具有个人信息的对话生成模型研究
2021-02-25柯显信白姣姣
曹 斌 柯显信 白姣姣
(上海大学机电工程与自动化学院 上海 200444)
0 引 言
随着数据时代发展,人们越来越关注利用大量真实的交流数据来训练对话模型,这些模型的一个主要问题是它们倾向于选择具有最大可能性的响应(训练数据中表示的人类的共识响应),产生的回复通常是模糊的或不一致的[1]。Vinyals等[2]指出,当前的对话系统仍然无法通过图灵测试,在众多限制中,缺乏一致的个人信息是最具挑战性的困难之一,如表1所示。在人机交互的过程中,对话的部分内容会涉及到机器人的自身信息类问题[3],如姓名、年龄、性别等。和谐自然的人机交流需要机器人对于涉及个人信息类问题的回复总是稳定的,不要出现前后不一致的现象。

表1 信息不一致的回复
近年来,Li等[4]以序列到序列模型为基础,通过Al-Rfou等[5]使用类似的用户嵌入技术来模拟用户个性化的工作,两项研究都需要每个用户的对话数据来模拟她/他的个性。Qian等[6]利用双向解码器来生成预先给定的个人信息,但是需要大量数据标注信息位置。
本文提出一种具有个人信息的对话模型,赋予聊天机器人特定个人信息(如表2所示),并使聊天机器人能够生成与其给定信息一致的回复。
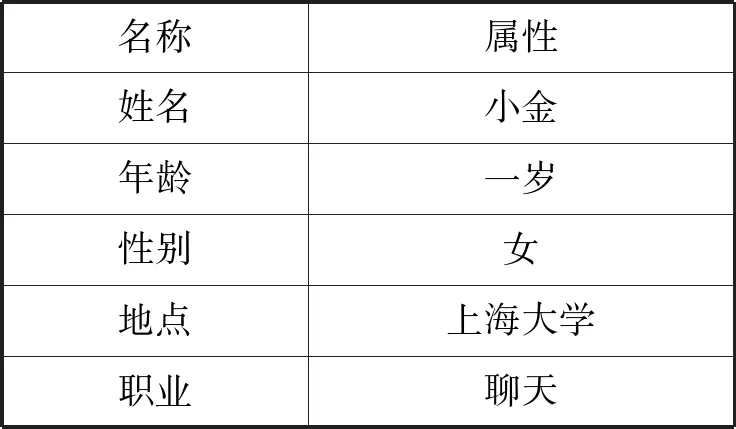
表2 预设五种个人信息
1 对话模型
对话模型如图1所示,任务描述如下:给出一个输入问题x,问题分类器D预测问题x是否属于个人信息问题:如果是,将问题转入个人信息回复模块,随机返回问题所属类别K的候选回复y作为模型回复;否则转入开放域对话模块,生成回复y。生成回复的过程如下:
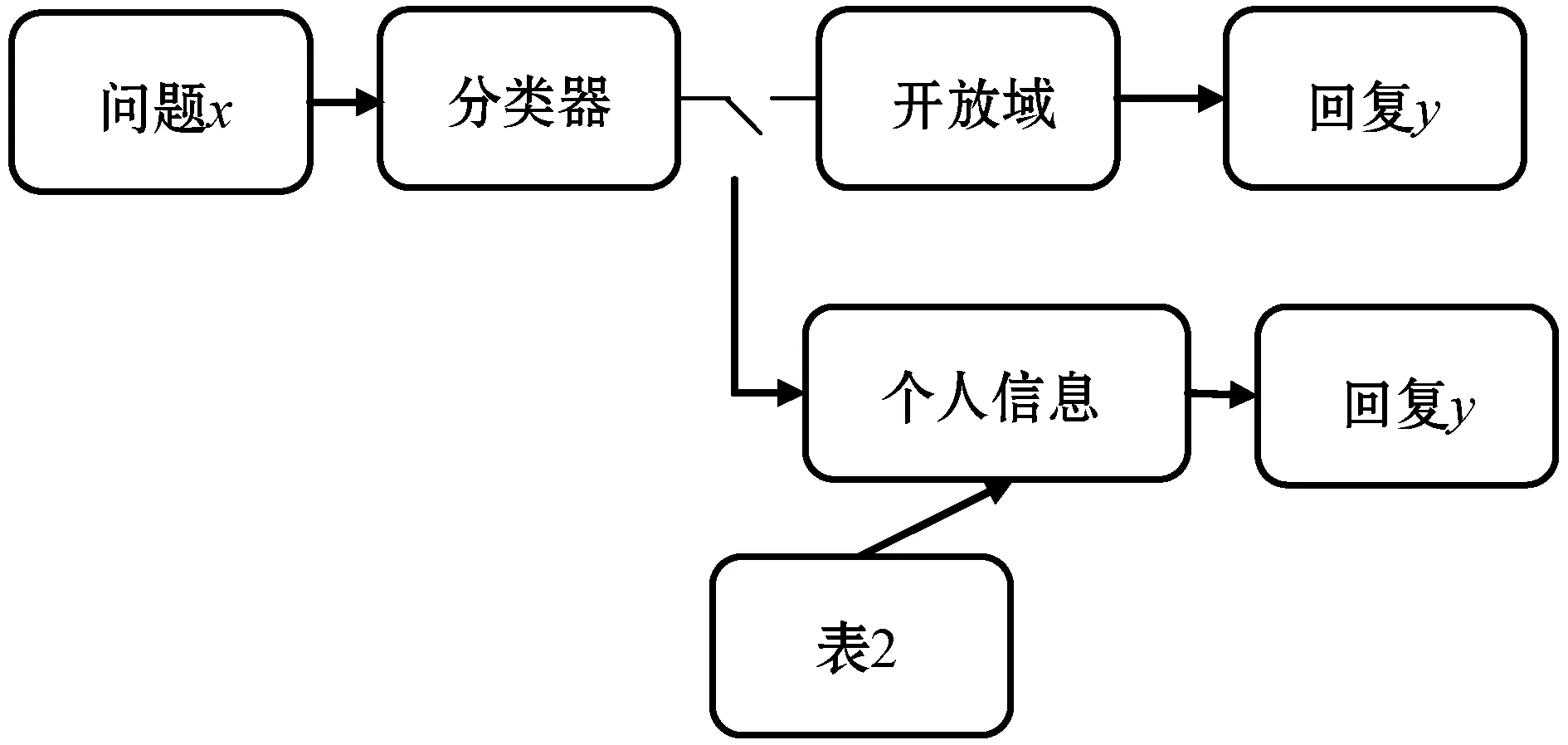
图1 对话模型
P(y|x)=P(z=1|x)×PO(y|x(ki))+
P(z=0|x)×PG(y|x)
(1)
式中:P(z|x)表示输入问题(x)所属类别的概率;z=1表示问题x属于涉及个人信息,否则反之。PO(y|x(ki))表示个人信息回复模块给出的所属类别的答案的概率;PG(y|x)表示开放域对话模块给出的回复的概率。
2 问题分类模型
分类模型用来判别输入问题是否需要个人信息回复模块处理,是一个二分类问题。用P(z|x)(z∈{0,1}),z=1表示需要个人对话模块,例如:“你今年几岁?”则P(z=1|x)≈1;“你哥哥今年几岁?”则P(z=1|x)≈0。
近年国内外学者对于短文本分类的问题做了大量研究,主要分为两类:机器学习算法和深度学习算法。机器学习领域有支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistics Regression,LR)、朴素贝叶斯分类法(Naive Bayes Classifier,NBC)、K-最近邻法(k-Nearest Neighbor,KNN)、决策树法(Decision Tree,DT)和中心向量法等[7]。深度学习算法有Kim[8]提出的Text-CNN,其具有良好表现。然而自然语言处理中最常用的是具有捕捉上下文信息的递归神经网络(Recurrent Neural Network,RNN)。为了将RNN与CNN结合,又提出RNN-CNN模型来弥补CNN不能够处理文本上下关系和RNN在长距离上存在信息衰减的问题。
