重复利用状态值的竞争深度Q网络算法
2021-02-22张俊杰赵涵捷
张俊杰,张 聪,赵涵捷
武汉轻工大学 数学与计算机学院,武汉 430023
强化学习(Reinforcement Learning,RL)是一种由动物心理学和控制理论等相关学科结合发展形成的机器学习方法[1-2]。在学习过程中,强化学习的智能体(Agent)通过不断试错的方式进行学习,寻求在当前环境中获得累计奖赏最大的策略[3]。目前强化学习,获得了产业界和科研人员的密切关注,并且在优化、控制、仿真模拟等领域取得了丰富的研究成果[4-6]。深度学习(Deep Learning,DL)是机器学习(Machine Learning,ML)领域中一类重要的方法,其中神经网络是模仿人类大脑的运行机制来解释数据,它可以从人脑无法直接提取特征的复杂高维数据中提取易于区分的特征数据[7]。近年来,深度学习已在计算机视觉、自然语言处理以及语音识别等领域取得较大的进步,也有不少实际应用[8-9]。
在过去几年,强化学习已经和深度学习成功地结合,两者结合形成的机器学习方法称为深度强化学习(Deep Reinforcement Learning,DRL)。如由强化学习中的Q 学习(Q-Learning)方法和深度卷积神经网络(Convolutional Neural Networks,CNN)结合而成的深度Q 网络(Deep Q-Network,DQN)是深度强化学习领域中的一个重要方法[10-11]。Hasselt等人[12]提出双Q网络(Double Deep Q-Network,DDQN)[13],该方法在计算目标网络的Q 值时使用两套不同的参数,有效解决了DQN 网络对动作值过高的估计。Hausknecht 等人[14]首次将长短时间记忆单元(Long-Short Term Memory,LSTM)引入DQN中,提出了一种基于LSTM修正单元的深度循环Q 网络(Deep Recurrent Q-Network,DRQN),其利用LSTM 的记忆功能在大多数Atari2600游戏实验环境中取得较为理想的成绩。Wang等人[15]提出竞争深度Q 网络(Dueling Deep Q-Network,DuDQN),将神经网络中提取出来的特征分为优势函数通道和状态值函数通道输出,该方法显著提高了在Atari2600 环境下的游戏效果。