面向教学资源的均值惩罚随机森林非平稳时序预测方法
2021-02-28袁景凌陈旻骋盛德明
罗 佩,袁景凌,陈旻骋,盛德明
(武汉理工大学 计算机科学与技术学院,武汉 430070)
1 引 言
随着互联网技术的迅猛发展,在线教育受到越来越多人的关注.在线教育是以网络为介质的教学方式,相较于传统教育,在线教育是更方便学生的学习方式.教学资源需求具有及时性,根据用户使用标签、关键字、内容等对资源进行请求来计算不同资源的实时请求量,从而及时调整不同资源的内存分配或页面占比及页面位置,智能改善页面,提高用户的个性化体验.这种资源的及时性多由资源请求点击数据以时间序列的形式表现出来,因此对面向教学资源进行时序预测是一项有价值的任务.目前已有多种成熟的模型方法来对时序数据进行时序规律推理[1-4],如广为采用的支持向量机模型[5]、自回归移动平均模型(ARMA)[6]、差分自回归滑动平均模型(ARIMA)[7,8]、贝叶斯模型(Bayesian)[9]、长短期记忆模型(LSTM)[10,11]、门循环单元模型(GRU)[11]、循环神经网络模型(RNN)[12]等.然而大部分是基于时序稳定的前提.其中长短期记忆模型具有建模简单,实现简单的优点,但同时存在着速度缓慢,并行差不好落地的缺点,即便是在对序列建模有优势的情况下,对周期性不明显的非稳定时序数据预测偏向滑动平均,效果较差.差分自回归滑动模型虽然是统计模型中最常见的一种用来进行时间序列预测的模型,且建模简单,仅需要内生变量,然而其要求时序数据必须平稳,若非平稳需要先通过差分化稳定数据,对于波动大的数据无法捕捉其规律,且本质仅能捕捉线性关系,而不能捕捉非线性关系.决策树也是时间序列预测的主流算法之一[13].但其在建树时需要把所有属性读入内存,使得无法对大规模数据进行处理,而且容易出现过拟合,从而使得对测试数据集分类或回归效果不佳.实际生活中由于受到许多不确定因素的影响,大部分时序都表现了强烈的非平稳性.传统的模型方法在非平稳时序预测上无法达到较优的预测效果,因而非平稳时间序列的预测始终是一个具备挑战性的任务.
针对这个挑战,我们引入均值惩罚机制来对时间序列数据进行处理,使得时间序列数据在输入到模型之前就降低了不稳定性和随机性.同时选择随机森林作为预测模型方法,随机森林是一种集成学习方法[14].该方法拥有预测准确率高、训练时间短、设置参数少和泛化误差较小等优势,可以有效避免发生过拟合现象.加之随机森林对多元共线性不敏感,预测非平衡时序数据时较为稳健,能够很好地预测上千解释变量.使用随机森林模型进行预测在众多领域都取得了一定的效果[15-17],证明了本文实验的可行性.本文提出了一种均值惩罚随机森林非平稳时序预测方法(PMP-RF),针对非平稳时序数据集进行短期预测.本文主要工作如下:
1)针对获得的时间序列数据集,进行稳定性检验,结合时序图和单位根检验(ADF),通过时序图、显著性检验统计量以及置信度共同判断筛选非平稳的时间序列.
2)对于非平稳时序的短期预测结果误差较大的现象,提出均值惩罚机制来预处理数据,根据时序的周期调整原始数据中的过多偏离均值的节点值,提高预测准确度.
3)本文基于随机森林预测理论和单位根检测时序平稳性方法以及均值惩罚处理方法对面向教学资源的非平稳时序进行预测.
实验结果表明,基于均值惩罚的随机森林模型预测精度优于LSTM模型、SVM模型、ARIMA模型以及原始随机森林模型,且在原始模型基础上有0.109662%的精度提升.
