基于BTM图卷积网络的短文本分类方法
2021-02-22董春阳黄夏炎
郑 诚 ,董春阳 ,黄夏炎
1.安徽大学 计算机科学与技术学院,合肥 230601
2.计算智能与信号处理教育部重点实验室,合肥 230601
短文本因为其内容简短、易于阅读和传播的特性而作为信息交互的载体广泛存在,例如新闻标题、社交媒体的信息、短信等,因此如何让机器自动而高效地理解短文本一直是自然语言处理的重要任务。文本分类作为文本理解的基础任务,能够服务于大量的下游应用(例如文本摘要、情感分析、推荐系统等),更是长期以来学术界与工业界关注的焦点。
尽管传统的分类模型如支持向量机(Support Vector Machine,SVM)[1]和神经网络[2-3]已经成功地应用于处理长文本,但是当其直接应用于短文本时,性能会不可避免地下降,这是因为短文本语句存在严重的稀疏性和模糊性问题,从而导致模型在分类的时候没有足够的特征进行类别的判断。
针对以上问题,本文构建了一个用于建模短文本的异构信息网络(Heterogeneous Information Network,HIN),它可以灵活地合并文本的潜在语义信息及其关系,并提出一种用于短文本分类的新型图卷积网络BTM_GCN(BTM 图卷积网络)。该新型图卷积网络可以有效地捕获异构信息网络中融入的主题信息和单词信息,以及它们之间的关系,增强了文档节点的语义信息,从而有效地缓解了短文本存在的语义稀疏性问题。
本文的贡献总结如下:
提出了一种用于短文本分类的新型图卷积网络BTM_GCN,利用BTM主题模型获取了短文本的文档级潜在主题。图卷积网络是一种简单且高效的图神经网络,能够很好地捕获到节点与节点之间的高阶邻域信息。
在三个英文短文本数据集上的实验结果表明,本文提出的BTM_GCN相比于基准模型,达到了最好的文本分类效果。
1 相关工作
传统文本分类的主要研究内容为特征工程和分类算法两部分。例如SVM 等[4]都是基于特征工程的,其中最常用的特征有词袋(Bag of Word,BoW),词频-逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)和某些更复杂的特征,如n-grams或主题等[5]。最近有一些研究工作[6-7]将文本建模为图形,并从图形中提取出基于路径的特征。尽管它们在长文本和经过良好编辑的文本上取得了成功,但是在短文本分类时由于特征不充足,导致它们都未能获得令人满意的分类性能。为了解决这些问题,很多人都做出努力来丰富短文本的语义信息。例如,Phan等人借助外部语料库提取了短文本的潜在主题[8]。Wang 等人提出了从KBs中引入外部实体信息来提高文本分类效果[9]。但是他们都是依赖于领域知识的特征工程,导致这些方法的性能都很有限。
深度学习用于文本分类的研究主要分为两部分,一部分聚焦于词嵌入[10]的研究,另一部分聚焦于深度神经网络的研究。最近的一些研究表明,深度学习成功地应用于文本分类,在很大程度上是由于词嵌入的有效性[11]。有一些研究工作将无监督的词嵌入聚合为文档嵌入,然后再将这些文档嵌入输入分类器进行分类[12]。另外,Joulin等人提出了一种简单而有效的文本分类方法fastText,该方法将单词嵌入的平均值作为文档嵌入,然后将文档嵌入送到线性分类器中进行分类[13]。Wang等人提出标签嵌入注意模型(Label Embedding Attention Model,LEAM),该模型将单词和标签嵌入同一个联合空间中来进行文本分类[14]。在深度神经网络的研究中,卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)是两种具有代表性的深度神经网络。在文本分类中,Kim提出了基于词向量的多个卷积核的卷积神经网络用于句子分类[2]。Santos等人将英文单词字符序列作为基本单元,分别训练得到文本的单词级和句子级特征,提高了短文本分类的准确性[15]。Lee 等人提出了基于CNN 和RNN 的混合模型对短文本进行分类,并取得了不错的分类效果[16]。
最近,称为图神经网络或图嵌入的新研究方向引起了广泛关注[17-18]。它们已成功地应用于各种领域,例如网络分析[19]和自然语言处理等领域。在自然语言处理领域中,Bastings 等人在句法依存树上使用了图卷积网络来改善关于句子的机器翻译[20]。Yao等人提出了Text GCN[21],该模型使用包含文档和单词作为节点的图形对文本语料库进行建模,并将图卷积网络应用于文本分类,获得了最先进的性能。与现有的工作不同,本文为短文本构建了一个异构信息网络,该网络是灵活且可扩展的,其合并了文本的潜在主题特征,进行了文档级语义的抽取,并结合图卷积网络,提高了短文本分类效果。
2 BTM图卷积网络
2.1 BTM主题模型
传统的主题模型,如LDA(Latent Dirichlet Allocation)和PLSA(Probabilistic Latent Semantic Analysis)等,其获取词语的共现信息来表示文档级的潜在主题,当这种方式用在短文本上时,由于短文本长度很短,会存在严重的数据稀疏问题。因此,Yan等人提出了一种用于在短文本中建模主题的新颖方法[22],即通过直接对整个语料库中单词共现模式(即双词)的生成进行建模来学习主题,称为双项主题模型(Biterm Topic Model,BTM),解决了文档级的稀疏单词共现模式的问题。
BTM 主题模型的生成过程可简要叙述为:将整个语料库看为一系列主题的组合,每一对词组来自某一个主题,一对词组属于某个主题的概率是由每对词组中两个单词从同一个主题中随机抽样得到。该模型生成过程的概率模型如图1所示。

