基于人脸图像和脑电的连续情绪识别方法①
2021-02-23李瑞新蔡兆信王冰冰潘家辉
李瑞新,蔡兆信,王冰冰,潘家辉
(华南师范大学 软件学院,佛山 528225)
1 引言
1.1 研究背景
情绪(emotion)是人对客观事物的态度体验和相应的行为反映[1],是一种由感觉、思想与行为综合而成的复杂的心理和生理状态,它与大脑许多内部和外部活动相关联,在生活中的各个方面都起重要作用.情绪识别在心理学研究、安全驾驶、犯罪测谎、远程教育、人机交互、数字医疗等领域有着重要的影响和需求.情绪识别技术涵盖人工智能、自然语言处理、认知与社会科学等领域的方法和技术[2].但是,目前情绪识别的量化精度不高,又囿于被试生理数据的缺乏以及情绪的主观性,目前情绪识别在技术层面仍然需要克服数据集小、跨被试性能差等问题.基于此背景,本文采用Posner 提出的情绪的二维模型[3]量化情绪,将情绪分为效价(valence)和唤醒度(arousal)两个维度,每个维度的分数范围为1–9.同时,本文基于人脸图像和脑电技术,提出了多个情绪识别模型.
1.2 研究现状
(1)人脸表情识别的相关研究
人脸的表情是一种重要的情绪交流方式,1971年,Ekman 等[4]首次将表情划分为6 种基本形式:悲伤(sad)、高兴(happy)、恐惧(fear)、厌恶(disgust)、惊讶(surprise)和愤怒(angry).而人脸表情识别(Facial Expression Recognition,FER)技术则将生理学、心理学、图像处理、机器视觉 与模式识别等研究领域进行交叉与融合,是近年来模式识别与人工智能领域研究的一个热点问题[5].传统的人脸表情识别方法重视特征提取和表情分类.2016年,Meng 等[6]将Roweis 研究团队提出的LLE 方法[7]与神经网络进行结合,提出了LLENET 特征提取算法,显著提高了算法的性能.2009年,朱明旱等[8]结合二维Fisher 线性判别分析(Two Dimensional Fisher Linear discriminant Analysis,2DFLA)与局部保持投影算法识别表情,显著提升了识别效率.基于深度学习的人脸表情识别方法能够同时提取特征并分类表情.Mollahosseini 等[9]将AlexNet与GoogleNet 模型结合,构建了一个7 层的卷积神经网络(Convolutional Neural Networks,CNN)用于人脸表情识别,得到了较好的识别效果.目前人脸表情识别的研究有如下难点:①表情量化方式不精确;②表情适用范围小;③被试数据量不足,难以训练更复杂的深度学习模型.
(2)脑电情绪识别的相关研究
相较于人脸表情,脑电信号具有的更高的客观性,难以伪装.因此,脑电信号在情绪识别领域备受关注.现有的脑电情绪识别技术大多针对时域特征、频域特征、时频域特征和空间域特征4 个方向进行特征值挖掘[10],以达到更好的分类效果.1924年,St.Louis 等[11]首次提出在实践中应用脑电技术,后来该技术被应用于情绪识别领域.2009年,Yazdani 等[12]利用贝叶斯线性判别分析,基于脑电模态对喜悦、愤怒、厌恶、悲伤、惊讶、恐惧等6 种情绪进行分类,实验表明准确率超过80%.2015年,Georgieva 等[13]采用6 种无监督算法构建被试内和被试间的情绪模型,实验表明模糊C 均值据类算法的效果最佳.2020年,郑伟龙等[14]用异质迁移学习构建跨被试脑电情感模型,利用眼动信号作为量化被试间域差异的标准,初步实现了跨被试情绪识别,准确率达到69.72%.目前基于脑电的情绪识别研究有如下难点:①脑电信号具有非平稳性,难以挖掘合适的特征值;②脑电信号个体差异性显著,大多模型为被试依赖型模型,难以在保证准确率的情况下实现跨被试型情绪识别模型.
(3)多模态情绪信息融合的相关研究
基于不同的生理模态,情绪识别的研究方法有很多.但是,单一模态的情绪识别往往准确率比多模态情绪识别低.正如前文所述,人脸表情容易伪装,脑电情绪的跨被试性能差,各个生理模态的信息有不同的优缺点.因此,近年来,针对不同层次的模态信息融合算法也在快速发展中.通过融合多种互补的模态生理信息,能够切实提高情绪识别的准确率和适用范围.
针对以上研究现状,本文的工作是:①对于人脸表情识别,利用迁移学习技术训练多任务卷积神经网络模型,以避免因数据量少而导致的过拟合现象.②对于脑电情绪识别,本文提出了两种互相独立的方法,第一种是准确率较高的被试依赖型模型—支持向量机(Support Vector Machine,SVM);第二种是适用范围广的跨被试型模型—长短时记忆网络(Long Short-Term Memory,LSTM)网络.③融合人脸图像模态和脑电信号模态的决策层信息(情绪得分),以提高情绪识别的准确率.其中,针对被试依赖型模型,我们将SVM 和CNN 子分类器进行模态融合,而对于基于脑电信号的跨被试模型LSTM,则作为单模态情绪识别模型,独立进行实验.
2 基于人脸图像的情绪识别
2.1 基于人脸图像识别表情的基本流程
在基于人脸图像识别表情的模块中,通过系统调用摄像头以4 Hz 的频率对视频进行图像数据采样,使用文献[15]的基于Haar 特征值的自适应增强(Adaptive Boost,AdaBoost)算法[16]检测人脸,并将提取的人脸图像信息转换为宽和高皆为48 像素的矩阵,将该矩阵输入至多任务卷积神经网络(Multi-Task Convolutional Neural Networks,MTCNN)[16]中,以预测人脸表情的效价和唤醒度得分.其系统运行流程如图1所示.

