基于生成式对抗网络的开放式信息抽取
2021-02-25韩家宝王宏志
韩家宝, 王宏志
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
信息抽取是自然语言处理领域内的重要研究内容之一。 研究目的是将文本结构化,结构化后的内容可以是三元组的表示形式,也可以是多元关系的表示形式[1]。 传统的信息抽取方法侧重于在语料库上建立一套预定义的抽取范式[2-4]。 因此,这些方法离不开大量的人工参与,为了减少信息抽取中的人工参与,研究人员提出了开放式信息抽取[5-6],开放式信息抽取不局限于一组与定义的目标关系,而是提取文本中发现的所有类型关系。 近年来,开放式信息抽取取得了可观的研究成果[4,7-20],一系列的开放式信息抽取系统陆续被应用到各种工具当中。 这些系统普遍采用多种自然语言处理工具,因此也无一例外地面临着错误积累和传播的问题[21]。近期的工作多采用端到端的神经网络方法来进行开放式信息抽取的研究,这些方法虽然有效避免了错误积累和传播问题,但却没有考虑到曝光偏差问题,即:使用编码器-解码器架构处理序列到序列问题时,训练阶段与测试阶段所使用的数据不一致。
本文中,提出了基于生成式对抗网络(GAN)[6,22]的模型来应对开放式信息抽取任务,GAN 模型不仅避免了传统方法带来的错误累积和传播问题,还能很好地解决曝光偏差问题[5,23-25]。 此模型包含一个序列生成器,一个鉴别器。 其中,序列生成器负责生成开放式信息抽取的结果,鉴别器用于鉴定生成器的结果是否来自训练数据。 文中也对一个大型的Open IE 基准数据集进行了研究,实验结果表明,该算法的性能优于几种常用的基准。 同时,也证实了本文提出的模型要比单一的编码器-解码器模型好得多。 此外,性能上的明显改进也证实了GAN 模型在解决开放信息抽取任务中的曝光偏差问题上的有效性。
1 模型架构
生成式对抗网络已经成功应用于计算机视觉等领域以及一些其他重要的领域[26-30]。 GAN 由2 个模块组成,分别是:生成器G和鉴别器D,其目的旨在估计当前输入施工训练数据而不是从生成器中产生的概率。 在开放式信息抽取任务中使用GAN 模型的价值函数为:
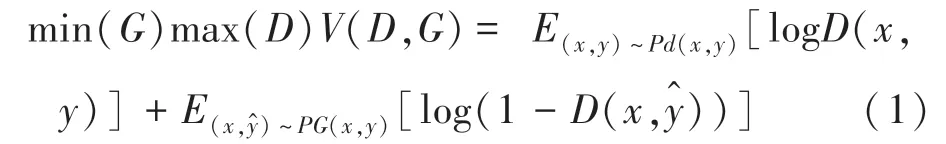
其中,(x,y)表示训练实例;x表示输入;y表示输出;Pd表示数据分布;PG表示生成器的参数分布。
如式(1)目标函数所述,鉴别器的学习目标是确定当前数据是来自训练数据、还是来自生成器的结果。 生成器的训练目标是产生与训练数据相当的结果来混淆鉴别器。 在实际的模型训练过程中,常用策略梯度[31]法来计算生成器的梯度。 更新生成器参数模型前,先采样候选答案并使用鉴别器来计算奖励分数,继而利用所得奖励分数来计算生成器的梯度,再使用反向传播算法来更新一代参数。 在训练过程中,将训练数据中的序列和采样后的候选序列分别作为鉴别器训练的正例和反例。 为了解决鉴别器的过拟合问题,使用MLE[32-34]提高生成器训练的稳定性。
图1 中展示了GAN 模型的整体架构,该模型是由Transformer 模型构成的序列生成器和CNN 模型构成的鉴别器组成。
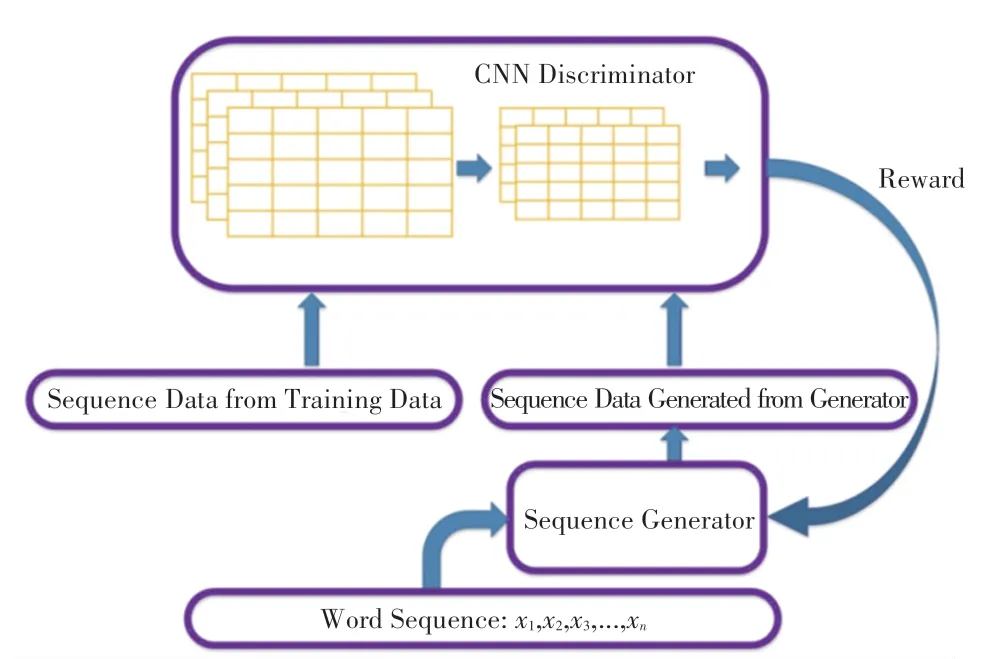
图1 模型架构Fig.1 Model architecture
1.1 序列生成器
对于序列生成器,编码器结构将输入序列映射到高维空间中的向量表示,解码器根据中间向量表示进行解码,与传统的网络结构不同,Transformer 模型不包含任何循环单元和卷积单元[35]。 研究中,是通过正弦位置编码来记录单词的相对位置,具体公式可写为:

