基于多节点组合特征和模糊聚类的中文词义消歧方法
2021-02-25杜建强熊旺平雷银香罗计根曾青霞
贺 佳 杜建强 聂 斌 熊旺平 雷银香 罗计根 曾青霞
1(江西中医药大学计算机学院 江西 南昌 330004)2(江西中医药大学岐黄国医书院 江西 南昌 330004)
0 引 言
一词多义或多词同义是自然语言中普遍存在的现象。词义消歧的目的是使系统根据某个歧义词所处的上下文语境识别出该歧义词的正确义项[1]。词义消歧不仅在机器翻译中有重要应用,也在信息检索、语义分析和话题关联检测[2]中有重要意义。词义消歧方法一般包括基于知识库的方法和基于统计机器学习的方法[3]。
基于知识库的方法通常借助WordNet[4]、Hownet[5]、《同义词词林》、机读词典等辅助目标歧义词的消歧特征。张春祥等[6]借助《同义词词林》,将窗口大小内的左右词单元对应的语义代码作为消歧特征,采用贝叶斯模型完成词义消歧。此方法虽能提升消歧效果,但知识资源包含的知识比较受限,仅能完成知识资源中出现歧义词的消歧任务。
基于统计机器学习的方法一般包括抽取特征和建立消歧模型两个流程[7]。通常采用有监督或无监督的方法建立消歧模型。张春祥等[8]将歧义词左右邻接词单元的多种语言学知识作为消歧特征,并使用Co-Training算法优化贝叶斯和最大熵模型,实现词义消歧。有监督的消歧模型在词义消歧性能上表现突出,但由于缺乏大规模标注语料,此类方法受到了很大限制[9]。无监督的消歧模型不需要大规模标注语料,具有较强的可移植性[10]。
为提高消歧质量,许多学者开始用更多更全面的语言学知识进行特征抽取。史兆鹏等[11]通过依存句法分析提取依存词、依存结构和歧义词的词性等作为消歧特征,细化特征粒度进行消歧。张春祥等[12]通过句法知识建立对应的句法树,抽取目标歧义词的父节点、左右兄弟节点的句法知识以及词性知识作为消歧特征,该方法不考虑词形信息。Han等[13]利用依存句法树中路径信息,抽取距离目标歧义词一定路径长度的词作为消歧特征。这种方法虽提高了消歧效果,但路径之外距离目标歧义词较近的单元词没有被考虑。王少楠等[14]抽取专有名词、量词等具有词性标签的词,以及与歧义词具有并列关系的词、紧邻歧义词的动词、非歧义单词的语义类别等作为LDA主题模型的输入,实现词义消歧。可以看出,非常丰富的语言学知识能够提取出更多更有效的消歧特征,对提高消歧质量有很大帮助,但一定程度上会增加特征维度,提高计算复杂度。
