带标记音节的双向维汉神经机器翻译方法
2021-02-22艾山吾买尔斯拉吉艾合麦提如则麦麦提西热艾力海热拉刘文其吐尔根依布拉音汪烈军瓦依提阿不力孜
艾山·吾买尔,斯拉吉艾合麦提·如则麦麦提,西热艾力·海热拉,刘文其,吐尔根·依布拉音,汪烈军,瓦依提·阿不力孜
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.新疆大学 新疆多语种信息技术实验室,乌鲁木齐 830046
3.新疆大学 软件学院,乌鲁木齐 830091
机器翻译(Machine Translation,MT)是自然语言处理与人工智能的重要分支之一,是指使用机器自动地将一种自然语言序列X={x1,x2,…,xn}转化为具有相同语义的另一种自然语言序列Y={y1,y2,…,yn} 的过程。机器翻译可以分为基于规则的机器翻译、基于实例的机器翻译、基于统计的机器翻译和基于神经网络的机器翻译。
基于神经网络的机器翻译(Neural Machine Translation,NMT)[1-2]方法提出以来,不断地在多种语言的翻译任务中表现出优异的性能,逐渐成为目前主流的机器翻译方法。2014 年Sutskever等[1]首次提出神经网络机器翻译模型Seq2seq,使用端到端的编码-解码神经网络结构。针对长文本翻译质量不佳的问题,Bahdanau等[2]在编码-解码模型中引入注意力机制。2017年Facebook提出基于卷积神经网络(Convolutional Neural Network,CNN)的翻译模型[3],使得机器翻译的性能大幅提升。同年,Google提出一种仅使用注意力机制的简单网络架构Transformer[4],丢弃了复杂的循环和卷积神经网络结构,该模型不仅缩短了训练时间,还提高了机器翻译的准确度。自此,Transformer成为目前使用最广泛的机器翻译模型。
无论是统计机器翻译还是神经网络机器翻译,都依赖大规模的双语平行语料。虽然Transformer模型在资源丰富的语言上明显提升了翻译质量,但在维吾尔语等一系列小语种翻译任务中,存在平行语料不足的问题,难以满足Transformer 模型的训练需求。目前,由于维-汉平行语料较少,资源欠缺,已有的数据中部分数据的质量不高,因此在维吾尔语与汉语之间存在严重的资源不对称和不均衡问题。其次,维吾尔语是一种典型的黏着语,形态复杂,单词由词干和词缀组成,同一个词干与不同的词缀构成不同的新单词[5]。因此,维吾尔语的词汇量特别丰富,低频词较多,导致在训练过程中存在严重的数据稀疏问题和OOV(Out of Vocabulary)问题。
