结构外观度量下的无监督人体图像生成
2021-02-28赵应丁何俞玲杨文姬吴沧海杨红云黄丽芳
赵应丁,何俞玲,杨文姬,吴沧海,杨红云,3,黄丽芳
1(江西农业大学 软件学院,南昌 330045) 2(江西农业大学 计算机与信息工程学院,南昌 330045) 3(江西省高等学校农业信息技术重点实验室,南昌 330045) 4(江铃控股有限公司,南昌 330052)
1 引 言
近年来,人体图像生成研究得到了极大的关注,广泛应用于智能照片编辑、电影制作、虚拟试衣和行人重识别等应用领域.由于非刚性变换的先天性特点,进行和人类感知相同的人体姿态转换是一项很大的挑战.如图1所示,当只能观察到人体部分部位时,生成器需要推断未观察到的身体部位.此外,一个典型的人体图像中,拥有丰富纹理特征的服装占据了大量的区域,使得不同视角下的不同姿态的图像在外观上存在着巨大差异,因此生成器需要捕捉图像分布的巨大变化.为了更好地捕获图像分布的巨大变化,研究者提出了基于变分自动编码[1-4]和基于生成对抗网络的两种主流方法[5-10],前者通过建模数据结构的方式捕捉数据不同维度之间的关系生成新数据,后者通过生成器和判别器互相博弈共同进步的方式生成图像.由于GAN采用的分布匹配loss优于VAE采用的point wise loss,使得GAN能生成更为清晰的图像,受到更多研究者的追捧.因此,本文主要是研究基于生成对抗网络(GANs)[11]的图像生成方法.

图1 由源图像和目标姿态,生成目标姿态下的新的图像
针对现有有监督的方法需要成对数据集以及无监督方法不能生成细致的纹理等问题,本文提出一种基于CycleGAN的无监督人体图像生成方法,可以在不使用成对数据集的情况下合成细节纹理清晰的人体图像,具体网络框架结构如图2所示.首先在目标姿态指引下将源图像转换为目标图像,然后使用双向循环机制将生成图像映射回源图像.网络生成器由一系列注意模块串联而成,每个模块都负责图像中的特定区域,逐步地生成图像.此外,为了生成细致的纹理,设计了外观一致性损失对特征和结构的一致性进行度量.最后,在DeepFashion和Market-1501数据集上验证了提出方法的有效性.
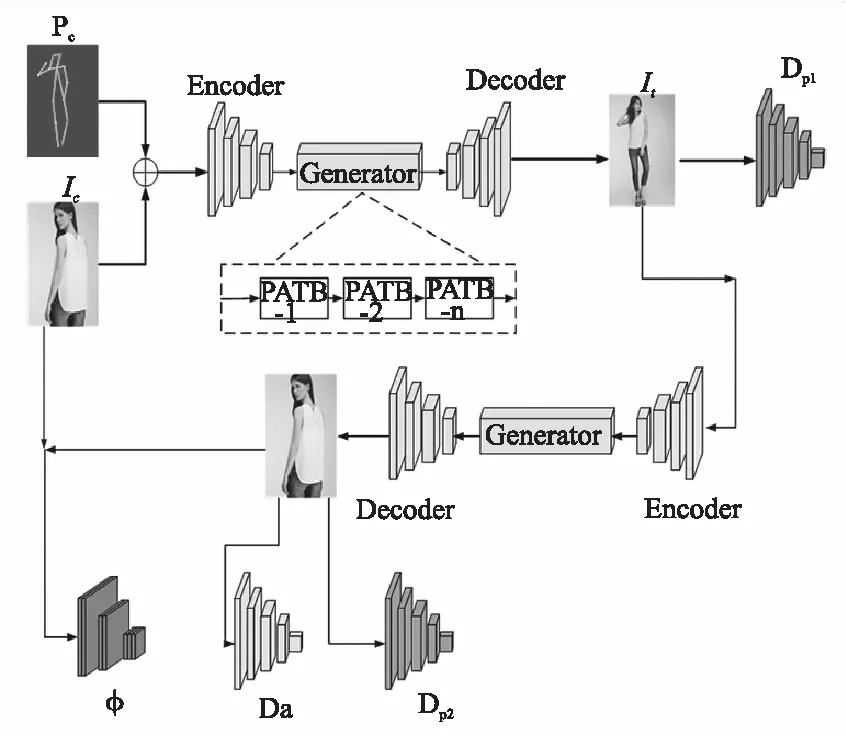
图2 模型结构图
2 相关工作
随着生成对抗网络的不断发展,人体图像生成获得了广泛的关注,在电影制作、行人重识别(Re-ID)、虚拟试衣等应用方面存在巨大潜力.针对基于生成对抗网络的人体图像生成方法,Ma等人[12]首次提出姿态引导人体图像生成模型PG2,该模型采用了coarse-to-fine策略将方法分为两个阶段,第1个阶段生成目标姿态下较为模糊的图像,第2个阶段则对第1阶段生成的图像在纹理颜色质量等方面进行提升.第二阶段虽然一定程度上提升了图像的质量,但仍无法很好地捕获图像分布的变化,使得生成的图像缺乏细致的纹理.为了获得更好外观纹理,Essner等人[13]将人体图像中的外观和姿态信息解耦,利用解耦后的姿态信息生成图片,然后在生成图片上融入源图像的外观信息.然而由于模型中包含基于U-Net的跳跃连接,会引起由姿态差异导致的特征偏移问题.