基于PanGan和高通滤波相融合的改进深度神经网络遥感图像超分辨率算法研究
2021-02-25邱治邦
邱治邦

摘 要:遥感图像融合中的泛锐化是指将全色图像与低分辨率多光谱图像进行融合,得到高分辨率多光谱图像。最近,卷积神经网络基于CNN的泛锐化方法已经达到了最先进的性能。尽管如此,仍然存在两个问题。一方面,现有的基于cnn的策略需要监督,只需对高分辨率图像进行模糊和降采样即可获得低分辨率多光谱图像。另一方面,它们往往忽略全色图像丰富的空间信息。为了解决这些问题,我们提出了一种新的无监督框架,用于泛锐化,该框架基于生成式对抗网络,称为CBMA_PanGAN,在网络训练中不依赖所谓的真实数据集。在我们的方法中,生成器分别与光谱鉴别器和空间鉴别器建立对抗博弈,从而保持多光谱图像丰富的光谱信息和全色图像的空间信息。
关键词:PanGan;高通;滤波相融合;深度神经网络遥感图像;超分辨率
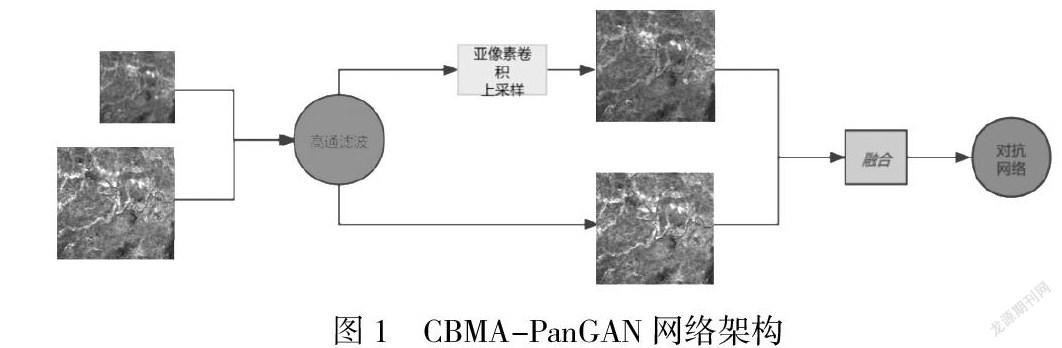
一、CBMA-PanGAN网络架构
优化网络是在PanGAN的网络基础上引入高通滤波算法,亚像素卷积采样,已经增加了目前最为流行的CBMA注意力模块(通道注意力和空间注意力)。另外我们的网络是基于tensorflow1.0版本架构开发,虽然近几年主流深度学习框架为Pytorch,但是基于tensorflow开发的网络架构然有优秀的算法可以改进,而TensorFlow架构没有如pytorch架构具有注意力的框架。所以在具体算法编码过程中,我们提供了在TensorFlow1.0版本架构中添加各类注意力机制的解决思路和办法。
我们改进后的CBMA-PanGAN网络架构在保留了光谱信息和空间信息的基础上,引入了PanNet提出的高通滤波及ResNet的网络思想,极大程度上的过滤掉了平滑噪声,同时由传统的插值采样的办法改为亚像素卷积的方式,提高了采样后图像质量。全色图像和低分辨率图像融合之后将送入高通滤波处理,高通滤波是过滤掉低频信息保留图像在高通区域的信息,此方法是传统锐化方法,通过滤波后我们可以得到处理过后的图像。之后我们将低分辨率图像通过亚像素卷积的上采样操作,将低分辨率图像上放大至原图像的四倍,然后进行融合送入对抗网络,得到我们所需要的输出目标图像。
我们将高通滤波添加到遥感图像融合之后,先通过高通滤波处理。高通滤波的作用是使图片的高通信息通过,过滤掉图片低频的信息,从而达到突出边缘信息的作用,达到泛锐化的效果。高通滤波也是常用的物理办法处理图像锐化,在过去几十年内的图像处理领域有着极好的表现,我们的思路是在网络中先进行预处理。突出轮廓,使得送入神经网络时有这较之前更好的处理效果。
在我们的框架中,我们不可避免的会遇到图像上采样的问题。在图像采样领域,有多种方法。上采样是指放大图像,下采样是指缩小图像。采样常见的方法有线性插值、双线性插值、双三线性插值方法。这些方法各有优缺点,普通的线性插值速度快但是效果差。双三线性插值效果比普通线性效果好,但是缺点是时间长。所以通过对比,我们选择亚像素卷积的办法来进行我们低分辨率图像的上采样操作。亚像素卷积的核心思想是像素重组,它是将低分辨的特征图,通过卷积和多通道间的重组得到高分辨率的特征图,已达到提高分辨率的效果。
