基于类别不平衡的企业信用风险违约测度探索
——以制造业上市公司为例
2021-02-23郭畅
郭 畅
(安徽大学 经济学院,合肥 230601)
0 引 言
信用风险是商业银行面临的主要风险之一,并且随着“互联网+”时代的到来,互联网金融行业蓬勃发展,越来越多的金融产品走向市场。然而信贷业务不仅限于商业银行,也开始有了越来越多的选择,对于互联网金融公司,机遇的同时面临着极大的挑战。不管是银行还是互联网金融行业,信用风险的管控都是不可逃避的关键环节和决策的主要依据。之前安然事件引发了J.P摩根和花旗集团的信用风险,使得J.P摩根对安然的无担保贷款高达5亿美元;由于信用风险监管缺失,德隆系(与新疆德隆有关的上市公司)在银行的贷款高达200~300亿元,造成银行信贷危机。近年来, P2P(互联网金融点对点借贷平台)的破产事件引起了社会极大关注,不可避免的原因在于大多 P2P平台借助各方担保,这加速了平台信用风险的酝酿和积累。
可见不管是银行还是互联网金融业,“风险管控”都是必经之路,而“征信系统”的完善更是要共同追求的目标。如何构建高效的信用风险评估系统,从企业的角度防范信用风险是研究的重点。而制造业是我国国民经济的重要组成部分,制造业是立国之本、强国之本、富民之本。在“中国制造2025”强国战略实施背景下,关注制造企业发展及其资金借贷状况显得尤为重要。然而制造业企业整体信用风险偏高,是商业银行不良贷款的主要来源,因此需要针对制造业企业的特点,合理构建企业信贷的风险评估方法,完善企业风险预警机制,提升违约风险识别的精度是研究的重点内容。
1 文献综述
岳爱东[1]使用2004年至2012年9年的财务指标数据计算出指标的WOE值和IV值,初步筛选变量,再选择其中不同的变量组合,分别建立Logistic回归模型,通过比较模型的预测结果反推出可纳入信用风险模型的优良定量指标。