为解决上述问题,Siarohin 等人[14]引入可变形形跳跃连接转换身体各部位的特征,有效缓解了特征偏移问题.Zhu等人[15]提出了渐进式的姿态注意力转换网络进行人体姿态转换,该网络通过级联9个姿态注意力转换模块能够利用外观和姿态特征平滑地指导姿态转换过程.为了对各属性实现灵活控制,Men等人[16]提出了Attribute-Decomposed GAN,将人体各部分的属性代码独立地嵌入潜在空间,并按照特定的顺序重新组合这些代码组成完整的外观代码,达到对各属性灵活控制的效果.上述方法都是基于成对数据的有监督生成方法,由于成对数据集的获取难度大、处理难度高,都使得前述的方法无法快速处理更复杂的情况.为了解决这一局限性,Pumarola等人[17]采用了循环一致性思想以无监督的方式合成人体图像,但是生成结果在细节处理方面不理想.Ma等人[18]提出一种分阶段的无监督学习网络,首先将人体图像解耦为前景,背景,姿态3种弱相关特征,之后分别以这3类特征作为目标,训练对抗性生成网络实现从高斯噪声生成新的对应特征,同时利用前一步训练得到的图像解码器对新特征解码得到新的人体图像.Song等人[19]同样采用无监督的方法提出了E2E网络,该方法将姿态转换任务分为语义解析转换和外观生成两个子任务,先由语义生成网络进行语义层面的姿态转换,再由外观生成网络合成语义感知纹理.Ma等人[20]从人物图像中分离并传输多层次的外观特征,并将其与姿态特征合并重建源人体图像.该方法以源图像为自我驱动进行无监督人体图像生成,生成了细致的纹理效果,但网络复杂度较高.Yang等人[21]建立了一个类似Encoder-Decoder网络框架从输入图像中同时提取形状和外观特征并利用学习到的形状特征为掩膜,将其应用于输入图像以获得更清晰的外观特征.该无监督框架可以在不输入目标人体骨骼图的情况下合成人体目标人体姿态图像.
3 相关算法
3.1 生成对抗网络
生成对抗网络已经被多项研究证实可以生成高质量的人体图像.生成对抗网络由两个神经网络组成,分别是生成器G和判别器D.生成器负责学习从已知数据分布pz和噪声空间Nz到数据空间Nx的映射关系.鉴别器负责对生成的图像进行甄别真假,判别样本x是否来自于真实的数据分布pdata(x).二者通过互相博弈共同进步,达到一个平衡的纳什状态,获得最终的结果.整个训练过程的目标函数可用如下多项式来表示:
(1)
3.2 基于CycleGAN的无监督学习
相较于有监督学习,无监督学习避免了成对数据集的使用,数据源域和目标域之间不需要严格的对应,使得数据集更易获取,因此,可以获得更为多样化的转换模型.Zhu等人[22]针对使用成对数据集的局限性提出了无监督的图像转换模型CycleGAN.该模型首先将源域图像映射成目标域图像,再将生成图像反向映射回源域,实现了非匹配的图像转换,在没有成对数据的情况下学习将源域x转换为目标域y.
x→G(x)→F(G(x))≈x
其中,x表示源域图像,G(x)表示经生成器获得的生成图像,再经过生成器F的反向映射后,获得的图像尽可能的与源图相一致.网络结构如图3所示.
