基于MapReduce 的朴素贝叶斯算法文本分类方法
2021-02-27张晨跃刘黎志邓开巍
张晨跃,刘黎志,邓开巍,刘 杰
智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉 430205
近年来,随着网络的迅速发展和大数据时代的到来[1-3],文本数目也不断增多。面对巨大的数据量,需要使用恰当的方法对文本进行分类。朴素贝叶斯算法以其可靠的数学基础成为最主要的分类算法之一。由于其依据各个条件相互独立,而各特征词之间往往具有一定联系,所以特征项加权[4-5]已成为重要的研究内容。词频-逆文本频率指数(term frequency-inverse document frequency,TF-IDF)[6-7]是文本分类中常用的特征权重算法,突出特征词在类内和类间的分布也有助于提升算法性能。本文选取多项式朴素贝叶斯算法(naive bayes,NB),在Hadoop[8]集群上并行处理文本数据,实现对文本的分类,通过实验验证了在该集群上设计的并行化朴素贝叶斯分类方法能够展现出良好的性能。
1 相关研究
1.1 朴素贝叶斯分类算法
朴素贝叶斯算法[9-10]假设各特征之间是相互独立的,是一种有效的分类方法。常用的模型为多项式模型和伯努利模型,本文采用多项式模型,假如待分类的文本特征项为X( x1,x2,…,xn),类别集合为C( c1,c2,…,cm)。该算法以词条在ca类与cb类之间相互独立为前提,计算出词条属于每类文档的概率P( cm|X ),以概率最大所在类别作为预测文档所属的类别cm。多项式朴素贝叶斯计算公式如下所示:
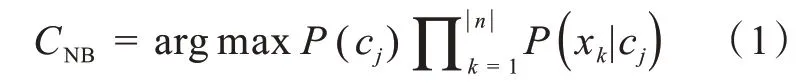
其中,P(cj)为新文本属于cj类的概率;P( xk|cj)为cj类中包含词条xk的概率。

其中,Sj为类cj下的词语数目,S 为所有类下的词语数目。
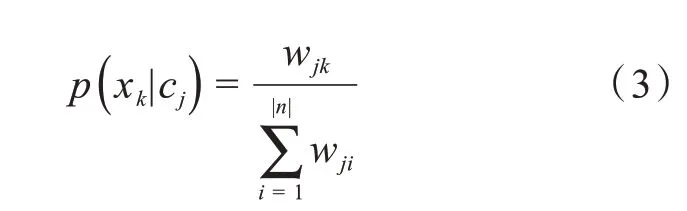
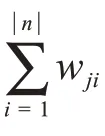
为了防止特征词xk在类别cj中可能出现零次,导致零概率问题,一般采取以下解决方式:
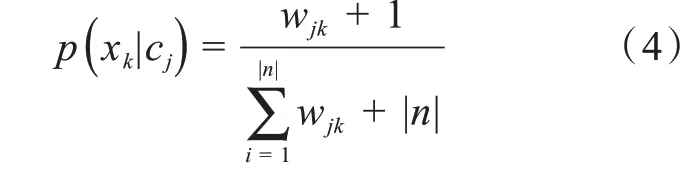
1.2 卡方特征选择
由于在预处理阶段所筛选的词语维度较高,需要专门进行特征选择,得出区分度高而维度较小的特征词[11]集合。本文用χ2统计[12]的方法进行特征选择。该方法假设两个样本之间互不关联,卡方值大小决定了两者偏离程度的大小。卡方值越大,代表特征越明显。该方法计算公式如下:
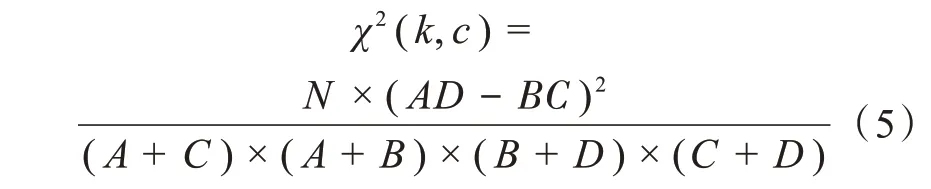
其中,N 为文档数量,k 代表特征项,c 代表类别。B为非类别c 中包含特征项k 的文本总数,C 为c 类中不包含特征项k 的文本总数,A 为c 类中包含特征项k 的文本总数,D 为非类别c 中不包含特征项k的文本总数。
1.3 TF-IDF 权重
TF-IDF[13-14]表示词频-逆文档频率,TF 表示词频,IDF 表示逆文档频率。在一篇文章中,假如一个词语的TF 高,它在别的文档中又很少出现,那么该词语能较好地代表这一类文章。其表达式为:

其中,Wdt代表特征项t 在文档d 中所占权重,fdt代表特征项t 在文档d 中的词频,N 代表所有文档数目,nt代表有多少文档含有特征项t。但在实际计算的过程中,假如特征项出现的文档数为0,分母为0,因此,可以把分母加1,即

1.4 MapReduce 编程框架
MapReduce[15]的核心思想是由许多分节点去处理大规模数据,这些分节点由一个主节点统一来管理。将各分节点的处理结果进行整理,就可以得到最终的结果。Map 和Reduce 是该框架的两个主要部分。其在< key,value >形式的键值对上工作。由于NB 算法假设各特征项之间是相互独立的,因此该算法是可以通过并行实现的。
2 朴素贝叶斯算法并行化
将NB 的并行化过程分为:特征选择、权重计算、模型训练和测试4 个阶段。首先用中文分词工具jieba 对文本内容进行分词预处理,并通过本文构建的中文停用词表去掉无意义词语,计算同一类别的词频之和,并过滤掉词频过高或过低的词,最终得到totalnews 和wordcount两个文件。
2.1 特征选择
特征选择Job 的工作流程:
1)输入totalnews 和wordcount 文件,读取分布式文件系统中的内容;
2)Map 阶段,顺序读取两个文件,数据分别写入words_list 和news_list 元组。定义flag,通过for循环判断每个词在每类文本中是否出现,出现flag为1,否则为0,求出N 和每个特征项xk的A,B,C,D,利用公式(5)计算chi,再通过sqrt 对其进行开方,按照
3)所有分片输出的键值对会在Shuffle 过程按照s_CHI 大小降序排序、归并处理,Reduce 阶段接收排序和归并结果继续处理。整理结果会按照“
4)Reduce 阶段,获得上一步输出内容,每类选取top 前V 作为该类最终特征词,过滤掉重复的xk,得到最终的全局特征项X(x1,x2,…,xn),以
2.2 权重计算
权重计算Job 的工作流程:
1)输入totalnews 和CHI 文件,读取分布式文件系统中的内容;
2)Map 阶段,顺序读取两个文件,数据分别写入words_list 和news_list 元组。利用公式(7)首先计 算 出xk的TF 和IDF 值,按 照< wordID_xk,newCategory_TF_IDF> 键值对的形式溢出到HDFS 本地磁盘中保存为一个文件;
3)Shuffle 过程根据相同的key 值进行归并,Reduce 阶段接收归并结果继续处理。整理结果会按照“< wordID_xk,newCategory_TF_IDF>”的键值对形式进行输出;
4)Reduce 阶段,获得上一步输出内容,计算每个xk在每条文本中的权重值,以
2.3 训练分类模型
训练分类模型Job 的工作流程:
1)输入TF-IDF 文件,读取分布式文件系统中的内容;
2)Map 阶段,读取文件,计算xk在每个类别的TF-IDF 值,按照
3)所有分片输出的键值对会在Shuffle 过程按照wordID_xk归并处理,Reduce 阶段接收归并结果继续处理。整理结果会按照“
4)Reduce 阶段,获得上一步输出内容,直接以
2.4 测试分类模型
测试分类模型Job 的工作流程:
1)输入测试数据totalTestNews 文件和权重值weight文件,读取分布式文件系统中的内容;
2)Map 阶段,按顺序读取两个文件,根据公式(1)预测新文本概率。按照
3)所有分片输出的键值对会在Shuffle 过程按照newID 归并处理,Reduce 阶段接收归并结果继续处理。整理结果会按照“
4)Reduce 阶段,获得上一步输出内容,输出最大值对应的类别。
3 实验部分
3.1 环境配置
用联想z40-70 笔记本一台,该笔记本包含一台英特尔i5-4210U 物理CPU,该CPU 有2 个内核,主频1.70 GHz,内存8 GB,硬盘1 TB,物理网卡1个。笔记本安装win10 专业版操作系统,使用Vmware Workstation Pro14 软件创建4 个虚拟机,每个虚拟机包含一个内核CPU,内存1 GB,硬盘20 GB 和虚拟网卡1 个。搭建Hadoop 分布式集群,使用Anaconda3、Python3.7 和PyCharm 作为开发环境。同时,本文通过编写爬虫程序,从新浪新闻网站爬取了4 类新闻数据作为实验语料,分别为娱乐、军事、体育和科技4 个类别,格式为新闻类别、标题、URL 和内容。每类新闻数目为4 500 条,共包含1.8 万条新闻,其中训练数据与测试数据比值为2∶1,即包含1.2万条训练数据和6 000条测试数据。
3.2 实验结果及分析
第1 组实验是不同节点运行时间对比实验。选择4 个节点对本文数据集进行训练,记录并行化处理的总时间。当节点数为1时,运行时间为658 s;节点数为2 时,运行时间为534 s;节点数为3 时,运行时间为397 s;节点数为4 时,运行时间为274 s。节点数目越多,处理时间越少,因此该方法一定程度上可以提高算法的时间效率。
第2 组实验是传统朴素贝叶斯分类算法与本文并行化算法的分类时间对比。如图1(a)所示。图1(a)表明:在初期训练集较少时,并行算法读取数据需要消耗一定时间,串行朴素贝叶斯算法分类的效率优于并行的朴素贝叶斯算法。随着训练数据集的扩大,集群运行优势逐步体现,且数据规模越大优势越明显。
第3 组实验是对本文算法分类效果的评估。在单机和集群环境下,分别选取精确率U、召回率R 和它们的调和平均值F1进行比较。