2 均值惩罚随机森林预测方法
2.1 教学资源时间序列的非平稳性检测
本文拟对教学资源非平稳时序进行预测,因此在预测之前需要对教学资源时间序列进行非平稳性检测.一个时序样本包含了随机生成变量的历史与当下,这个随机过程的基本特性可以用均值、方差、协方差来表征,如果在未来的时间里这些基本特性能保持不变,这个时序则是平稳的.本文采用常用的时序图和最严格的统计检测方法扩充迪基-富勒(Augmented Dickey—Fuller)方法,简称ADF方法,检测时序的平稳性.一个平稳时序在时序图上离散点会表现出一种围绕其均值不断波动的过程,而非平稳时序在不同的时间段则表现出具有不同的均值.
设给定的时间序列表示如下:
T={(x1,y1),(x2,y2),…(xi,yi),…,(xn,yn)}∈(X,Y)l
(1)
其中xi表示时刻,yi表示随机变量.则该时序的回归模型的函数为:
yi=byi-1+a+i
(2)
ADF单位根检测首先令原假设为存在单位根,得到显著性检验统计量以及置信度.其步骤具体为:
假设拒绝原假设,检验时间趋势项系数的显著性;
a.若时间趋势项的假设检验值结果明显小于3个置信度,则认为该序列为趋势平稳;
b.若时间趋势项的假设检验值结果并不完全小于3个置信度,则观察检验结果是否趋于零,若趋于零则认为该序列为趋势平稳,否则是非平稳的.
表1为本文采用来自于ClarkNet WWW服务器的教学资源访问日志的时序数据集进行ADF单位根检测,由于数据的缺失我们采用了均值替换的方法,因此时序是无滞后的,ADF检测中最大滞留数取0值.图1为该时序数据集连续3条时序图,表1是采取对这3条时序进行ADF单位根检测的结果,数字保留小数点后6位.
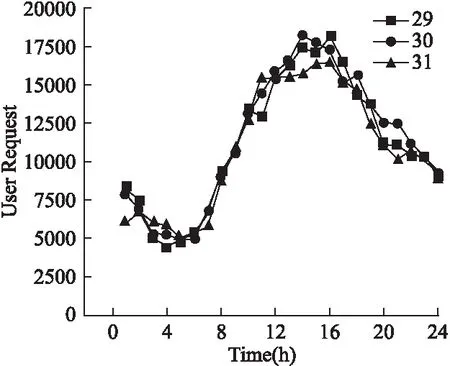
图1 时序图
从图1时序图可以看出,本文使用的教学资源29-31选段时序呈现了明显的周期性且在不同的时间段表现出具有不同的均值,因此粗测可得两段时序都是非平稳的.
从表1ADF单位根检验结果可以看出,对第29时序进行ADF单位根检验中,t检验与1%、5%、10%不同程度拒绝原假设的比较是同时大于1%、5%、10%的,即未拒绝原假设,即单位根不存在,这个第29时序是非平稳时序;同样在对第30和第31时序进行ADF单位根检验中,t检验与1%、5%、10%不同程度拒绝原假设的比较也是同时大于1%、5%、10%的,且Pvalue远大于0.05,即未拒绝原假设,说明同样存在单位根,即为非平稳时序,综合可知29-31选段时序数据也是非平稳时序.结合图表说明本文采用该方法证明选定的教育资源时序数据集是非平稳时序数据集成立.