目前在机器翻译领域,对低资源NMT 的研究成为一个研究热点。针对资源匮乏问题,学者们提出了基于中间语言的方法和基于迁移学习的方法[6-7],展开了对无监督[8-9]、半监督[10]等机器翻译方法的研究。但是这些方法只在相似性较高的语言上取得了较好的效果,当语言之间相似性越低,翻译质量提升越不明显。针对数据稀疏与OOV问题,Luong等[11]提出先标记再利用词典对译文进行替换的方法。Sennrich等[12]采用字节对码化(Byte Pair Encoding,BPE)算法提取子词(sub-word)单元,完成对罕见词的拆分,模型编码和解码工作均在拆分后的子词上进行,该方法取得了很好的效果。Luong等[13]提出词语与字母混合模型。Costa-Jussà 等[14]提出一种字符级别的神经机器翻译方法。Li 等[15]提出“替换-翻译-恢复”的方法,并在汉-英翻译任务中得到了较好的效果。
从目前的维汉机器翻译状况来看,维汉机器翻译研究慢慢地从统计机器翻译方法完全转移到神经机器翻译方法上。哈里旦木等[16]对比了基于短语的统计机器翻译模型与6 种神经机器翻译模型在小规模平行语料上的表现。帕丽旦等[17]在统计机器翻译的基础上集成了RNN(Recurrent Neural Network)编码器-解码器,创建了新联合模型(PSMT+RNN)。张胜刚等[18]提出基于深层神经网络的字节对编码及单词的维汉机器翻译模型,使用LAU(Linear Associate Unit)代替GRU(Gated Recurrent Unit)网络,在一定程度上缓解了训练和优化模型难的问题。张金超等[19]提出多编码器-多解码器的大规模神经机器翻译模型,在翻译效果上超过基于短语的统计机器翻译模型和基本的NMT 翻译模型。朱顺乐[20]提出一种融合特征的汉维翻译策略,把多个特征通过一个对数线性模型组合,得到2 个BLEU 的提升。杨郑鑫等[21]提出一种利用伪语料对神经机器翻译模型进行增量训练的方法,有效提升神经机器翻译在维汉翻译任务上的质量。张新路等[22]通过集成策略和基于交叉熵的重排序方法将具有相反解码方向的翻译模型整合,在CWMT2015维汉平行语料上提高了4.36个BLEU值。
音节是人类听觉能够自然感受到的最小语音片段,在维吾尔语中,单词由具有一定语义信息的音节构成。为了研究音节对维汉机器翻译的影响,进一步提升维汉机器翻译的质量,本文从维吾尔语的音节特点考虑,把维吾尔语单词切分成音节,将汉语以单个字符划分,以更小粒度作为翻译单位。同时为了弥补音节产生的歧义问题,融入BME(Begin,Middle,End)标记思想,提出一种基于带标记音节的神经机器翻译方法。实验部分,用本文提出的方法与使用单词粒度和BPE 粒度的翻译方法在不同模型与不同规模的数据上分别进行了对比实验。实验结果表明,本文方法简单有效,较好地缓解了维-汉与汉-维机器翻译中的数据稀疏问题,并在翻译效果上超过基于单词粒度与BPE 粒度的神经机器翻译系统。
1 神经网络机器翻译
1.1 神经机器翻译模型
神经机器翻译模型由编码器-解码器组成,编码器把输入的源语言序列压缩到一个固定长度的上下文向量中[1],也被称作句子向量或内容向量。上下文向量被当作是输入序列的语义概要。
