结合注意力及胶囊网络的多通道关系抽取模型
2021-02-28张亚彤彭敦陆
张亚彤,彭敦陆
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
随着互联网技术的不断发展,用户信息规模呈现出爆炸式增长.信息抽取可以从纯文本的大量冗余信息中提取出有价值的信息,因此可以解决信息爆炸的问题.关系抽取[1,2]作为信息抽取的子任务之一,可以从非结构化文本数据中自动提取实体对之间的关系.从RE中获得的实体关系三元组可以应用于自然语言处理的许多下游任务中,例如:知识图谱的构建,智能问答等.
传统有监督关系抽取方法需要大量人工标注数据,非常耗费人力资源和时间.为解决这个问题,文献[3]提出了远程监督关系抽取方法,通过对齐知识库和文本来自动地生成训练数据.远程监督本质上是一种自动标注样本的方法,但它的假设太强,会导致错误标注样本的问题.为了缓解这个问题,文献[4]提出多实例远程监督关系抽取.但是,这些方法的数据处理过度依赖于NLP工具,这将会导致错误积累并降低关系抽取的性能.
近年来,神经网络方法逐渐应用于关系抽取任务中,该方法无需复杂的特征工程即可自动提取句子的特征.比如卷积神经网络[5]、循环神经网络[6],长短期记忆网络[7]和基于注意力机制的双向长短期记忆网络[8].但现有方法存在两个主要问题:首先,注意力机制采取的加权和形式会丢失句子的时序信息,且这些方法采用的表示句子的方法都是单通道的.单个通道在注意力分配权重时可能会出现错误,最能反应实体关系的单词可能并没有被分配较高权重,因此单通道注意力分配机制存在着误差,影响最终的分类结果.例如:在“Last year,microsoft sued google to stop a star computer scientist and manager at microsoft,Kai-fu Lee,from working on search technology at google.”句子中,要判断kai-fu lee(实体1)和Microsoft(实体2)中所存在的关系,manager单词明显对判断出这对实体中所存在关系更重要,但是在单通道注意力机制分配权重过程中,它可能并没有被分配到较大的权重.如果只根据这一个通道所分配的注意力权重去进行关系分类,就会引起误差,但在采用多通道的注意力机制中,由于其他通道的存在,注意力机制就会有更大概率给manager单词分配高权重.因此,采用多通道的注意力机制会平衡误差,使模型的泛化能力更强.其次,在实体关系分类中,实体的位置信息对于提取关系非常重要,但现有关系抽取方法常采用卷积神经网络进行最终关系分类,卷积神经网络在池化过程中会丢失掉大量信息,不能充分利用标记实体的位置信息,且忽略了低层特征与高层特征之间的空间关系.
针对上述问题,本文提出了一种基于注意力机制及胶囊网络的多通道关系抽取模型(BG-AMC),该模型首先通过双向GRU神经网络对句子词向量进行编码以获取句子的高维语义,接着利用注意力机制辅助生成句子的多通道表示,最后采用胶囊网络进行关系分类.多通道中的每个通道在递归传播时互不影响,可减轻注意力机制为单词分配权重时所产生的误差,使神经网络学习到同一句子的多种表示形式,减轻句子的歧义.胶囊网络可充分考虑到标记的实体及其位置信息,并克服CNN中池化操作丢失掉大量信息的问题.
2 相关工作
关系抽取是自然语言处理中最重要的任务之一.到目前为止,已经有很多种不同的方法来进行关系抽取,比如无监督关系抽取、半监督关系抽取、和有监督关系抽取等[9,10].其中,有监督关系抽取是常用方法,并且取得了很不错的效果.然而有监督关系抽取方法严重依赖于高质量的标注数据,非常耗费人力资源和时间.
为了解决有监督关系抽取要人工标注数据这个问题,文献[3]采用远程监督方法,通过对齐知识库和文本来自动地生成训练数据.该方法假设如果两个实体在知识库中有某种关系的话,则所有包含这两个实体的句子表达的都是这同一种关系.远程监督本质上是一种自动标注样本的方法,但是它的假设太强,会导致错误标注样本的问题.为了缓解这个问题,有的研究[4]将关系分类任务当作一个多实例多标签的学习问题.知识库中一个实体对的关系是已知的,而外部语料库中包含该实体对的多个句子,表达的关系是未知的(自动标注的结果未知真假).多实例学习的假设是:这些句子中至少有一个句子表达了已知的关系.于是从多个句子中只挑出最重要的一个句子,作为这个实体对的样本加入到训练中.文献[5]提出at-least-one 多实例学习和分块卷积神经网络(PCNNs+MIL)来进行远程监督关系抽取.但现有的远程监督关系抽取有两个问题:
首先,由于识别实体关系是在句子级别进行的,有些句子可能仅包括几个单词,因此句子存在特征稀疏性问题.特征稀疏性更加突出了捕获句子结构和语义信息的重要性.许多语言现象(例如句子的多义性、歧义性)会影响关系分类最终分类的准确率.现有远程监督关系抽取方法默认采用单通道的注意力机制去获取句子中的单词对判别该句实体之间的关系重要性,因此在注意力分配权重时可能存在误差.针对这一问题,提出多通道架构,其中多通道灵感来自于在图像处理领域,图像由3个通道(红、绿、蓝)组成,每个通道都用多层神经网络层进行处理,由于每个通道在循环传播过程中没有相互作用,它使神经网络能够从每个通道学习到不同的表示,因此每个通道都包含了一个独立的图像描述.在关系抽取中采用多通道架构,可以使每个单词在同一个句子中分配到不同的注意力权重,因此学习到句子不同的表现形式,有助于捕捉句子的结构和语义信息以减轻句子的歧义现象,使模型的泛化能力更强.多通道概念已经在自然语言处理领域得到了一些应用,例如句子分类[11],情感分类[12],单词表示[13]等.
其次,卷积神经网络(CNN)因其优秀的特征提取能力已经被广泛运用到远程监督关系抽取任务中,但是,CNN在关系抽取中并没有充分考虑标记的实体及其位置信息,忽略了低层特征与高层特征之间的空间关系,并且CNN的池化操作会丢失掉大量信息.针对CNN中存在的问题,文献[14]提出基于动态路由算法的胶囊网络,其中胶囊是一组向量,胶囊网络解决了CNN 低层特征向高层特征传输时的局限性.文献[15]将胶囊网络应用于文本分类模型架构中的最后一层,以取代最大池化完成分类任务,在文本分类常用数据集上的实验结果表明胶囊网络相比CNN表现卓越.文献[16]首次将胶囊网络应用到关系分类中,在卷积操作后使用胶囊去代替池化操作,最终输出的胶囊的个数既是关系的个数,胶囊的长度表示实体所属类别的概率.
3 多通道及胶囊网络模型
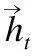