由于传统的logistic回归模型因为其解释性强、预测能力较好且稳定性较高的原因常常被用来建立信用评分模型,但由于个人信用评估的数据一般较大,涉及变量较多,指标之间往往存在多重共线性,此时,传统的逻辑回归会因为变量间的相关性导致模型性能较差,不再适用,而进行变量子集选择后的逐步回归倾向于保留部分不重要的变量,使模型准确率大打折扣,因此很有必要进行有效的变量选择。方匡南等[2]基于logistic回归模型的优点,结合变量筛选的目的将Lasso-logistic模型应用于信用风险的评估取得较优预测结果。
通过梳理信用风险评估方面文章[3-5]可以发现,对于企业信用评估,由于其指标往往具有强相关性,在建模之前需要进行指标筛选。然而LASSO(Least Absolute Shrinkage and Selection Operator)就是一种变量选择和参数估计相结合的方法。它的原理是在模型的损失函数上增加一个正则化项,通过对模型系数的压缩,实现控制模型复杂度的效果。由于其特殊的性质,方法兼具岭回归和子集选择的优点。因此,采用具有变量筛选功能的Lasso-logistic模型作为子模型再对不同子模型的预测概率进行集成,与不同的单个模型进行对比,研究模型的预测效果。
预测制造业上市公司信用违约情况的目标是提前预知哪些企业更倾向于违约,发生违约的企业往往占少数,因此上市公司财务数据呈现出类别不平衡的结构。常用的信用风险评估模型Logistic回归等模型的基本假设是各个类别数目分布比例大致均等,因此,对不平衡数据的处理也显得尤为重要。建立在不平衡数据集上的机器学习算法性能引起了越来越多学者的高度关注。其中最受关注的方法分为数据和算法层面的处理,数据层面即从抽样方法上进行处理,通常采用欠采样(Under Sampling)和过采样(Over Sampling)的方法。Under Sampling顾名思义就是减少数据集中多数类的样本来平衡分布;Over Sampling是对数据集中的少数类样本进行重复抽样至数据平衡。然而,前者损失了大部分的样本信息,后者又容易造成模型过拟合。基于过采样方法的弊端,Chawla等[6]提出基于k近邻,利用线性插值法合成少数类样本数据的SMOTE(Synthetic Minority Over Sampling Technique)方法。