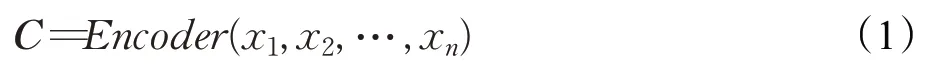
其中,C是被压缩的上下文向量,编码器Encoder可以是RNN或CNN等网络结构。
解码器的作用是根据编码器生成的上下文向量,生成目标语言句子的符号化表示。早期的研究仅使用解码器网络的最后一个状态作为下次解码的初始状态。

其中,C是编码器端传递的上下文向量,解码器Decoder同样可以是RNN 或CNN 网络结构,yt是Decoder第t时刻的输出,它依赖于Decoder之前的输出,最大化P(y)是模型最终目标。
早期的神经网络机器翻译模型在翻译比较短的句子时效果尚好,但在翻译长文本时质量严重下降[2]。这是因为固定长度的上下文向量无法记忆长句子的所有信息,当编码器处理输入序列,就会逐渐遗忘开始的部分。针对上述问题,Bahdanau等人[2]提出了注意力机制,改进了编码-解码模型在翻译长句时质量不高的缺陷。
假设当前解码器要输出的是Yt,且已知解码器上一时刻的隐藏层输出St-1。首先通过一个Fatt函数将St-1与编码器各时刻的隐藏层输出hi做相似度计算,得到源语言和目标语言之间的匹配度eti,计算公式如式(4)所示:

其次把计算结果通过一个SoftMax 函数来转化为概率,得到权重α,计算公式如式(5)所示:

最后对输入与α加权求和,计算出输入序列的表达Ct,并作为解码器当前的部分输入,从而生成Yt,计算公式如式(6)和(7)所示:
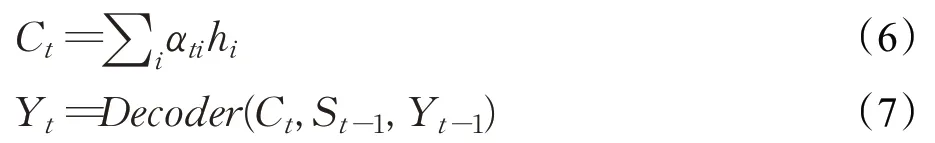
注意力网络通过将源语言句子的隐含状态与目标语言的隐含状态直接链接,缩短了源语言单词的信息传递到对应目标语言单词的路径,显著提高了模型的翻译质量。
1.2 完全注意力网络的神经机器翻译
完全注意力网络的神经机器翻译模型Transformer[4]也是由编码器和解码器组成。编码器由一个多头注意力网络和一个简单的全连接前馈神经网络组成,在这两个网络中间添加了一个残差连接,并进行层标准化操作。解码器是由两个多头注意力网络和一个全连接前馈网络组成,同样也用了残差连接以及层标准化操作。
缩放点积的注意力:Query-key 通过相似度计算得到权重,除以是为了减少计算量,然后用SoftMax函数对权重归一化,最后乘以V,作为注意力向量。计算数学公式如式(8):
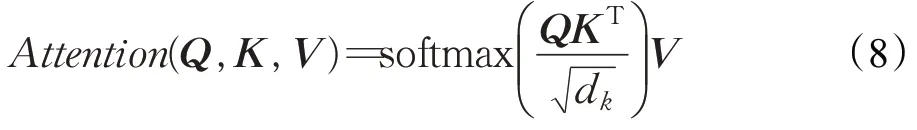
多头注意力机制:给定(Q,K,V),首先使用不同的线性映射分别将Q、K和V映射到不同的空间,然后使用不同的注意力网络计算得到不同空间的上下文向量,并将这些上下文向量拼接得到最后的输出。计算公式如式(9)和(10):

位置编码:Transformer 使用了位置编码的方法,将编码后的向量与词嵌入进行求和,加入了相对位置信息。计算公式如式(11)和(12):

其中,pos指词语在序列中的位置,pos在偶数位置时使用正弦编码,在奇数位置时使用余弦编码;dmodel是模型的维度。