但是使用深度强化学习算法对空间插值算法进行超参数优化时,例如对反距离加权法(Inverse Distance Weighted method,IDW)中的加权幂次数或克里格插值算法中变异函数模型的基台值、变程等超参数进行优化[16],当算法的超参数空间大且为连续空间时,优化过程耗时久,效率低,并且容易产生过估计现象。
1 经典理论基础
1.1 反距离加权算法
反距离加权算法广泛应用于重金属含量分析、气象分析、水文分析等多个领域。它是一种多元空间插值方法,通过若干个已知空间离散点的值计算待测点的值,其最大的优点是计算简单且插值速度快。反距离加权算法是根据待测点和已知点的距离的倒数或距离n(n>0)次方的倒数进行加权,然后取所有邻近点的加权平均值。对于点p的估计值Y,其一般形式为[17]:
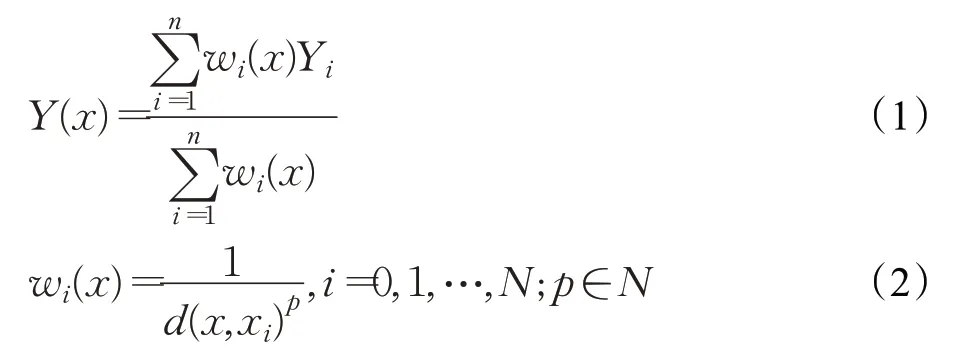
式中,x为插值点;xi为已知点;Yi为已知点xi处的值;N为用于插值的已知点的总数;d(x,xi)为已知点xi到未知点x的距离。权重wi随着与未知点距离的增加而减小,p值越大,则距离未知点越近,对未知点的值影响也越大。
1.2 强化学习
强化学习是智能体以当前环境状态为根据,采取行为并从环境中获得奖励的过程。一般情况下,强化学习是以马尔科夫决策过程为基础,寻求马尔科夫决策过程的最佳策略[18-21]。
强化学习框架如图1 所示,在当前状态St下,总体采取行为at,并根据状态转移函数P,环境状态将从St转到St+1,同时环境会根据在状态St下采取行为at的情况,反馈给智能体一个奖励信号r。智能体多次循环执行这一过程,以获得最大化累计奖励为目标,通过不断训练,最终得到该过程的最优策略。
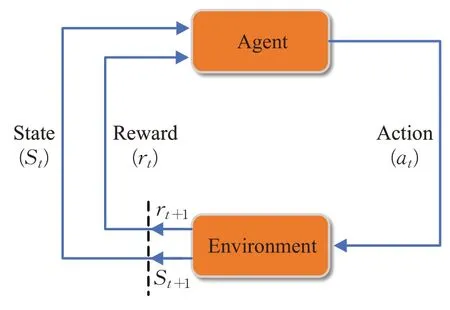
图1 强化学习框架
1.2.1 DQN网络
深度Q网络是一种经典的深度强化学习算法,其中深度学习部分可以感知环境信息,而强化学习部分可以根据深度学习部分提供的环境信息做出决策,完成从状态到动作的映射,并获得奖赏,再将这些信息转化为训练数据提供给深度学习,用以持续优化神经网络中的权重矩阵。深度Q 网络使用神经网络来近似估计Q-Learning中的Q-table值,但也因此破坏了Q-Learning的无条件收敛性[11]。为解决这一问题,DQN从以下两方面进行了改进。
