近红外光谱结合极限学习机的榛子蛋白质含量检测
2021-02-26张冬妍周宝龙张瑞韩睿赵思琦
张冬妍,周宝龙,张瑞,韩睿,赵思琦
(东北林业大学,黑龙江 哈尔滨 150040)
榛子作为四大坚果之一,具有很高的营养价值,目前我国榛子品种主要为平榛和毛榛两大类,平榛与毛榛广泛分布于我国北方各省,榛子果壳呈深褐色,表面光滑,形状为圆球形,平榛直径平均为1.44 cm,出仁率约33.3%。榛仁颗粒充实,富含蛋白质、脂肪酸、微量元素等营养物质。但对其蛋白质的检测仍以传统化学检测方法为主,而且化学检测成本高、破坏样本并且分析重现性差,难以满足目前无损检测的需求。近红外光谱检测技术作为一种新兴的无损检测方法已成功地应用于水果、肉类等食品检测,具有快速、便捷、无污染、不破坏样本等特点[1-4]。因此本文以近红外光谱检测技术为基础,结合极限学习机建立预测模型,对榛子的蛋白质含量进行分析。为榛子内部品质无损检测提供新的方法和途径。
1 材料与方法
1.1 材料
本次试验选择产自黑龙江省伊春市的平榛与产自小兴安岭的毛榛为试验样本。所用光谱仪为德国INSION公司生产的NIR-NT-spectrometer-OEM-system光谱仪,波长范围为900 nm~1 700 nm。光谱采集软件为海洋光学公司开发的spectrasuite软件。
由于榛子蛋白质与脂肪的化学检测要求每组样本至少20 g,所以挑选出约2 000个平榛与3 000个毛榛进行去壳取仁,用电子秤进行称重,每20 g榛子仁分为一组,共制备90组毛榛榛子仁样本和60组平榛榛子仁样本进行试验。
1.2 光谱采集
在对数据进行采集前,先对软件进行初始化操作,并进行暗、亮光谱校准,首先设置软件初始积分时间为20 ms,平均次数为5次,将未开启光源的探头对准校准白板测量暗光谱。开启光源,预热20 min左右,将探头对准校准白板,测量亮光谱。