激光诱导击穿光谱技术结合神经网络和支持向量机算法的人参产地快速识别研究*
2021-03-04董鹏凯赵上勇郑柯鑫王冀高勋郝作强林景全
董鹏凯 赵上勇 郑柯鑫 王冀† 高勋‡ 郝作强 林景全
1) (长春理工大学理学院, 长春 130022)
2) (山东师范大学物理与电子科学学院, 济南 250358)
利用激光诱导击穿光谱技术结合机器学习算法, 对东北5 个产地(大兴安岭、集安、恒仁、石柱、抚松)的人参进行产地识别, 建立了主成分分析算法分别结合反向传播(BP)神经网络和支持向量机算法的人参产地识别模型.实验采集了5 个产地人参共657 组在200—975 nm 的激光诱导击穿光谱, 经光谱数据预处理后, 对C, Mg, Ca, Fe, H, N, O 等元素的8 条特征谱线进行主成分分析, 原光谱数据的前3 个主成分累积贡献率达到92.50%, 且样品在主成分空间中呈现良好的聚集分类.降维后的前3 个主成分以2∶1 进行随机抽取,分别作为分类算法的训练集和测试集.实验结果表明主成分分析结合BP 神经网络及支持向量机的平均识别率分别为99.08%和99.5%.发生误判的原因是集安和石柱两地地理环境的接近而导致的H, O 两元素在Ca 元素离子发射谱线下的归一化强度相似.本研究为激光诱导击穿光谱技术在人参产地的快速识别提供了方法和参考.
1 引 言
人参(panax ginseng)是五加科多年生草本植物, 在中国已有4000 多年的药用和食用历史.人参中主要有效成分为人参皂苷和多糖, 还含有维生素类、酶类、有机酸及其酯、蛋白质、甾醇及其苷、多肽类、含氮化合物、木质素、黄酮类和无机元素等多种成分, 具有滋补强身、预防疲劳、抗衰老、抗肿瘤、提高免疫功能等多种功效, 被广泛应用于制药、保健产品、美容产品、饮料等领域, 对内分泌系统、心血管疾病和中枢神经系统等方面有突出疗效[1,2].研究发现, 人参皂苷、多糖等主要有效成分在人参内形成、转化与积累等过程与人参产地的土壤环境、日照环境和气候环境有关, 因此不同人参产地的相同品种人参在临床疗效上存在着较大的差异.目前, 中国人参产地众多, 同一品种人参质量参差不齐, 质量监控困难.东北三省是我国重要的人参产地, 目前不法商人借“长白山人参”等噱头出售人参来牟取利益, 导致人参市场充斥大量伪品及混淆品, 严重影响人参的有效使用以及国际市场的推广.所以人参产地的识别对人参质量品牌保护非常重要, 并且对提高中药制剂的临床疗效均一性和稳定性及人参市场的发展具有重要研究意义.
传统的“五行”“六体”识别方法对人参种类和质量的判断易受人为因素影响.随着现代科技的发展, 通过对药效成分含量的测定来确定不同产地药材的差异是重要的中草药识别方法.光谱技术因能客观地反映药材内在质量从而被广泛应用于中草药鉴定中, 常用的光谱检测方法主要有近红外光谱(near infrared spectroscopy, NIR)技术、拉曼光谱(Raman spectroscopy)技术、荧光光谱(fluorescence spectroscopy)技术等[3−6].常规的光谱技术由于光谱信号微弱很容易受到背景光的影响, 且检测样品时处理时间长且复杂, 无法实现实时、在线和快速检测.因此, 亟需一种快速可靠的人参产地检测方法.