本文将对比各方法在语料上面的性能,综合考虑选取恰当的方法。
3 个人信息回复模块
为了维护前后回复的信息一致性,本文的解决思路是相似问题匹配,即对比用户的输入问题与设定的数据库中问题的相似度,返回最大相似度的问题的答案作为模型回复。相比于机器学习方法,深度学习能够发掘以往很难发掘的隐含在大量数据中的不显著特征,更细化地表达文本匹配问题[9]。
本文以孪生网络思想构建个人信息回复模块,如图2所示。
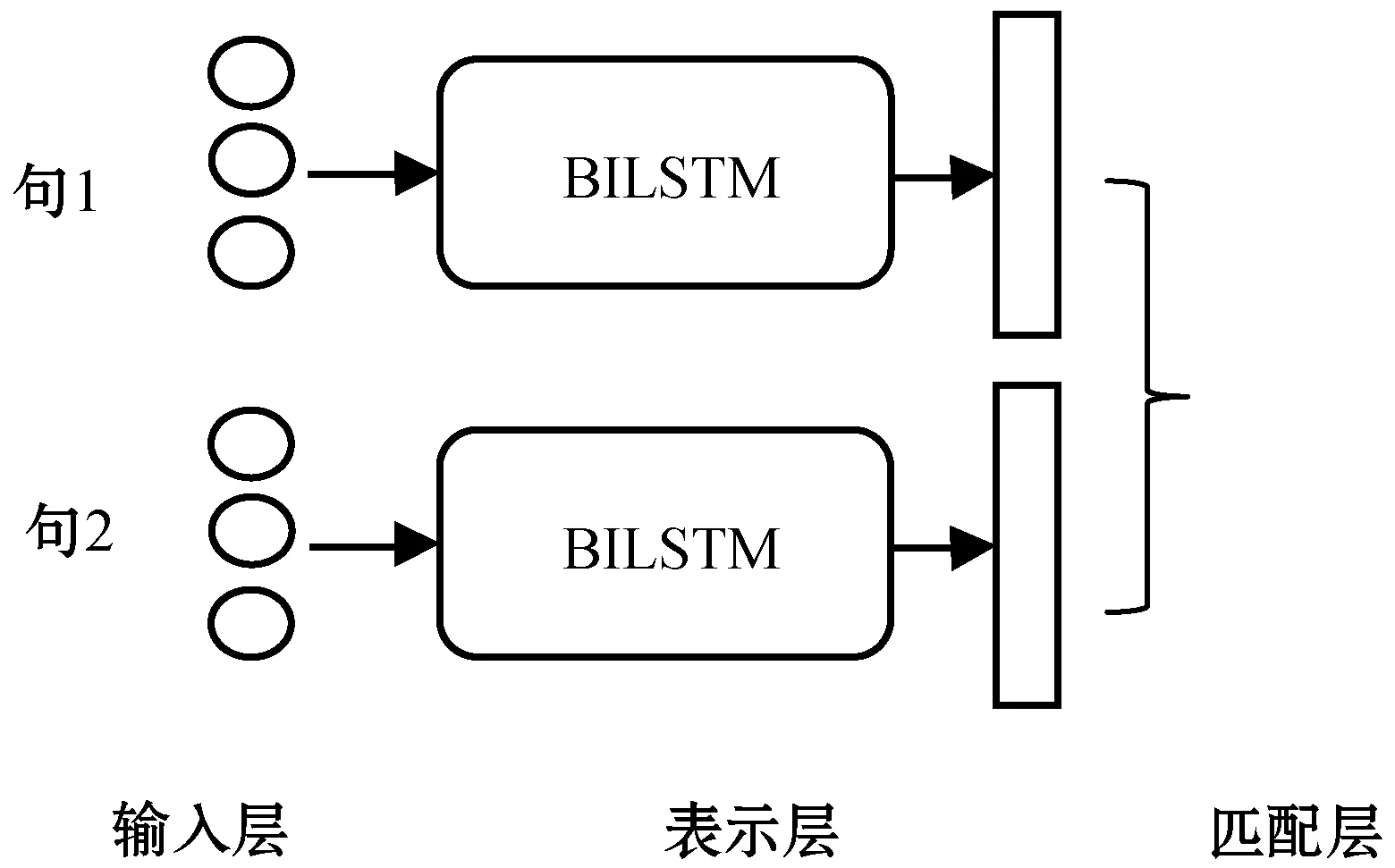
图2 个人信息回复模型
本文模型首先将两个句子通过深度学习模型进行表示,然后利用相似度方程计算这两个表示之间的相似度即匹配度。该方法注重于构建句子的表示层,尽量用等长的向量表示待匹配句子的语义。本文采用BiLSTM模型对句子的语义信息进行表示,BiLSTM由正反两个长短期记忆网络(Long Short-Term Memory,LSTM)[10]模型组成。LSTM记忆单元各部分在时刻t更新如下:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
(4)
(5)
ot=σ(WO[ht-1,xt]+bo)
(6)
ht=ot×tanh(Ct)
(7)
式中:it、ft、ot依次表示输入门、遗忘门、输出门;xt表示t时刻的特征向量;σ(·)表示sigmoid函数。
BiLSTM模型增加对文本逆向语义的学习。连接正反两个方向的LSTM模型输出向量作为t时刻BiLSTM的输出Bt[11]:
(8)
(9)
(10)
本文采用的损失函数是对比损失函数,可以有效地处理成对数据的关系,其表达式如下[12]:
(11)