其中,pos表示单词的位置;i表示输入句子的维度;d表示编码器输出的维度。 在第一个编码器和解码器部分,位置编码通过式(2)、式(3) 进行计算。 第j个编码器的输出Se j是通过一个自注意力层和一个前馈神经网络层进行计算得到:

其中,Oe(j)表示第j个编码器的注意力层的输出;LN(·) 表示的是归一化层;表示的是编码器的输入;第j个解码器的输出是由一个编码器-解码器的注意力层EDATT() 产生的。 此处需涉及的数学公式可写为:

其中,表示解码器的输入;表示第j个解码器自注意力层的输出;表示第j个编码器的输入;最后一个解码器层的输出Sd(n)被线性映射到V维的矩阵中,这里的V是输出词汇表的长度。
1.2 对抗模型
对于给定的输入序列x,鉴别器需要区分当前结果是来自生成器的输出y^,还是来自训练数据中的实序列y。 因此,研究使用卷积神经网络来度量序列对(x,y) 的匹配度。 考虑到卷积神经网络具有逐层卷积和池化的功能,在该项任务中则有着独特的优势。 卷积神经网络可以准确地捕获(x,y) 在不同空间中的对应关系,给出给定序列对(x,y),先通过简单地连接标记为x和$y$的嵌入向量构造2D表示。 对于x中的第i个单词xi和y中的第j个单词yj,有以下特性映射:
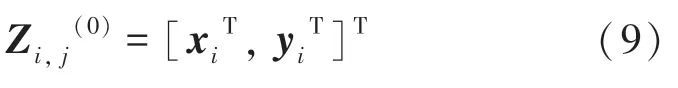
基于这种2D 表示,这里的卷积窗口设置为3*3 大小,通过以下的类型f的特征映射来捕获x与y的映射关系:

其中,σ(·) 表示sigmoid激活函数,σ(x)=1/(1+exp(- x)),再使用一个2*2 的窗口进行池化操作:

在此基础上,将提取的特征输入到一个全连通层,利用上一层的sigmoid激活函数,求得训练数据中(x,y) 的概率。 该鉴别器的优化目标是以训练数据(x,y) 为正例,序列生成器采样数据为负例,以最小化二值分类的交叉熵损失为目标。
训练目标:生成器模型试图生成一个高质量的序列来欺骗鉴别器。 对于鉴别器D,使用训练集和G生成的序列对D进行训练。 形式上D的目标函数是使V(D,G) 最大化:

对于序列生成器G,G的目标是最大化期望奖励(D的概率),而不是直接最小化V(D,G),函数如下:

鉴别器的训练过程与传统模式训练没有区别,只需要向鉴别器提供发生器的输出和训练数据。 发生器的训练过程不同于鉴别器的训练过程,因为从发生器的离散采样结果y^使得从鉴别器直接反向传播误差信号到发生器要较为困难,使V(D,G) 对G的参数不可微。 为此,研究中使用了enhance 算法来优化生成器G。
2 实验
研究中使用了大型基准数据集OIE2016[36],包含3 200 个句子,共10 359 个提取、包含24 296 个句子,共56 662 个提取。 为了验证本文提出方法的性能,仿真中使用了数个最先进的基准测试,包括OLLIE、ClausIE、Stanford OpenIE、PropS 和OPENIE4来与本文方法进行比较。 实验中,使用了2 个评价指标,即:精确度和查全率。
2.1 模型参数
研究中利用keras-transformer 实现Adversarial-OIE。 本次实验中使用了Tesla P100 GPU。 该模型包括6 个编码器和6 个解码器、768 维的隐藏状态和512 维的单词嵌入。 词汇量有55 K 个。 仿真时采用Relu作为注意激活函数和前馈激活,退出率设为0.05。 同时选用Adam优化了本文模型。 对于对手D,CNN由2 个卷积+池化层、一个全连接层和一个softmax层组成,卷积窗口大小为3*3,池化窗口大小为2*2, 特征大小为20,隐藏层的大小为20。
2.2 实验结果
在OIE2016 中的脚本作为本次研究的工具来评估精度和召回结果。 仿真得到的精确率/召回率曲线如图2 所示。 在基准测试集OIE2016 中,将本文提出的模型与许多基准测试方法进行了比较。 从实验数据可以看出,与现有方法相比,本文方法在精度方面有明显的优势。 该模型的主要优点就是端到端神经网络模型,避免了错误传播的问题。

图2 实验结果Fig.2 Experimental results
3 结束语
本文创新性地采用生成对抗网络模型来处理开放式信息抽取任务。 研究中,将开放式信息提取任务定义为序列到序列的任务。 编码-解码器结构的网络模型处理序列到序列的任务会导致暴露偏差问题(由训练和推理过程中的文本生成不一致引起)。这种不一致性反映在推理和训练中使用的不同输入上。 在训练过程中,每个单词输入都来自于一个真实的样本,但是当前用于推理的输入来自于上一个预测的输出。 采用生成对抗网络模型可以有效地解决这一问题。 生成对抗网络模型的再训练阶段给每个单词设定一个相应的奖励,而非如同极大似然估计一样来增加单词出现的概率,如此就不会产生曝光偏差问题。 本文的模型尽可能地保证了鉴别器的可靠性。 利用高质量的鉴别器改进了序列发生器。无需任何手工制作的模式和其他NLP 工具,序列生成器就可以生成精度更高的三元组。 实验表明,该模型具有较好的性能。 从实验结果不难看出GAN模型的不足。 也就是说,在一定的时间间隔内,精度会迅速下降。 究其原因则在于GAN 模型的对抗性训练不容易控制。 在训练过程中,如果鉴别器模型有偏差,发生器模型就会被误导,产生一个劣质循环,这一偏差也会越来越大。 最终,模型的性能会突然下降。