2.2 均值惩罚数据预处理(PMP)
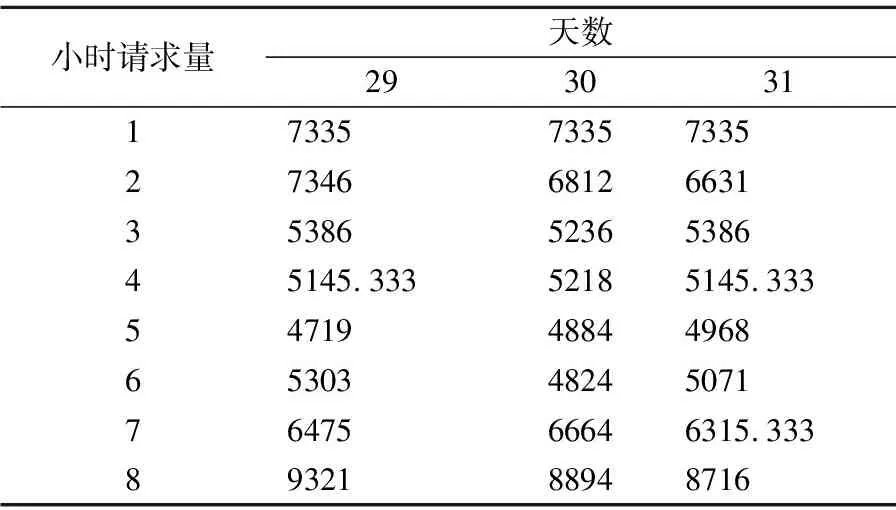
通过了ADF单位根检测的教学资源数据集即非平稳时序数据集,此时的数据集周期性明显,不够平稳,易导致预测的结果误差较大,因此我们提出采用均值惩罚机制来预处理经过ADF检测为非平稳时序的数据,形成最大化保留原本特性同时提高时序平稳性的训练集以及保持原状的测试集.
采用公式(3)和公式(4)对一组(m条)需要实验的时序数据进行预处理.
yi_avg=(y1i+y2i+…+ymi)/m
(3)
(4)
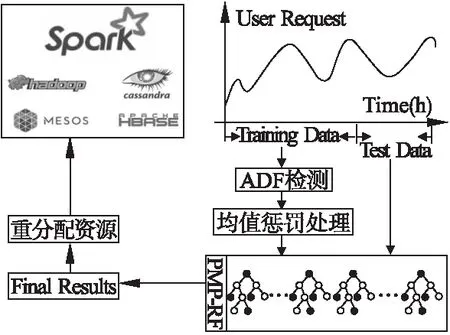
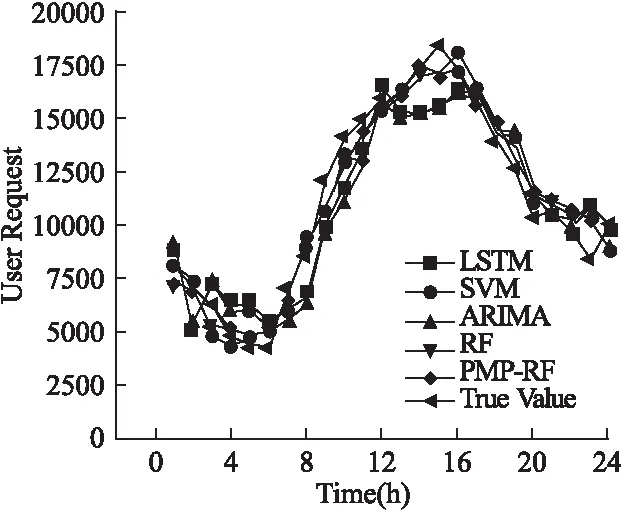
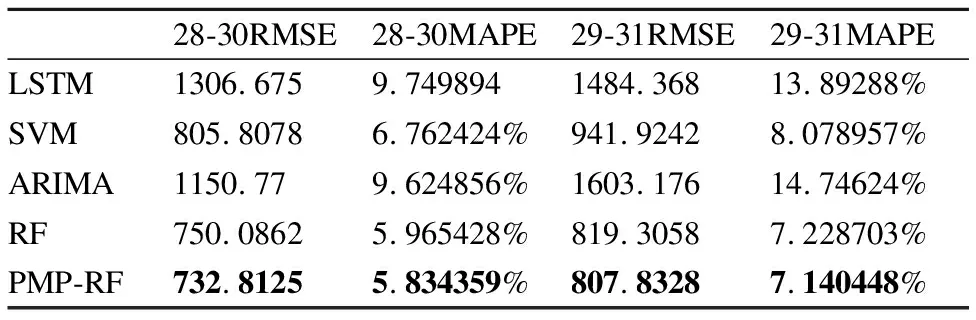
其中,yi表示时间序列中每天第i(0 表2 训练集中部分原始数据 表3 经过均值惩罚后的训练集数据(pf=1) 由于时序的平稳性表现在数据围绕着一个不变的均值上下波动,因此相比于波动较小的非平稳时序,波动较大的非平稳时序有更多的节点数据与均值偏离较大,即存在大量的噪声节点数据(偏离期望值的数据).此时就体现了PMP-RF中均值惩罚预处理数据的优势,在阈值的把关下,这些通过了ADF检测的非平稳时序噪声节点数据都会被惩罚修正,降低非平稳性.而由于波动较大,需要被均值惩罚的噪声节点数据较波动较小的非平稳时序更多,就能更大幅度降低非平稳性来提高预测精度. 随机森林算法是一种装袋算法(bagging算法),其应用于分类和回归任务的步骤类似,主要区别在于预测阶段的方法就是bagging的策略,分类采用投票,回归采用均值.本文模型对每个样本建立一棵回归决策树,最后取均值得到预测结果.随机森林算法预测的基本步骤如下: 步骤1.给定样本集d、特征集F,最大叶子结点数p,决策树棵数K,树深h. 步骤2.采用bootstrap取样方法有放回地随机从原始样本集中抽取K轮,每轮抽取等规模训练样本集,作为单棵决策树的训练样本集. 由于是有放回的重复抽样,对于每一棵决策树,样本集d中几乎有37%的数据不出现在该树的训练样本集中,这些数据被称作袋外估计样本. 步骤3.遍历K份等规模训练样本集以构造回归决策树,每棵决策树样本集的每个结点根据参数随机从特征集F中选取由f个特征变量,该棵决策树根节点由该样本集和f个特征变量生成. 步骤4.从这f个特征变量中选择一个导致最优划分的变量来分裂结点,直到叶子结点数目达到阈值即最大叶子结点数p.通过前文的定理得知,该步骤是为了控制随机森林的泛化误差,泛化误差计算公式如下: E^*=P_(X,Y)(mg(X,Y)<0) (5) 根据大树定理可知,无论决策树的数量如何增长,泛化误差总是收敛于: (6) 步骤5.K棵决策树遍历构造完成后组成随机森林,输入一组测试数据test={(x1,y1),(x2,y2),…(xi,yi),…,(xn,yn)}到随机森林中,每棵树进行预测,最终预测集由每棵决策树预测的结果取均值所得. 