图1 BG-AMC框架图
3.1 句子表示
3.1.1 词嵌入表示
词嵌入将句子中的每个单词映射为一个低维的实数向量,该向量可以捕获单词的语义信息.在本文中,给定一个包含m个单词的句子X={w1,w2,…wm}.每个单词wi均是实数向量,由词嵌入矩阵V∈R|V|×d转换而成,其中V表示词汇表的大小,dw是词嵌入的维度.
3.1.2 位置嵌入表示
在关系抽取任务中,靠近实体的词通常可以为确定实体之间的关系提供更多的信息.因此,本文将句子中每个单词到两个实体的距离拼接到词向量表示当中.采用文献[5]中方法,使用位置特征(PF)去指定实体对,PF是当前单词到两个实体e1和e2相对距离的组合.若词嵌入的维度为dw,位置嵌入的维度为dp,将句子中每个单词的词嵌入和位置嵌入连接起来,得到句子的向量序列X={x1,x2,…xm},其中xi∈Rd(d=dw+2×dp).
3.2 Bi-GRU层
门控循环单元(GRU)是一种类似LSTM的循环神经网络,它的输入和输出结构与普通的RNN是一样的.和LSTM相比,GRU的结构更加简单、参数少、性能更优.GRU包括两个门机制:重置门r和更新门z,对于某个时间节点t,它们的计算公式为:
zt=σ(Wzxt+Uzht-1)
(1)
rt=σ(Wrxt+Urht-1)
(2)
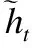
(3)
(4)