第一方面,在DQN 的智能体与环境的不断迭代交互中,上一个状态与当前状态具有高度相关性,如果不经过处理,直接输入到神经网络中,会导致神经网络产生过拟合现象而无法收敛。因此在DQN中加入一个记忆库,用来储存一段时间内的训练样本。在每次学习过程中,DQN会从记忆库中随机抽取一批样本,输入到深度神经网络中,并对其梯度下降进行学习。在产生新的训练样本时,将老的训练样本和新的训练样本进行混合批次更新,从而在打断相邻训练样本之间的关联性的同时,提高了训练样本的利用率。
第二方面,在DQN中建立了一个与当前Q-Evaluate网络结构完全相同,但参数不同的Q-Target 的神经网络,该网络仅仅用来计算目标Q 值,而当前Q 值只由当前Q-Evaluate 网络预测产生。此方法可以减少目标值与当前值的相关性。损失函数公式为:
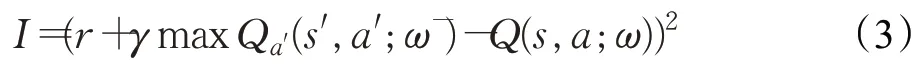
式中,s表示当前状态,a表示执行的动作,r表示环境对智能体的奖励值。Q(s,a;ω)为在s状态下执行a动作时,当前Q-Evaluate 网络的输出值,用来评估当前动态动作对的值函数;Q(s′,a′;ω-)为使用Q-Target网络计算得出的目标值函数的Q值。
Q-Evaluate 网络的参数w在每轮训练结束后实时更新,而Q-Target网络的参数ω-是由Q-Evaluate网络的参数ω延迟更新获得,即在若干轮训练结束后,将QEvaluate 网络中的所有参数完整地赋值给Q-Target 网络。对参数ω进行求解,可得到值函数的更新公式:
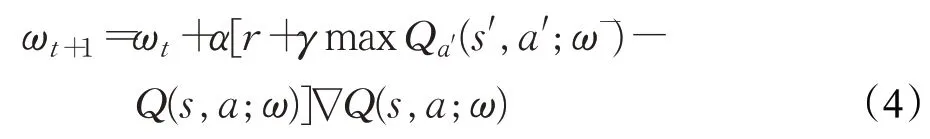
1.2.2 Double DQN
在使用经典强化学习算法Q 学习和深度Q 学习对动作进行决策和评估时,会参考Q-max的值。由于根据Q-max选择的动作并非一定是下一状态选择的动作,会导致对Q 现实值的过估计,而为了解决这一问题,van Hasselt等人提出了双重深度Q学习。
DDQN和经典DQN一样也具有两个结构完全相同的神经网络,但DDQN与经典DQN不同的是:DDQN通过解耦目标Q值动作的选择和目标Q值的计算这两步,来消除对Q 现实值的过度估计问题。先在当前Q 网络中,找到Q-max 值对应的动作,然后利用找到的动作在Q-Target网络中选择该动作的Q值。更新公式为:
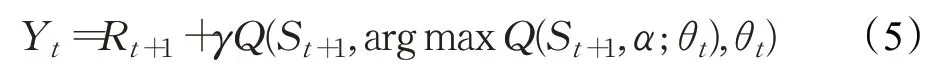
2 基于状态值再利用的竞争深度Q学习网络算法
2.1 竞争深度Q学习网络
在DDQN中,通过减小对目标Q值的过估计来优化算法,而在竞争深度Q学习网络(Dueling Deep Q-learning Network,DuDQN)中,通过改进神经网络的结构来优化算法。DuDQN将经典的DQN中的Q网络分成两部分:第一部分是价值函数部分,此部分仅仅与状态S有关,与将要采取的动作并无关联,记作V(s;θ,β);第二部分是优势函数部分,此部分不仅与当前状态S有关,并且与将要执行的动作A相关,记为A(s,a;θ,α) 。因此DuDQN中Q网络的输出为:
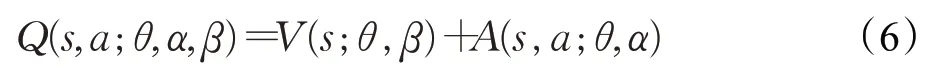
由于DuDQN 的Q 网络直接输出Q 值,无法分辨价值函数部分和优势函数部分各自的作用,为了体现这种可辨识性,对公式进行适当修改,修改后的公式为:
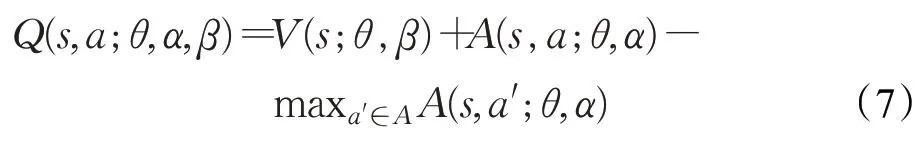
在实际应用中,通常使用优势函数的均值来代替优势函数的最大值求解,在保证性能的前提下在一定程度上提高了优化的稳定性。
2.2 RSV-DuDQN模型
在使用DuDQN对IDW算法中超参数进行学习时,DuDQN的收敛速度和在收敛之后的稳定性方面较其他经典深度强化学习算法有一定差距,算法性能有待提高。针对这一问题,提出了一种改进的DuDQN 模型。状态值再利用的竞争深度Q 学习网络(Reuse of State Value-Dueling Deep Q-learning Network,RSV-DuDQN)通过将Q 网络中的价值函数部分的状态值与当前状态下执行动作的奖励值结合,增强了状态与动作的内在联系,并强化了各个状态-动作对的奖励信号,使得智能体在较好状态时,对环境奖励更加敏感,在较差状态时,对奖励不敏感。从而使算法收敛速度更快,并在收敛之后波动幅度大大减小,提高了算法的稳定性。
在DuDQN 训练中,奖励信号值为r,表示在状态s下,执行a动作后,环境对此行为的奖赏。而在RSVDuDQN中,奖励信号值公式为:
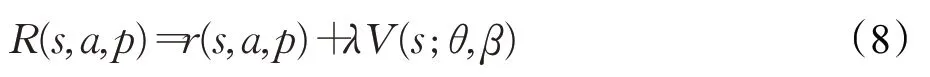
其中,p表示在当前状态s下,执行动作a后,环境转移到下一状态的概率。在对IDW算法中超参数学习中,p是确定的。V(s;θ,β)为Q 网络的价值函数部分的输出。λ是惩罚分子,范围为(0,1],其作用是确定环境反馈的奖励信号r在整个奖励值中占主导地位,防止因价值函数的状态值过大,导致对环境反馈奖励信号的失去敏感,从而使Q网络无法收敛。
RSV-DuDQN 模型的框架流程图如图2 所示,智能体在学习阶段随机采取动作和环境进行交互,并将得到的奖励r与采取的动作a,采取动作前后环境的状态s和s′结合,并以(s,a,r,s′)的形式存放到记忆库中。当记忆库中的信息达到规定值后,开始训练。首先从记忆库中随机提取若干条记录输入到DuelingDQN 的输入层中,经过若干个隐藏层后到达输出层。图中Fc_V 层的输出为价值函数的值V(s;θ,β),而Fc_A层的输出为优势函数的值A(s,a;θ,α)。将Fc_V层的输出与环境的奖励值结合形成最终的总奖励值并将其反馈给智能体。优势函数和价值函数结合形成Q(s,a),Q(s,a)指导智能体选择动作。如此循环,直到智能体达到目标状态或者训练步数达到指定值。
在实际训练中,为防止神经网络学习到奖励信号与状态值的直接关系,使用无限制增加价值函数的状态值来获得更大的环境总奖励。通常在每轮训练时,从记忆库中抽取若干个训练样本,将样本中的状态动作对输入到Q-网络中学习,得到价值函数部分的输出,再将得到的输出进行标准化,然后再以上文提出的方式进行结合。这样做的优点如下:
将不同状态下的训练样本进行标准化,进一步减小了相邻两个状态的样本相关性,更有利于算法的学习和收敛。
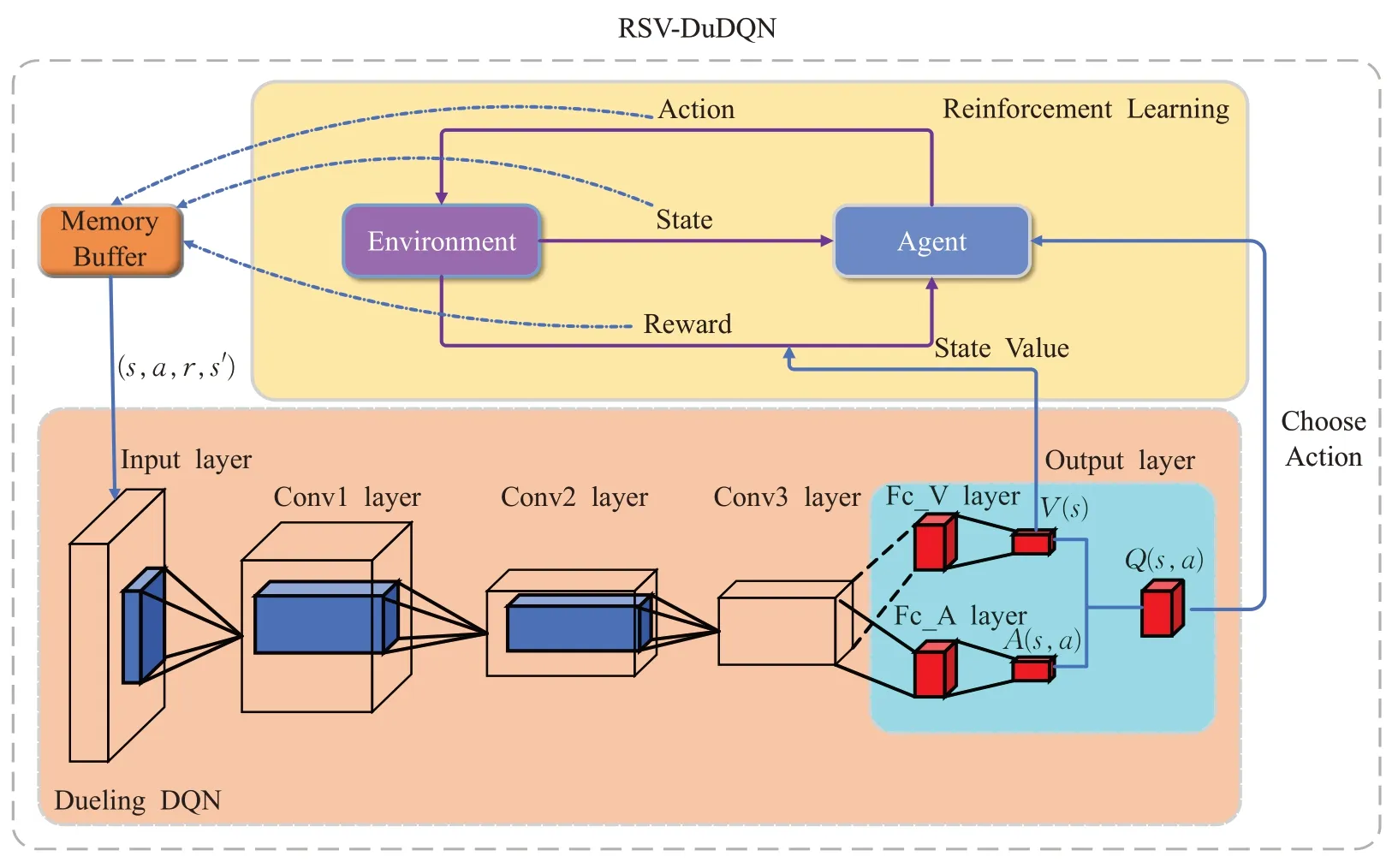
图2 RSV-DuDQN框架流程图
标准化之后,得到的状态值仅仅与当前状态有关,切断了总奖励值与Q网络的关联,从而避免Q网络通过直接输出较大状态值来变相获得总奖励。
算法实现步骤如下:

3 实验与结果分析