随机森林预测的算法表示如下: 算法1.RF Prediction 输入:样本集d,特征集F,决策树数量K,最大叶子结点数p,测试集test={(x1,y1),(x2,y2),…(xi,yi),…,(xn,yn)} 1.Begin 2.fori ← 1 to Kdo//构建决策树 3.bi←bootstrap(d,N); //bootstrap随机从d中抽样大小为N的样本集 4.ti←treeNode(bi);//在样本上建树 5.whilenode size != pdo 6.f←selectRandomVar(F,m); //从F中随机选择f个预测变量的m个子集 7.forvjin fdo 8.ifsplitCriterion(vj)==Truethen//分裂结点 9.vj1,vj2←splitNode(vj); 10.endif 11.endfor 12.endwhile 13.endfor 15.End 由相关工作可知,在时序预测工作中,RF算法有其独特的优势,然而时序不平稳时,预测精度会随之下降.本文建立基于均值惩罚的随机森林预测模型,通过将通过了ADF检测的教学资源非平稳时序数据转换成均值惩罚后的时序数据,然后再采用随机森林算法对数据进行建模.在均值惩罚的过程中,设置惩罚因子对原始数据点中的异常值(相对于均值过高或过低的数据点)增加惩罚项,均值惩罚后的训练数据相对于原始数据要平稳很多,同时单一的惩罚处理也最大限度保留原始数据的特性.最后将均值惩罚处理后的样本集输入随机森林回归模型中,得到最终的预测结果. 均值惩罚随机森林预测算法表示如下: 算法2.PMP-RF 输入:原始样本集d1={T1,T2,…Tm},预测值数量n,训练集样本数m 1.Begin 2.forTjin d1do//遍历样本集检测非平稳性 3.ifadf(Tj)==true and j≥mthen 4.fori←1 to ndo//遍历时序的点 6.ifABS(yji-yi_avg)/yji>6%then 7.yji←yji-(yji-yi_avg)×pf; //均值惩罚 8.endif 9.endfor 10.endif 11.endfor 13.End 由算法1随机森林预测算法可知,当每棵决策树的样本大小为N,特征集数量为F,树深为D时,决策树生长将特征集内所有的特征变量都作为分裂候选,并为其计算一个评价指标,所以决策树遍历每层的时间复杂度为O(N×F),树深D,则一次决策的时间复杂度O(N×F×D),K棵决策树组成的随机森林遍历复杂度为O(K×N×F×D).