基于上述问题和已有方法的不足,本文依据依存语法理论,建立依存结构树,选择目标歧义词的祖父+父亲+孩子节点组合作为消歧特征,采用TF-IDF计算特征权重,形成特征向量矩阵,利用模糊C均值(fuzzy C-means,FCM)聚类算法的软划分优势[15],将特征向量矩阵作为FCM聚类算法的输入,实现词义消歧。通过分析与目标歧义词相关程度较大的所有节点的不同组合方式,验证了祖父+父亲+孩子节点组合的有效性。与现有的词义消歧工作相比,本文方法主要有三种优势:(1) 特征抽取时不需要借助知识库;(2) 充分利用了依存语法理论,采用三个节点组合作为消歧特征,特征维度相对较少;(3) 采用无监督的、基于软划分的FCM聚类算法,可将样本划分到多个类别,更加符合客观世界的数据分析。
1 基于多节点组合特征的消歧方法
基于多节点组合特征的词义消歧方法可分为两个部分,如图1所示。第一部分为特征抽取:采用依存句法分析得到每个预处理语料的依存结构树,在依存结构树中选取多个节点进行组合形成消歧特征;第二部分为消歧模型的建立:采用经典的TF-IDF计算特征权重,将文字形式的消歧特征转为数值化的特征权重向量,采用FCM聚类算法计算目标歧义词的义项类别。

图1 多节点组合特征的消歧方法流程
1.1 基于多节点组合的特征抽取方法
依存语法通过分析单元词间的依存关系揭示句子中的句法结构。直观而言,句子的“主谓宾、定状补”等语法成分由依存句法分析识别并对各成分间的关系进行分析[16]。依存结构树基于依存句法分析,形象化地展示了词之间的关系。
本文采用哈工大信息检索研究中心语言技术平台中的依存句法分析工具[17]。为了使本文思路简洁清晰,提出定义如下:
定义1依存结构树中节点命名:根据树的特点,将每个节点以目标歧义词为核心,命名为目标歧义词的祖父节点、父节点、孩子节点、兄弟节点和孙子节点等。
定义2家族结构树:指在依存结构树中,只包含目标歧义词的祖父节点、父节点、孩子节点、兄弟节点、孙子节点的树。