以下将验证提出的RSV-DuDQN 模型较常见的深度强化学习模型具有一定的优势。实验1 分别使用DQN、DDQN、DuDQN和RSV-DuDQN学习反距离加权插值法在武汉城郊农田土壤重金属含量数据集[22]上的加权幂次数。该数据集来自于湖北省技术创新重大项目“武汉城郊农田土壤重金属积累特征及风险评价”,数据集中每个样本的测定方法都是依据《土壤环境监测技术规范》(HJ/T166—2004)和《土壤环境质量农业农用地土壤环境污染管控》(GB15618—2018)的要求执行,总采样点1 161个,重金属种类八种。实验2使用由实验1学习到的超参数进行反距离加权插值,并与经典反距离加权插值算法进行对比。
实验环境如下:处理器为AMD2600,主频为3.4 GHz,内存为24 GB,由于模型中使用深度神经网络,大多采用矩阵运算,因此使用了GTX1660 图形处理器对模型进行辅助加速运算。
3.1 基于RSV-DuDQN的超参数估计
为验证RSV-DuDQN模型的有效性,本节采用武汉城郊农田土壤重金属含量数据集,该数据集包括As、Cd、Cr、Cu、Hg、Ni、Pb、Zn 八种常见土壤重金属。分别使用DQN、DDQN、DuDQN和RSV-DuDQN估计反距离加权插值法在该数据集中六种金属含量数据上的超参数。所有深度强化学习算法中智能体的动作空间为[-1,1],经过多次实验,最终确定动作空间离散为[-1.0,-0.5,-0.1,0,0.1,0.5,1.0]。经过实验验证,将动作由连续空间离散到精度0.1 的离散空间后,算法学习到的超参数对整个插值结果影响可以忽略不记。在实验开始阶段,先使用ArcGIS+软件将原数据中的经纬网坐标转换为常用的平面直角坐标,并将标准化与初始化后的超参数一起输入到Q 网络。八种金属的算法训练图如图3~图10所示,横坐标为训练次数,纵坐标代表在当前学习到的超参数下,用反距离加权法进行插值得到的预测值与真实值的误差,单位为mg/kg。四种深度强化学习算法分别在对八种重金属含量进行IDW的超参数预测时,训练情况如表1。表中展示了各种模型在对不同重金属数据集训练中第一次收敛时的训练轮数。为了更直观地展示算法训练时的情况,在训练中,当训练轮数达到5 000时,停止训练,此时还未收敛的算法在表格中收敛时的训练次数以“>5 000”形式表达。
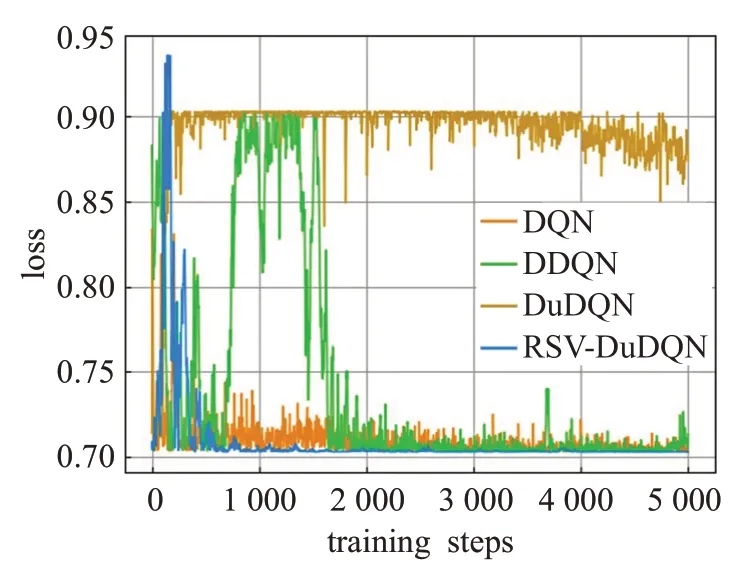
图3 重金属As数据的训练结果
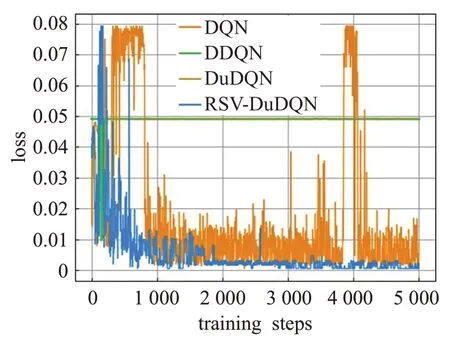