在Transformer模型中最重要的部分是Self-Attention和Multi-Head Attention 架构。Transformer 模型在摒弃传统CNN 和RNN 的情况下,表现出更好的性能,可并行化的机制减少大量训练时间,同时提升翻译质量[4]。
2 音节粒度的维汉机器翻译
2.1 维吾尔语音节特点
维吾尔语属于黏着语,词语具有丰富的形态变化。维吾尔语共有32 个字母,包含24 个辅音字母和8 个元音字母,同时每个字母具有不同的形式,共计约有130种。在维吾尔语中,句子由一个或多个单词组成,单词间以空格分开,每一个单词由一个或多个音节组成。音节是最小的语音结构,是人类听觉能够自然感受到的最小语音片段。维吾尔语中音节由一个元音或一个元音加多个辅音组成,每一个音节包含一定的语义信息,维吾尔语音节实例如表1所示。这一特点正如汉语拼音的组成一样,拼音由韵母和声母组成,尽管在汉语中没有音节这一概念,但可以将一个汉语拼音看成一个音节单位。

表1 维吾尔语音节切分示例
维吾尔语的音节切分有一定的规则,音节结构固有(起音)+领音+(收音),其中音节中必须要有领音且必须是元音,而在起音和收音中可以有也可以没有[23]。C 表示辅音,V 表示元音,单词音节类型总共有12 种,可以表示为V、VC、CV、CVC、VCC、CVCC、CCV、CCVC、CCVCC、CVV、CVVC、CCCV。其中,前6 种是常见的维吾尔语单词音节类型,后6 种是外来词的音节类型。一般在维吾尔语中CV 与CVC 类型的音节出现频率最高。本文按照这个规则研发了音节提取工具,正确率达到96%~98%。
2.2 带标记音节的维汉神经机器翻译
维吾尔语语法和形态的复杂性、维汉平行语料匮乏以及数据稀疏问题,使维-汉机器翻译研究进展相对缓慢。本文将维吾尔语数据切分成具有一定语义信息的音节,汉语数据划分为单个字符,这样可以使翻译单元数量减少,出现频率增加。每一个翻译单元出现频率的增加使得网络模型学习能力增强。而翻译单元数量减少,不仅能缩小词表规模,降低模型的复杂运算,缩短模型的训练时间,同时还能有效地解决集外词(OOV)问题,缓解维汉神经机器翻译的数据稀疏问题,从而提高翻译质量。基本流程如图1所示。
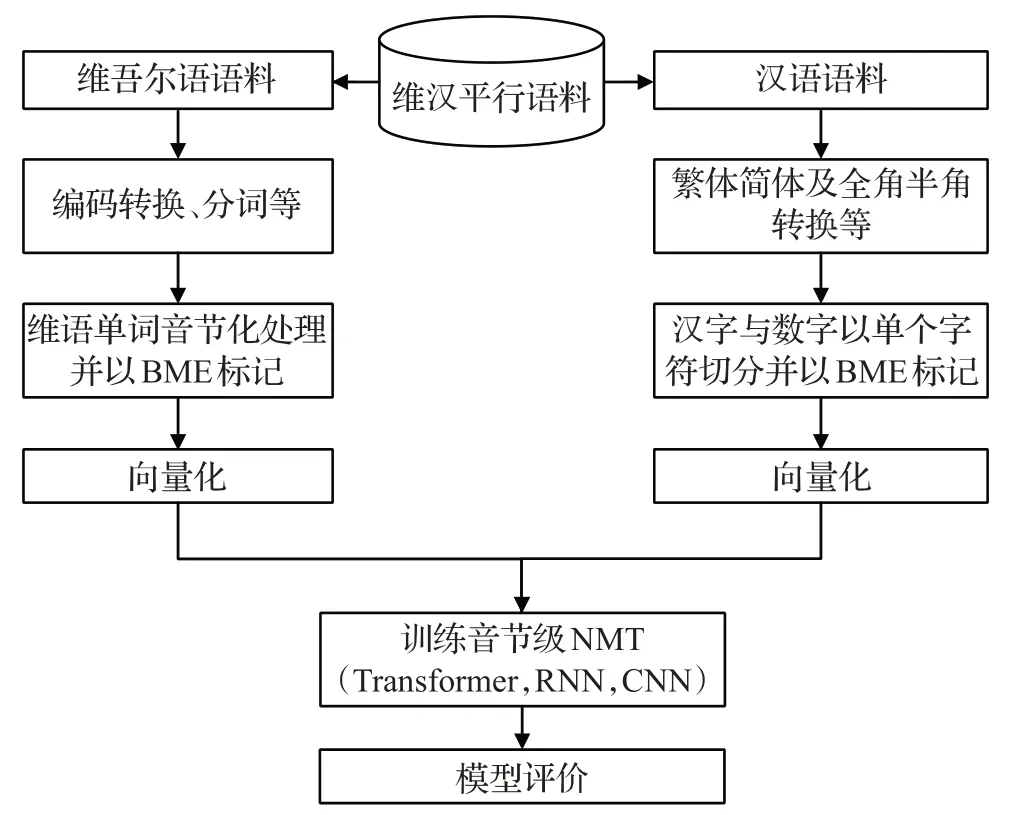
图1 带标记音节级的NMT训练流程
(1)编码统一化:通过本课题组研发的维吾尔语分词与编码转换工具来对维吾尔语语料进行分词并编码转换,对汉语语料进行繁体简体及全角半角转换,得到同意编码的语料。
(2)语料音节切分:通过本课题组研发的基于规则的维吾尔语音节切分工具来对维吾尔语语料进行音节切分,对汉语语料进行字符级切分,同时对维汉语料进行BME 标记。这种切分方法把数据切分成更小的单位,使词表规模更小。
(3)音节向量化:将切分好的维吾尔语音节向量化以后作为神经机器翻译模型的输入单元,把汉字向量作为模型的输出单元,训练一种基于音节粒度神经机器翻译模型。