分类器在类cj上的精确率定义如下:其中,Ncuj代表正确分到cj类中的文档数目,Nuj代表分到cj类中的全部文档数目。
分类器在类cj上的召回率定义如下:

其中,Ncj表示实际类别cj中应有的文本数。
分类器在类cj上的F1值定义如下:
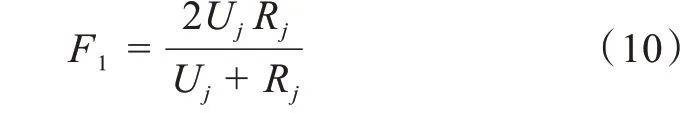
将娱乐,军事,体育,科技类分别记为类别1,2,3,4。传统的朴素贝叶斯和本文并行化的朴素贝叶斯分类精确率、召回率和F1值对比分别如图1(b),图1(c),图1(d)所示。

图1 传统和并行朴素贝叶斯的比较:(a)运行时间,(b)精确率,(c)召回率,(d)F1值Fig.1 Comparison of traditional method and parallelized naive bayes method:(a)runtime,(b)precision,(c)recall,(d)F1 values
由于进行了专门的特征词选取工作,由图1(b)可知,4 类新闻的分类精确率都有所提高,军事类精确率提高了7.66%。由图1(c)可知,分类召回率不但有所提高,类间的差距也在不断缩小,逐渐趋于平稳。其中,体育类召回率提高了7.56%。由图1(d)可知,并行化的朴素贝叶斯算法整体上提高了F1值,体育类的F1值提高了11.98%。由此可知,该方法较对照组传统朴素贝叶斯方法精确率,召回率,F1值分别至少提高了7.66%、7.56% 和11.98%。从总体上看分类效果较好。
4 结 论
本文利用NB 算法,通过Hadoop 平台实现了文本分类的并行化。在特征选择,权重计算等阶段分别使用MapReduce 框架来计算。实验证明,与串行NB 算法相比,在同样的数据规模下,本文分类算法在精确率、召回率和F1值上均有所提高,具有更好的分类效果。同时,节点数目越多,算法运行时间越少,运算效率显著提升。因此,Hadoop平台对大规模的文本处理具有较大的优势。但由于实验中语料库的规模较小,在今后的研究中,将尝试与其它大数据平台、优化算法相结合,扩大数据规模,并适当增加集群的节点数,不但要提升时间效率,还要从根本上提升算法分类的准确率。