现今,研究者们仍然对“数据”层面处理不平衡的基础算法进行不断改进。陈启伟等[7]从欠抽样方法入手,在多数类样本中反复抽取和少数类样本量相等的子样本组成多个子数据集,对多个数据子集建立模型并采用简单平均集成得到较好的预测性能。
通过梳理文献,还未有文章结合lasso指标筛选和不平衡处理进行集成的信用违约测度方法,鉴于此,选择沪深A股上市的2 042家制造业上市公司在偿债能力、盈利能力、营运能力、发展能力、现金流能力5个方面22个财务指标数据,先通过计算WOE和IV值,剔除风险识别能力和稳定性较差的变量,再同时从“数据”的修正和“算法”的改进入手,将改进的Batch-US-LLR模型与单模型进行对比并研究模型在不平衡制造业上市公司财务数据上的违约预测效果。
2 方法与模型
2.1 Lasso-logistic (LLR)模型
Batch-US-LLR模型的算法设计如下:
Lasso方法的本质是在损失函数上增加正则化项,在进行参数估计时,系数会被压缩,部分系数甚至可以压缩到0来实现特征选择。对于信用违约预测,其因变量是否违约属于二分类变量,因而应该在Logistic模型损失函数增加lasso正则项即使用Lasso-logistic模型。
假设样本数据为(xi,yi)i=1,2,…,n,其中xi=(xi1,xi2,…,xip)和yi分别是预测变量和目标变量,并且是二元离散数据变量取值为0,1,则logistic回归模型的条件概率为
(1)
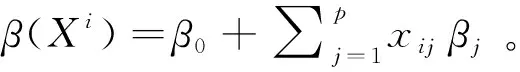
(2)
式(2)中为
Lasso-logistic模型中参数估计写成如式(3)的形式:
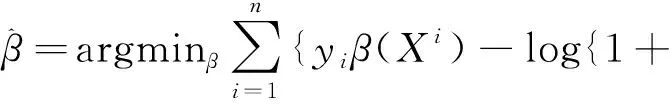
(3)
2.2 Batch-US-LLR模型
Batch-US-LLR模型的算法设计如下:
算法:Batch-US-LLR集成模型(图1)。