(4)模型评价:对音节粒度的翻译模型效果进行评价,分别在不同规模的数据上与使用单词粒度、BPE 粒度的翻译模型进行对比分析。
3 实验结果与分析
3.1 实验数据
本文实验数据选用机器翻译评测(CCMT 2019)中的维-汉平行语料,其中训练集17万条维汉平行句对,验证集1 000 条维汉平行句对。由于训练数据集比较少,没有进行数据筛选。
3.2 数据预处理
对数据进行细致、有效的预处理是机器翻译任务中关键性的一步。本文的预处理包括编码转换、全角半角转换、乱码过滤、分词、BPE切分以及音节提取等。详细预处理步骤如下:
(1)利用新疆大学多语种实验室小组研发的编码转换工具分别对维-汉语料进行编码转换,包括基本扩展区转换、全角半角转换、繁体简体转换、乱码过滤与去重。
(2)利用开源的哈尔滨工业大学中文NLP工具LTP对中文语料进行分词处理。
(3)利用新疆大学多语种实验室小组研发的维语分词工具对维文语料进行分词处理。
(4)利用subword-nmt开源工具对维-汉等语料进行BPE切分处理。
(5)利用新疆大学多语种实验室小组研发的音节切分工具对维语音节拆分处理。
不同粒度的数据集切分示例如表2所示。
为了更好地分析对比不同规模数据集对基于不同粒度模型翻译效果的影响,本文随机抽取了5万、10万、15 万和17 万条四种不同规模的实验数据集,分别进行单词粒度、BPE 粒度与音节粒度等不同粒度的对比实验。其中,单词粒度的源语言和目标语言的词表大小分别为9 万和6 万;BPE 粒度的源语言和目标语言词表大小均为3.2 万,BPE 粒度的迭代轮数均为2.4 万;音节粒度的源语言和目标语言词表大小分别为8 500和5 100。具体的数据集信息如表3所示。
本实验以BLEU 值为主要评价指标,维-汉翻译方向采用基于字符(character-based)的评价方式,汉-维翻译方向则采用基于单词(word-based)的评价方式。维-汉翻译任务中,译文除了替换UNK 没有使用其他的后处理操作。在汉-维翻译任务中,将译文中对音节单位进行合并生成单词操作。

表2 不同粒度的数据切分示例
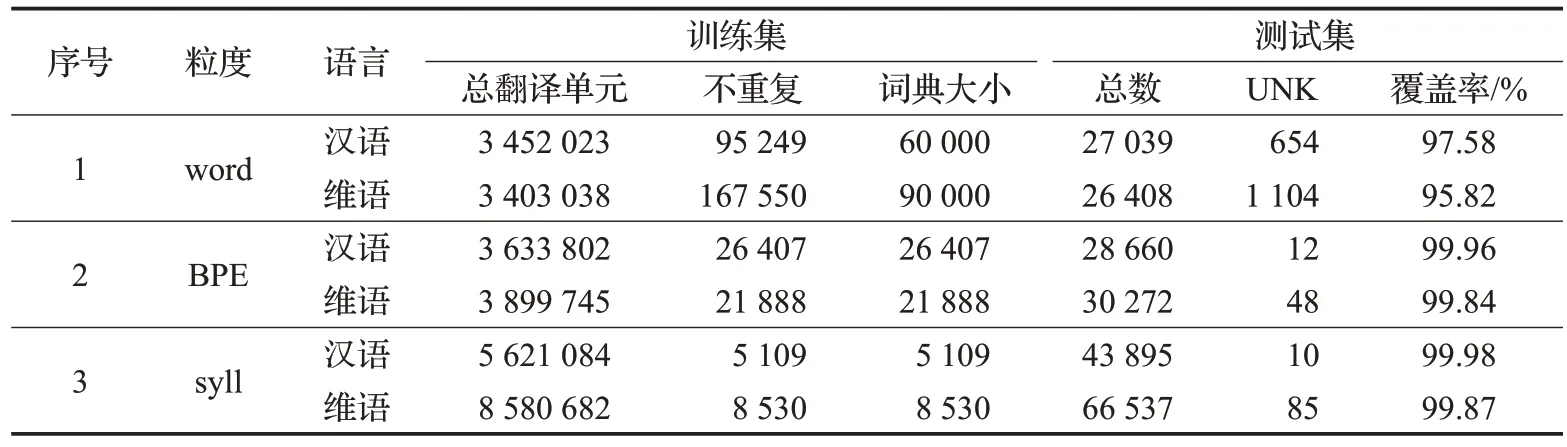
表3 训练集、测试集统计结果
3.3 实验环境与模型参数
实验在Ubuntu16.04操作系统上进行,两块GeForce RTX 2080 Ti(11 GB),Intel®CoreTMi5-9400F CPU@2.90 GHz 处理器和 32 GB 内存。选用 RNN、CNN 与Transformer 模型进行对比实验,所有实验均使用以下参数:
RNN 模型:使用 Google 开源的 GNMT[24]工具进行训练。系统参数如下,编码器和解码器均为4层的双向LSTM循环单元,词向量维度为512,隐藏层节点1 024,Batch Size为128,Dropout为0.1,其他参数为默认值,训练6 万步。在解码阶段采用Beam Search 策略进行预测,beam size大小均为12。