然后将仪器探头置于黑盒子中固定好位置,并将待测榛子仁置于探头直射光线下,对吸光度数据进行采集。采集得到的榛子样品光谱数据存储在剪切板中,再将数据直接粘贴到Excel表格中,将20 g榛子分为一组样本,以每组样本中所有榛子的平均光谱作为该组榛子样本的光谱数据,最终在Matlab中绘制两种榛子样本的光谱图。
1.3 蛋白质含量真实值测定
通过凯氏定氮法测得榛子仁中的含氮量进而得到其蛋白质的含量,使用该方法进行榛子蛋白质真实值测定,得出真实值用于与后续建模预测值进行比较分析[5-6]。
1.4 光谱预处理及特征选择
为了简化光谱数据,通过一阶导数、二阶导数、多元散射校正和标准正态变量变换预处理方法对榛子光谱进行预处理,比较不同预处理方法的效果,选择适合榛子光谱的预处理方式。通过反向间隔偏最小二乘法筛选出适用于蛋白质预测的特征波段[7-10]。
1.5 极限学习机建模
极限学习机(extreme learning machine,ELM)在结构上与BP神经网络完全一样属于前向型神经网络,而在算法上提出了新的思想。它的经典结构为单隐含层,包含一个输入层和一个输出层。极限学习机的第一层与第二层的连接权值和隐含层的阈值是随机确定的且一旦设定就不需要调整,它与BP神经网络相比减少了一半的学习过程,极限学习机的第二层与第三层间的连接权值同样不需要迭代训练,而是通过解方程组的方式一次性解出,因此相对于BP神经网络,极限学习机的学习速度明显更快[8-16]。极限学习机网络结构如图1所示。
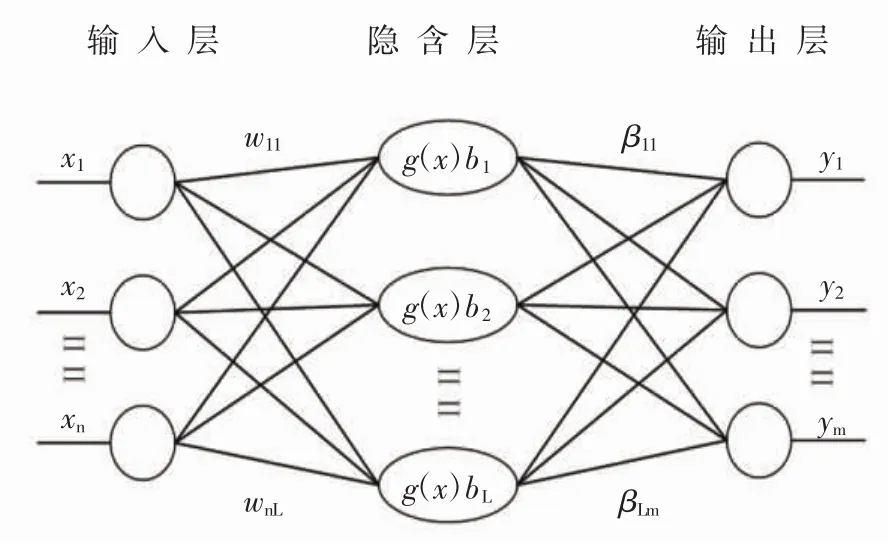
图1 极限学习机网络示意图Fig.1 Schematic diagram of extreme learning machine
2 结果与讨论
2.1 光谱预处理结果