输入:数据集D={(xi,yi),i=1,2,…,N,yi∈{0,1}},多数类样本数记Nm,稀有类样本记Ns,Nm+Ns=N,采样率记为SR,k为lasso-logistic子模型个数。
算法步骤:
(1) 将数据集中多数类样本和少数类样本分别记为Sm和Ss,k=ceil(Sm/Ss);
(2) forj=1,2,…,kdo
(3) 从1~(Ns-i+1)中随机抽样,取出对应序号的样本x′;
(4) 在类0样本中取出所选样本Ss=Ss-x′;
(7) end for;
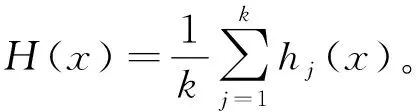
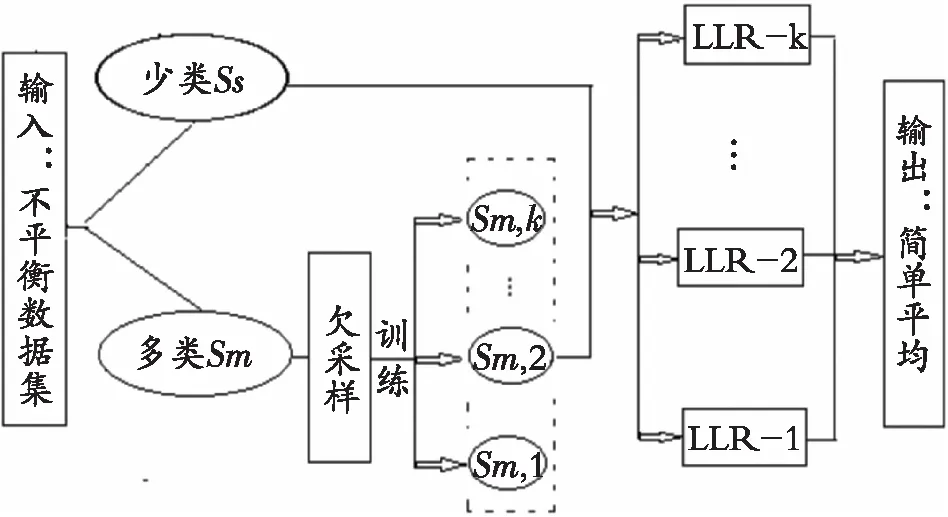
图1 Batch-US-LLR集成模型框架Fig. 1 Batch-US-LLR integrated model structure
3 研究设计
3.1 指标选取及解释
选取我国上海证交所和深圳证交所所有A股市场上的制造业上市企业作为研究样本。由于ST、*ST、S*ST企业都为特殊处理的公司(下文简称ST类),ST股为经营连续2 a亏损的公司;*ST股为经营连续3 a亏损、有退市预警的公司,S*ST为连续3 a亏损、有退市预警且未完成股改的公司,一般ST类企业财务风险较为严重,因此将其作为违约对照组,非ST类的公司作为正常组样本。
企业的财务状况和经营状况体现在企业对债务的偿付能力、资产运营管理能力以及企业的盈利水平、企业发展潜力等多个方面,因此,从国泰安数据库(http://www.gtarsc.com/),选取了2017-06-30—2018-06-30的2 394家制造业上市公司的偿债能力、盈利能力、营运能力、发展能力、现金流能力5个方面共24个财务指标数据。其中,根据统计的样本数据的某些会计年度数据的缺失情况,对每个方面财务指标数据中样本会计年度缺失值大于20%的指标直接删除,由于不考虑风险积累的时间序列影响,故对其剩余取值做均值处理汇总成截面数据,最终选取2 042家制造业上市公司21个财务指标作为自变量,按其是否违约作为因变量。具体变量说明如表1所示。