激光诱导击穿光谱技术(laser inducted breakdown spectroscopy, LIBS)是一种原子发射光谱技术[7−9], 适用于所有物质(气态、液态、固态), 具有快速、微损、样品准备简单和多元素同时探测等优点, 广泛地应用于爆炸物检测[10]、文化遗产[11]、生物医学分析[12]、土壤重金属检测[13]、地质分析[14]、食品安全[15]等领域.利用LIBS 技术和化学计量学方法结合可实现待测样品的分类识别.Junjuri和Gundawar[16]利用主成分分析(principal component analysis, PCA)方法和人工神经网络(artificial neural network, ANN)两种算法结合LIBS 技术,采用PCA 方法对样品进行分析, 以主成分数据作为ANN 的输入量实现了对5 种消费塑料进行鉴定, 最终识别精确度为97%—99%; Velioglu 等[17]利用LIBS 结合PCA 实现了纯下脚料和混合下脚料掺假牛肉样品的识别; Lin 等[18]使用LIBS 技术结合偏最小二乘(PLS-LDA)及支持向量机(support vector machines, SVM)方法实现了钢种的识别,采用偏最小二乘支持向量机算法(LSSVM)将识别精度由96.25%和95%提高到了100%; Wang 等[19]利用LIBS 结合PCA 算法和ANN 算法对不同产地、不同部位的当归、党参、川芎3 种中药材进行分析鉴定, 达到99.89%的识别精度; 郑培超等[20]利用随机森林分类模型结合LIBS 技术对石斛进行价格等级分类, 利用袋外数据误差率估计随机森林在不同的决策树个数和分裂属性集中属性个数下的分类效果, 选取最优参数, 将平均识别率提高到了96.46%.
目前关于LIBS 结合机器学习算法对人参产地分类还有待研究.本文基于LIBS 技术结合机器学习算法对人参产地快速识别, 首先通过PCA 提取人参样品的LIBS 光谱数据的特征量, 分别采用BP 神经网络(back propagation artificial neural network, BP-ANN)算法、SVM 算法建立人参产地识别模型, 对东北5 个产地的同种人参(白参)进行聚类分析, 实现了人参产地的识别.结果表明,LIBS结合机器学习方法是实现人参产地快速识别的有效方法.
2 实验部分
2.1 实验装置
激光诱导击穿光谱技术用于人参产地识别的实验装置如图1 所示.激光光源为输出波长1064 nm,脉宽10 ns, 重复频率10 Hz 的Nd:YAG 激光器(Continuum, surellite II), 激光光束直径为6 mm,激光光束通过由半波片和格兰棱镜组成的能量调节系统对诱导击穿人参等离子体的脉冲能量进行调控, 激光光束经焦距为120 mm 的熔石英玻璃平凸透镜聚焦在人参样品表面诱导击穿产生等离子体.激光光束聚焦焦点位于人参样品表面内0.8 mm, 目的为避免诱导击穿空气等离子体, 减少对人参光谱分析带来干扰.在与人参等离子体膨胀轴向方向成45°的人参等离子体发射光谱方向上,用焦距为75 mm 的熔石英透镜收集耦合人参等离子体发射光谱耦合到配有ICCD 探测器(1024 ×1024 pixel, DH334)的中阶梯光栅光谱仪(Andor,Me5000)的光纤探头, 光谱仪焦距为195 mm, 光谱分辨率为 λ /∆λ ≈5000 , 一次光谱探测范围为200—975 nm.激光器和ICCD 探测器均由数字脉冲延时发生器(Standoff, DG645)同步触发工作,通过优化激光脉冲与ICCD 探测器间的时间延时和ICCD 探测器的探测时间门宽, 设定延时和门宽分别为1 和5 s, 获得高信背比的人参LIBS 光谱信号.为避免人参样品过度烧蚀, 人参样品固定在三维平移台上, 使每个激光脉冲作用在人参样品表面新的位置.实验中人参LIBS 光谱为100 个脉冲进行平均, 降低脉冲能量抖动对人参LIBS 光谱的稳定性影响.实验均在标准大气压、室内温度为22 ℃、空气相对湿度为25%的条件下开展.