同样,平均每个特征变量的切分点数量为split,随机森林的空间复杂度为O(N+F×split×K).由于PMP-RF模型需要先进行ADF检测以及均值惩罚,当样本集内时序数量为m,一条时序对应变量数为n时,PMP-RF的时间复杂度为O(n×m+K×N×F×D),而由于ADF检测和均值惩罚后的样本集维数时无变动地输入进随机森林模型中,因此空间复杂度和随机森林模型的相通,为O(N+F×split×K). 图2展示了教学资源非平稳时序数据预测流程,对时序进行划分后输入PMP-RF模型中进行均值惩罚数据预处理和预测,将预测后的结果反馈回在线教育平台,使其可以针对性地重分配资源,实现教育资源更好的及时性和交互性. 图2 教学资源非平稳时序预测流程图 本文所使用非平稳时序数据集来自于ClarkNet WWW服务器的教学资源访问日志数据集,按4天为一组对其进行分段,取其中08.28-08.31这4天作为28-30选段时序以及08.29-09.01这4天作为29-31选段时序数据进行处理得到每天的24小时访问教学资源的次数频度数据.以08.28-08.30这3天和08.29-08.31这3天的24小时预测08.31和09.01一天24小时作为两次独立实验,每天数据中的前3天数据作为对历史分析的数据集合,后一天的数据作为测量结果分析的集合.对于数据集中部分数据的缺失我们采用了均值替换的方法. 3.2.1 Rootmeansquare error(RMSE) 资源需求预测结果的评价指标采用均方根误差,计算公式为: (7) 3.2.2 Mean absolute percentage error(MAPE) 资源需求预测结果的评价指标采用平均绝对百分比误差,计算公式为: (8) 基于相关工作部分,本文采用长短期记忆模型(LSTM)、支持向量机模型(SVM)、差分自回归平均模型(ARIMA)以及随机森林(RF)对教学资源非平稳时序数据集进行预测,作为对论文中提出的面向教学资源的均值惩罚随机森林预测模型(PMP-RF)的对比,采用两组非连续紧密段非平稳时序,第1组波动较大,第2组波动较小.图3、图4是两次实验5种模型对该教学资源请求时序数据集预测结果与真实数据的曲线拟合图. 图3 28-30选段预测结果图 图4 29-31选段预测结果图 对以上两次实验计算得出有关LSTM、SVM、ARIMA、RF以及PMP-RF这5个预测模型的评价指标结果,如表4所示. 表4 模型预测评价指标对比 由时序非平稳性检测部分可知28-30选段非平稳时序相对29-31组波动较大,针对28-30选段时序的预测未经均值惩罚预处理的RF模型和经过均值惩罚预处理的PMP-RF模型都表现出了很大的优势,证明我们选择使用随机森林模型作为基本模型的正确性,且PMP-RF均方误差和平均绝对误差较RF模型分别低了17.2737和0.131069%,证明均值惩罚对非平稳时序数据进行预处理的可行性.