将两种榛子经过一阶(1-der)导数、二阶(2-der)导数、多元散射校正(multiplicative scatter correction,MSC)以及标准变量变换(standard normal variate,SNV)4种不同方法预处理后的光谱数据与原始光谱作为输入,通过偏最小二乘法建立榛仁蛋白质含量预测模型。比较不同预处理对模型精度产生的影响,本文选择常用的模型精度评价指标相关系数R、交叉验证均方根误差(root mean square error of cross validation,RMSECV)以及预测均方根误差(root mean square error of prediction,RMSEP)来刻画,得到的榛仁蛋白质模型评价结果如表1所示。毛榛与平榛光谱SNV预处理图见图2。

表1 不同预处理方法建模精度Table 1 Modeling accuracy of different preprocessing methods
经过SNV预处理的毛榛蛋白质预测模型,R为0.862 1,平榛的蛋白质预测模型,R为0.860 5,均高于其它预处理结果,从图2也可得出经SNV处理的榛仁光谱图波峰更加明显。因此选择SNV作为后续建模的光谱预处理方法。
2.2 特征选择结果
试验原始光谱波长范围为900 nm~1 700 nm,输入变量个数为500,将光谱区间分为20个,每个区间包含25个输入波长,用经过SNV预处理后的光谱建立榛子蛋白质PLS模型,精度RMSECV如表2、表3所示。
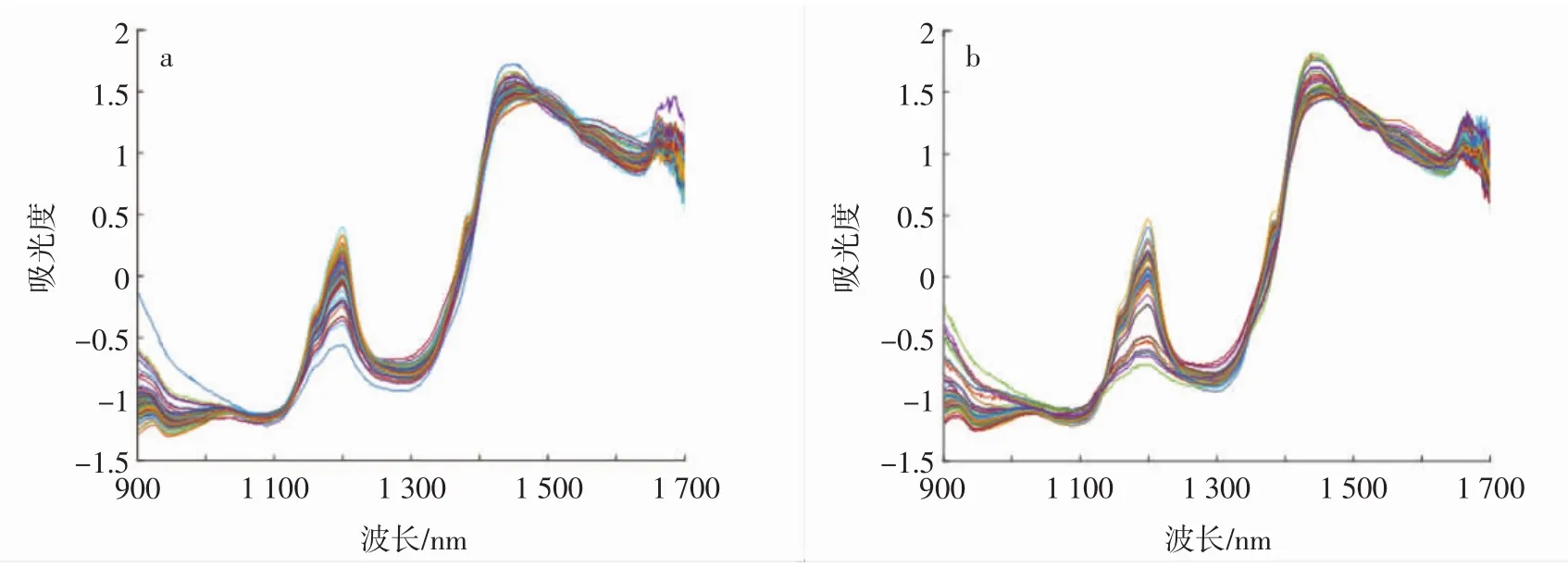
图2 毛榛与平榛光谱SNV预处理Fig.2 Spectrum and flat hazel SNV pretreatment
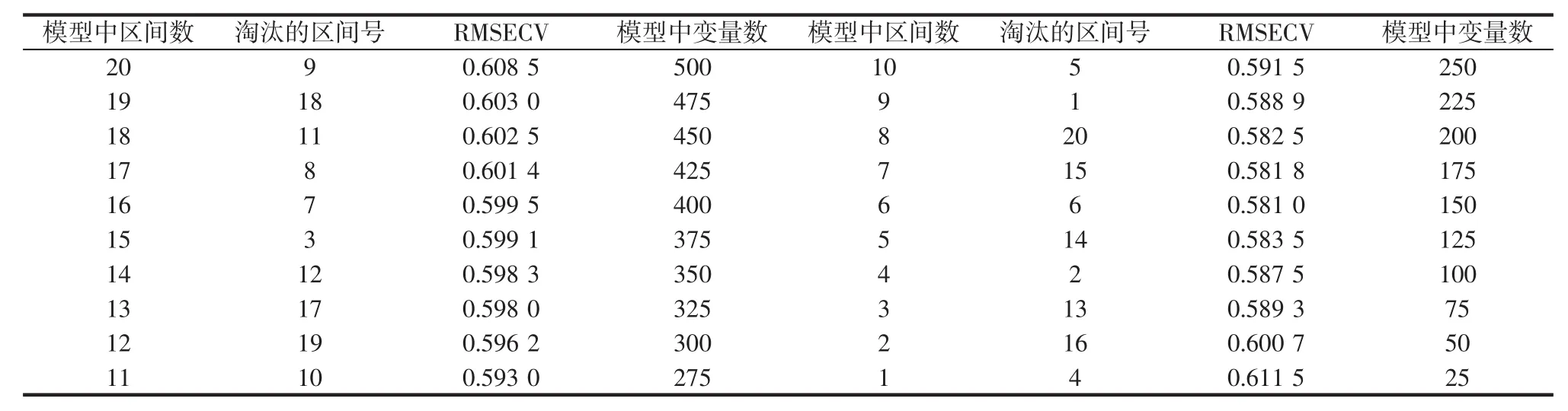
表2 毛榛蛋白质模型BiPLS特征选择过程Table 2 BiPLS feature selection process of hair hazel protein model