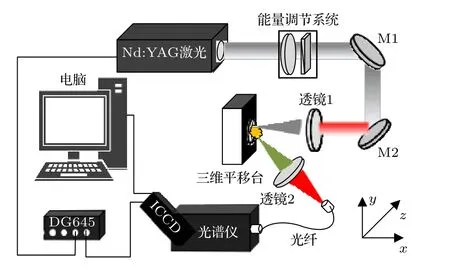
图1 激光诱导击穿光谱实验装置示意图Fig.1.Schematic diagram of the experimental setup of LIBS.
2.2 样品制备
实验所用的人参样品均为生长年限15 年的白参, 产地分别为辽宁省石柱(SZ)、恒仁(HR), 黑龙江省大兴安岭(DXAL), 吉林省抚松(FS)、集安(JA).LIBS 光谱信号受样品密度、干燥度及研磨均匀性等物理属性的影响, 在实验前先对5 个产地的人参样品进行纯净、干燥处理, 取干燥后的人参中间支干部位, 使用振动研磨机(安合盟(天津)科技发展有限公司, PrepM-01)研磨至粉末, 分别经50 目和100 目过筛, 取1.5 mg 样品过筛人参粉末, 使用机械压片机(安合盟(天津)科技发展有限公司,FW-40)在25 MPa 压力下压制25 min, 制成直径30 mm、厚度为2 mm 的圆形人参样品, 用于人参产地识别实验样品.
2.3 主成分分析算法
主成分分析(principal component analaysis,PCA)算法是一种数据降维的高效信息处理方法,它采用特征分解获得最大方差的主成分代替原来变量, 可以消除原变量的相关性, 降低数据的维数,提高建模速度和稳定性.PCA 分析方法为将人参样品LIBS 光谱的采样值整理并代入向量Xi=(xi1,xi2,···,xin) 中( n 为光谱特征值), m 为进行降维的m 组光谱数据, 对样本标准化: 标准化采用P维随机变量, 选取m 个样品, 构造样本阵, 对样本阵进行标准变换:
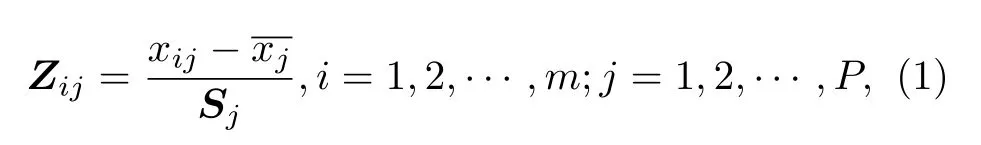


其中, λ 称为 R 的特征值, 非零向量 R 称为A 对应于特征值 λ 的特征向量; 根据主成分贡献率选择主成分, 计算主成分得分, 将所得主成分作为分类算法的输入参量, 对人参进行产地识别.
2.4 BP 神经网络算法
误差反向传播(back-propagation algorithm,BP)神经网络[21]是一种按误差逆传播算法训练的多层前馈网络, 它利用大量的数据进行训练获得输入与输出间的映射关系, 再通过梯度下降法不断调整网络的权值和阈值, 使网络的误差达到最小.图2为典型的BP 人工神经网络结构示意图.网络 N 个输入节点, L 个输出节点, 隐含层包含 Z 个神经元.x1,x2,··· ,xN为网络的实际输入, y1,y2,··· ,yL为网络的实际输出.
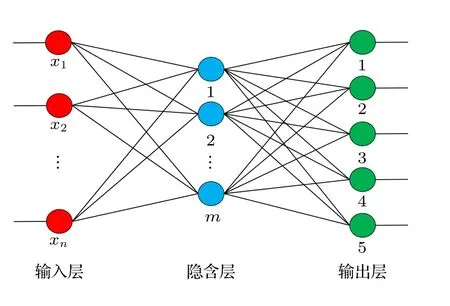
图2 BP 神经网络结构示意图Fig.2.Structure of BP neural network.