图1 人脸表情识别系统运行流程
2.2 人脸检测
本文采用基于Haar 特征值的AdaBoost 模型进行人脸检测.对于AdaBoost 算法而言,用式(1)假定一个训练数据集T,用式(2)假定权值系数Di.

其中,xi∈X⊆Rn为实例,X是实例空间,Y是标记集合.最终分类器G(x)由多个弱分类器线性组合而成.弱分类器yi∈Y={−1,+1} 的分类误差率em由式(3)表示,弱分类器Gm(x)的系数αm由式(4)表示.

每次计算出更新的训练数据集的权值分布Dm+1如式(5)所示,权值向量中的每个权值由式(6)表示.式(6)中的Zm是规范化因子.

通过不断地训练,可以得到如式(8)所示的最终分类器.AdaBoost 算法执行流程如图2所示.

本文采用AdaBoost 算法在人脸检测及模态信息融合模块中进行分类预测.在人脸检测中,使用OpenCV开源框架中已训练的分类模型,该模型通过(*.xml)文件存储信息,是用于检测人脸及前额的AdaBoost 检测方法.
2.3 利用迁移学习技术训练CNN 人脸表情识别模型
(1)多任务卷积神经网络
我们利用迁移学习技术,训练一个多任务卷积神经网络来进行人脸图像的特征提取和特征分类.具体来说,训练网络的过程分为2 步.第1 步,先将网络在一个具有图像级别标注的大数据集(Fer2013)进行训练[17].第2 步,将模型所有卷积层参数固定,以相对比较小的学习率(0.001)在小数据集(我们的目标数据集的划分)上再进行二次训练(微调),这样才能完成模型的训练.
得到充分训练的CNN 模型之后.对于一个视频,在找出视频中的人脸之后,我们将多个人脸分别输入模型得到多个子结果,通过这些子结果的投票,我们得到这个视频的基于脸部的情绪结果(valence 和arousal的分类).
CNN 得到子结果的过程是通过神经网络的一个从输入端到输出端的前向传播.具体过程如下,对于一个48×48 的灰度图,首先被模型的3 个卷积层提取图像特征,第1 个卷积层为32 个3×3×1 的卷积核.第2 个卷积层是具有32 个大小为3×3×32 的核.第3 个卷积层有64 个大小为3×3×32 的核.提取出来的特征经过铺平后送到第4 层与64 个神经元完全连接.所有卷积层和全连接层,都应用ReLU 激活函数[18].网络随后分为两个分支预测任务.本文所提出的卷积神经网络结构如图3所示.