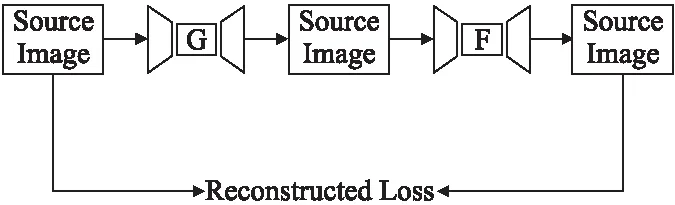
图3 CycleGAN结构图
4 方 法
4.1 符号介绍
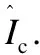
4.2 网络结构
本文的网络结构如图2所示,共包含生成器、判别器和VGG19[24]网络3个部分.生成器用于生成目标姿态下的人体图像.判别器利用3个鉴别器DP1,DP2和Da以及生成器进行生成对抗训练,促进网络生成更加逼真的图像.VGG19网络用于计算生成图像和源图像之间特征的距离,进一步提高生成图像的特征一致性.
4.2.1 生成器
为了提升生成图像的效果,本文生成器采用修改后的PATN该生成器由多个姿态转移模块级联而成,每个模块负责图像中不同位置中的姿态的转换,逐步地将图像中的姿态转换为目标姿态.姿态转移模块内部结构如图4所示,结构分为姿态和图像两个路径进行转换,其中FP和FI分别代表经过编码器后的姿态图像和人体图像,σ表示sigmoid函数,⊙表示元素相乘,⊕表示元素相加,‖表示深度连接.为了将生成图像映射回源图像,本文未舍弃姿态码,而是保留了姿态码与图像一起进行对抗训练.
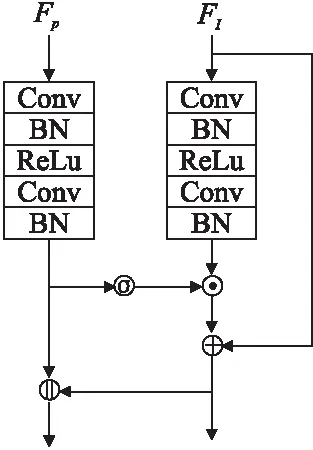
图4 姿态转移模块内部结构图
4.2.2 判别器

4.3 损失函数
4.3.1 生成对抗损失
生成对抗损失的目标在于指引生成器生成的图像接近于真实图像.该目标由生成器和判别器之间的min-max对抗过程实现.判别器需要最大化正确判别出真实图像和虚假图像的分布概率,生成器的任务是最小化生成的图像被判别器鉴别为虚假图像的概率,二者不断对抗,最终达到纳什平衡.本文使用具有DP1,DP2和Da的对抗损失函数帮助生成器优化生成参数,合成目标姿态下的人体图像.本文的生成对抗损失公式如下:
(2)
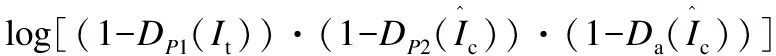
4.3.2 重建损失
4.3.3 外观一致性损失
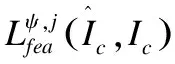
纹理一致性损失通过度量原始图像和生成图像之间特征的相似性促进生成更真实的纹理,具体公式如下:
其中,ψj(Ic)表示VGG19网络中第j层的输出特征,x表示网络ψ所有层的一个子集.
结构一致性损失Lreg建立在最小二乘函数的基础上,通过由只依赖于源图像矩阵表示的标准线性系统进行最小化.公式如下:
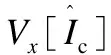
因此,外观一致性损失的总公式如下:
Lappera=Lfea+λLreg
5 实验结果及分析
5.1 数据集和实现细节
为验证提出方法的有效性,本文在Market-1501[25]和DeepFashion[26]两个数据集上进行了实验.对于两个数据集,先对数据集进行处理,将数据集中人体姿态估计器(HPE)无法检测出人体姿态的噪声图像进行去除.DeepFashion数据集包含52712张背景单一、分辨率为256×256的人体图像,从筛除后的数据集中随机挑选37258张图像作为训练集,12000张图像作为测试集.相较于DeepFashion数据集,Market-1501数据集是一个非常具有挑战性的数据集.数据集中的背景、人物姿态以及拍摄角度都较为多样化.它包含32668张、分辨率为128×64的图像,从筛除后的数据中选取12936张图像作为训练集,19732张图像作为测试集.特别是,为了客观地评价网络的泛化能力,两个测试集中都不包含训练集中相同的人物.其次,使用8GB内存的NVIDIA Quadro P4000 GPU在Pytorch框架中实现该网络.为了优化网络参数,采用既具有Adam[27]快速收敛的优点又具有SGD优点的Rectified Adam(RAdam)[28]对网络进行120k次迭代训练.初始学习率设置为1×e-5,经过60k次迭代后线性衰减为0.Market-1501和DeepFashion的batch size分别设置为1和4.