BP 神经网络通常由输入层(input layer)、输出层(output layer)、一个或多个隐含层(hidden layer)组成.传递函数对误差和训练时间会有很大的影响, 合理地选择传递函数能够降低网络误差, 四种传递函数为trainlm, trainda, traindm, Traindx.激活函数以及传递函数的确定需要根据训练数据来进行测试、对比与筛选.在进行BP 神经网络仿真前, 还需要先进行LIBS 光谱数据的训练集和测试集选择, 从而能够快速实现人参产地鉴定识别.
2.5 SVM 算法
支持向量机[22](support vector machine, SVM)实现分类的本质是找一条分割线, 将所有样本点尽可能远离分割线, 即最优超平面.设训练样本集{(xi,yi),i=1,2,··· ,l} , xi对应样本属性值, yi对应属性值标签.对于非线性训练集, 通过一个非线性函数将训练数据 x 映射到一个高维特征空间, 映射在高维空间中的不同产地人参属性值向量ϕ(xi)变为线性可分问题.此时需构造最优分类超平面并得到决策函数.
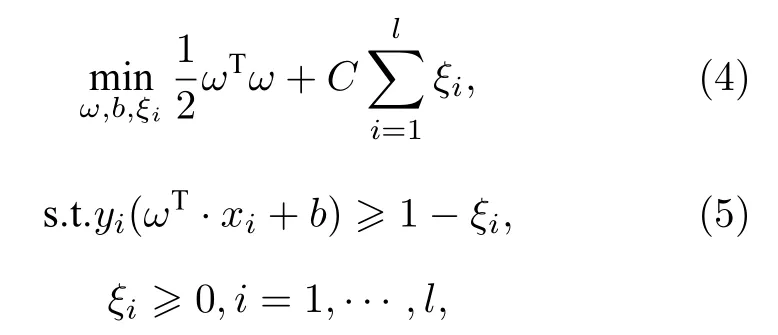
其中 C 为识别参数, ξi,i=1,··· ,l 为引入的非负松弛变量.采用拉格朗日(Lagrangian)乘子法求解该问题, 得到对偶形式.

其中 K (Xi,Xj)=ϕ(Xi)Tϕ(Xj) 为核函数, 本实验采用径向基函数(radial basis function, RBF)作为 核函数, 即

式 中, σ 表示高斯核函数宽度.最终, 决策函数
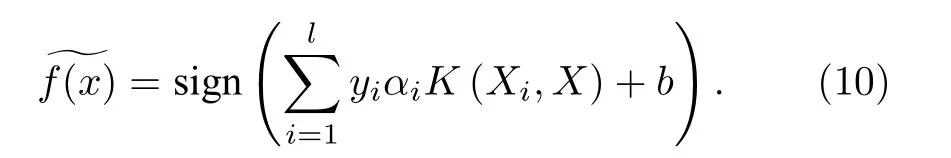
SVM 核心问题是优化惩罚因子 C 及核函数g( g =1/σ2).惩罚因子控制对大间隔和最小训练错误率之间的平衡, 用于核空间上非线性可分数据.本实验基于交叉验证和网格搜索对 C 与 g 进行训练, 获得最佳参数 C , g 进行训练支持向量机算法 , 从而能够快速实现人参产地鉴定识别.
3 结果与分析
3.1 特征光谱的选取
进行人参产地识别, 需要考虑实验待测产地人参的LIBS 全光谱信息, 但LIBS 全光谱信息量很大, 进而导致机器学习算法计算量过大, 从而人参产地的识别快速性不能得到保证.为此, 选取合适的特征谱线代表人参样品的全光谱信息, 从而实现快速人参产地识别尤为重要.激光诱导人参的等离子体发射光谱由线状光谱叠加在连续光谱上组成,连续背景光谱的存在, 导致了LIBS 光谱的信背比变低, 本文采用窗口平移平滑法降低背景连续光谱, 5 个产地人参的激光诱导击穿光谱如图3 所示.根据美国NIST 原子光谱数据库对人参LIBS 光谱进行了元素标记, LIBS 光谱中存在Mg, Ca, Fe 等矿质营养元素以及C, H, N, O 等人参组成元素的原子发射光谱.不同产地人参中元素含量不同, 对应的LIBS 特征谱线强度有一定的差异, 因而通过多条元素特征光谱强度可对人参产地进行识别.特征光谱的选择应满足光谱线的重叠少、自吸收现象弱、谱线强度大(信背比高)等条件, 最终选取Mg,Ca, Fe, C, H, N, O 共7 个元素8 条特征谱线进行人参产地识别(特征谱线信息如表1 所列).