3.3 采用多通道的注意力机制
句子中的每一个单词对判别该句实体之间的关系并没有起到均等的作用.因此,本模块采用单词级别的注意力机制来提取对句子含义有重要影响的单词.由于单通道的注意力机制在为单词分配注意力权重时可能会存在误差,所以本模块采用多通道的单词级别注意力机制,每个通道都用多层神经网络层进行处理,且每个通道在循环传播过程中没有相互作用,它使神经网络能够从每个通道学习到不同的表示,因此每个通道都包含了一个独立的句子描述.假设需要得到l个通道,那么第l个通道的计算方式为:
scorelt=Wl·tanh(Wl2·ht+bl)
(5)
(6)
clt=alt·ht
(7)
Cl=[cil,ci2,…,cim]
(8)
其中,Wi、Wi2是可训练的参数矩阵,tanh()是双曲正切激活函数,bl是偏置项,每个通道的参数独立训练.exp是以e为底的指数函数,clt是第t个词在第l个通道的高维向量表示,Cl是第l个通道的表示.
对于给定的句子包,采用文献[5]提出的方法在给定句子包中选择一句最大概率表达这种关系的句子去训练模型.
3.4 胶囊网络
本模块将上一层中l个通道的结果进行拼接,得到Ce=[C1⊕C2⊕…Cl],其中CeRm×2×(l×B).假设ui∈Rd表示胶囊的参数集,其中d是胶囊的维度.不同窗口之间共享卷积核的大小设置为Wb∈R2×(l×B).在CeRm×2×(l×B)上以步长1每次滑动2个向量,最终形成的矩阵为U∈R(m+1)×C×d,共C×d个卷积核.
初级子胶囊层:因为卷积神经网络在池化过程中会丢失掉句子的部分特征,所以本模块在经过卷积操作得到U矩阵后并不进行池化操作,而是将U进行重排列以得到初级子胶囊,最终得到的重排列结果为:U={u1,u2,…,u(m+1)×C},其中共有(m+1)×C个d维向量作为初级子胶囊.
初级子胶囊的和通过聚类表达为高级胶囊,为了增强特征表示的能力,每个初级子胶囊ui在传入高级胶囊vi之前要和转换矩阵Wij∈Rd×d相乘得到预测向量uj|i∈Rd.为了减少训练参数并防止过拟合,转换矩阵在初级子胶囊上采取共享权重Wj的方式,由于共有E种关系,所以共享权重Wj的个数取为E,转换公式为:
uj|i=Wjui
(9)
动态路由算法:
胶囊网络中的每个初级子胶囊ui传输到高级胶囊uj采用的是动态路由算法,其算法流程见算法1[14].
算法 1.Routing algorithm
输入:weight parameterbij
times of routingr
number of capsule layersl
1.procedureROUTING(uj|i,r,l)
2.forall capsuleiin layer and capsulejin layer(l+1):bij←0
3.forriterationsdo
4.forall capsuleiin layerl:ci←softmax(bi)
5.forall capsulejin layer(l+1):sj←∑1cijuj|i

7.forall capsuleiin layerlandjin layer(l+1)bij←bij+uj|i*vj
8. returnvj
输出:vector output of capsule j:vj.
其中,bij是初始化系数,表示l层的胶囊uj|i连接到l+1层胶囊vj的可能性,bij初始值取0目的是在首次迭代时l层胶囊uj|i到l+1层胶囊vj的概率相同;r表示迭代次数;耦合系数ci|j由bij进行迭代更新;sj表示l层胶囊uj|i的加权结果;vj的结果是由压扁(squash)函数得到的,其长度代表了最终关系分类的概率.
动态路由的基本思想是一个非线性映射,表示为:
其中H=(m+1)×C,E是关系的种类数(父胶囊个数).
对于实体关系分类任务,胶囊网络最终输出的向量vj表示分类结果,其长度代表分类的概率,对每个关LK系胶囊采用独立的间隔损失:
Lk=Ykmax(0,m+-‖vk‖)2+
λ(1-Yk)max(0,‖vk‖-m-)2
(10)
如果关系k存在即Yk=1,取m+=0.9,关系k不存在即Yk=0,取m-=0.1,λ=0.5.
总损失为:
(11)
4 实验设置
4.1 数据集介绍
为了验证本模型的有效性,在Ridel NYT数据集和GIDS数据集上进行了实验,表1总结了数据集的详细信息.

表1 数据集详细信息
NYT数据集是由Riedel等人[17]通过将Freebase知识库中的关系与纽约时报语料库(NYT)进行启发式对齐生成的,其中2005-2006年的句子用于训练集,2007年以后的句子用于测试集.数据集中的实体已由Stanford NER标注好.该数据集在远程监督关系抽取任务上有着广泛的应用.
GIDS:全称Google Distant Supervision数据集[18],此数据集能保证多实例学习的“at-least-one”假设成立.
4.2 模型相关参数设置
BG-SAC 模型实验设备的操作系统是 Win10,其它设备信息是 Intel(R)Core(TM)i7-8700K CPU @ 3.70GHz,64GB内存以及两块NVIDIA GeForce 1080Ti 显卡,然后在Python3.6 编程完成实验.
在文献[4,8,14]等的参数基础上做了多次尝试,在得到最优超参数后,采用 Adam 算法对模型的训练进行优化.本文模型参数设置如表2所示.