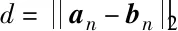
4 最大互信息的开放域对话模型
基础的Seq2seq模型是以最大对数似然为目标函数,模型在面对问题时会容易产生类似“我不知道”“呵呵”“哈哈”等通用无意义的回复。因此本文借鉴了Li等[13]提出的抗语言模型(anti-language model,anti-LM),以最大互信息作为Seq2seq的目标函数,公式如下:
(12)
(13)
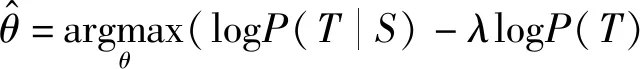
(14)
式中:λlogP(T)视为对任何输入都具有高概率的候选词的惩罚,由参数λ控制惩罚的大小。由于惩罚项的存在,模型不再一昧选择概率高的词,避免产生通用的回答。但惩罚会影响句子结构和流畅性,因此引入分段函数g(k)[14]:
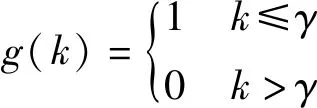
(15)
(16)
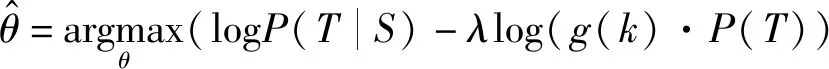
(17)
前期生成词对句子多样性的影响显著大于后期生成词,为了尽可能地保证句子流畅性,在解码器生成句子过程中仅仅对前期生成的高概率候选词进行惩罚。
5 实 验
5.1 数据样本
本文根据设定的五种身份信息,从微博、小黄鸡语料和青云语料提取和采样得到了10 072个样本用于训练问题分类器。通过对样本进行标注,涉及个人信息为正样本(标签为1),反之为负样本(标签为0),部分语料如表3所示。

表3 部分问题分类样本示例
训练个人信息回复模型时需要输入两个句子和相似度。人工地将所收集的正样本进行五分类(姓名、年龄、性别、地点、职业),同类型样本间构成相似问题对(标签为1),不同类型间样本构成不相似问题对(标签为0),如表4所示。