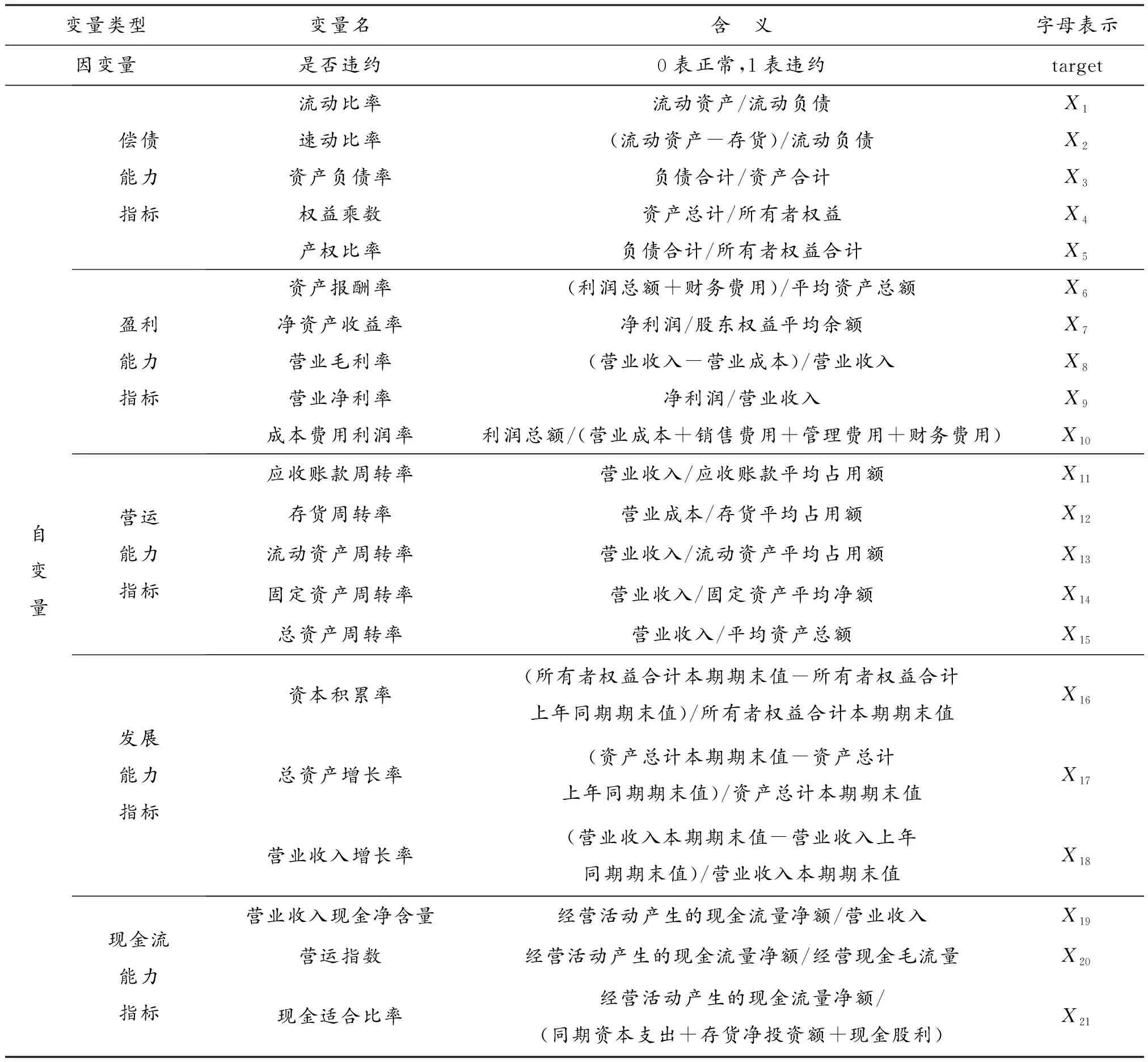
表1 变量说明表Table 1 Variable description
对数据做基础的描述性统计发现,数据存在明显的异常值,使用R语言编写盖帽法函数对数据进行修正。
3.2 变量检验及筛选
3.2.1 变量统计检验
要研究预测变量与目标变量之间的关联,由于目标变量是分类变量,因此采用方差分析查看变量是否通过检验。方差分析结果见表2,除了变量X11,X12,X14,X20没有通过检验,说明4个变量对企业是否违约影响不大,考虑剔除。
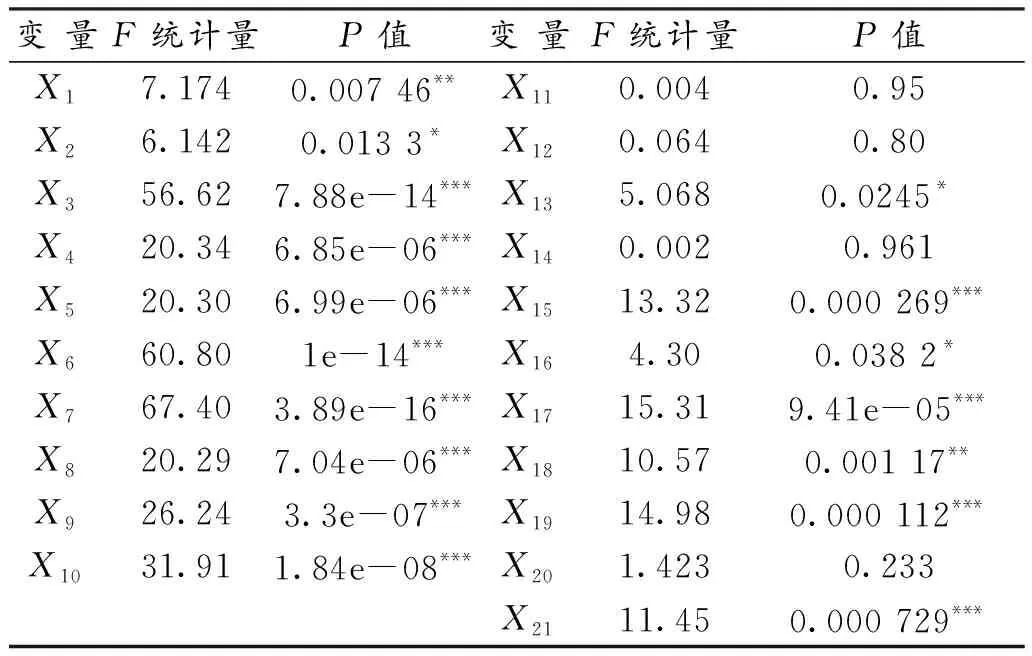
表2 各变量与是否违约的方差分析检验表Table 2 Variance analysis test of each variable and whether default
3.2.2 变量初筛
根据所取得的上市公司财务指标数据,并根据所计算的指标的WOE变动和IV值结合变量坏账率图形,进行变量初筛。WOE(Weight Of Evidence)含义为证据权重。IV(Information Value)即为信息价值,衡量自变量对因变量的影响能力。
经验证,所有变量的IV值见表3,剔除IV值小于0.3的变量,其余自变量对是否违约均产生影响。结合WOE趋势不符的变量共有:X11,X12,X20。考虑变量的统计检验将X14剔除。对剩余变量进一步检查变量相关性,做变量相关图2,可见部分变量间存在明显的相关性,有必要对其进行变量筛选,因此选择Lasso-logistic模型作子模型。
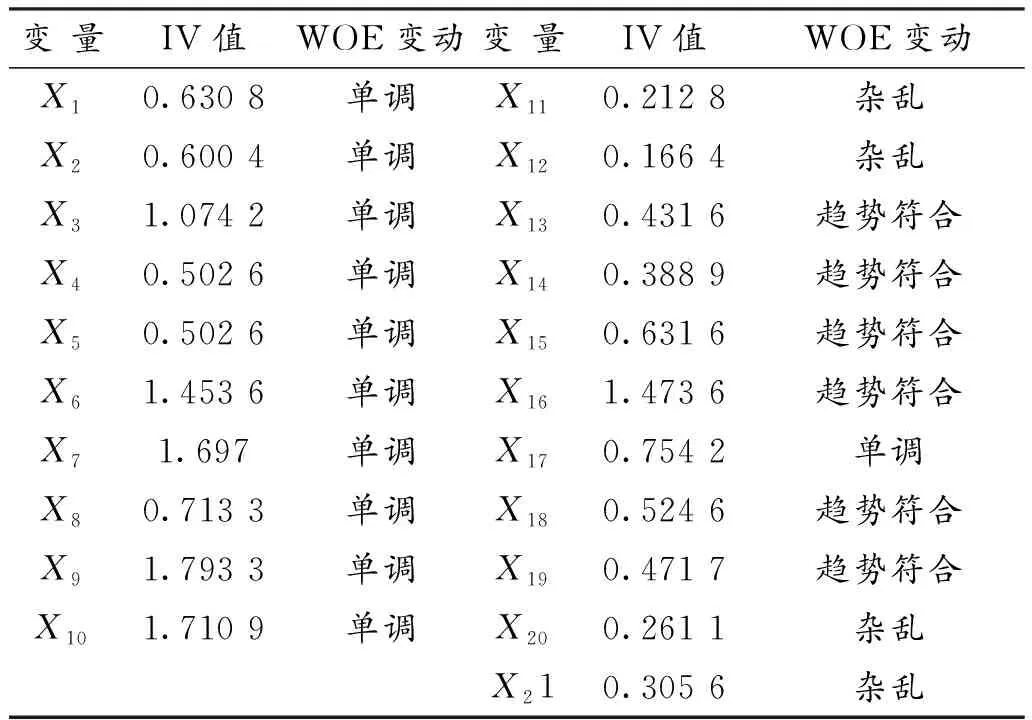
表3 变量IV值和WOE变动Table 3 IV and WOE of variables
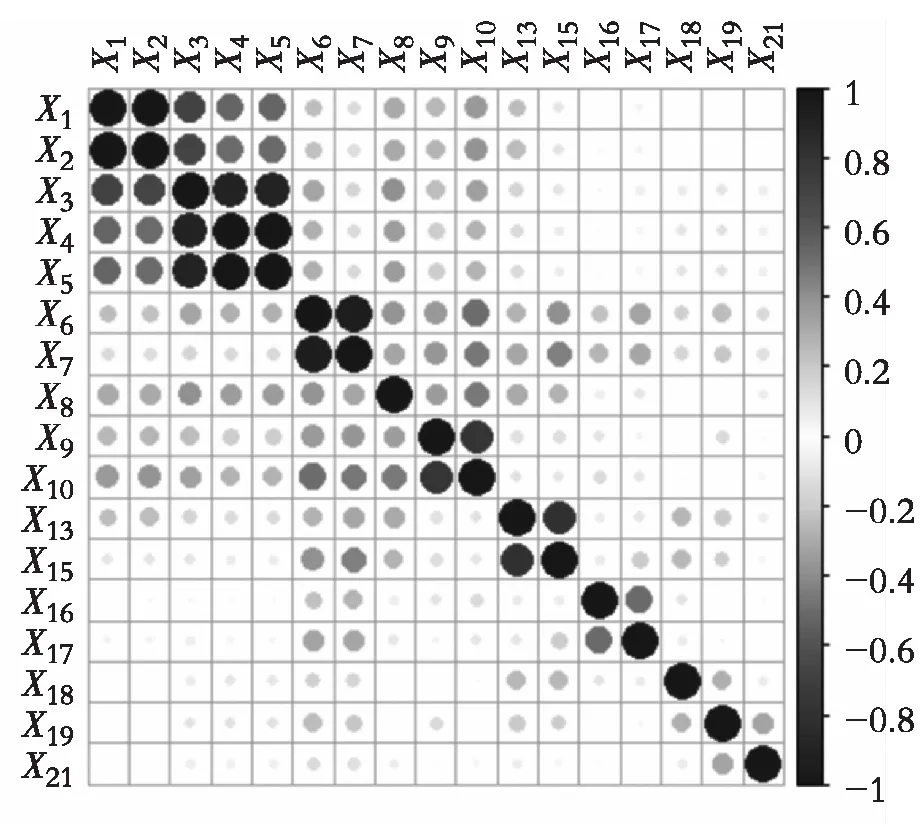
图2 变量相关图Fig. 2 Variable correlation
4 模型建立与评价