图3 人参LIBS 光谱(产地分别为大兴安岭、集安、恒仁、石柱、抚松)Fig.3.LIBS spectra of ginseng(the ginseng origins are DXAL, JA, HR, SZ and FS).

表1 人参特征谱线及波长Table 1.Characteristic line and wavelength of ginseng.
在LIBS 实验过程中, LIBS 光谱强度受到外部气体流动、激光脉冲能量抖动及样品表面元素含量的变化等因素影响, 从而导致在给定实验条件下的LIBS 光谱强度存在一定的起伏, 这将对依据LIBS 光谱谱线强度作为元素定量分析产生一定的误差.因此, 选取LIBS 光谱中多次重复性实验较为稳定且光谱强度值较大的特征谱线进行LIBS光谱强度归一化处理, 能够有效降低外部实验环境等因素造成的LIBS 光谱强度起伏对定量分析的影响.本文人参样品LIBS 光谱中Ca I 393.40 nm特征谱线强度最大, 且多次重复实验的光谱强度稳定, 因此选取谱线强度最大的Ca I 393.40 nm 作为归一化标准.为降低谱线强度波动对分类结果的影响, 每个LIBS 光谱中的8 条特征谱线强度均以Ca:393.40 nm 光谱强度作归一化处理, 最终得到5 个产地人参的657 组数据(DXAL 117 组、JA 150组、HR 153 组、SZ 96 组、FS 141 组), 每组数据有8 个属性, 作为PCA 的输入: Xi=(xi1,xi2,··· ,xi8).
3.2 主成分分析
由PCA 分析出人参LIBS 光谱中Mg, Ca,Fe, C, H, N, O 共7 个元素8 条特征谱线对LIBS全谱的主成分贡献情况, 得到前10 个主成分的贡献率和主成分的累计贡献率如图4(a)所示, PC1,PC2 和 PC3 主成分累计贡献率为92.5%, 可认为PC1, PC2, PC3 包含了原始人参LIBS 光谱的大量信息.PC1, PC2 和 PC3 3 个主成分向量组成的三维散点图如图4(b)所示.图4 中每个散点代表一个人参样本, 可以看出同产地人参样品的特征LIBS 光谱经PCA 处理后存在特定的聚集区域,显示了良好的聚类效果.结果表明结合PCA 处理后的LIBS 光谱数据能够表征人参的产地特征信息, 且能将不同产地人参间的差异进行有效区分.由图4(b)可知, HR, FS 和DXAL 等产地人参的聚类性较好, 相互之间区分度高, JA 和SZ 产地人参样品也可聚在一起, 但存在部分重叠.
3.3 结合机器学习对人参产地进行识别
通过PCA 算法对5 个人参产地、共657 组LIBS数据进行光谱数据降维处理, 优化PCA 算法参量,实现PC1, PC2 和 PC3 前3 个主成分累计贡献率为92.5%, 就以PC1, PC2 和 PC3 主成分代替人参的LIBS 特征光谱, 从而构建出人参样品LIBS光谱的特征空间向量, 特征向量构成的 6 57×3 的数据矩阵分别作为BP 神经网络与SVM 产地识别算法的输入量, 进而依据PCA-BP 和PCA-SVM算法实现人参产地分类识别.BP 神经网络人参产地识别算法按产地以2:1 随机选取经主成分降维处理的657 组数据, 分为438 组测试集(Test)和219 组训练集(Train).训练集构成的 4 38×3 维数据矩阵作为神经网络训练输入量.网络的输入向量为三维数据, 因此BP 神经网络的输入层和输出层的神经元分别为3 和5.运行经多次训练, 最佳隐含层神经元个数为11, 输入层激励函数为tansig,输出层激励函数为purlin.网络初始化参数的迭代数设为1000, 学习率为0.1, 误差目标为0.0001.