5.2 评价指标
Inception Score(IS)[29]和Structure Similarity(SSIM)[30]是最常用的评价生成图像质量的指标.前者运用Inception Net-V3网络从图像清晰度和多样性两个方面评价生成图像质量.后者是一种基于感知的计算模型,从亮度、对比度和结构3个方面度量两幅图像的相似性,值越大越好,最大值为1.此外,还引入了Detection Score(DS)[31]来衡量图像中是否可以检测到人,从而确保生成图像中的姿态完整性.然而,IS和DS仅依靠生成图像本身进行判断,忽略了它与真实图像之间的一致性.基于此,还采用了Fréchet Inception Distance(FID)[32]对生成图像进行真实感度量,该方法首先将生成图像和真实图像都转化为特征空间,再计算两种图像之间的Wasserstein-2距离.除上述的客观评价指标之外,还进行了User Study 调研,通过采集志愿者对生成图像的评价形成主观指标.
5.3 定性与定量分析
由于生成图像的判别较为主观,故而主要将本文生成的人体图像与Def-GAN[13],PATN[15]和PG2[12]的生成图像进行比较.比较结果如图5所示.从视觉效果上来说在Market-1501数据集上,本文生成的图像清晰度更高,色彩更为艳丽,失真的情况相较于其他3个方法较少.在DeepFashion数据集上,生成图像尽可能地保留了源图像的纹理特征,如发色、衣服颜色、服装细节等.与其他方法相比,本文提出的方法与使用成对数据的有监督方法具有相似的生成效果,有效地避免了对数据集的高要求,从而可以很容易地应用于更多的非刚性转移任务中.
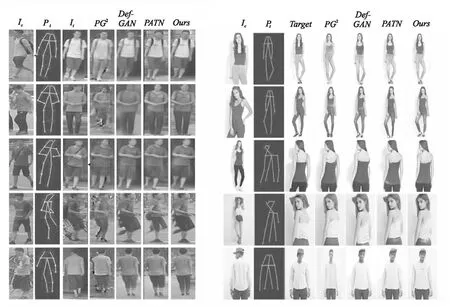
图5 在Market1501和DeepFshion数据集上的定性结果
表1展示了本文方法与Def-GAN、PATN、PG2和PATE的定量比较结果.其中,前3者都是使用成对数据的有监督方法,最后一个是无监督的方法.实验结果表明,本文提出的网络生成的图像相较于有监督的方法和无监督的方法都具有较强的竞争力.对于Market-1501数据集,IS值达到了3.533,DS值达到了0.74,高于其他方法,说明本文生成的图像在清晰度和姿态完整性上都达到了令人满意的效果.SSIM值虽然低于Def-GAN和PATN,但是查阅同样使用IS和SSIM指标评价图像的文献[12,15,33]后,发现当IS值增大时,SSIM值会略微减少.这可能意味着图像锐度越高,SSIM值越小.对于DeepFashion数据集,由于该数据集的分辨率较大,对于图像中的细节要求更高,所以在IS值上低于Def-GAN.但对于FID值,仍然优于有监督的方法Def-GAN和PATN,说明本文提出的方法生成的图像十分接近真实图像.