CNN 模型:使用 Facebook 开源系统 FairSeq[3]进行训练。系统参数如下,词向量维度为512,Dropout为0.2,max-tokens为4 000,其他参数为默认值,训练150 epoch。在解码阶段采用Beam Search策略进行预测,beam size大小均为5。
Transformer模型:使用Google开源的Tensor2Tensor[25]工具进行模型训练,并重写了模型的数据语料处理部分。为了使实验结果具有可比性,对所有的系统均使用文献[4]中的transformer_base参数,使用单个GPU训练,训练迭代次数均为6万步。在解码阶段采用Beam Search策略进行预测,beam size大小均为12,解码时长度惩罚α大小为0.6。
3.4 实验结果与分析
实验中,首先在不同大小的数据集上分别进行了维-汉以及汉-维方向的单词粒度、BPE粒度和音节粒度的Transformer神经机器翻译对比实验,实验结果如表4所示。从实验结果中可以发现,本文提出的基于音节粒度的机器翻译方法实验结果明显优于其他两种粒度的实验结果。其中,在维-汉翻译任务上与单词粒度机器翻译结果相比,在不同数据集上(数据集规模由小到大)分别提升了 9.06、7.62、7.26 和 7.04 个 BLEU 值;与 BPE粒度的机器翻译结果相比提升了4.92、3.55、3.05 和2.01 个BLEU 值。在汉-维翻译任务中与单词粒度机器翻译相比,在不同数据集上分别提升了6.69、5.89、5.83和5.87个BLEU值;与BPE粒度机器翻译结果相比分别提升了 5.51、3.30、3.54 和 2.82 个 BLEU 值。可见,基于音节粒度的机器翻译结果与其他两种粒度实验对比,当数据规模越小时,BLEU值的提升越明显。
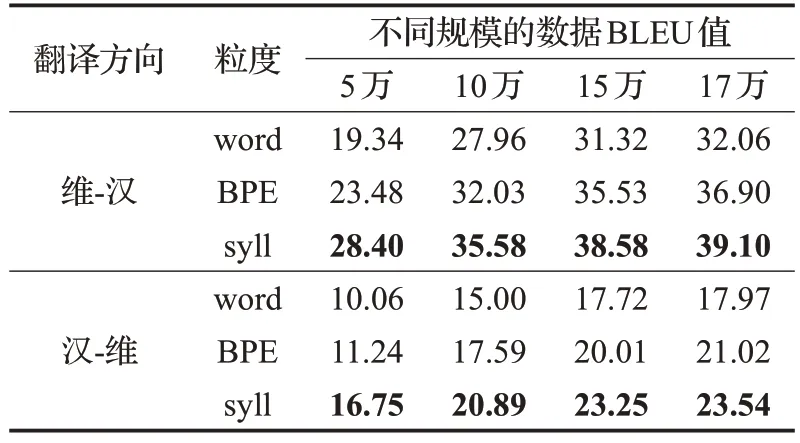
表4 Transformer模型在维-汉任务上的翻译结果
同样地,在CWMT2018 的50 万英汉数据上也进行了多粒度与不同规模数据上的对比实验,实验数据处理和模型配置与维汉系统一致,实验结果如表5所示。从表5中可以看出,音节粒度的机器翻译方法在英汉机器翻译上同样能提升效果。相比于在不同规模数据上(数据集规模由小到大)的单词粒度机器翻译分别提升了4.09、5.22、6.09、4.47、4.05个BLEU值,相比于BPE粒度机器翻译分别提升了2.34、2.19、2.01、1.3、0.3 个BLEU值。由此可见,音节粒度的机器翻译方法在数据规模较少的情况下性能提升明显,随着数据量的增大,BPE 粒度的效果越来越好,当训练数据规模到50万时,音节粒度和BPE的效果几乎持平。
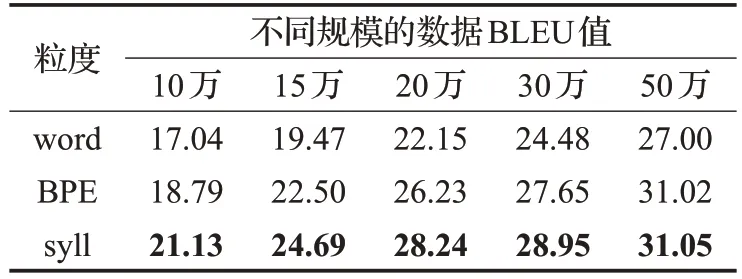