图1 BTM概率模型图
图中,θ表示文档-主题分布,φ表示主题-词分布,z表示主题标记,wi和wj表示一对词组中词的标记,NB表示每对词组的集合,Κ表示主题个数。
2.2 图卷积网络
图卷积网络(Graph Convolutional Network,GCN)是一种多层神经网络,它可直接在图上进行,并根据其邻域的属性来生成节点的嵌入向量[23]。
本文将图表示为G=(V,E) ,其中V(| |V =n) 和E分别是节点和边的集合。假设每个节点都与其自身相连,那么任意v有 (v,v)∈E。令X∈ℝn×m是包含所有n个节点及其特征的矩阵,其中m是特征向量的维数,每行xv∈ℝm是v的特征向量。引入G的邻接矩阵A及其度矩阵D,其中Dii=∑jAij。由于自环,A的对角线元素都设置为1。当GCN只有一层时,它仅可以捕获直接邻居的信息,当多个GCN层堆叠在一起时,有关较大邻域的信息将被集成。对于一层GCN,新的k维节点特征矩阵L(1)∈ℝn×k计算为:


其中,j表示层数且L(0)=X。
2.3 BTM_GCN
BTM_GCN模型对短文本数据进行文本预处理后,利用BTM 主题模型进行主题训练,再将训练结果与短文本进行基于异构图的文本建模。该异构图灵活地建模了词、文档、主题对象之间的语义信息,并使用图卷积网络来捕获文档节点的邻域节点嵌入的语义信息,从而缓解短文本的语义稀疏性问题。具体的模型结构如图2所示。