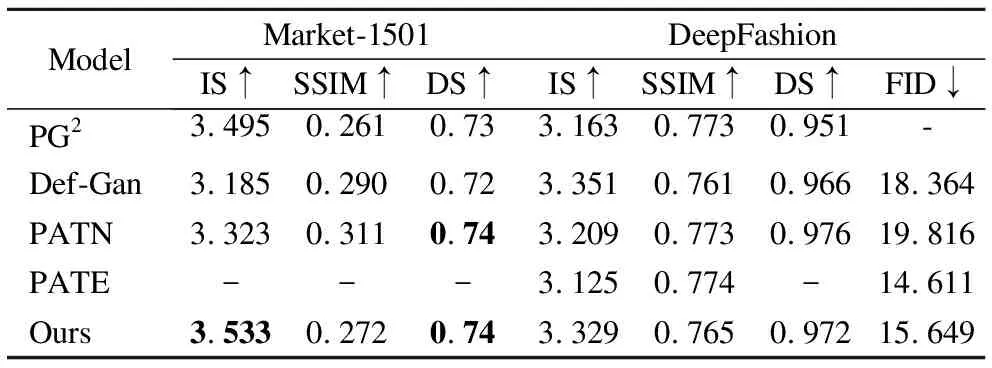
表1 DeepFashion和Market-1501数据集的量化比较
5.4 用户研究
人类的主观判断对于生成图像是一个非常重要的指标.本文依靠问卷星网站做了差异测试.实验中,100名志愿者被要求在一秒钟之内从生成图像和真实图像中选择出他认为更为真实的图像.为了保证置信度,本文采用与PG2,PATN和Def-Gan相同的评估协议,以便进行公平的比较.具体来说,遵循[18]中的规则,随机抽取55张真实图像和55张生成图像进行乱序处理,再从中挑出10张用于志愿者练习,其余100张用于评价判断.每张图像由不同的志愿者进行3次比较.结果如表2所示,本文方法生成的图像在人类的主观评价中获得了显著的效果.值的注意的是,在DeepFashion数据集上,有39.41%的生成图像被志愿者选为真实图像,优于其它3个有监督的方法.进一步验证了本文生成的图像更真实自然.

表2 用户研究
其中R2G表示真实图像被评定为生成图像所占的百分比.G2R表示生成图像被评定为真实图像的百分比.
5.5 验证外观一致性损失
为了进一步提高生成图像的外观一致性和结构完整性,本文提出了外观一致性损失.为了得出该损失对于生成图像的作用效果,本文设计了3组对比实验进行验证.该实验在保证数据集划分、迭代次数、学习率等不变的情况下,改变不同的损失函数,得到生成图像的IS、SSIM和DS值并进行比对.第1组使用传统的感知损失,第2组为留白组,既不使用外观一致性损失也不使用感知损失,第3组使用本文提出的外观一致性损失.实验结果如表3所示.
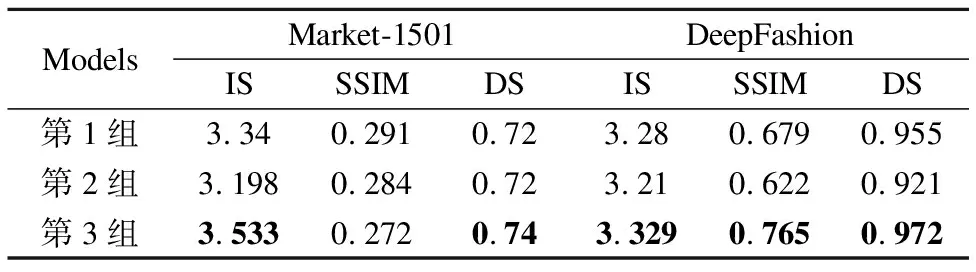
表3 外观一致性损失的定量比较
从表中可得,在Market-1501数据集上,第3组的IS值和DS值高于第1组0.193、0.02,高于第2组0.335、0.02.虽然第1组的SSIM值低于第2组和第3组,可能是由于图像锐度的增加拉低了SSIM值,但整体的图像质量仍然高于第2组和第3组.在DeepFshion数据集上,第3组的IS值、SSIM值和DS值相较于第1组提高了1.493%、12.666%、1.780%,相较于第2组提升了3.707%、22.990%、5.537%.说明本文提出的外观一致性方法在对于提高图像质量贡献了积极地作用,同时也说明了该损失优于传统的感知损失.
6 结 论
为避免成对数据集的需求,本文提出了基于CycleGAN循环一致性思想的人体图像合成方法,通过保留源图像的风格和语义内容规避了对训练数据的成对需求.为了更好地指导图像生成过程,使用了两个专为图像真实性和姿态一致性而设计的判别器.此外,还提出了Appearance Consensus Loss,通过对比源图像和生成图像之间的特征差异和加入姿态保持正则项在图像细节和人物姿态两个方面进一步提升生成图像的质量.最后,在Market-1501和DeepFshion数据集上对提出的方法进行了实验,实验的定量和定性结果表明,生成的图像质量优于其他无监督方法生成的图像,即使相较于使用成对数据的有监督方法,本方法也具有竞争力.在未来的研究中,将进一步验证本文提出的方法在其他非刚性对象转换任务中的可行性,克服了转换任务中缺少成对数据集的局限.