图2 AdaBoost 算法执行流程

图3 多任务卷积神经网络模型,其中“DO”为CNN 的dropout 层
(2)基于卷积神经网络的情绪回归计算
第一个分支学习计算效价得分,它包含两个全连接的大小为64 和1 的层.然后将输出输入到Sigmoid函数中,并最大限度地减少交叉熵损失L1:
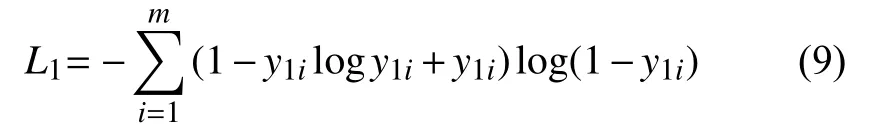
其中,y1i表示第i个样本效价的真实标签 (ground-truth labels),表示第i个样本对应于情绪效价的模型输出,m表示训练样本的大小.第二个分支是针对唤醒度进行预测的,它包含两个全连接i的大小为64 和1 的层.输出被馈送到Sigmoid 函数,我们再次最小化交叉熵损失L2:

其中,y2i表示第i个样本中唤醒度的真实标签,表示第i个样本对应于唤醒度的模型输出,m表示训练样本的大小.最终,我们最小化L1和L2的联合损失.

其中,αp是的线性权重,也是模型需要确定的超参数.如果我们将第二个权重设置为0,模型将退化为传统的单任务学习方法.在模型充分训练完之后,我们可通过式(12)从网络的输出值Sface中得到情绪效价和唤醒度分类的结果如下:

例如,如果上分支效价得分的输出为Sface=0.8,那么认为它对应的效价结果属于high 一类.对于表情数据的回归计算,本文的损失函数不再是交叉熵,而是均方差误差.然后分别预测效价和唤醒度的数值连续大小.
3 基于脑电信号的情绪识别
3.1 基于脑电信号识别情绪的基本流程
在基于脑电信号识别情绪模块中,使用Emotiv Eopc+的脑机接口采集生理数据,并利用小波变换提取特征值,选取好特征值后再利用SVM 或者LSTM 识别情绪.其中,基于SVM 的情绪识别方法为被试依赖型模型,基于LSTM 的情绪识别方法为跨被试型模型.基于脑电信号的情绪识别系统运行流程如图4所示.

图4 脑电情绪识别系统运行流程
3.2 利用小波变换提取脑电信号特征值
在特征值提取与选取阶段,利用小波变换从原始EEG 数据中获得功率谱密度(Power Spectral Density,PSD)特征.小波变换适用于多尺度分析,这意味着可以使用不同的频率和时间尺度检查信号.本文采用Daubechies 的小波变换系数[19]进行特征提取,小波变换公式如下所示:

其中,ωf(s,τ)表示一维连续小波变换,φ表示小波母函数,s表示尺度参数,t为平移参数.而连续小波逆变换的公式如下所示:

在提取特征值后,情绪识别模型分为两种情况:第一种为一个模型仅适用于一个被试,即模型依赖于被试(subject dependence).此时训练数据集和测试数据集为同源数据,来自于同样的被试,没有域差异.第二种则为一个模型适用于所有被试,即模型不依赖于被试(subject independence).此时训练数据集和测试数据集来自于完全不同的被试,有一定的域差异.针对情况一,为构建被试依赖型模型(subject dependent models),使用递归特征消除算法(Recursive Feature Elimination,RFE)进一步选择了提取的特征,并将所选特征再通过SVM 进行分类以获得基于脑电信号的情绪状态.针对情况二,为构建跨被试型模型(cross-subject models),可以通过构建长度为10 s 的时序特征,将所有特征利用长短时记忆网络模型模型进行预测,从而跨被试预测脑电情绪状态.
3.3 利用SVM 构建被试依赖型脑电情绪识别模型
本文的算法使用14 个通道(AF3,F3,F7,FC5,T7,P7,O1,AF4,F4,F8,FC6,T8,P8,O2)进行特征提取.使用的5 个频率波段分别为theta (4 Hz<f<8 Hz)、slow alpha (8 Hz<f<10 Hz)、alpha (10 Hz<f<12 Hz)、beta(12 Hz<f<30 Hz)以及gamma (30 Hz<f<45 Hz),共有14×5=70 个特征.
在第二步分类中,在最终的特征被选择之后,本文用一个应用于高斯核的SVM 进行分类,且该SVM 的惩罚系数C=1.0 .当惩罚系数C=1.0时该模型能够达到较好的效果,弱数值过大,则易导致过拟合,若数值过小则容易欠拟合.为训练模型,我们去除了权重最低的10%的特征数据,并使用10 倍交叉验证分割训练数据集[20].训练完模型之后,对于不同的任务(预测valence 和arousal),我们分别用不同的SVM 进行预测.每个对应的SVM 预测出得分SEEG.我们再根据这个得分,通过式(13)获得基于脑电波的结果rEEG.