图4 重金属Cd数据的训练结果
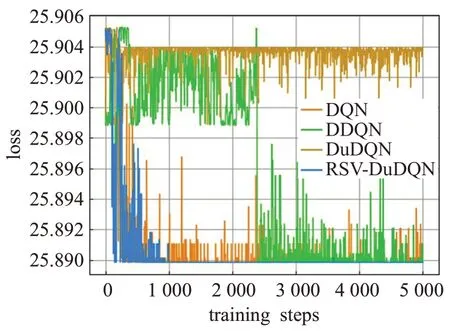
图5 重金属Cr数据的训练结果

图6 重金属Cu数据的训练结果
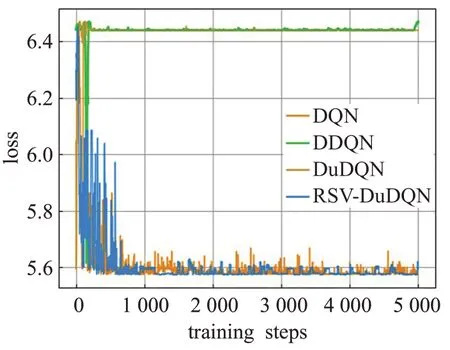
图7 重金属Ni数据的训练结果
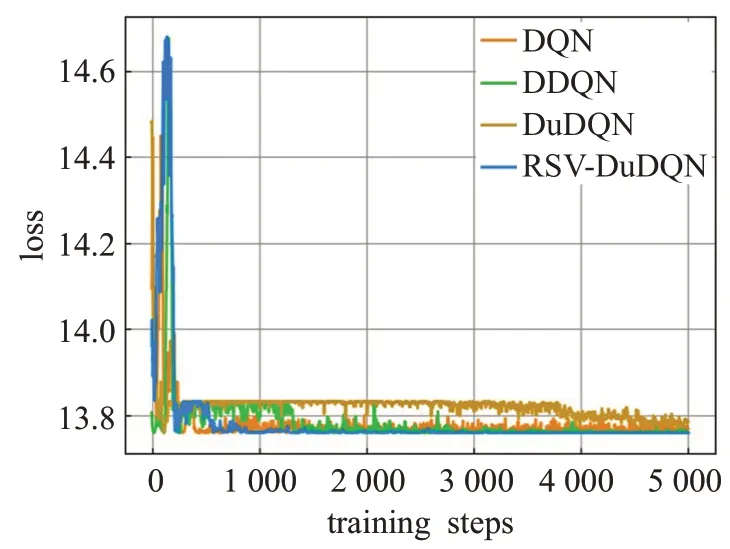
图8 重金属Pb数据的训练结果
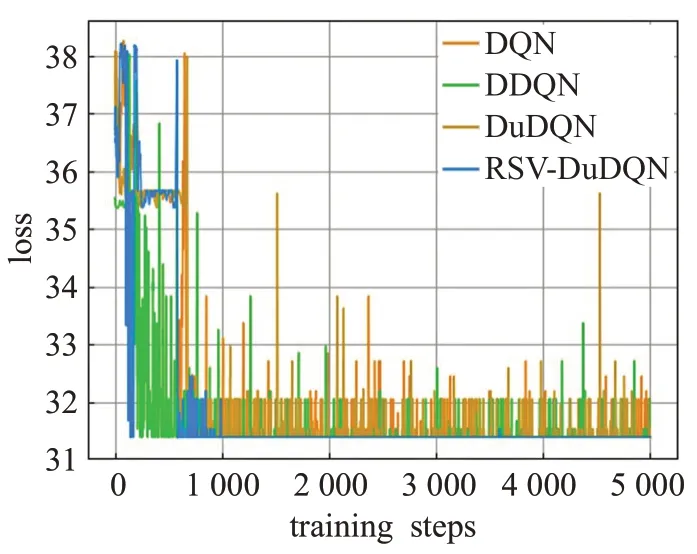
图9 重金属Zn数据的训练结果
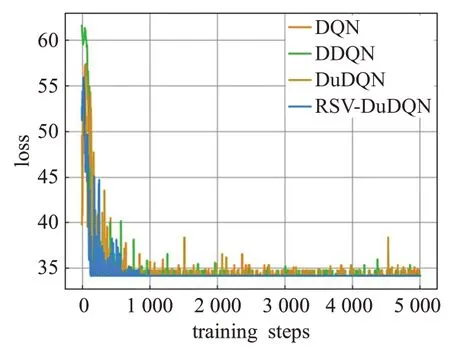
图10 重金属Hg数据的训练结果
由于RSV-DuDQN的时间复杂度与DQN、DDQN和DuDQN 相同,因此各模型的最小收敛轮数基本可以代表各模型的收敛时间。由表1可知,对于不同的重金属种类,DQN、DDQN 和DuDQN 的算法收敛速度不同。其中 DDQN 在 As 数据上收敛较快,DuDQN 在 Cu 数据上收敛较快,DQN在Cd、Cr、Ni数据上的收敛速度相比于 DDQN 和DuDQN 有较大提升。在As、Cd、Cr、Ni、Pb数据上,RSV-DQN 模型在收敛速度方面明显优于其他三个模型,而在Hg 数据上,四个模型的收敛速度相同。由图5、图6、图7、图10可以看出,DQN、DDQN和DuDQN在算法搜寻到最优解之后,仍然会出现较大波动,无法稳定在较好的状态,此情况在图5 中DQN 模型的表现上尤为明显。而由图4、图5、图9可知,DDQN和DuDQN并不能总是学习到最优超参数,某些情况下仅仅可以学习到较优超参数。对于图3~图10,RSV-DuDQN模型总是可以较快找到最优解,并且可以一直稳定在一定范围内,说明该模型相比于其他模型,在稳定性方面具有一定的优越性。

表1 不同模型在不同数据集上的最小收敛轮数
3.2 基于RSV-DuDQN的IDW插值实验