以包含目标歧义词“提高”的句子为例,具体特征抽取过程如下:
1) 例句:“这/r/Ed61 几/m/Dn05 年/q/Ca18,/wp/-1 随着/p/Kb07 我国/n/Di02 农村/n/Cb25 居民/n/Ad01 生活/n/Hj01 水平/n/Dd12 不断/d/Ka11 提高/v/Ie12,/wp/-1 消费/n/He03 需求/n/Df07 的/u/Kd01 结构/n/Dd06 变化/n/Ih01 明显/a/Ed46 。/wp/-1”该例句来自哈工大信息检索研究中心语言技术平台中的词义标注语料[17]。每个词后面分别用斜线隔开了两个标记,第一个是词性标记,第二个是词义标记。
2) 采用正则表达式去除句中的语义代码、斜线等,转成依存句法分析需要的格式。
3) 对句子进行依存句法分析,建立依存结构树,如图2所示。

图2 例句的依存结构树
4) 从依存结构树中抽取消歧特征。依存结构树很清晰地展示了句子中词语间的关系,也非常直观地展示了每个单元词与目标歧义词关系远近的程度。一般认为与目标歧义词关系较近的单元词对歧义词的词义有较大影响。从依存结构树中抽取目标歧义词的特征,能够避免抽取特征的任意性。以左右窗口大小为2抽取特征(不包含标点符号),则歧义词“提高”的消歧特征为“水平”“不断”“消费”和“需求”,对照依存结构树,明显可见“需求”属于歧义词“提高”的兄弟节点,“消费”为“需求”的孩子节点。兄弟节点以及兄弟的孩子节点距离歧义词“提高”的关系都比较远,对歧义词的词义支持度相对较低。
本文充分考虑依存结构树中词语间关系以及关系远近问题,衡量家族结构树中所有节点的不同组合作为消歧特征对歧义词词义的影响,从依存结构树中抽取目标歧义词“提高”的祖父、父亲、孩子节点组合,将其作为消歧特征。则目标歧义词的消歧特征为“变化”“随着”“水平”和“不断”。
1.2 建立消歧模型