观察有LSTM和ARIMA的预测结果则有着较大的不稳定性和误差,PMP-RF均方误差和平均绝对误差较同样表现优异的SVM分别低了72.9953和0.928065%,证明我们的PMP-RF模型明显提高了相对波动较大的28-30选段非平稳时序的预测精度. 而相对波动较小的29-31选段非平稳时序的预测,该选段时序有着较强的周期性,非平稳性也更明显,从而导致较大的均方误差以及平均绝对百分比误差.但PMP-RF仍旧表现出了优异的预测效果,其均方误差和平均绝对误差较效果较优的SVM高了134.0914和0.934477%,可以看出PMP-RF模型仍有着较高的预测精度,且其误差均高于LSTM、SVM、ARIMA、RF 4个模型.结合波动较大的28-30选段时序预测可知,在对非平稳性时序预测上,PMP-RF表现最好.且在非平稳性更大的选段非平稳时序上也能提高预测精确度,本文实验波动较大的28-30选段时序,在3天72个时间节点中有24个节点数据被惩罚处理,而波动较小的29-31选段时序,在3天72个时间节点中仅有15个节点数据被惩罚处理.更大幅度地降低了非平稳性,因此PMP-RF算法对于波动较大的非平稳时序也能够提高预测精度.综合两组实验可以看出PMP-RF模型具有较高的预测精准度和预测稳定性. 本文研究了面向教学资源的非平稳时序预测,了解了时序数据非平稳性检测、均值惩罚方法以及随机森林在时序预测中的性质,在此基础上提出了一种非平稳时序的预测方法,即基于均值惩罚的随机森林非平稳时许预测方法.通过对服务器访问日志请求量的预测结果表明,该方法较传统的预测方法更为稳定,较纯粹的RF预测方法更为精确,在非平稳性相对较差的时序预测上表现优异,在波动偏大的非平稳时序预测上也有稳定的精确度. 本文采用的预测方法应用在教学资源服务器的访问日志请求数据集,取得了预想的效果.但不同的教学平台仍有大量大教学资源非平稳时序,这些非平稳时序也根据其复杂度分为单一变量时序和多变量时序,如何将本文的方法普遍应用于非平稳时序的预测甚至是多变量非平稳时序的预测中,提升在波动较大导致非平稳性较小的非平稳时序上预测的精度,在PMP-RF的参数选取方面、同单一随机森林模型参数关系研究等方面,都还需要进一步研究.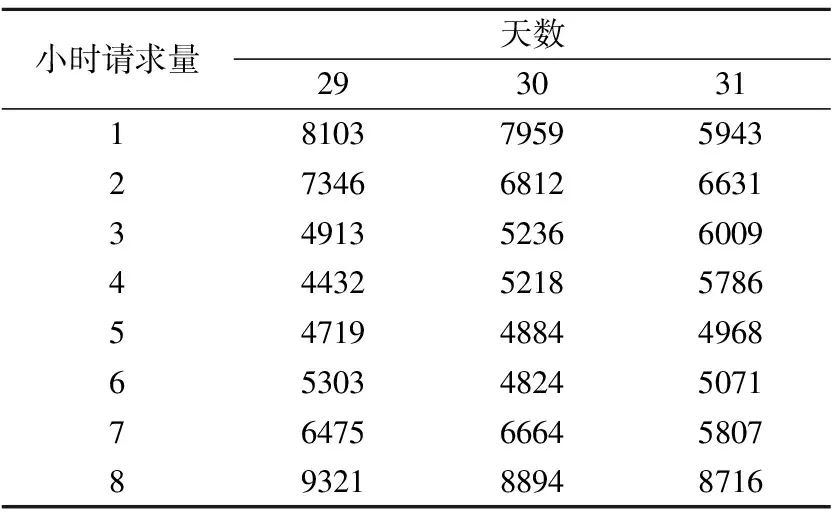
2.3 随机森林预测算法
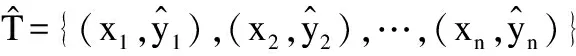
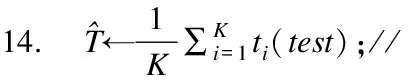
2.4 面向教学资源的均值惩罚随机森林预测方法
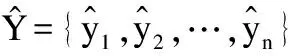

3 实验评估
3.1 实验数据集简单介绍
3.2 实验评价指标

3.3 实验结果分析

4 总结与展望