图4 (a)各主成分贡献率和主成分累积贡献率; (b)前3 个主成分的三维散点图Fig.4.(a) Contribution rate of each principal component and cumulative contribution rate of principal component; (b) three-dimensional scatter plot of first three principal components.
图5 (a)为BP 神经网络最佳验证性能图, 训练误差随训练次数不断减小, 测试均方差(MSE)也趋于平缓, 验证曲线MSE 不再变化时网络训练截止, 网络性能最佳坐标为(28, 0.03), 达到了最佳网络识别精度.在此基础上, 以BP 神经网络机器学习对人参产地分类结果如图5(b)所示, 图中“*”表示测试标签, “○”表示实际标签.当“*”和“○”重合时表明预测准确, 结果显示有2 个JA 产地的人参被误判为SZ 产地, 其他产地100%识别, 平均识别精度达到99.08%, 人参产地识别算法模型运行时间为2.48 s, 同时结果表明神经网络收敛性良好, 误差个数稳定, 高质量地实现了人参产地判别.
人参产地识别的SVM 算法的数据选取经主成分降维处理的657 组数据, 建立与BP 神经网络算法相同的训练集和测试集, 使用交互检验法优化参数, 得到PCA-SVM 的网格参数优化如图6(a)所示.图6(a)的x, y 轴分别表示C, g 取以2 为底的对数的值, 使用网格搜索方法的分类(SVC)参数计算出最佳惩罚因子 C 为0.14, 最优核函数g 为36.76, 此时交叉验证准确率为99.09%, 训练集准确率为99.07%.经参数优化后SVM 算法对人参产地识别的预测运行结果如图6(b)所示.图6(b)中“△”表示预测标签, “○”表示实际标签.结果表明, 1 个JA 产地的人参被误判为SZ, 识别精度为99.8%.其他产地的识别精度均为100%, 平均识别精度为99.5%, 人参产地识别算法模型运行时间为14.03 s.

图5 (a) BP 神经网络训练性能曲线; (b) 分类结果图Fig.5.(a) BP neural network training performance curve; (b) classification results.
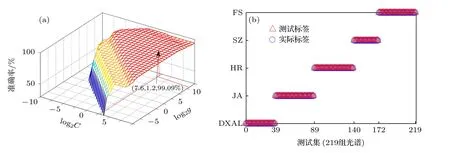
图6 (a) PCA-SVM 网格参数优化; (b)分类识别结果图Fig.6.(a) PCA-SVM grid parameter optimization; (b) classification recognition result graph.