由于违约事件的发生是少量的,获取的 2 042 家制造业上市公司的财务指标数据正负样本占比分别为96%和4%,数据存在严重不均衡,传统的基于准确率的模型评价指标已经不再适用。基于此,选取ROC曲线下面积AUC来评价模型的预测性能,KS值来评价模型风控能力。
由于采用的lasso-logistic基分类器具有变量筛选功能,因此将初筛后的全部变量纳入模型。为了更好地进行模型评估将数据按7∶3的比例划分为训练集和测试集。对处理后的数据建立5种单一模型:BP神经网络;AdaBoost;随机森林;logistic回归;Lasso-logistic 和提出的Batch-US-LLR集成模型进行对比分析。
由表4可得,单一模型中Lasso-logistic模型的AUC值达0.921 6,而使用Batch-US-LLR集成模型在所有对比模型中的AUC最高达到0.927 3,模型精度提升了0.57%,KS值约为0.77说明模型将“好”、“坏”客户区分的程度也很高,使用模型对正负样本精度和稳定性的测度在6个模型中最好。
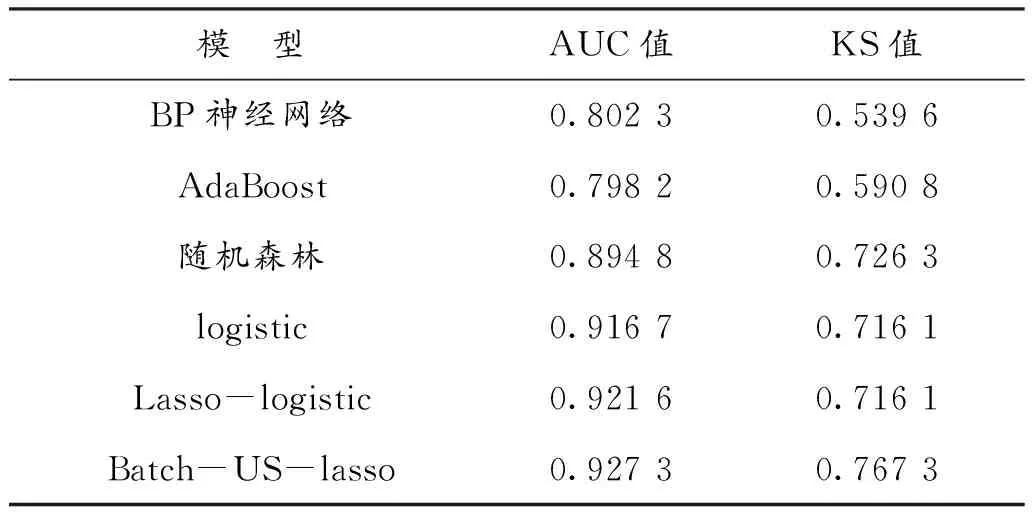
表4 模型结果汇总表Table 4 Summary of model result
5 结 论
5.1 变量筛选方面
研究并未摒弃传统的信用风险评分卡模型,而是采用传统A卡(申请评分卡)中变量筛选方法,通过计算WOE和IV的值得到较高风险识别能力和稳定性的变量纳入模型。以X3(资产负债率)、X6(资产报酬率),X9(营业净利率)为例,用R Studio做企业坏账率图可图3、图4、图5。对于制造业来说,其资金占用量大,随着企业资产负债率的上升,企业负担较重,往往伴随着企业违约率的上升。随着营业资产报酬率的上升,营业净利率的上升,企业坏账率逐步降低,Ⅳ值分别达到1.074 2、1.453 6、1.793 3,说明这些变量对企业是否违约有着重要影响。
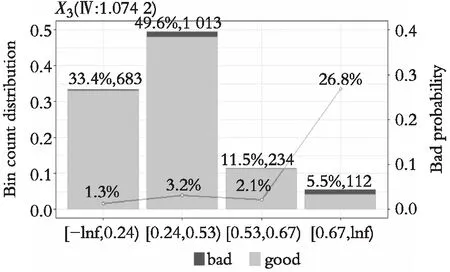