采样的好坏决定了图像质量的好坏我们将低分辨率图像进行上采样,和原网络利用双线性插值采样的方法不同,我们优化了采样办法选取目前流行的采样办法亚像素卷积。亚像素卷积的原理在上一章已經介绍,本章主要介绍具体实现。由于遥感卫星图像特性,全色图像与低分辨率图像大小为1比4,所以为了顺利融合,研究人员需要将低分辨率图像采样到与全色图像相同比例尺寸大小。传统的插值方法可能会导致图片严重失真,而亚像素卷积可以大大提高采样的质量,我们在如图所示的网络部分进行。经过对比试验,我们发现采用亚像素卷积处理后的采样图片效果比传统插值方法有着较大的提升,所以证明了亚像素模型对于改进算法有着良好的效果。在实验过程中,我们发现亚像素卷积在TensorFlow1.0版本中没有公开的包,所以在使用过程中,我们又对代码重新进行编写,达到了预期效果。
生成器中添加注意力机制。注意力机制是目前最为火热的手段技术,所以我们在网络中将添加最为主流的注意力机制CBMA注意力机制(空间注意力和通道注意力)。我们在生成器网络9*9、5*5、5*5卷积网络中进行添加双注意力,对每一层的输出都新增一个新的权重用来约束生成对抗网络的训练效果,使其提高生成器的图片质量。注意力机制是由平均池化和最大池化构成,在代码中注意力机制的位置是在激活函数之后,因为在我们看来,并不想因为注意力机制而导致网络原来结构的改变,我们仅仅是为了通过注意力来提高生成器提取信息的能力,从而起到更好的生成图片质量目的。
二、训练过程
我们的原始网络框架网络结构PanGAN是在英伟达3090显卡上进行训练,为了达到改进后算法的适应性,我们在GPU上训练次数设置为500000次,训练数据由32*32的原始低分辨率图像和分辨率为128*128的全色图像组成。初始化学习速率设置为0.0001,衰减速率为0.99,步长设置为10000。优化器选取为RMSProp优化器,RMSProp算法的全称叫 Root Mean Square Prop,是Geoffrey E. Hinton在Coursera课程中提出的一种优化算法,解决了优化中摆动幅度大的问题。所谓的摆动幅度就是在优化中经过更新之后参数的变化范围。在训练过程中,我们判别器最初旳损失值是在1.7左右,由于损失函数约束的作用,通过训练后损失值为0.5即可达到所需要的目标训练效果。训练集全部运行执行完需要两天左右。同时,由于我们的注意力机制的良好表现,我们在训练到15000次左右就基本达到训练预期目标效果。训练过程中我们发现由于注意力机制的原理机制产生了新的偏置,而新的偏置将会影响测试集代码运行,经过我们对代码的重构,添加了新的权重在测试集代码中,测试集代码速度较之前有了极大的提高。
三、实验结果
我们选取GF-2卫星作为图像测试集,,我们给出了原始HRMS图像下采样到LRMS图像再参考HRMS图像的Wald协议下的对比结果,如图2所示。左侧为HRMS与不同方法融合结果对应的误差图像。右侧为改进算法结果图像。在这些方法中,只有MTF-GLP、BDSD和我们的方法的结果能清晰地保留这个细节,而其他方法的结果缺失或较弱。但是,在MTF-GLP的结果中存在一些色差BDSD与pan-gan相比。结果表明,该方法在保持光谱分布的同时,也较好地保留了空间细节。