TF-IDF、词嵌入可以完成消歧特征向量化。TF-IDF是比较经典的计算特征权值的方法。核心思想:若某个词或短语在一篇文档中出现频率较高,且在其他文档中很少出现,则认为这个词或短语具有很好的类别区分能力[18]。词嵌入可以将词语映射成低维稠密的向量,在大量自然语言处理中,具有较好的效果[19]。但词嵌入技术需要海量语料库进行预训练才能较准确地识别词之间相似度。FCM聚类算法属于一种软划分的聚类算法,它是对硬聚类算法的改进。硬聚类算法对每个样本只能划分到一个类别中,而FCM聚类算法可以将每个样本按照一定的隶属度从属于多个类别[20],相对于硬聚类算法,FCM聚类算法更符合实际的无监督聚类应用。FCM聚类算法思想:使得被划分到同一个簇中的样本之间相似度最大,不同簇之间的相似度最小。
由于本文采用的语料库规模相对较小,且通过1.1节选取的消歧特征,维数较少。因此选用TF-IDF将1.1节的消歧特征转为特征向量矩阵,并作为FCM聚类算法的输入,实现词义消歧。其消歧模型建立流程如下:
1) TF-IDF形成特征向量矩阵。消歧特征i在样本j中的TF-IDF值wi,j为:
(1)
式中:TF表示词频,指消歧特征i在样本j中出现的频率;IDF为逆文档频率,是对某个特征普遍重要性的度量;|D|为样本总数;|Di|为包含特征i的样本数。
2) FCM聚类算法实现。将TF-IDF得到的特征向量矩阵X=[x1,x2,…,xN]T(xj代表第j个样本的特征向量,j=1,2,…,N;矩阵中的每一个值为TF-IDF值wi,j)作为FCM聚类算法的输入,通过调整最大迭代次数[21]等相关参数,在满足式(2)的条件下,求式(3)取最小值时的聚类结果:
(2)
(3)
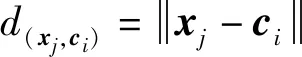
求解最小化目标函数时,可得出聚类中心和隶属度:
(4)
(5)
FCM聚类算法实现词义消歧的步骤如下:
输入:模糊参数m,聚类数目k,最大迭代次数MAX_ITER,特征向量矩阵X=[x1,x2,…,xN]T
输出:聚类结果
(1) 满足式(2)的条件下,采用[0,1]区间的随机数值初始化隶属度矩阵U。
(2) 用式(4)计算聚类中心ci,i=1,2,…,k。
(3) 通过式(5)更新隶属度矩阵。
(4) 重复步骤(2)和步骤(3)。当达到最大迭代次数时,循环停止,返回聚类结果;否则,返回步骤(2)。
2 实 验
2.1 实验数据与评价指标
