基于消息优先级队列分布式交换网元调用系统的研究
2021-02-27胡佳
胡佳
(中国联合网络通信有限公司广东省分公司,广东 广州 510320)
1 引言
随着移动互联网和手机的不断发展和普及,电信行业的数据业务量呈爆发式增长。针对如何处理如此大量的数据,在现有的解决方案中最普遍的就是搭建一个分布式的消息队列进行数据存储,数据存储在消息队列中等待被处理,这样可以实现消息的不遗漏处理。
现有的按照普通消息队列进行消费的处理方式存在明显的缺点。数据业务可细分出紧急业务,正常业务,低优先级业务等,当大量的低优先级或者普通业务堆积时,在现有的普通的消息队列中,需要按照时间顺序来一个一个处理,紧急业务不能得到优先处理,导致紧急业务被贻误,从而造成不必要的损失。
本研究的目的在于提供一种基于消息优先级队列的分布式交换网元调用系统,解决现有技术存在的无法按照优先级处理订单的问题。通过增添消息队列topic个数并且赋予每个消息队列topic优先级属性,然后按照高优先级的消息队列topic优先消费来将处理订单的顺序重新排列,达到高优先级的订单优先处理的目的,而且保证了消息队列还是分布式。同时,通过Json微服务调用工单拆分模块,将优先级高的订单分配到优先级高的消息队列中。最后高优先级的订单会优先执行工单激活模块,从而使多主机多节点同时工作,起到负载均衡和自动切换的作用,实现高可用。
2 总体技术方案
通过Json微服务调用工单拆分接口内的方法,工单拆分模块接收到Json调用后会接收到该订单要办理的业务的相关数据信息,在这个模块中有三部分要操作,即工单校验、工单拆分、工单入库。接到上游系统发来的业务Json后,对输入参数进行校验,如果缺少参数,则返回;如果参数完整正确,则继续。对工单进行拆分,遍历工单的服务编码,并结合参数编码匹配对应的子服务,如果无,则直接将服务写入服务列表;如果有,则生成新的子工单,并接入对应的平台和服务。遍历工单服务过程中,拆分新的服务编码时,如果发现已有工单存在对应的平台,则尝试合并工单服务列表;如果已有工单服务中存在串行服务,则生成新的工单。遍历完工单的服务编码后,将业务号码发送kafka中,kafka的topic为业务Json中指定的优先级topic。
工单调度模块采用多线程处理,工单获取Get线程,工单完工Finish线程,以及网元redis队列:in队列和out队列。Get线程根据号码处理相关的业务,号码来源是kafka消息,按照优先级从高到低的顺序依次消费kafka中的存放业务号码的topic,并根据号码取出数据库中关联的未处理工单。根据网元类型将工单分类打包,并放到待发送队列in队列。Finish线程获取待完工队列out中的单个工单,并根据当前工单的状态做不同的处理。工单激活模块会提取工单调度模块中保存到in队列中的工单数据进行工单翻译和工单交互。工单翻译为将工单的服务翻译为具体的指令集,工单交互为将工单的具体指令集发送到网元。
工单激活模块收到待发送工单列表集合后,会检查工单的服务名和当前激活模块服务名是否一致。对工单集合依次进行翻译,遍历工单列表和遍历工单的服务列表,完成工单服务编码对应的指令的映射、工单参数的变种和替换。遍历工单的服务列表,对工单的每个服务编码的多个指令进行交互,并根据交互的结构进行综合判断。如果交互成功,则进行下一个指令的交互;如果交互失败,则转换失败原因和进行容错判断。所有工单的所有服务编码对应的所有指令交互完成后,进行整个工单列表集合的返回。
2.1 消息优先级队列的分布式交换网元调用
联指云化系统是一种基于消息优先级队列分布式交换网元调用技术的系统(如图1所示),主要用到三份模块化的代码,即工单拆分、工单调度、工单激活这三个模块,和一个数据缓存集群、一个消息队列集群、数据持久化集群。本系统根据工具对业务的契合度和工具的优缺点,决定选用spring-cloud来模块化代码,redis工具来作为数据缓存集群,kafka作为分布式消息队列集群。通过Json微服务调用联指云化系统,数据经过该系统的处理后就会按照高优先级到低优先级的顺序发送指令去外围网元系统集合。

图1 基于消息优先级队列的分布式交换网元调用的流程示意图
2.2 消息优先级队列的分布式交换网元调用中工单拆分
运行的spring-cloud程序接收营业接口表的Json微服务调用。如图2,工单拆分模块首先会对Json数据的完整性进行校验,如参数的个数是否符合,如果参数为空,就直接返回,以及在日志中记录该条数据的报错和流水号,以便后期的报错定位。如果参数不为空则代表接收到的数据是完整的,那么程序会继续往下走。工单拆分的第二步是对接收到的工单数据进行服务编码匹配,工单数据有两种类型,一种是服务编码所代表的服务还能被细分成多个服务的,含有这种服务编码的数据会在这一步操作中被工单拆分模块拆分成多条数据。而另外一种数据则是服务编码仅仅代表一个服务,无法再细分下去了,那么这条数据就会跳过这一步服务代码拆分操作,直接进入下一步操作。在工单拆分的第三步操作中,处理完的数据分为两种类型的数据:一类是数据字段中网元字段相同的数据;另一类是网元字段不相同的数据。如果网元字段相同,那么代表这些数据将会发送去同一个目的地,同一个外围网元,所以将这类数据进行合并然后保存在数据库中;如果网元字段不相同,则代表发往不同外围网元,不进行数据合并直接保存到数据库中。在这一步进行工单合并的用意是减少同一网元的数据多次发送,降低与外围网元系统集合交互的次数,避免因为网络原因而导致的不必要损失。工单拆分的最后一步操作是按照Json中优先级字段,将数据写入到kafka的不同topic中(topic01,topic02,topic03,topic0n),优先级依次递减,到此工单拆分模块执行结束。