3.4 利用LSTM 构建跨被试型脑电情绪识别模型
本文提出利用LSTM 构建跨被试脑电情绪识别模型.该过程分为两步,第1 步先进行构造时序特征,第2 步再使用LSTM 进行回归预测.
在构建跨被试模型时所有特征值仍然如前文所述,但选取方式有了变化.在构造时序特征时,以10 s 作为一个样本,以50%的重叠率采样.并且,以每一秒作为一个时间单元,比如说对于离线实验,一秒有85 个特征,那么本文的一个样本是一个二维矩阵第1 维是10,而第2 维是85.而不是一个大小为850 的一维向量.样本的构造跟LSTM 的结构有关.
在使用LSTM 进行预测时,网络首先是两层LSTM层,跟着一个全连接层,然后接着是输出层.第一个LSTM 层由10 个LSTM 单元(LSTM cell)组成,每个单元包含128 个神经元.第二层LSTM 层由10 个LSTM单元(LSTM cell)组成,每个单元包含64 个神经元.全连接层包含54 个神经元.输出层由2 个神经元构成代表情绪的效价得分和唤醒度得分.每个层都应用了0.5 的dropout.每层都应用了ReLU 激活函数以及在每层之间,本文都进行了数据归一化.采用均方差作为网络损失函数.
4 融合双模态决策层信息的情绪识别
4.1 融合双模态决策层信息的算法流程
本系统通过调用摄像头和脑机接口设备采集两个模态的生理数据,并在各模态情绪识别模型的决策层进行信息融合,以提高情绪识别准确率.图5为本系统进行双模态情绪识别的运行流程图.首先对采集的人脸图像信息和脑电信息进行预处理,并提取特征值,然后分模块各自进行情绪量化计算,并最终融合两个模态的情绪得分.