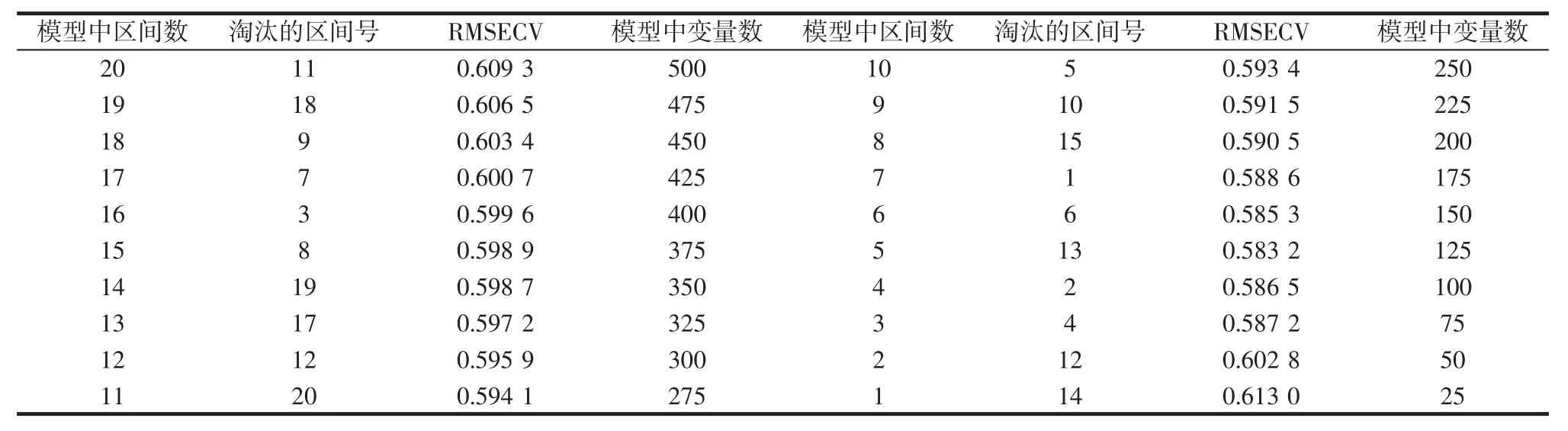
表3 平榛蛋白质模型BiPLS特征选择过程Table 3 BiPLS feature selection process of flat hazel protein model
由表2、表3可得,毛榛光谱当淘汰掉6号光谱区间时,偏最小二乘模型的RMSECV为最小值0.581 0,这时蛋白质预测模型淘汰的区间数为15,剩余的5个区间为最终特征选择的结果:2、4、13、14、16,模型中变量数为125,平榛光谱淘汰掉13号光谱区间时,偏最小二乘模型的RMSECV取最小值0.583 2,剩余4个最终特征选择结果:2、4、12、14。结果表明两种榛子具有相似的特征区间,波段选择如图3所示。
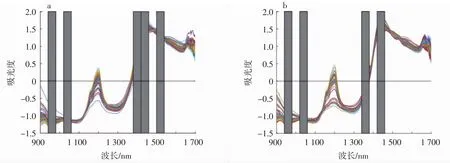
图3 毛榛与平榛蛋白质模型波段选择Fig.3 Selection of protein bands for hair hazel and flat hazel protein
图3中阴影部分表示选出的特征波段,用BiPLS选出的特征变量建立毛榛与平榛蛋白质预测模型,模型精度相对较高。可以得出两种榛子的预测集的相关系数R与预测均方根误差RMSEP分别为0.880 6和0.599 3,0.882 3 和 0.598 4。
2.3 极限学习机建模预测
以matlab为建模平台,激活函数选择s函数,当隐含层神经元个数等于训练样本数时可以达到零误差,因此设定神经元个数为15,并以5为间隔增加到60。将60组毛榛与40组平榛校正集样本光谱经过BiPLS选择的125与100个特征波长作为输入,校正集榛子样本蛋白质含量作为输出。建立预测模型。