图2 BTM_GCN模型结构图
本文建立了一个大型文本异构图G=(V,E),它包含短文档D={d1,d2,…,dm}节点、主题T={t1,t2,…,tK}节点和单词W={w1,w2,…,wn}节点。其中V=D∪T∪W,边的集合E包含了节点之间的关系。通过合并主题、单词和关系,丰富了短文本的语义,从而提高了分类的效果。如图3所示,通过BTM主题模型对AGNews数据集进行训练,可得出短文本“England stock market suffered a sharp fall on Monday…”的最相关主题是“Financial”和“Stock”,因此根据该主题信息就可容易且正确地将该条短文本判定为“Business”类别。再由短文本“The Bank of England is set to keep interest rates…”可知,其含有单词“Interest”和“England”,这两个单词在整个语料文本中多次共同出现,关联程度很大,于是将这两个单词建立边的连接,让这两个单词节点充当信息传播的桥梁和关键路径,使得短文本节点的标签信息可以通过图卷积网络在整个图形中全局性地传播。
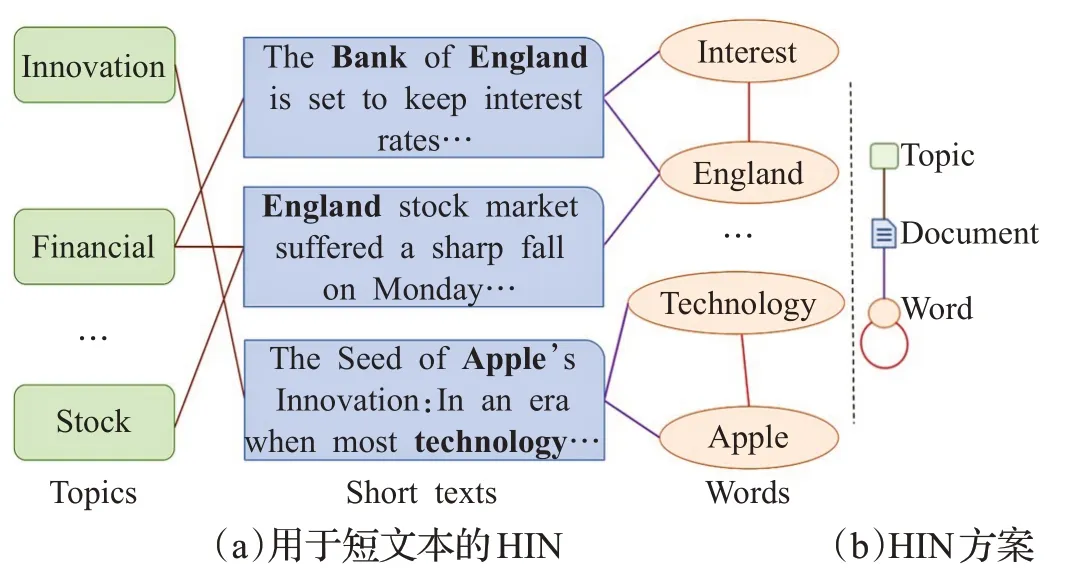
图3 一个AGNews短文本的HIN示例
具体地说,首先利用BTM挖掘潜在主题T,以丰富短文本的语义。每个主题ti=(θ1,θ2,…,θw)(w表示单词的数量)由单词的概率分布表示。为每个文档分配概率最大的前P个主题,即最相关主题。若将文档分配给主题,则会在文档节点和主题节点之间建立边,边的权重设定为主题概率值。
其次利用Doc2vec[12]为每个文档训练出长度为d的特征向量作为文档的初始化表示。Doc2vec 继承于Word2vec,它能更好地使用文章或短句进行训练与建模,并且可在文档层面保留词语的顺序关系与语义。这里单词节点特征的初始化为预训练的Glove向量,长度也为d。
最后根据文档中单词的出现(文档—单词边)和整个语料库中单词的共现(单词—单词边)在词节点之间建立边。文档节点和单词节点之间的边的权重是文档中单词的词频逆文本频率,其中词频是单词在文档中出现的次数,逆文本频率是总文本数目除以包含该单词的文本数目,再将得到的商取对数获得。发现使用TF-IDF权重比仅使用单词频率更好。为了利用全局单词共现信息,在语料库中的所有文档上使用固定大小的滑动窗口来收集共现信息。本文采用逐点相互信息(Pointwise Mutual Information,PMI),它采用一种流行的词关联度量来计算两个词节点之间的关联程度,并作为边的权重。在本文的初步实验中,使用PMI可以获得比使用单词共现计数更好的结果。形式上,节点p和节点q之间的边权重定义为:

关于每对单词p、q的PMI值计算方式为:

其中,W(p)表示滑动窗口包含单词p的数量;W(p,q)表示滑动窗口包含单词p、q的数量;Wsum表示滑动窗口在文本中的滑动总数。若大于0 的PMI(p,q)值越大,就代表单词p、q的语义关联度越高,而小于0 的PMI(p,q)值越小,就代表它们的语义关联度越低。
在构建完异构文本图后,将该图输入到只有两层的简单GCN中,因为输入的是一个异构图,所以构建了一个大型的特征矩阵其中⊕表示矩阵的连接操作,XT、XD、XW分别表示主题节点、文档节点和单词节点的特征矩阵,而矩阵的每一行代表一个节点的特征向量。最后通过一个softmax分类函数来预测文档的标签:
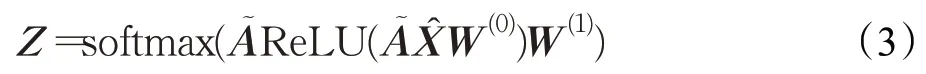