本文选用哈工大信息检索研究中心语言技术平台中的词义标注语料[17],该语料来源于《人民日报》1998年上半年的电子版。从该语料中选取“材料”“代表”“地方”“队伍”“发表”“根本”“领导”“提高”“突出”“中心”“组织”和“左右”共12个歧义词进行实验,包含381个实例。选取的歧义词体现三个特点:(1) 歧义词义项与词性无直接关系,即一个义项可能对应多个不同词性,多个义项可能对应相同词性;(2) 歧义词义项数分布随机,为2~5个不等;(3) 每个歧义词义项对应的实例数随机分布,未刻意保持平衡。部分语料展示如表1所示。每个歧义词的义项由《同义词词林》的语义类别表示。
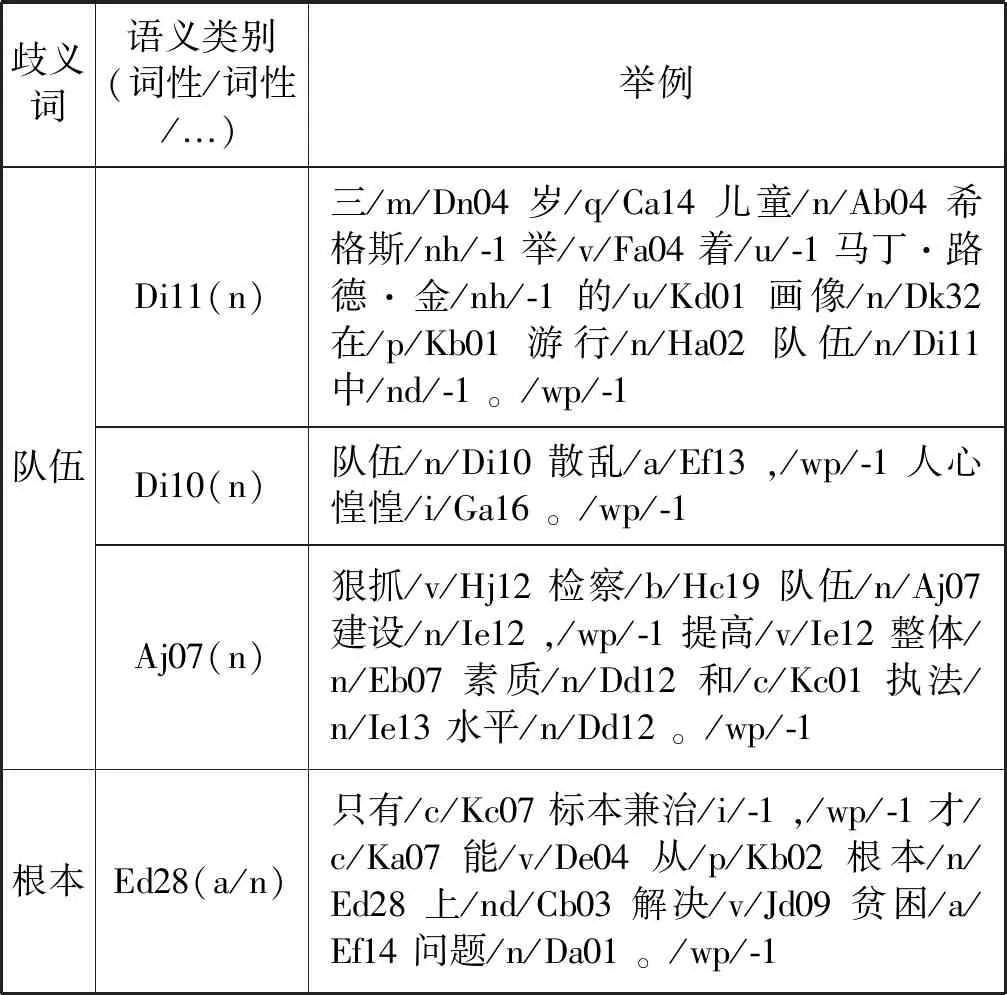
表1 部分语料展示
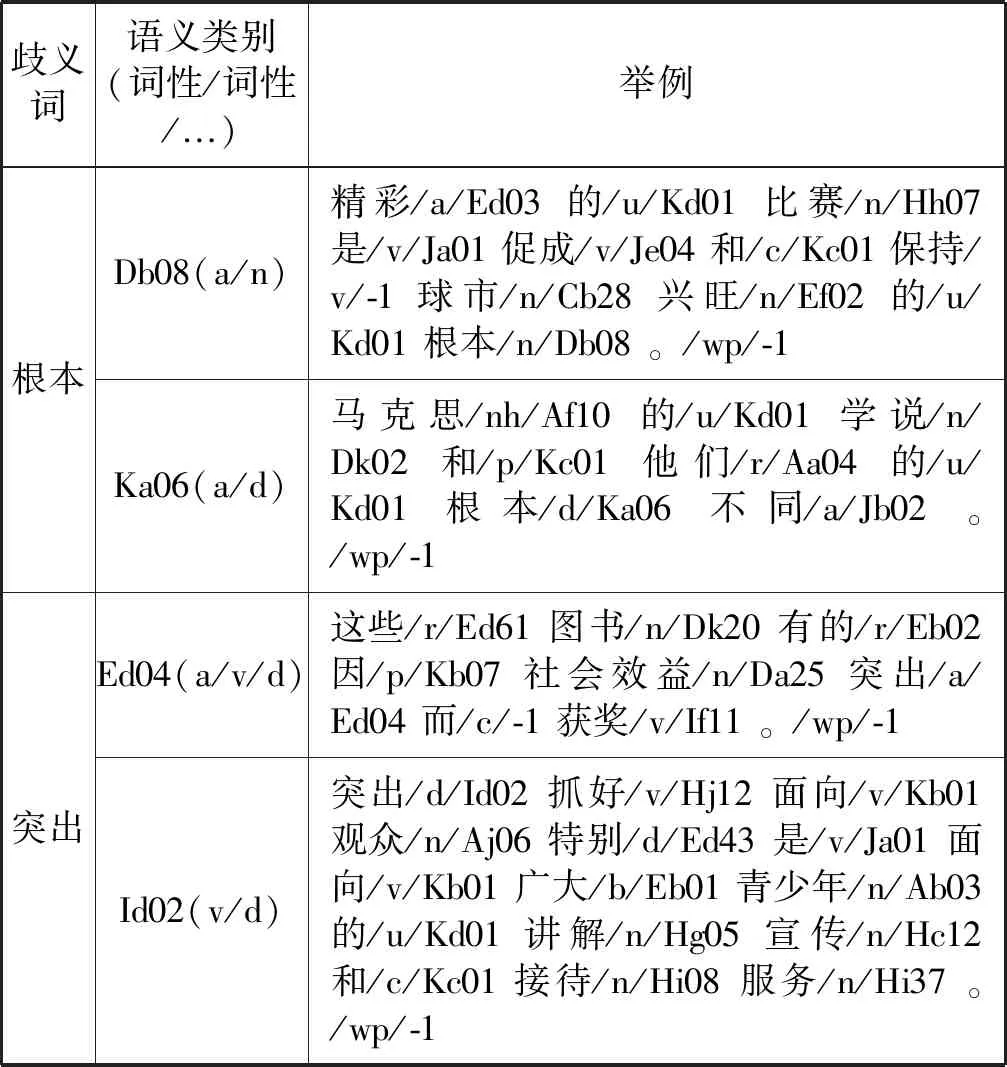
续表1
实验采用CIPS-SIGHAN-2010提供的B-Cubed评价指标,其计算公式如下:
(6)
(7)
(8)
式中:S={S1,S2,…}是聚类算法聚类的结果;R={R1,R2,…}是人工标注的结果。
为了验证本文方法的整体性能,基于上述计算公式,取12个歧义词的平均值作为词义消歧评价指标:
(9)
(10)
(11)
2.2 实验结果与分析
本文从三方面进行了实验:1) 分析依存结构树中与目标歧义词相关程度较大的所有节点,探寻具有普遍适用性的节点组合;2) 为了验证本文方法的消歧性能,基于FCM聚类算法,分别用文献[11]和文献[13]的特征抽取方法进行对比;3) 选用凝聚层次聚类、K-means聚类两个经典的聚类算法做对比,验证FCM聚类算法的性能。
2.2.1多节点组合提取消歧特征
假设在依存结构树中:(1) 距离目标歧义词越近的节点对判断歧义词语义的贡献越大;(2) 并非将距离较近的所有节点作为消歧特征,消歧效果就最好;(3) 不同的节点组合方式对消歧结果有不同影响。本节基于这三种假设进行实验。表2为8种节点组合方式及所得实验结果。

表2 八种节点组合方式及实验结果 %
可以看出,不同的节点组合对中文词义消歧有着重要的影响。下面将对实验结果重点分析:
(1) 不同节点组合对消歧效果有不同影响,使用依存结构树抽取特征时,要考虑选用的节点以及节点组合方式。
(2) 总体来看,在依存词(父子节点组合)基础上添加其他节点,比单纯地将依存词作为消歧特征效果好。其中,“祖父+父亲+孩子”节点组合作为消歧特征,虽平均准确率比“兄弟+父亲+孩子”节点组合少1.02个百分点,但平均召回率提高了6.11个百分点,平均F1值也提高了 1.41个百分点。实验表明,“祖父+父亲+孩子”节点组合,效果最好。
(3) 从依存结构树中,分析各个节点与目标歧义词的距离,发现祖父节点、孙子节点分别与目标歧义词路径一致,但祖父节点与依存词组合的消歧特征平均召回率与平均F1值均比孙子节点与依存词组合的消歧特征效果好,说明除路径长度外,单个节点对歧义词的消歧贡献也很重要。
(4) 由于实验采用多个不同歧义词,且每个歧义词的样本个数、义项分布均有不同。采用“祖父+父亲+孩子”节点组合抽取特征,具有一定的普遍适用价值。
2.2.2词义消歧性能比较
为了验证本文方法的消歧性能,分别用文献[11]和文献[13]的特征抽取方法进行对比。文献[11]选用歧义词的依存词、依存结构、歧义词词性作为消歧特征;借鉴文献[13]的思想,取依存结构树中路径长度为4的词作为消歧特征。FCM聚类算法需要设置两个参数,分别为模糊参数m和最大迭代次数。文献[22]认为1.5≤m≤3.0时效果较好[22]。本文选取模糊参数为1.5,最大迭代次数为100。
本文从特征向量矩阵的维度(简称特征维度)和平均F1值两方面分析三种方法的词义消歧性能。平均F1值的实验结果见表3和图3,其中每个歧义词的F1值通过运行10次求和平均得到。特征维度的实验结果见图4和图5,特征维度的平均值指12个歧义词特征维度之和的平均值。
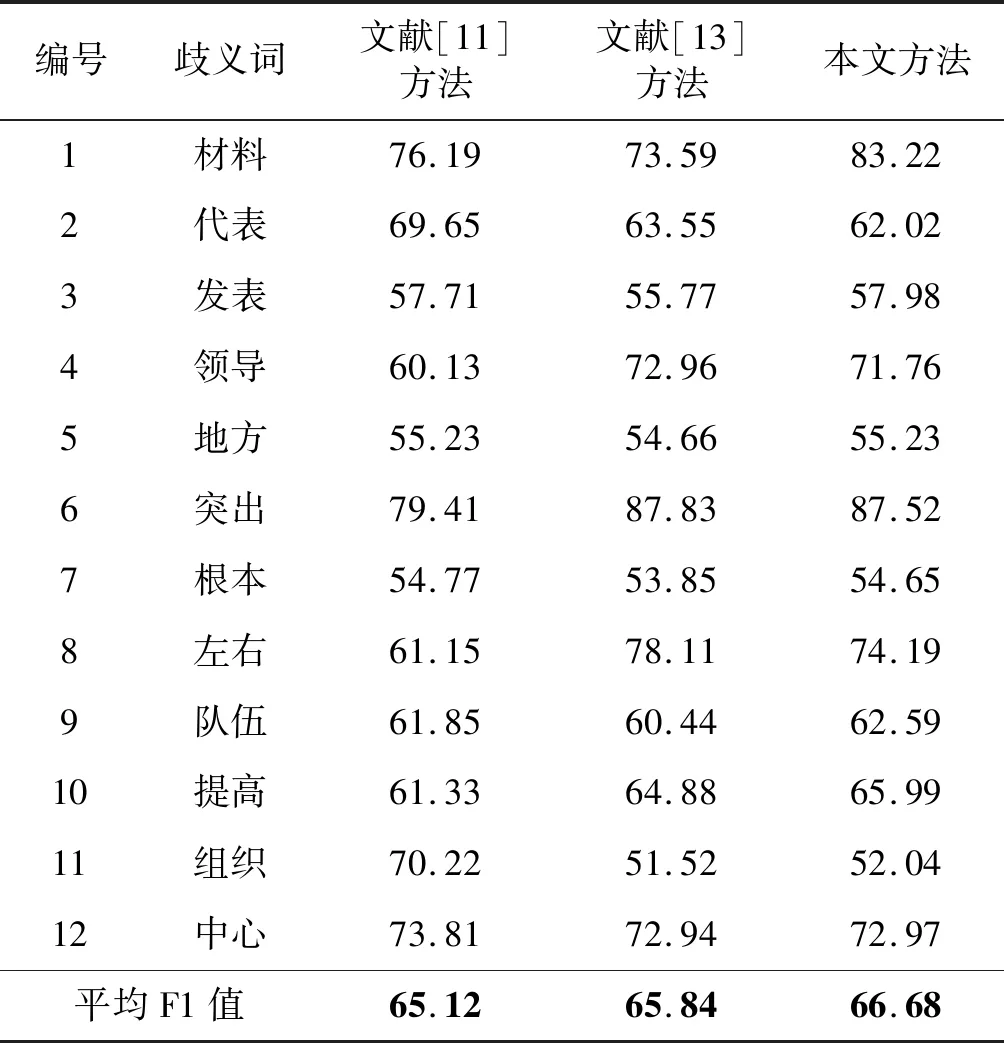
表3 三种方法F1值对比 %

图3 三种方法的平均F1值

图4 三种方法的特征向量矩阵维度

图5 三种方法的特征维度平均值