得出隐含层神经元个数从15变化到60的过程中,两种榛子训练集的均方根误差都不断减小,而预测集的均方根误差先减小再大幅度增大,当隐含层神经元个数为45时毛榛达到最小值0.40,平榛同样达到最小值0.39,故取隐含层神经元个数为45建立两种榛子蛋白质预测模型。取毛榛样本30组和平榛20组测试集的预测结果如图4和图5所示。
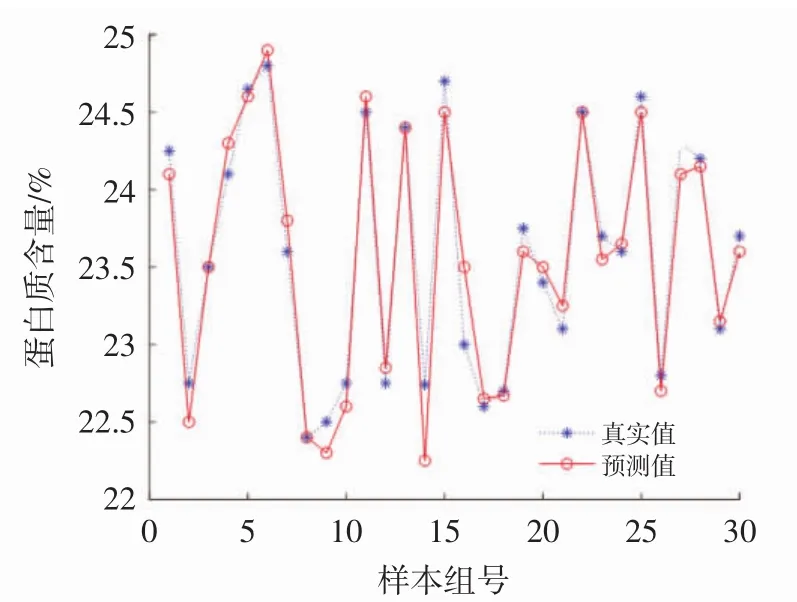
图4 极限学习机预测毛榛蛋白质含量结果Fig.4 Results of extreme learning machine predicting protein content of hair hazel
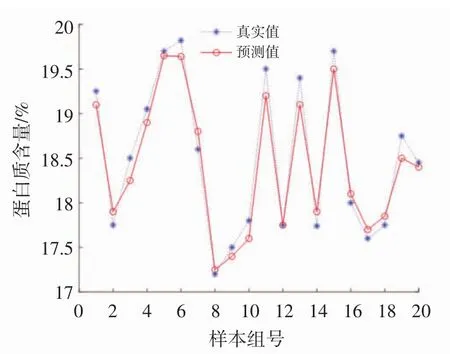
图5 极限学习机预测平榛蛋白质含量结果Fig.5 Results of extreme learning machine prediction of flat hazel protein content
从蛋白质含量预测结果图分析可得出毛榛与平榛预测均方根误差RMSEP分别为0.397与0.377,相关系数R分别为0.953与0.950,由此可知模型精确度很高。
3 结论
本文基于近红外光谱检测技术,结合极限学习机建模方法进行了榛子蛋白质的无损检测,利用一阶求导、二阶求导、SNV和MSC处理毛榛与平榛的原始光谱,求导处理在消除基线漂移的同时也会增加噪声,MSC处理后能够凸显出光谱变化规律,SNV相比于MSC对每条光谱逐一进行处理且不会产生噪声,对毛榛与平榛原始光谱进行SNV处理效果皆为最好。用BiPLS法分别对平榛与毛榛的蛋白质建模进行特征提取,将原始光谱划分为20个区间,最后筛选出适合毛榛蛋白质建模的5个区间,适合平榛蛋白质建模的4个区间,减少了建模输入量同时提高了模型的精度。应用极限学习机建立预测模型相关系数大于0.95。应用此种方法为榛子蛋白质含量的预测提供了新的有效的途径。