图3 资产负债率和企业违约与否的坏账率图Fig. 3 Bad debt ratio chart of asset liability ratio and enterprise defaults or not
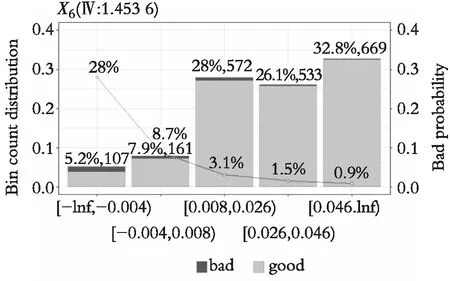
图4 资产报酬率和企业违约与否的坏账率图Fig. 4 Bad debt ratio chart of return on assets and enterprise defaults or not
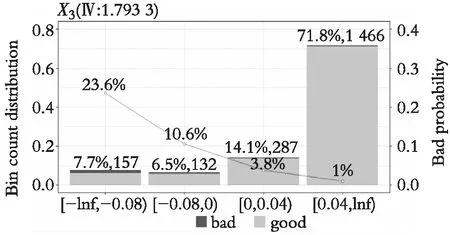
图5 营业净利润率和企业违约与否的坏账率图Fig. 5 Bad debt rate chart of operating net profit margin and enterprise defaults or not
结合表2和表3,除去应收账款周转率、存货周转率、固定资产周转率和营运指数外的17个财务指标均对是否违约有显著影响。因此,建议企业关注反映企业盈利能力和偿债能力的财务指标,这些指标能够帮助银行等贷款机构提醒个别制造业企业尽早发现风险隐患,帮助银行及其他金融机构制定预警机制,及时降低信用风险发生的概率。
5.2 模型方面
对制造业上市公司的财务指标不平衡数据,分别对Batch-US改进后的模型和未改进的单个模型进行对比,由表4可以看出,基于Batch-US-LLR集成的模型结果明显优于没有处理不平衡数据的单个分类器建模结果。由于在互联网风控模型中千分之一的精度改变带来的影响也是巨大的,可见对不平衡数据的处理具有一定意义。结合模型和实际企业信用评估对评分模型的实际需求,进一步将模型输出的概率结果用坏账率表和K-S 值分析,证实了Batch-US-LLR模型在实际业务中的可行性和有效性。因此,模型能够帮助金融贷款机构识别更多的违约企业,银行或其他金融贷款机构在制定信用风险预警机制时可以结合此模型,注意处理数据呈现的明显不平衡问题,并且对于企业财务数据指标之间相关性较强的问题采取指标筛选处理,并探索子模型集成的方法来降低银行等金融机构可能存在的信用违约风险。