表5 Transformer模型在英-汉任务上的翻译结果
为了进一步验证基于音节粒度的维汉神经机器翻译方法在不同模型上的有效性,本文选用17 万规模的数据集,采用RNNsearch 模型和CNN 模型分别进行了不同粒度的对比实验,实验结果如表6 所示。可以得出,无论是在CNN还是RNNsearch模型上,基于音节粒度的方法的翻译效果都明显高于基于单词和基于BPE粒度的方法。
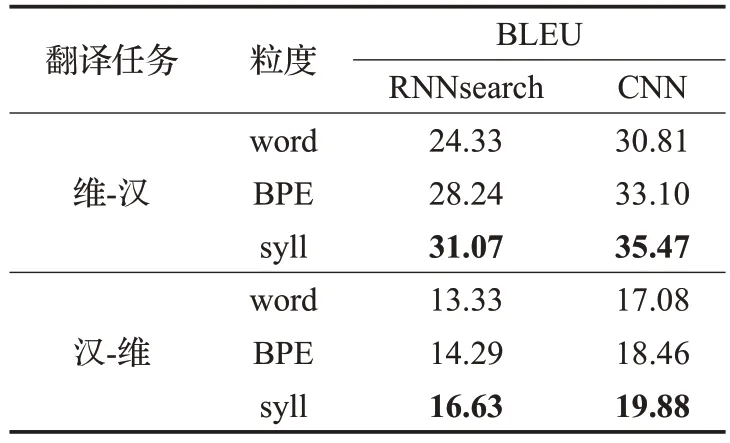
表6 RNN与CNN模型在维-汉任务上的翻译结果

表7 音节粒度syll+BME切分示例
另外,对实验结果进行错误分析后发现,当维吾尔文音节作为输入,中文汉字作为输出时,会出现一些严重的歧义问题。比如,维吾尔语的“sepil”(城墙),可切分成两个音节“se+pil”,其中“pil”音节单独(可视为一个单词)能表达“大象”;维吾尔文中“sugukkanlik”(坦然)可切分成4个音节“su+guk+kan+lik”,其中的“kan”音节有“血”的意思,这些歧义问题的存在影响着翻译效果。为有效解决歧义问题,进一步提升翻译质量,本文首先将维吾尔语切分成音节,将单词的首音节标注为“_B”,中间的音节全部标注为“_M”,末音节标注为“_E”,单独一个音节或符号时标注为“_BE”,具体示例如表7所示。
将改进后的序列作为神经机器翻译的输入与输出,在17万的数据集上开展实验。在Transformer模型上的实验结果如表8所示。可以看到Transformer模型在维-汉翻译中,融入BME 标注的音节切分方法与音节粒度和BPE 粒度的翻译效果相比分别提升了0.83 和3.04 个BLEU 值;而在汉-维机器翻译中,分别提升了0.59 和3.09 个 BLEU 值。RNN 与 CNN 模型的翻译效果在维-汉、汉-维方向都有所提升。实验结果表明,本文提出的融入BME 的标注方法能有效缓解语言中的歧义问题,进一步提升翻译质量。

表8 不同模型在syll+BME切分的维-汉翻译结果对比
综合表4、表5、表8的实验结果,可以得出以下结论:
(1)以Transformer 模型为基础,在不同的翻译方向和多种数据集规模上,基于音节粒度的机器翻译效果明显优于基于word 和BPE 粒度。数据集规模越小,提高效果越明显。
(2)音节+BME 粒度缓解了部分歧义问题,能有效地提高维-汉或汉-维方向的翻译效果。
(3)基于音节粒度的机器翻译在CNN、RNN与Transformer模型上不仅能进一步提升翻译质量,同时还能缓解因维吾尔语形态复杂与资源欠缺所导致的数据稀疏等问题。
3.5 不同句长度(字/词)的BLEU值
在神经机器翻译中,模型对句子长度比较敏感。本文提出的方法将单词切分音节,使句子长度变得更长。为了探讨句子长度对BLEU值的影响,本文在两种翻译方向中,针对不同长度的目标语言进行了BLEU值的对比,结果如表9所示。分析实验结果,可以得出如下结论:
(1)在Transformer 模型上,基于音节粒度的机器翻译模型在不同方向和不同长度句子的翻译任务中,翻译结果明显优于其他两种粒度的翻译结果。
(2)在维汉翻译任务中,句子长度在(40,70]范围时,基于音节粒度的机器翻译模型效果最优;句长在其他范围时,基于音节+BME粒度的机器翻译模型效果最好。
(3)在汉维翻译任务中,句子长度在(0,15]范围时,基于音节粒度的翻译效果最佳;句子长度大于15 个汉字时,基于音节+BME 粒度的机器翻译模型效果最佳;在句长为(0,40]和(70,100]时,提升效果最明显。
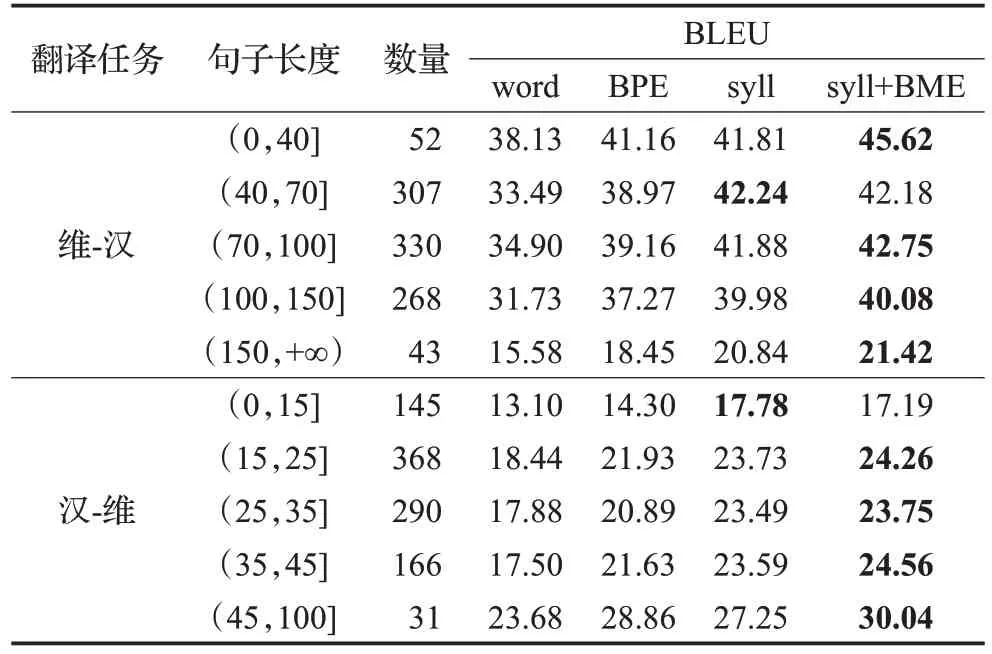
表9 Transformer模型在不同粒度不同句长时的翻译结果
3.6 Transformer模型翻译示例
表10 是Transformer 模型在1 000 条验证集上的部分对比翻译示例。可以看出本文提出的方法在翻译精度与翻译质量上优于其他两项。在维-汉翻译任务中,通过对译文的对比分析发现基于syll 粒度方法在翻译过程中存在部分重复翻译和漏翻译(示例1 王沪宁,示例3 党)等问题,同时还存在人名、地名、数字以及标点符号等实体的错误翻译现象,基于word 和BPE 粒度方法这种现象更为严重。虽然基于syll+BME粒度的方法缓解了这种现象,但是某些地名、人名比较罕见,训练时学习不充分,从而导致这种错误翻译现象出现。在汉-维翻译任务中,分析发现单词部分词缀漏翻译或过翻译现象(示例6 kitabi、kitablar、iqtisadiy 等)是最棘手的问题,同样也存在地名、人名等实体翻译错误的现象(示例5 shëdë、shëdiwo、budanis 等),这种现象在基于 word 和BPE粒度方法中更为严重。这两个问题是在汉-维翻译任务中提高翻译精度和翻译质量的最大障碍,也是以后研究工作的落脚点。

表10 Transformer模型翻译示例
4 结束语
本文提出了一种基于带标记音节的机器翻译方法并在不同切分粒度、不同数据规模和不同翻译模型上分别进行了维-汉、汉-维和英-汉方向的对比实验。实验结果表明:(1)与单词和BPE粒度的机器翻译模型相比,基于音节粒度的机器翻译模型的实验结果更好;(2)当数据规模越小时,基于音节粒度的机器翻译模型效果越好;(3)当基于音节粒度的机器翻译模型融入BME标注方法时,翻译结果有明显的提升;(4)基于音节粒度的切分方法缩小了源端和目标端词表大小,使得模型训练更快并且模型文件更小。由此可以得出结论,本文提出的基于带标记音节的机器翻译模型对语料资源缺乏和数据稀疏的维吾尔语到汉语方向的机器翻译是有效的。在后续研究中,将进一步研究音节粒度到BPE 粒度、音节粒度到单词粒度等不同的粒度交换方法对翻译结果的影响,同时将本文提出的方法应用到其他与维吾尔语相似、资源稀缺、形态丰富的黏着语的翻译任务中。