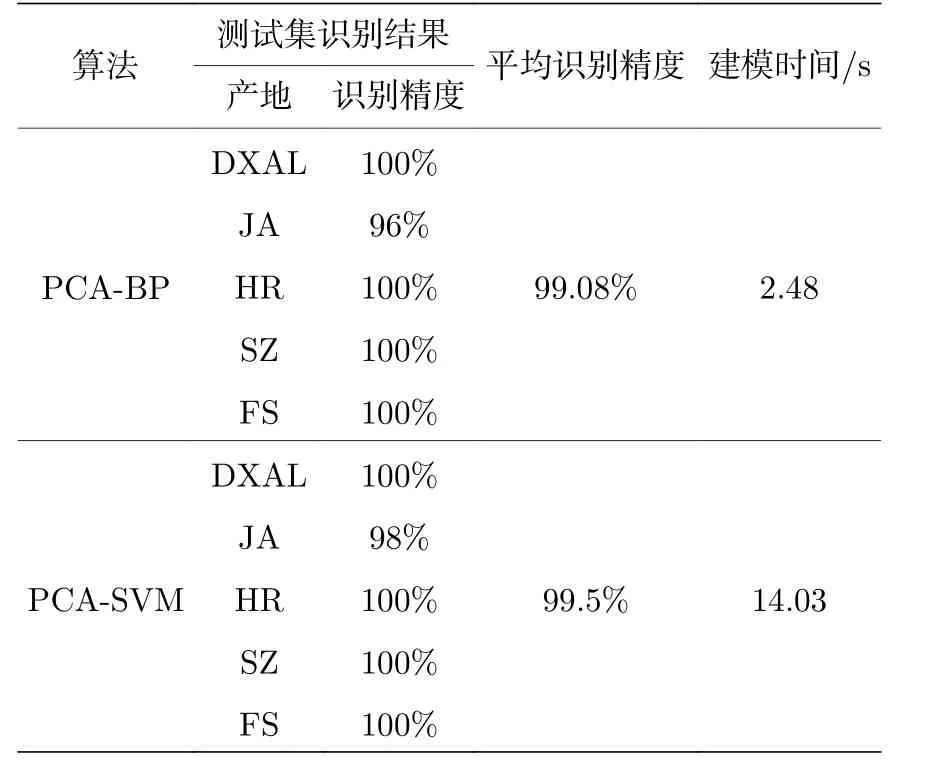
表2 人参产地识别结果对比Table 2.Comparison of ginseng origin identification results.
PCA-BP, PCA-SVM 分类算法对人参产地的识别结果如表2 所列.由LIBS 技术结合机器学习的研究结果可知, PCA-BP 和PCA-SVM 两种分类算法的分类精度均达到了99%以上, 实现了目标分类精度, 但在JA 人参产地的识别上均发生了一定数量的误判.在算法模型运行时间上, PCABP 算法和PCA-SVM 算法的人参产地识别运算时间分别为2.48 和14.03 s, PCA-BP 算法相对于PCA-SVM 算法的建模速度快了11.545 s, 有明显优势.主要原因可能为BP 神经网络算法具有自主学习能力, 而SVM 算法需通过核函数将非线性问题实现线性的转化, 识别能力依靠分类超平面的划分, 需寻找最优的核函数以满足识别精度要求, 因而建模时间较BP 神经网络算法慢.
人参的品质主要由人参皂苷及人参多糖的含量决定, 人参皂苷是固醇类化合物, 人参中皂苷和多糖主要由C, H, O 等元素决定.通过分析5 个产地人参C I 247.8 nm, H I 656.39 nm, O I 777.42 nm元素在Ca II 394.2 nm 元素谱线强度下的归一化强度结果如图7 所示.可以看出, JA 和SZ 两地人参在组成成分上虽因产地的不同导致金属元素的原子发射谱线强度存在差异, 但其H I 656.39 nm与O I 777.42 nm 两条谱线强度的归一化强度几乎相同, 从而导致JA 和SZ 人参产地分类时发生误判.
4 结 论

图7 人参LIBS 谱中C, H, O 元素谱线的归一化强度比Fig.7.Normalized intensity ratios of C, H and O element lines in the LIBS spectrum.
基于激光诱导击穿光谱技术结合机器学习算法对5 个产地的人参进行了产地的分类识别, 测试集219 组光谱中, PCA-BP 算法和PCA-SVM 算法分别正确识别了217 组和218 组, 两种算法的识别精度分别为99.08%和99.5%.但在分类速度上,主成分分析结合神经网络(PCA-BP)算法明显优于主成分分析结合支持向量机(PCA-SVM)算法.JA和SZ 两种人参样本LIBS 谱线中的H I 656.39 nm和O I 777.42 nm 谱线在以Ca:393.40 nm 光谱强度作归一化处理后的强度几乎相同, 最终导致两产地发生误判.实验结果证明, PCA-BP 算法较PCASVM 算法训练速度快, 训练结果较为稳定, 对5 个产地人参的分类精度较高, 因此利用LIBS 技术结合机器学习算法可实现人参产地的快速识别.