为了验证由深度强化学习模型搜索出来的超参数的有效性,本次实验使用实验1 中数据集的江夏区数据,共包含266 个采样点。分别使用RSV-DuDQN 模型搜索出来的超参数和常用先验超参数进行IDW插值实验,在As 数据集上使用RSV-DuDQN 模型搜索出来的超参数进行IDW 插值实验,然后使用相同方法常见超参数进行对比实验,并标记为“id=0”。用相同方法在Cr和Ni数据上进行实验,分别标记为“id=1”和“id=2”。最后两个模型预测的结果与真实值做比较,得到均方误差(Mean Square Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和平均绝对误差(Mean Absolute Error,MAE),实验结果如表2所示,所有误差精度取0.01。
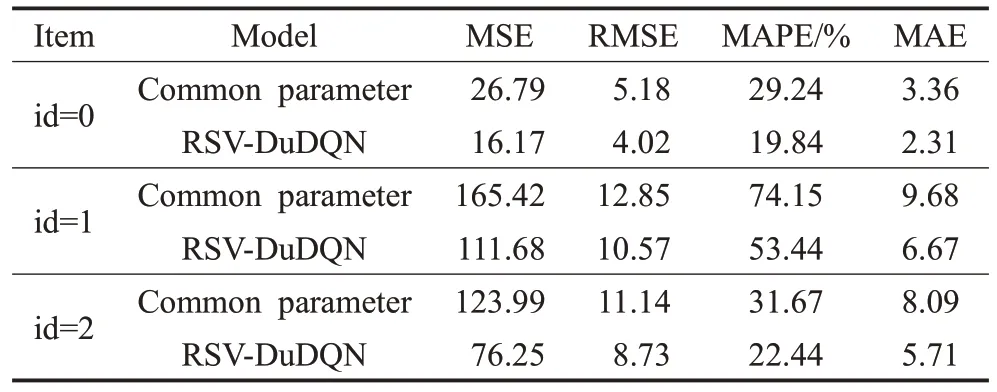
表2 模型在不同数据上的插值误差
在三次对比实验中,由于加入了RSV-DuDQN 模型,整个插值过程更为复杂,除IDW 插值所需时间外,RSV-DuDQN 模型需要额外的时间对IDW 算法中的超参数进行学习。但由表2 可知,基于RSV-DuDQN 的反距离加权法的MSE、RMSE、MAPE 以及MAE 均在不同程度上小于经典反距离加权法,使用RSV-DuDQN模型搜索出来的超参数进行IDW插值时得到的平均误差相比与使用常见超参数插值时的误差低13.11%,说明其在该数据集上的插值表现优于经典反距离加权法。因此可知,由RSV-DuDQN模型学习到的超参数优于常见的先验超参数,并且RSV-DuDQN模型确实有效可行。
4 结束语
本文提出了一种基于竞争深度Q学习网络的RSVDuDQN模型。该模型将竞争深度Q学习算法中Q网络中价值函数部分的状态输出值与环境反馈得到的奖励信号相结合,并将其以总奖励的形式加入到强化学习的训练中,解决了竞争深度Q 学习网络在一定情况下收敛速度较慢,并且收敛之后网络依然不稳定的问题。在与DQN、DDQN 和DuDQN 的对比实验中,证明了RSV-DuDQN 模型在收敛速度以及稳定性方面具有一定的优势。最后使用RSV-DuDQN 模型学习到的超参数对数据进行反距离加权法插值,并与常用先验超参数进行对比实验,证明了RSV-DuDQN模型学习到的超参数具有一定可行性。
虽然该算法在插值算法类的小规模动作空间中的超参数优化问题上,优化效果较好,但在较大规模动作空间上超参数优化过程的时间复杂度还有进一步提高空间。在接下来的研究中,可以使用遗传算法对深度强化学习的超参数进行优化,进一步在降低算法时间复杂度的同时提高算法收敛速度。