其中,yD表示用于训练的短文本索引集合;N表示输出特征的维数,即标签类别的数量;Y是相应的标签指示矩阵;Θ表示模型参数;λ表示正则化因子。
3 实验及结果分析
3.1 数据集
本文对三个英文短文本数据集(MR、AGNews 和Snippets)进行实验,它们的详细描述如下。
MR:电影评论数据集,其中每个评论仅包含一个句子[24]。该语料库含有5 331 个正面评论和5 331 个负面评论,每个句子都用正或负来标注,以进行二分类情感分类。
AGNews:该数据集来自文献[3]。从AGNews中随机选择9 000条新闻,将新闻平均分为4类。
Snippets:该数据集包含Phan等人发布的Google搜索摘要[8],共有8个基本标签,例如健康和体育等。
表1 展现了三个数据集的统计信息。其中每个数据集随机选出70%作为训练集,30%作为测试集,在训练集中再随机选出10%作为验证集。

表1 数据集统计表
3.2 实验设置
对于BTM_GCN,将第一个卷积层的嵌入大小设置为200,并将窗口大小设置为10,主题数K=15,每个文档的最相关主题数P=2,学习率设置为0.001,dropout率设置为0.5,正则化因子λ=5E-6。随后使用Adam[25]对该网络进行最多epochs=300 的训练,如果连续10个epochs关于验证集的损失没有减少,则停止训练。对于基准模型,使用默认参数设置作为原始论文或复现中的参数设置。对于使用了预训练词嵌入的基准模型,使用的Glove词向量长度d=200。
3.3 对比实验
(1)SVM+LDA:使用LDA主题特征的SVM分类器[5]。
(2)CNN:卷积神经网络[2],这里使用随机初始化的词嵌入作为CNN的输入。
(3)PTE:预测文本嵌入[26],它首先构建包含词、文档和标签作为节点的异构文本网络来学习词嵌入,然后以平均词嵌入作为文档嵌入进行文本分类。
(4)LSTM:LSTM模型[27]使用最后一个隐藏状态作为整个文本的表示形式。
(5)fastText:一种简单而有效的文本分类方法[13],该方法将单词嵌入的平均值作为文档的嵌入,然后将文档嵌入送到线性分类器中进行分类。
(6)LEAM:标签嵌入注意模型[14],该模型将单词和标签嵌入同一个联合空间中进行文本分类。
3.4 实验结果
表2 展示了在三个数据集上不同方法的文本分类精准度,其中BTM_GCN在所有数据集上均达到了最优的分类效果,证明了本文模型的有效性。BTM_GCN运作良好的主要原因有以下两点:(1)文本图可以同时捕获文档-主题关系、文档-单词关系和全局的单词-单词关系;(2)GCN 作为拉普拉斯平滑的一种特殊形式,将节点的新特征计算为其自身及其二阶邻居的加权平均值。节点之间的高阶领域信息表现在同一短文本语料库中不同短文档间单词的关联性上,这些关联可能是多阶连接的,即为高阶邻域,而GCN能很好地捕获到这些信息。主题节点融合了文档级的潜在主题,丰富了短文本的语义,缓解了短文本数据的稀疏性。
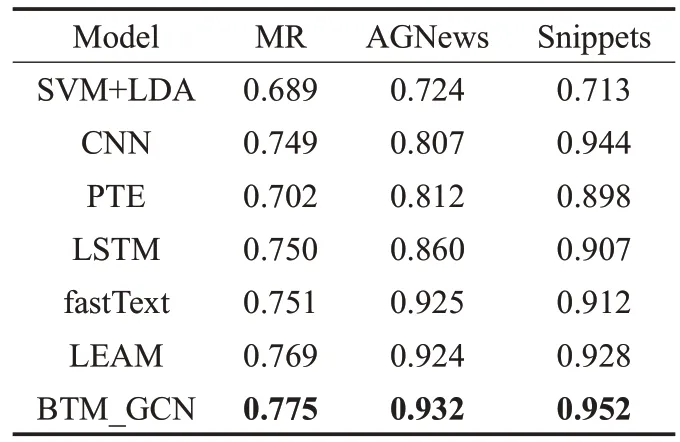
表2 实验结果比较(Test Accuracy)
另外,还观察到BTM_GCN相比于其他模型在分类性能上的提升并不非常突出。这是因为GCN忽略了在文本分类中有用的单词顺序,而CNN 和LSTM 等模型则明确地对连续的单词序列进行了建模。另一个原因是,由于短文本较短且滑动窗口数量较少,导致图中边的数量明显少于长文本图中边的数量,使得信息在节点之间的传递不够充分。
3.5 参数分析
图4 展示了在MR 数据集上主题数K对分类结果的影响。可以看到,对于主题数,测试集的分类准确性首先随主题数的增加而增加,当主题数大于15时,其分类准确性就会慢慢下降。这是因为,当主题数很少时,发现的主题就会非常粗糙,在这种情况下,简短文档更可能属于一个主题。相反,随着主题数K的增加,将会学习到更多的具体主题。但是如果主题数非常多的话,在选取最相关主题后,就可能会丢失其他相关主题信息。