特征抽取不仅需要考虑消歧特征的区分性,还要考虑特征维度。较低的特征维度有利于降低计算复杂度[23]。图4中,本文采用的特征抽取方法所得特征维度总体上比其他两种方法的特征维度少,尤其当特征维度超过80时,本文方法在特征维度上相比于其他两种方法,相差幅度较大,优势显著。图5中,本文方法的特征维度平均值比文献[11]方法降低了5维,比文献[13]方法降低了25维。
表3和图3反映了三种词义消歧方法所得平均F1值。整体来看,本文方法优于其他两种方法。文献[11]采用依存词、依存结构和歧义词词性作为消歧特征。由于本文中歧义词的每个义项会包含不止一个词性,如歧义词“突出”的一个义项代码为Ed04,但会有三种不同的词性a、v、d,这些词性会影响对该义项的区分。因此这可能是影响该特征抽取方法效果的一个原因。
综上所述,本文方法不仅降低了特征维度,在平均F1值上也突显一定优势,对中文词义消歧具有一定的价值。
2.2.3实例聚类效果比较
为验证FCM聚类算法的可行性,选用凝聚层次聚类和K-means聚类两个经典算法作为对比实验。三个聚类算法的输入均以实验1中的“祖父+父亲+孩子”节点组合作为消歧特征。FCM聚类算法的相关参数与2.2.2节中参数相同。实验结果如图6所示。

图6 实例聚类效果图
可以看出,对平均F1值分析,FCM聚类算法比其他两种算法提高了近8个百分点,这说明FCM聚类算法的消歧性能最佳。FCM聚类算法相比其他两种算法,虽准确率稍有降低,但召回率提高幅度很大,表明采用FCM聚类算法,能够更全面地找到消歧信息。整体来看,FCM聚类算法优势突出。另外,FCM聚类算法凭借其软划分优势,使得每个样本不受限于一个类别中。软划分的聚类算法比硬划分的聚类算法更加符合客观世界的数据分析。
3 结 语
为了提高中文词义消歧质量,本文提出了一种基于多节点组合特征和FCM聚类算法的词义消歧方法。在特征提取部分,基于依存语法理论,分析不同节点组合方式,实验表明将“祖父”“兄弟”和“孙子”三个节点组合作为消歧特征具有普遍适用性,且降低了特征维度,对歧义词的识别有较大的区分度。采用TF-IDF构造特征向量,最终利用FCM聚类算法得到歧义词词义类别。大量的对比实验表明本文提出的方法在F1值上相较于其他算法提高显著,从而验证了该模型具有一定的优势。由于FCM聚类方法需要提前设定聚类的类别数目,未来工作将研究在保证消歧效果的条件下自动生成聚类数目。
