,因此前期大量神经元的系数比为0 或为很小的数值,即为网络中的无用神经元或“微弱”神经元.图6 横线为本文设定的阈值,为0.01,低于该阈值的神经元即可删去,因此经该算法获得的隐层神经元个数为123 个.

图6 系数比和隐层神经元数目间关系曲线Fig.6 Performance of ratio of the first l accumulation coefficients to the sum coefficients
另外,较小的隐层维度能有效提高网络的识别速度.由于此时隐层神经元已被裁剪,所以为了保证网络隐层权值的合理性,需要对此时的隐层权值进行更新.此时还剩Lopt个隐层神经元,删去的神经元定义为:{d1,d2,···,dˆl}.

原来隐层第j个神经元与输入层第i个神经元的连接权值为更新后的权值为为输入层连接隐层第i个神经元构成的权值向量,xxxi为第i个样本的特征向量.初始化阶段最终获得合适的隐层神经元个数Lopt以及此隐层神经元下的隐层权值Wopt(Wopt∈Rn×Lopt) 和偏置bbbopt(bopt∈RLopt).
4.2 更新阶段
OES-ELM 网络更新阶段的算法步骤如下:
1) 对于一含有N个样本的训练集X:{(xxxi,ttti)},1≤ i ≤ N,xxxi ∈Rn,ttti ∈Rm,X ∈RN×n,T ∈RN×m,获得此时隐层参数(ˆaf1,ˆbbbf1),隐层的特征映射数据可以表达为:
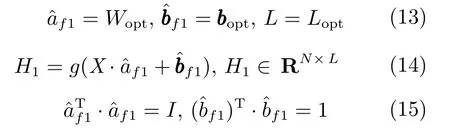
2) 对于期望输出T,输出层权值为:
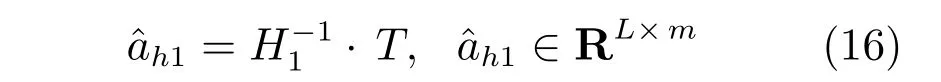
3)获得此时的输出层误差矩阵En−1,En−1∈RN×m,求出误差回传矩阵Pn−1,初始时n=2.
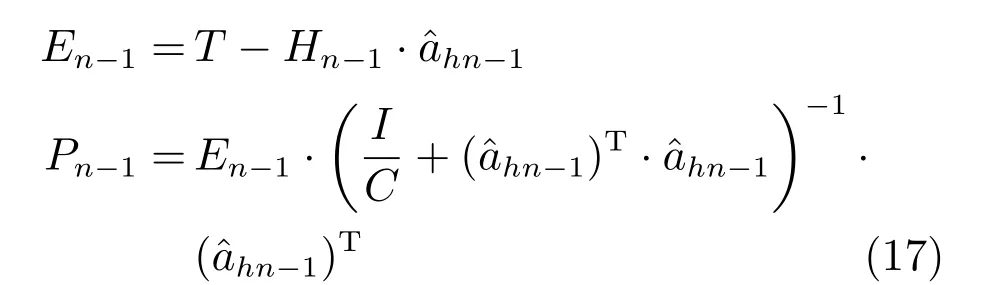
4) 此时期望的隐层特征映射矩阵Hn为:

5) 更新隐层权值和偏置:
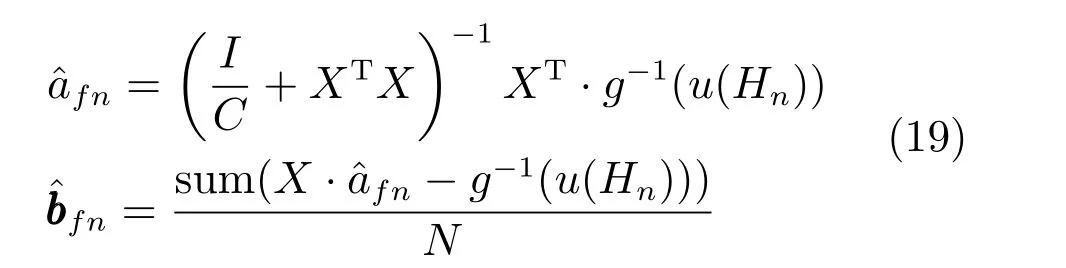
6) 更新输出层权值:
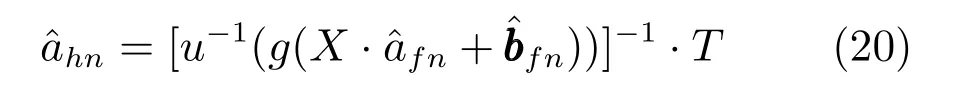
7)n=n+1,重复迭代步骤(3)~(6),直至相邻迭代级间输出层误差趋于稳定,即||En−1||-||En||≤ε,ε为任意小的正数.
为了验证本文更新阶段算法迭代对网络的影响,采用开源数据集:BCW (Original) 进行仿真.经初始化阶段确定隐层神经元个数为123 后,在权值更新阶段,设定不同的迭代次数,获得的网络训练集检测精确度如图7 所示.由图7 可知,网络经过一次权值更新后,训练集的识别精度就趋于稳定,即网络误差趋于稳定.