图5 双模态情绪识别系统运行流程
4.2 利用枚举权重算法融合信息
在获取了基于脑电波和人脸表情2 个分类器给出的情绪得分之后,通过枚举2 个单模态分类器输出的线性组合权重,来找到一个参数k,使得两个模态情绪输出的线性组合在训练集上取得最好的表现:对于分类,找出最大准确率;对于回归,找出真实值和预测值的最小绝对值.具体来说,先通过式(16)来进行融合输出情绪得分,并通过式(17)输出结果.问题的关键在于找出合适的k,以0.01 的步长枚举k,并且每一次枚举,都计算融合后的准确率,选取一个k,使得融合后在训练集上准确率最大.
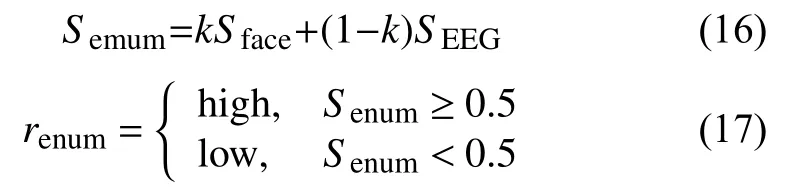
其中,renum代表量化的情绪分数融合后预测的分类结果(high 或low)而Senum则代表融合后预测的连续值结果,Sface和SEEG分别代表人脸表情和脑电波的输出,而k代表人脸表情的重要程度,相应地,(1–k)代表脑电波的重要程度.我们应用这个方法在两个不同的任务(效价和唤醒度)上,也就是说,两个任务的k是不同的.
4.3 利用自适应增强算法融合信息
对于第二种方法,我们使用AdaBoost 技术,将两个分类器作为AdaBoost 的子分类器进行融合.该方法的目标是为每一个子分类器寻找wj(j=1,2,···,n)和获得最终的输出,如式(18),式(19).
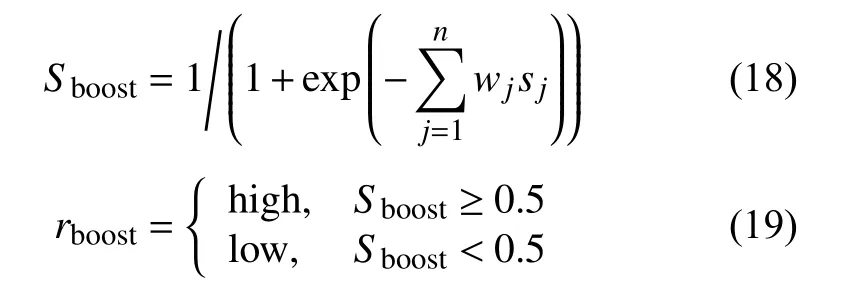
其中,rboost代表自适应增强融合方法的预测的结果(high 或low),sj∈{−1,1}(j=1,2,···,n)代表对应的子分类器的输出.比如说,S1是基于脑电的情绪分类器的输出而S2代表基于人脸图像的情绪分类器的输出.而要获取wj(j=1,2,···,n)的方法如下所述:对于一个含m个样本的训练集,我们先用s(xi)j∈{−1,1}表示第j个分类器对于第i个样本的输出,用yi表示第i个样本的真实标签.我们首先用式(20)初始化每个样本的训练权重:

其中,αi代表第i个样本的权重系数.训练权重体现在训练数据的时候,如果用到当前数据点,那么数据点的数据要先乘以这个权重系数.然后进行子分类器的训练如之前所述,训练完之后用式(21)计算错误率 εj.

其中,ti通过式(22)确定.

最终,用式(23)得到需要计算的子分类器权重:

随后,还需根据式(24)更新每个数据点的权重系数,用于下一个分类器更加针对性地训练.

与枚举权重融合方法相同,我们应用这个方法在两个不同的任务(效价和唤醒度)中,为两个任务训练出不同的参数.
5 实验设置与结果分析
5.1 离线实验
(1)被试依赖型模型的离线实验结果
本实验选用的数据集为DEAP 数据集来验证被试依赖型模型的有效性.图6是4 种被试依赖型模型在DEAP 数据集上的表现.根据实验结果可知,人脸表情识别的准确率较高,但在部分被试上仍表现出较低的准确率,其分别为:被试1、被试3、被试5、被试11、被试12.各模型的平均最高准确率如表1所示.
(2)被试依赖型模型实验的显著性分析
对被试依赖型模型进行数据的显著性检验:首先对4 种方法的结果(EEG,脸部图像,枚举权重融合方法和自适应增强融合方法)进行正态分布检验(normality test),正态分布检测的结果小于0.05,因而认为其符合正态分布.对符合正态分布的数据接着进行t方检验,t方检验的P值小于0.05,因而可以认为有显著的差异;而对于不符合正态分布的数据,则进行Nemenyi 检验,其P值小于0.05,因而也可以认为其有显著差异.进一步地说,显著的差异意味着准确率的显著提升.在DEAP数据集的valence 空间和arousal 空间中,各个融合方法之间未体现出显著性差异.
(3)跨被试情绪识别模型的实验与分析
对于跨被试情绪识别模型—基于LSTM 识别脑电情绪模型,利用MAHNOB-HCI 数据集训练并验证.该数据集采集自30 名被试,此处我们仅使用脑电数据集,并对该模型进行了如下两组实验:验证数据与训练数据部分同源实验、验证数据与训练数据完全非同源实验.记验证数据与训练数据部分同源组为A 组,验证数据与训练数据完全非同源实验为B 组.