表4 部分相似度训练样本示例
5.2 问题分类
本文测试了SVM、LR、NBC、CNN、LSTM和LSTM-CNN。传统机器学习模型的文本表达形式为词袋和TF-IDF;SVM采用线性核函数;深度学习方法采用预先训练好的词向量;CNN参考Text-CNN模型;LSTM模型利用最后一个时刻状态经过全连接输出;LSTM-CNN利用CNN把LSTM每个时刻的输出进行卷积和池化。本文选取了准确率、F1值和AUC值来评价各模型性能,实验结果如表5所示。
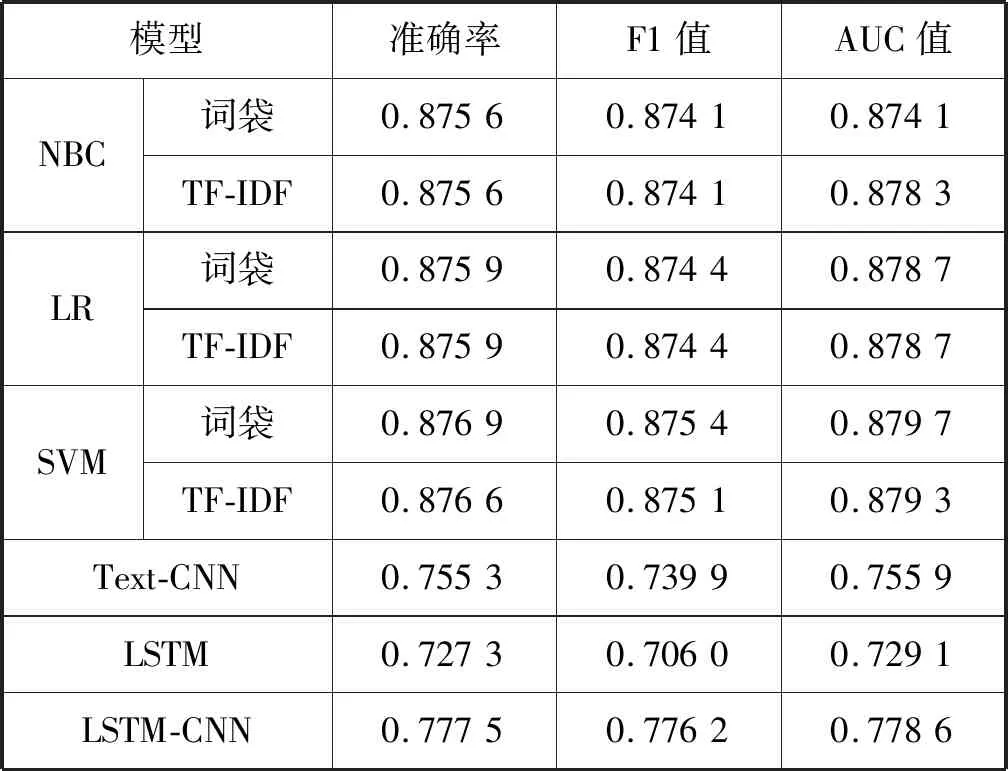
表5 不同方法模型评估
可以看出:(1) 基于词袋的SVM取得了最好的性能指标。(2) 传统的机器学习分类性能整体优于深度学习,主要原因是因为所提取的语料中某些词汇频繁出现,比如涉及姓名信息问题中姓名、名字和叫什么等词汇大量出现,所以具有统计特性的模型会有良好表现。本文还选取准确度最多的三个模型进行加权平均法,但是分类效果没有显著提高。最终本文选取基于词袋的SVM作为问题分类器。
5.3 个人信息回复模型
除了本文中的基于BiLSTM的孪生网络的相似度计算方法外, 还比较了基于LSTM与全连接、基于BiLSTM与全连接、基于LSTM与余弦以及基于词向量余弦距离和词移距离(Word Mover’s Distance,WMD)的方法。以上几种方法对应简称为LSTM_F、BiLSTM_F、LSTM_cosine、w2v_cosine和w2v_wmd, 其中采用全连接层的网络加入了Batch normalizationn层[15]来提高收敛速度,LSTM_cosine利用余弦计算logit与目标值[1,0]的距离,作为相似度。