图7 训练误差和迭代次数关系曲线Fig.7 The performance of training accuracy with respect to iteration n
4.3 OES-ELM 网络的数学证明
下面证明本文提出的算法,即经第4.2 节的权值更新环节后,相邻迭代级间误差会逐渐平稳.
引理1[34].给定有界非定常分段连续激活函数g(·),式(21) 成立:
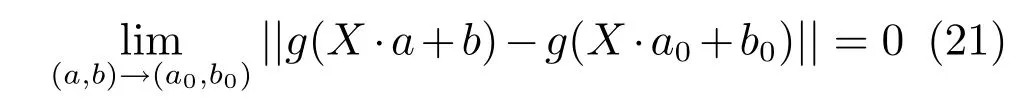
定理1.给定隐层激活函数,N个样本的样本集X:{(xxxi,ttti)},1≤ i ≤ N,xxxi ∈Rn,ttti ∈Rm,对于任意输出T,若权值满足式(22) 和(23),则以概率1 成立.
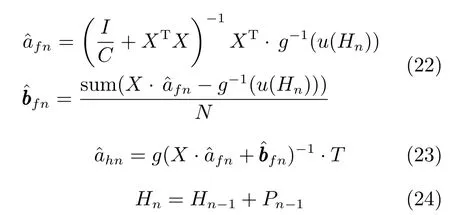
其中,(I/C+XTX)−1XT是训练样本集的Moore-Penrose 逆,C是正则系数,g(·)−1是激活函数的逆函数,u是归一化函数,u(x):R →(0,1]将训练集从原数据范围映射到0 到1 之间,u−1是归一化函数的逆函数,将训练集从0 到1 映射到原数据范围,Hn是第n次更新时期望特征空间映射矩阵,Pn−1是第n次迭代时的误差回传矩阵.
定理1 表明,随着迭代次数n的累增,网络相邻两次迭代间的输出误差呈缩小的趋势,即网络经有限次权值迭代后,实际输出和期望输出间的误差将趋于稳定.
若En−1是输出层误差矩阵,则可得到误差回传矩阵Pn−1:


Hn−1是第n -1 次更新时的特征映射.令λn=X ·afn,λn满足:

若激活函数是sine 函数,则隐层权值矩阵:
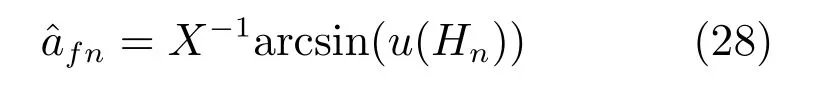
若激活函数是sigmoid 函数,则隐层权值矩阵为:

根据引理1:


5 实验结果与分析
为了验证OES-ELM 网络的有效性及基于OES-ELM 网络高频地波雷达目标识别的可行性,本文选择多个经典数据集和雷达RD 谱图像来进行实验.本文实验所采用的数据集为开源公共数据集,在实验平台Intel i7-860 (2.8 GHz) CPU,12 GB 内存的硬件支持下,利用MATLAB 2016b进行了相关仿真实验.在理论验证方面,分别将OES-ELM 网络和普通ELM 网络,ES-ELM 网络,OES-ELM(L1) 网络进行对比.ES-ELM 网络舍弃OES-ELM 初始化阶段,设定更新阶段权值随机赋值且隐层神经元数为2m(m为输出层维度);OESELM(L1) 网络将原预处理阶段的L1/2正则子替换为L1正则子,更新阶段不变.通过大量实验验证,经一次更新迭代所获得的OES-ELM 网络就能达到较好的泛化性能,因此实验部分OES-ELM、ESELM、OES-ELM(L1) 均只进行一次权值迭代.
在第5.1 节,我们将OES-ELM 网络和其他经典的神经网络算法进行对比,验证该网络的可行性;在算法应用方面,在第5.2 节,我们设计了两组实验,分别用高频地波雷达实测RD 谱图像和仿真RD 谱图像,对本文提出的目标点检测算法进行评估,并与经典RD 谱目标检测算法(二维CFAR、自适应小波) 进行对比,验证本文算法的目标识别性能.
5.1 OES-ELM 与其他神经网络算法性能对比
在这部分,我们用大量回归(Regression) 和分类(Classification) 问题来检验OES-ELM 网络的有效性.第5.1.1 节主要介绍实验所处的环境信息,第5.1.2 节和第5.1.3 节分别介绍4 种网络在特定分类问题和回归问题中的识别性能.
5.1.1 实验环境设置
本文所用数据集的所有样本在测试前均合理分成两部分,一部分为带有标签的训练集,一部分为待识别的测试集,所有输入数据均归一化到[-1,1]之间,回归问题的输出归一化到[0,1]之间.数据集的相关情况如表1 和表2 所示,这些数据集均下载自加州大学数据库(UCI) 和LIBSVM 数据集(LIBSVM data sets).通过这几个数据集可以充分验证本文算法的有效性.

表1 分类数据集的具体信息Table 1 The detail of classification datasets
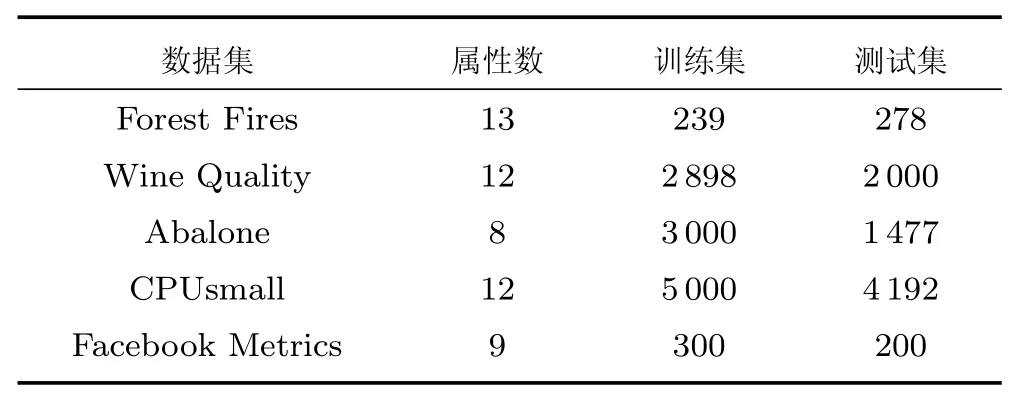
表2 回归数据集的具体信息Table 2 The detail of regression datasets
5.1.2 分类问题
在这部分,对4 种算法ELM、OES-ELM、OESELM、OES-ELM(L1) 在7 个分类数据集上进行对比,每组实验都进行10 次,最终结果取平均值进行显示.表3 展示不同算法在不同数据集下的识别性能,其中为网络在该样本集的均方根误差,为网络在测试集的测试结果.由于ELM 网络隐层神经元个数的多少对最终识别性能有很大影响,因此为了保证实验比较的公平性,ELM 网络将进行多次测试以找到最佳隐层神经元个数.
由表3 分析可知,OES-ELM、ES-ELM、OESELM(L1) 这三种网络在大部分数据集的分类识别中都具有较好的性能,而ELM 网络只在Covtype.binary 数据集中有更好的表现.即:

表3 不同网络在不同数据集下性能对比Table 3 Generalization performance comparision
1) 从横向来看,在输入维度较小的数据集中,ES-ELM、OES-ELM 和OES-ELM(L1) 网络对训练集的分类效果均有不错表现,且三者之间的分类效果差别不大.在输入维度较大的数据集中(如Gisette 和Leukemia)、OES-ELM 和OESELM(L1) 网络的识别分类性能具有显著提升,而ES-ELM 网络的识别性能并不理想.分析原因为:ES-ELM 网络隐层神经元个数为2m(m为输出层维数),这种网络结构对高输入维度,低输出维度的样本显得力不从心,这种网络结构所获得的隐层特征映射矩阵并不能很好地刻画输入样本和输入数据.而OES-ELM 网络灵活的算法结构可有效规避这一缺陷,有效实现隐层神经元的灵活选取.
2) 从纵向分析,OES-ELM 和OES-ELM(L1)网络对训练集的分类准确率相近,而具有L1/2正则的OES-ELM 网络在对测试集的识别效果上较好,这进一步表明L1/2正则比L1正则化所获得的解更稀疏,更适合OES-ELM 算法对隐层神经元个数的选取.
5.1.3 回归问题
ELM、OES-ELM 和OES-ELM(L1) 三种算法在这5 个回归数据集的识别效果如表4 所示,其中为算法在某一训练集下的均方误差,测试集的均方误差,所有实验结果均为20 次实验后的平均结果,粗体表示性能较好的结果.由表4 分析可知,在这5 个数据集中,OESELM(L1) 的识别效果虽然不错,但和具有L1/2正则比的OES-ELM 网络相比,还是有一定的差距;ELM 网络在几个有限的数据集中有较好识别性能.

表4 不同网络在不同数据集下性能对比Table 4 Generalization performance comparision
表5 展示了OES-ELM 网络和普通ELM 网络在不同数据集,正则系数下的性能比较,表格中数据为20 次实验Te-RMSE的平均结果.从表5 可以看出,普通ELM 网络的泛化性能对正则项C高度敏感,C的选取直接影响最终网络训练的好坏,而OES-ELM 网络的测试结果并不十分依赖于正则项C的大小,也就是说,在网络训练开始前,人们可以随机选取正则项C的大小.
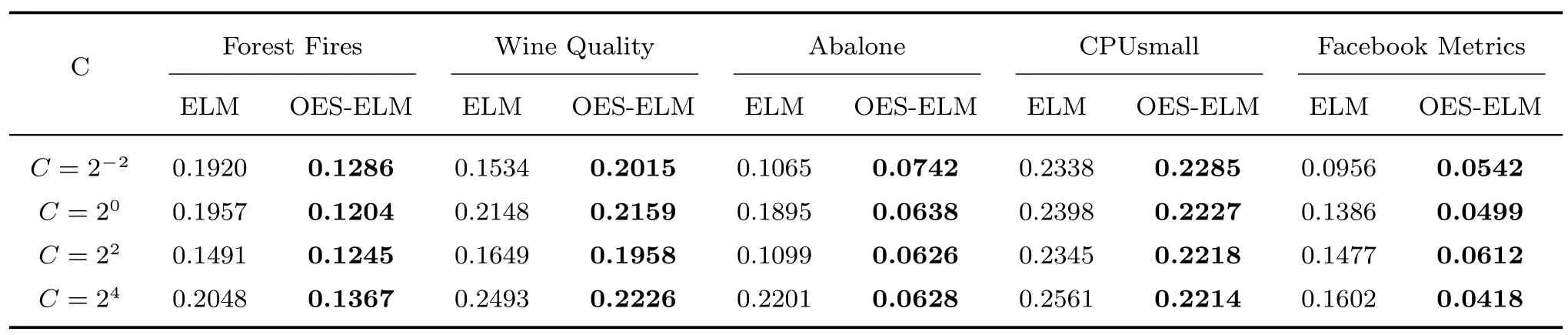
表5 ELM 和OES-ELM 在不同正则系数下Te-RMSE 比较Table 5 The comparision of ELM and OES-ELM with respect to Te-RMSE
综上所述,本文提出的OES-ELM 算法几乎在所有的数据集中均有较好的表现,主要体现在:1)网络泛化性能好;2)正则项C对网络性能并不敏感;3) 隐层神经元个数少且可根据数据集自适应获得.
5.2 高频地波雷达RD 谱图海面目标识别效果
在第5.2.1 节,我们将介绍目标检测中用到的训练数据集和评估指标;在第5.2.2 节和第5.2.3 节,本文分别设计了两组实验,以验证提出算法目标识别效果.
5.2.1 目标点检测的数据集和评估指标
鉴于本文提出的RD 谱目标检测算法由两个独立的分类器(线性分类器和OES-ELM 网络) 构成,我们用两个独立的数据集X1和X2作为两个分类器的训练集.用30 幅实测RD 谱图(大小:256 像素×256 像素) 生成数据集,这些RD 谱图中均包含所有种类的杂波和背景噪声,且目标均为真实舰船目标点.
1) 对于线性分类器的训练集,输入数据集X1由RD 谱图中所选定像素的灰度值构成,每个样本的输入维度为一维,期望输出Y1则为所选像素是否是目标潜在区域,输出两类.
2) 对于OES-ELM 网络的训练集,输入数据集X2的每个样本的输入维度为49 维,由以参考像素为中心的7×7 大小滑动窗口经Haar-like 算子提取获得,输出两类,Y2为该像素是否为目标点.
本文主要采用目标点检测率Pd,虚警率Pf,目标漏检率Mr,错误率Er作为目标检测性能的评估指标,具体定义如下:
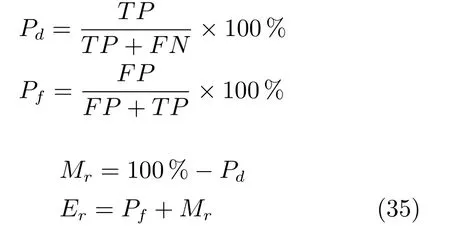
TP为检测到的真实目标点,FN是未检测到的目标点,TP+FN是所有目标点个数,FP是检测到的虚假目标点.表6 展示了两个数据集的详细信息.