图6 被试依赖型模型在DEAP 数据集上的准确率

表1 被试依赖型模型在DEAP 数据集上的准确率(%)
当验证数据与训练数据部分同源时,我们对数据集进行划分:选取1 至23 号被试的数据,1 号至20 号被试的数据作为训练集,21 号至23 号被试作为验证集.当已训练的模型预测1 至23 号被试的数据时,模型在valence 维度的平均准确率为78.56%,回召率为68.18%;而模型在arousal 维度的平均准确率为77.22%,回召率为69.28%.
当验证数据与训练数据完全非同源时,即我们使用被试1 至20 号的数据训练模型,而模型却预测21 至30 号的数据.最终模型在效价维度的平均准确率为51.70%,回召率为47.13%;而模型在唤醒度维度的平均准确率为58.65%,回召率为33.62%.
关于跨被试模型情绪识别的损失函数最终值如表2所示(表中loss 值对应实验组的训练损失函数,val_loss值代表实验组的验证损失函数);而关于跨被试模型情绪识别的准确率、回召率和均方根误差(Root Mean Square Error,RMSE)如表3所示.

表2 跨被试模型在MAHBON-HCI 数据集上的损失函数最终值
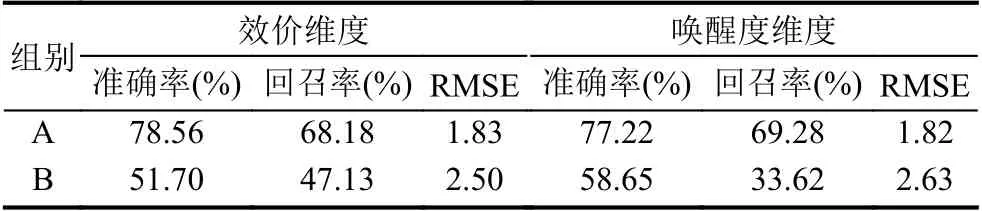
表3 跨被试模型在MAHBON-HCI 数据集上的情绪识别准确率和回召率
由此可见,虽然当模型预测非同源数据时准确率和回召率均有下降,损失函数最终值较高,但在面对预测连续情绪这种较为复杂多样的情绪的情况下仍能保持超过50%的准确率,情绪识别性能具有一定的稳定性.
(4)模型比较与分析
情绪识别相关研究有很多.本文使用两种信息融合算法,将双模态情绪识别信息融合,在唤醒度和效价维度平均准确率分别可以达到74.23%和80.30%.而本文提出的基于脑电的跨被试情绪识别模型,在使用MAHNOB-HCI 数据集验证的情况下,在唤醒度和效价维度最高准确率分别可以达到77.22%和78.56%.
2019年,Chao 等[21]基于脑电信号提出了多频段特征矩阵(Multiband Feature Map,MFM)和胶囊网络(Capsule Networks,CapsNet)模型,在使用DEAP 数据集验证的情况下,该模型在唤醒度和效价维度最高分别能够达到68.28%和66.73%的准确率.同年,Huang等[22]基于脑电和其他生理信号提出利用集成卷积神经网络(Ensemble Convolutional Neural Network,ECNN)识别情绪,该算法利用DEAP 数据集进行验证,对情绪的四分类准确率最高能够达到82.92%.2017年,Yin等[23]提出迁移特征递归消除跨被试模型,在使用DEAP数据集验证的情况下,在唤醒度和效价维度准确率分别达到78.67%和78.75%.
由此可见,本文提出的被试依赖型模型与其他模型相比同样具有较高的准确率.本文的跨被试模型与目前已有的跨被试情绪识别模型相比具有相近的准确率.
5.2 在线实验
(1)实验步骤
图7概述了本文实验的工作流程.一开始使用视频来诱发被试的情绪,同时记录面部图像和EEG 信号.在视频结束时,要求被试报告他们的效价维度(valence)和唤醒度(arousal)维度的分数,也即时情绪状态——模型要预测的目标.积极程度和唤醒程度的值为1 到9 之间的离散值.