2.3 消息优先级队列的分布式交换网元调用中工单调度
当数据经过工单拆分模块后会保存在两个地方(如图3所示)。

图3 基于消息优先级队列的分布式交换网元调用中工单调度的流程示意图
在工单调度模块有2个线程,分别为Get线程与Fin线程,而保存在kafka中的数据就会触发工单调度的Get线程。Get线程的第一步操作是按照优先级进行kafka消费,采用算法读取(topic01,topic02,topic03,topic0n),以此类推,Get线程没有消费到数据时会一直消费kafka,当消费到了数据时就会进行下一步操作,检查该条数据是否有其他进程在处理,如果有的话就跳过这条数据,处理下一条数据,如果没有线程在处理这条数据的话就会根据这条数据中的号码字段来捞取数据库中未处理的工单,当在数据库中捞取不到该号码的相关工单就跳过这条数据,处理下一条数据,如果在数据库中捞取到该号码的相关工单就会进行下一步的判断,检查号码是否有未完成的关键工单,如果有就跳过,处理下一条数据,如果没有就代表这条工单已经全部完成,则更新工单在redis和数据库中的状态,并按网元分类打包,放到待发送队列redis–in列表。
工单调度中的Fin线程会一直去获取redis-out列表中的工单,第一步操作会判断这条数据是否为关键工单,当不是关键工单的时候会跳过,继续获取下一条数据,当获取到关键工单数据的时候会进行第二步操作,判断工单状态(错误,成功,超时等)。如果这条数据工单状态为错误,就回单,也就是更新数据库中的状态为错误;如果这条数据工单状态为正确,会进行下一步判断,是否为其他工单的前置工单,是的话就更新后置工单到redis-in列表中然后回到Fin线程最开始,不是话就检查所有工单状态,符合回单就更新表状态,不符合就删除该号码关联定单中当前定单;如果这条数据的工单状态为超时则直接删除该号码关联定单中当前定单,经过第二步数据状态判断的操作后就会进行第三步操作,检查该号码关联的订单状态,如果还有没完成的关键订单就继续等待,如果关键订单均完成后就会检查是否有同一个号码的其他订单,有的话就进入号码二次处理队列,没有的话就删除同号标志。
2.4 消息优先级队列的分布式交换网元调用中工单激活
如图4所示,在工单拆分模块中处理完的数据,也就是图中接收到的Json请求并且通过了服务名校验的数据,这些数据存到了redis-in 列表中,工单激活模块会一直去redis-in 列表中获取数据,当获取到一条数据的时候就会进行第一步操作——工单翻译,首先会处理数据中的特殊服务,如果在工单服务列表中匹配不到的话就跳过,如果匹配到了就判断特殊服务类型并处理服务列表;其次是处理扩展参数,如果遍历工单参数列表后发现变种参数的话就直接生成变种参数然后加入扩展参数列表,如果没发现变种参数就直接加入扩展参数列表;再次就是获取服务编码的配置,替换服务对象;最后是指令代码参数替换,扩展参数替换指令模板。工单翻译运行到这里就完成了,每条工单被翻译成能够被网元理解的指令。
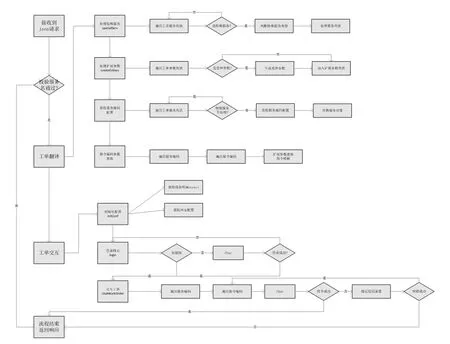
图4 基于消息优先级队列的分布式交换网元调用中工单激活的流程示意图
当工单翻译完了之后就会和对应的网元进行工单交互,首先会去初始化登录的配置,获取线程所属socket和网元的配置,然后就能够登录到对应的网元,并根据交互的结构进行综合判断,如果交互成功,则进行下一个指令的交互。如果交互失败,则转换失败原因和进行容错判断。所有工单的所有服务编码对应的所有指令交互完成后,进行整个工单列表集合的返回。
2.5 运行效果
高峰期工单处理能力比未改造消息优先级队列时:原来100万/天,提升到>1000万/天(10倍);高峰期工单处理时长:原来14 秒,缩短到<2 秒(7 倍);高峰期联指处理能力:原来100 万/天,提升到>1000 万/天(10 倍);高峰期指令处理时长(含网元时间):原来17 秒,缩短到<3 秒(6 倍);工单并发处理数:原来10TPS,提升到>200TPS(20倍)。
3 结语
本系统通过Json微服务调用工单拆分模块,将优先级高的订单分配到优先级高的消息队列中,然后工单调度系统按照高优先级队列优先处理原则进行工单的调度,最后高优先级的订单会优先执行工单激活模块,这样既保证了消息的队列分布式处理,又能将订单进行排序,以提高系统效率,强化系统能力,扩大系统使用范围,同时具备云平台的高效率、高可用、高扩展特点,简化运维操作,释放人力资源。高效率即是模块微服务化,轻Json 格式调用,去除耗时的数据库扫表操作,使用中间件缓存。高可用即是系统分布式部署,多主机多节点同时工作,起到负载均衡和自动切换的作用,实现高可用。