表2 模型参数设置表
4.3 基线模型
为了评估BG-AMC模型,对比了以下基线模型:
Mintz:文献[3]针对远程监督范式提出的一个多类别逻辑回归模型.
MultiR:文献[4]针对多实例学习提出的概率图模型.
PCNN:文献[5]提出的一个基于卷积神经网络的关系抽取模型,该模型使用了分段最大池化来进行句子编码.
MIMLRE:文献[19]一个同时进行多实例和多标签建模的图模型.
PCNN+ATT:文献[20]在PCNN的最大池化句子编码的基础上,加入了句子级别的注意力机制.
BGWA:文献[18]提出的一个基于双向GRU加上单词和句子级别的注意力机制的关系抽取模型.
BG-AMC:本文提出的模型,更多细节请见第5小节.
4.4 评价标准
采用文献[19]中的方法,使用留出法来评估模型.实验采用准确率-召回率曲线(Precision-Recall)进行评估,评估过程通过对比那些从测试集句子中提取到的关系和那些在Freebase中的关系来完成.准确率、召回率的计算公式:
(12)
(13)
其中out_right表示输出中预测正确的关系数量,out_all表示输出中总共的关系数量,test_all表示测试集中总共的关系数量.
5 实验结果
在本节中,实验分析了两个主要问题:
Q1.BG-AMC在远程监督关系抽取任务上是否比现有的方法更有效?(5.1)
Q2.不同的通道数的选择对BG-AMC的表现会有哪些影响?(5.2)
5.1 关系抽取结果有效性对比
为了评估BG-AMC模型的有效性,在Ridel数据集上对比了4.3节中提到的所有基线模型.在GIDS数据集上对比了神经网络的基线模型.在Riedel数据集上的准确率-召回率曲线如图2所示,在GIDS数据集上的准确率-召回率曲线如图3所示,可以得到以下结论:

图2 Ridel数据集P-R曲线对比图

图3 GIDS数据集P-R曲线对比图
1)基于神经网络的模型如PCNN、BGWA和BG-AMC都比基于特征的传统模型表现更好,原因是因为神经网络模型可以避免特征选择和NLP工具带来的错误传播问题.
2)BGWA和PCNN+ATT模型比单纯的PCNN模型取得了更好的效果,说明注意力机制能够使模型关注于更重要的信息,忽略那些无用的信息,进而有助于远程监督关系抽取任务.
3)本文提出的BG-AMC模型在Riedel数据集和GIDS数据集上,在大部分召回率相同的区域中,准确率比其他所有的模型更高,这说明结合注意力及胶囊网络的多通道方法对关系抽取的性能要优于采取普通注意力机制的方法,多通道可以使每个单词在同一个句子中分配到不同的注意力权重,因此可以减轻注意力分配权重时所存在的误差,使句子在特征层次的数据增强,有助于捕捉句子的结构和语义信息,在最终的关系分类时也会综合考虑句子多个通道的表示.BG-AMC采用胶囊网络来进行最终分类,代替了卷积神经网络中可能损失大量特征信息的max-pooling,用胶囊的长度去预测关系存在的概率,有效保留了关系分类中实体的位置信息,对远程监督关系抽取性能起到了提升效果.
5.2 通道数选择研究
在本节中,分析了在NYT数据集上BG-AMC模型在不同通道数上的表现.为此,本文模型用BG-AMC-{1,3,5,7}代表通道数分别为{1,3,5,7}的BG-AMC模型,不同通道数在GIDS数据集上的准确率-召回率曲线如表3所示,可以得到以下结论:

表3 通道数Precison-Recall值对比结果
1)BG-AMC-3模型的表现效果最好,即通道数选择为3时,实验效果达到最优,因此将BG-AMC模型的通道数默认选取为3.
2)当通道数增加到为5时,模型效果反而有所下降,这说明通道数并不是越大越好.
3)BG-AMC-1本质上是单通道模型,BG-AMC-3的表现要优于BG-AMC-1,这个结果验证了多通道可以学习到更加丰富的句子表示,降低句子的歧义性,从而验证了本文的中心论点,即多通道可以提升关系分类的效果.
6 总 结
本文提出了一种基于注意力机制及胶囊网络的多通道关系抽取模型,模型首先通过双向GRU神经网络对句子词向量进行编码以获取句子的高维语义,再利用注意力机制辅助生成句子的多通道表示,以解决以往单通道的注意力模型在注意力分配权重时出现的误差问题.多通道中每个通道在递归传播时互不影响,可以使神经网络学习到同一句子的多种表示形式,以减轻句子的歧义现象.最后,模型采用胶囊网络进行关系分类以获取句子实体的位置信息.在未来工作中,可将本论文中提出的方法应用于其他自然语言处理任务中.