图7 在线实验流程图
在线实验包含20 名被试(50%男性,50%女性),年龄范围从7 到75(平均值=34.15,标准差=22.14).实验过程如下,首先向被试介绍了valence 和arousal 的含义,接着被试观看视频并在每个视频结束时报告他们的情绪指标(valence 和arousal).在实验期间,被试坐在舒适的椅子上并被指示尽量避免眨眼或移动他们的身体.期间还进行了设备测试并校正了相机位置,以确保拍摄对象的面部出现在屏幕中央.
在进行实验之前需要选择用于诱发情绪的材料:从大量商业电影中手动选择40 个视频进行剪辑,再将他们分为2 部分用于采集训练时展示和采集测试数据中展示.每个部分包含20 个视频.影片剪辑的持续时间为69.00 到292.00 s (平均值=204.06,标准差=50.06).
在进行测试之前,首先需要数据来训练模型.因此,实验首先进行训练数据的收集.对于每个被试收集20 组实验的数据.在每组实验开始时,屏幕中央都会有10 秒倒计时,以吸引被试的注意力,并作为视频开始的提示.倒计时结束后,屏幕上开始播放电影视频用于诱发情绪.在此期间使用摄像机每秒收集4 个人脸图像,并使用Emotiv Epoc+移动设备每秒收集10 组EEG 信号.每个影片持续2~3 分钟.在每组试验结束时,情绪自评量表(Self-Assessment Manikins,SAM)[24]出现在屏幕中央,以收集被试的valence 和arousal 标签.指示被试填写整个表格并单击“提交”按钮以进行下一个试验.在两次连续的情绪恢复试验中,屏幕中央还有10 秒的倒计时.收集的数据(EEG 信号,面部图像和相应的化合价和唤醒标签)用于训练上述模型.
在测试阶段,每个被试进行20 组实验.每次实验的过程与训练阶段数据收集的过程类似.这里使用不同于训练采集数据时的视频对被试进行刺激,因为相同的视频会引发相同的生理状态从而导致无法判别生理状态是由情绪产生还是由视频产生.在每次试验结束时,使用4 种不同的检测器(面部表情检测器,EEG 检测器,枚举权重融合方法和自适应增强融合检测器)来得到结果.通过比较预测结果和真实标签来统计准确率.
(2)实验结果与显著性分析
图8展示了20 个实验对象的测试过程中准确率.

图8 在线实验不同对象各种方法准确率
表4展示了测试过程中各种方法的平均准确率.可以看到,除了在线实验中唤醒度维度中枚举权重融合方法相对于脑电情绪识别的准确率,所有融合方法的准确率都比单一模态高.并且,由于在线实验无法进行超参的调整,使得我们的模型普适性更高.在线实验中,我们只针对被试依赖型情绪识别模型进行实验.