表6 两个数据集的详细信息Table 6 The detail of two designed datasets
5.2.2 RD 谱图目标点检测
本文先对实测RD 谱进行处理,验证该算法对HFSWR 目标检测问题的实际效果.首先,在算法训练阶段,分别用数据集X1和X2训练该算法中的线性分类器C1和OES-ELM 网络C2.在测试阶段,先用训练好的网络C1处理待测RD 谱图I0,获得去掉背景,只含目标潜在区域的RD 图I1;之后用Haar-like 算子对目标潜在区域提取高阶特征,采用网络C2获得只含目标点的RD 图I2,最后经统计可获得RD 谱图上所有的目标点信息.
为了验证本文提出算法对目标点的检测性能,对20 幅已知舰船位置的实测RD 谱图像进行目标点检测实验,经统计20 幅RD 谱图的目标点检测率Pd为92%,虚警率Pf低于6%,目标点漏检率Mr和错误率Er分别为8% 和15%.图8 是这20幅图像中的两幅典型检测结果,其中图8(a) 和(b)是原始RD 谱图像,图8(c) 和(d) 是经线性分类器得到的目标潜在图像,在这两幅图像中,淡色区域为非目标的背景区域,目标点一定位于亮色区域中,OES-ELM 网络只考虑这些非背景区域,图8(e) 和(f) 是最终目标检测图像.可以看出这两幅RD 图中,几乎所有目标点被识别出来,同时也可一定程度识别被杂波干扰的海面目标点,因此本文算法可从复杂区域中将目标区域检测出来.