图4 BTM_GCN模型的主题数K 对分类效果的影响
图5展示了在MR数据集上分配给文档的最相关主题数P对分类结果的影响,测试集的分类准确性首先随着P的增加而增加,然后在P大于2时降低。以上结果表明,模型对主题数和最相关主题数较敏感,过多或过少的数量都会对模型的分类效果产生较差的影响。
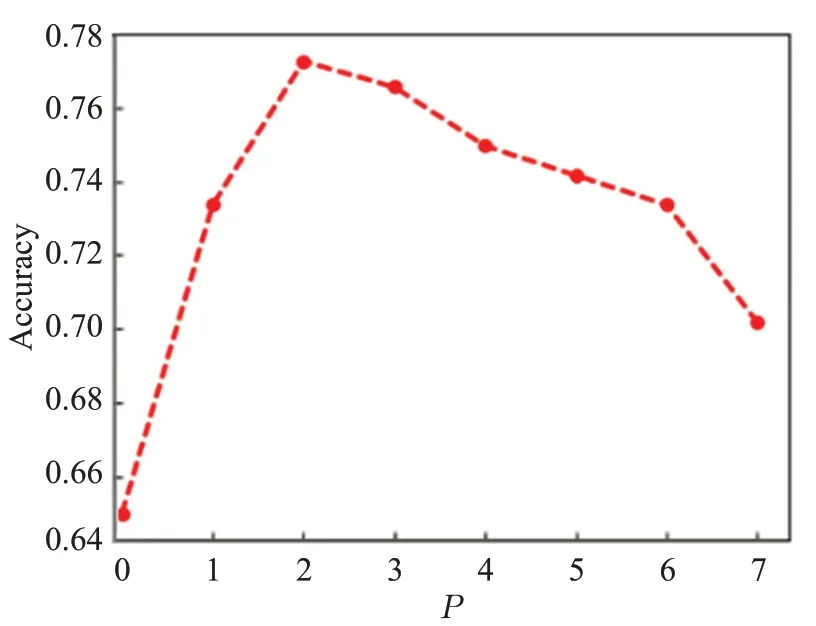
图5 BTM_GCN模型的最相关主题P 对分类效果的影响
图6 展示了在MR 数据集上滑动窗口大小W的测试精度。可以看到,随着窗口大小的增大,测试准确性首先会提高,但是当窗口长度大于10时,准确率就会慢慢下降。这表明,窗口太小则不能生成足够的全局单词共现信息,而窗口太大则可能会在关系不紧密的节点之间添加边。

图6 BTM_GCN模型的滑动窗口大小W 对分类效果的影响
4 总结
本文构建了一个用于建模短文本的异构图,它灵活地合并了潜在的语义信息及关系,并提出一种用于短文本分类的新型图卷积网络BTM_GCN。利用该图卷积网络可以有效地捕获异构图中潜在的主题信息和单词信息,以及它们之间的关系,丰富了文档节点的语义信息,从而有效地缓解了短文本分类时存在的语义稀疏性问题。本文在三个数据集上进行了实验,达到了较基准模型更好的分类效果。未来的工作会考虑加入Attention机制或者引入外部知识,如知识图谱等,来提高模型的性能。