由于本文设定五个身份信息,因此准确性是指预测的类别是否为标签类别,公式如下:
P=P(klabel=kp)
(18)
kp=K(max(Similarity))
(19)
式中:P为模型准确度;klabel为标定种类;kp为预测类别;K为设定的五类信息;Similarity为相似度。
实验阶段针对五种身份信息选取 500个问题作为匹配数据库,每个类型100个,各模型实验结果如表6所示,均耗时指的是平均每个问题回复的时间。
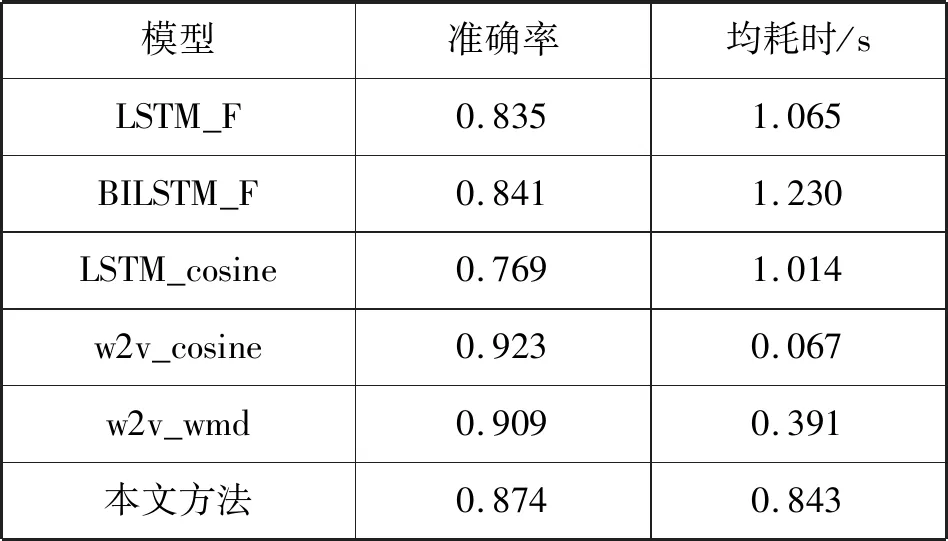
表6 各模型实验结果
w2v_cosine和w2v_wmd直接将词向量拼接来表示句子特征,这导致只要句子关键字相同就会判别句子表达主题相似,而本部分数据经过问题分类,选取的数据词语分布集中所以取得了较高准确率;BiLSTM_F、LSTM_F和LSTM_cosine利用LSTM能够学习文本深层次关系。本文方法取得了较好的准确率,因为对比损失函数可以很好地表达成对样本的匹配程度,但是在时间效率上略有不足。
为了回复的多样性,本文为每个类别分别设置多个回复模板,比如关于年龄的回复有“我今年一岁了”“人家已经一岁了”“一岁”“本宝宝出生一年了”等,每次选取一个答案作为回复。
5.4 最大互信息回复模型
对开放域回复模块采用人工测评与BLEU评估结合的形式,分别以最大对数似然和互信息作为目标函数训练了两个对话模型。实验中最大互信息模型的惩罚系数λ取值为0.5,γ设定为1。