表4 在线实验情绪识别准确率(%)
对于在线实验,在效价维度中,枚举权重融合方法相对于脸部图像的结果有显著差异P=0.026.而且自适应增强融合方法与人脸表情识别方法,在效价维度和唤醒维度均有显著性差异,效价维度中的P为0.026而唤醒度维度中的P为0.007.
5.3 改进情绪识别方法的有效性分析
(1)AdaBoost 融合双模态信息的有效性分析
为了融合双模态决策层信息,本文提出利用AdaBoost算法融合人脸表情识别分类器和脑电情绪识别分类器,以达到提高双模态情绪识别准确率的效果.实验表明,AdaBoost 算法的表现优于枚举权重.
AdaBoost 相对于枚举权重算法的优点主要体现在两点:①对多组训练数据集赋予不同权值;②子分类器权重精度更高.
本文所提的两种融合方法都是根据错误率的降低的思路来找到最优解的.枚举权重算法仅设置了一定精度的步长(本文为0.01),通过步长的增加,子分类器的权重遍历范围为[0,1]之间的数值,从而找到最低错误率对应的子分类器权重.而AdaBoost 算法首先赋予多组训练数据集默认权值,然后计算分类误差率,接着通过分类误差率计算子分类器的权重,最后更新训练数据集的权值分布,开始下一个分类误差率和子分类器权重的计算.在这个过程中,AdaBoost 算法要求计算规范化因子,并结合上一组的训练数据集权值、规范化银子、子分类器系数、ground-truth 标签和子分类器权重,计算下一组权值分布,使得该权值成为一个概率分布——对于重要的训练数据集,权值更高.这种方法区别于默认数据集为均匀权值分布的枚举权重算法,更符合实际中训练数据集是非均匀分布的这一情况.同时,在计算过程中,因为没有固定的步长.由此可得,子分类器的权重精度高于枚举权重算法.
(2)整体情绪识别算法复杂度分析
对于模型的算力需求和时间复杂度,整个算法的计算主要集中在卷积神经网络的部分,相比于卷积神经网络的参数,SVM 的参数极少.而实际上,我们的卷积神经网络共有831 074 个参数,使用GeForce GTX 950显卡中,进行一次单样本前向传播的时间是0.0647 s.对于基于LSTM 的脑电情绪识别模型,我们首先提取了脑电特征值,然后进行训练,每个epoch 训练时间均不超过3 s.
在模型融合方面,第一种枚举权重融合方法被许多多模态融合的研究广泛使用,该种方法比较简单但是其计算损失却随着模态的增多指数上升.因为第一种融合方法的复杂度为O(100mn),其中m是样本个数而n是模态个数.而第二种方法AdaBoost 的时间复杂度却是O(nm).也就是说第二种方法随着模态的增多计算损失的增加是线性的,因此在更多模态的条件下第二种融合方法更加适合.
(3)改进的情绪识别机制
在情绪识别的基准值方面,区别于传统的离散情绪识别方法,本文引入了连续情绪的概念,利用效价(valence)和唤醒度(arousal)两个维度的得分量化情绪,分数为整数,范围为[1,9].
在算法方面,本文重点介绍了两种方法,分别用于解决情绪识别的两个难题:准确率不高、跨被试性能差.
为了提高准确率,本文结合了人脸表情识别技术和脑电情绪识别技术.在人脸图像模态,我们采用端到端的多任务卷积神经网络,以计算效价和唤醒度得分.由于在通过被试获取数据集时,人脸图像往往数据集过少,因此利用迁移学习技术,首先用Fer2013 数据集预训练模型,然后再用采集的被试的数据微调模型.在脑电模态,我们利用了分类效果最好的支持向量机算法,根据效价和唤醒度得分是否大于5,来进行二分类.(若大于5 则为高分,否则属于低分).而为了融合两个模态的数据以进一步提高准确率,我们探究了枚举权重融合方法和AdaBoost 方法.通过在决策层的信息融合提高情绪识别准确率.实验表明,在融合更多模态数据的时候,AdaBoost 表现出优于枚举权重算法的性能.
然而,上述算法依然无法做到一个模型识别多个被试的情绪,而是针对每个被试训练一组特定的模型,由此本文称之为被试依赖型模型,其适用范围不广.
为了提高情绪识别的跨被试性能,本文在脑电模态提出了基于LSTM 的跨被试情绪识别方法.通过构建长短时记忆网络达到一个模型识别多个被试情绪的目的.实验表明,该方法具有一定的跨被试性能.
6 总结
本文基于人脸图像和脑电信号提出了多种情绪识别方法.本文使用情绪的二维模型量化情绪,根据连续情绪的效价和唤醒度两个维度的得分量化情绪.在人脸图像模态,本文利用迁移学习技术训练多任务卷积神经网络以识别人脸表情.在脑电信号模态,对于与训练数据同源的数据,本文采用支持向量机进行情绪识别;对于非同源数据,则采用长短时记忆网络.为了提高情绪识别的准确率,本文提出使用枚举权重模型和自适应增强模型融合人脸表情模型和脑电情绪模型的决策层信息以提高准确率.
本文进行的实验可验证各情绪识别方法的有效性.其中跨被试脑电情绪模型在预测非同源数据时准确率仍然高于传统算法,一定程度上保证了模型的稳定性和有效性.对于多模态情绪识别来说,本文的最终实验涵盖了情绪的效价和唤醒度,即愉悦度和强度.该量化情绪的指标有效、可行,且在识别较多种类情绪的情况下依然体现出了较高的准确率.下一步的工作即针对跨被试型脑电情绪识别模型进行优化,通过结合其他生理模态信息的方法,为不同被试源的情绪信息衡量域差异,并根据域差异来进一步利用迁移学习提升跨被试脑电情绪识别模型的性能.