图8 本文算法目标点检测结果Fig.8 The final detection result of our proposed method
5.2.3 目标点检测性能对比
这部分将对本文算法和文献[6]改进CFAR 算法,文献[10]自适应小波算法进行性能对比.在实际海域监测中,由于监控海域面积太大,因此目标点的具体位置和数量很困难,即获得的可进行实验对比的RD 图像十分有限,尽管可以利用自动识别系统(AIS) 的数据,但对于一些未应用该系统的舰船,AIS 是无法检测到.因此,为了能进一步进行大量的对比实验,我们在HFSWR 实测谱数据中随机添加20~40 dB 的仿真目标点数据,以获得可用的仿真RD 谱图.在本实验中,选取200 幅添加了仿真目标点的RD 谱图作为实验所需测试集.
文献[10]提出的自适应小波算法,首先用两个一维自适应小波算法分别去除电离层杂波和海杂波;再通过模糊集增强算法对高频小波系数进行模糊处理,达到增强目标信息,抑制背景噪声的目的;最后用阈值自适应分割以得到RD 谱图中的海面目标点.
文献[6]提出的改进CFAR 算法先利用曲线拟合做了削弱杂波和噪声的预处理,再利用被测单元周围单元格的平均估计背景噪声,并将得到的背景噪声与决定虚警概率大小的门限因子相乘作为判别检测单元是否为目标的检测门限.
表7 是三种算法对200 幅RD 谱图目标检测的实验性能对比,本文分别利用Matlab 对三种算法进行实验仿真,在算法检测时间方面,自适应小波算法仅统计从一维小波到自适应阈值分割所需时间;改进CFAR 算法统计从曲线拟合到最终检测结果所需时间;本文提出的OES-ELM 算法不计算网络训练时间,仅统计RD 谱图测试时间,表7 的时间为200幅测试图像的平均处理时间.在本实验中,本文算法的检测速度都要快于自适应小波和改进的CFAR 算法.其原因为:本算法在第一个线性分类器就可以排除大量背景和噪声成分,这些成分在后续算法中不被考虑,故而可大幅度减少该算法的时间复杂度.同时,本文提出的OES-ELM 网络也在保证识别精度的基础上,具有网络简单,分类速度快的优点,因此可以进一步减少目标点识别的时间需求.
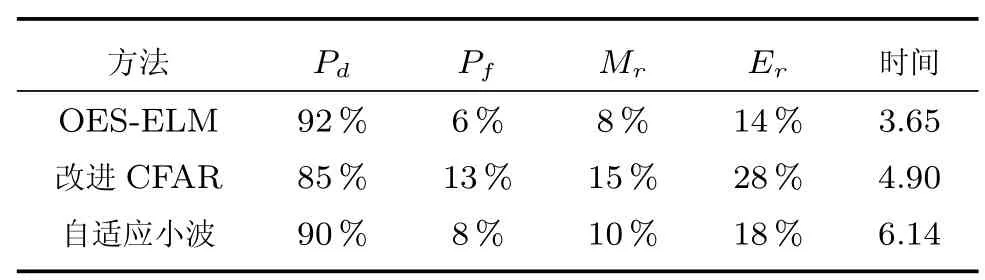
表7 三种算法的性能对比(时间:平均测试时间(秒))Table 7 The performance of These three algorithms(Time:Average testing time (second))
从表7 前4 列可以看出,相对于其他两种经典算法,本文算法具有更好的目标点检测性能.目标点检测率Pd分别比改进CFAR 算法和自适应小波算法提高了7% 和2%,而虚警率Pf、目标点漏检率Mr和错误率Er也比这两种算法低,其中,本算法的错误率Er 比两种算法分别低了14% 和4%,其原因为:本算法提取的Haar-like 特征非常适合描述RD 谱中的海面目标,通过该算子可以准确刻画RD谱图中目标点和不同干扰间不同差异,且具有较好的适应性.
6 结论
本文从机器学习的角度,提出了一种基于误差自校正极限学习机(OES-ELM) 的高频地波雷达RD 谱图海面目标识别算法.本文构造的基于灰度特征的线性分类器,利用RD 谱图背景像素点和目标、杂波像素点灰度值差异大的特性,可以快速找出目标的潜在区域.基于最优误差自校正极限学习机(OES-ELM) 的海面目标精确识别算法,结合Haar-like 算子对RD 谱图提取的高阶纹理特征,准确地把海面目标点从杂波中检测出来.本文提出的OES-ELM 网络,一方面通过L1/2正则化保证网络隐层特征映射矩阵的稀疏性,另一方面,又利用权值更新迭代使训练得到的网络的隐层和输出层权值均为最小二乘解,确保网络的泛化性能实验结果表明:1) OES-ELM 网络的正则项对最终网路的分类性能并不敏感,速度快且泛化性能好.2) 从机器学习角度,提出一种RD 谱图目标检测算法,该算法基于OES-ELM 和级联分类器理论,能对高频地波雷达实时准确地进行目标点检测.