两个模型的BLEU值为0.17 和0.25,以最大互信息为目标函数的模型较好。在人工测评中,让20个人与两个模型分别进行20句以上的交互,判断哪种生成的结果更好,结果显示大多数人认为两个模型差不多,30%的人认为以最大互信息为目标函数的模型较好。
5.5 对话模型实验
本文随机选取部分对话,请10 位志愿者对其以下几个方面进行评价。
自然性:回复是否自然通顺。如果太短或者无意义回复被认为缺乏自然性,获得0分,反之得1分。
逻辑性:回复与问题是否成逻辑关系。比如涉及性别问题,回复类似“女孩”等将获得1分,反之得0分。
信息一致性:对于涉及个人信息的回复是否保持前后一致。比如年龄一类问题,回复的属性值应该与设定的一样“一岁”。信息一致获得1分,反之得0分。
多样性:对于某一类问题是否具有多种回复。比如对于回复年龄类别,应该具有不同的回复如“我今年一岁”“人家已经一岁了”。具有多样性获得1分,反之得0分。
人工评价结果如表7所示。可以看出,本文模型在每个指标都优于普通的Seq2seq模型,特别在信息一致性,这是因为本文添加了个人信息回复模块。本文模型对话样例如表8所示。
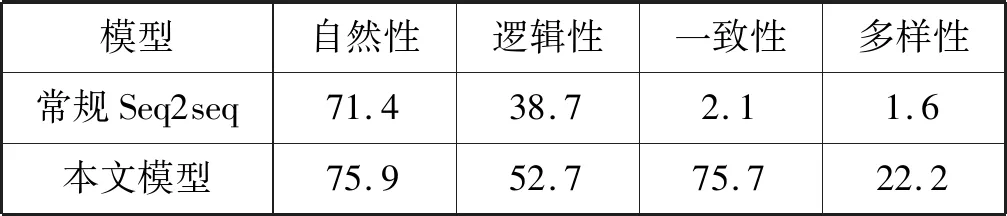
表7 回复的评估 %
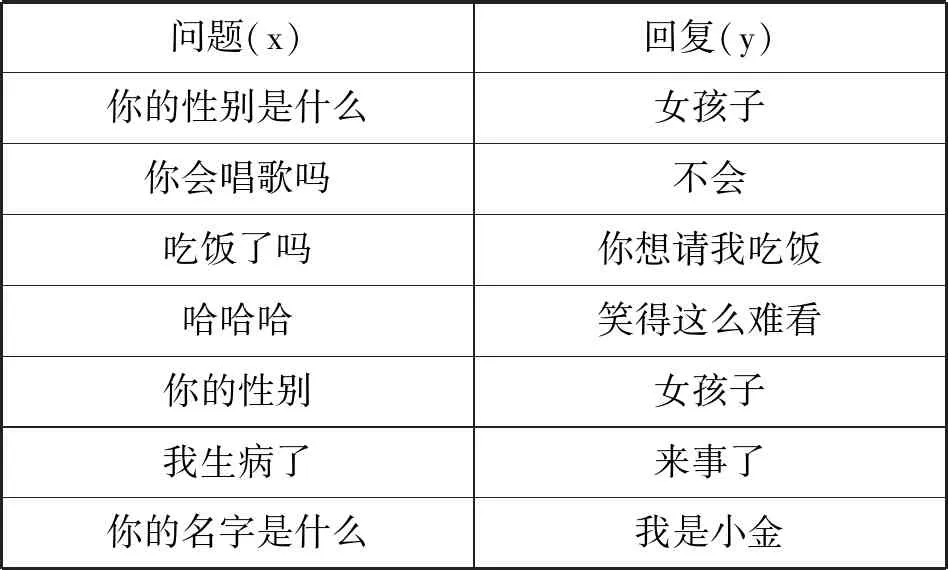
表8 对话样例
6 结 语
为了维护对话前后个人信息的一致性问题,本文提出了具有个人信息的对话模型,该模型能够简化从对话数据中学习个人信息的复杂性。实验表明,本文的对话模型能够有效地生成与预设信息一致的回复,同时减少无意义的通用回复,有助于产生更加连贯和多样的对话。
本文不足如下:训练语料的质量不佳,模型的时间复杂度较大。未来研究还需要考虑对话的情感状态、对话的逻辑推理和对话的风格等。
