一种复合型手势识别方法研究
2021-02-22韩文静罗晓曙杨日星
韩文静,罗晓曙,杨日星
1.广西师范大学 电子工程学院,广西 桂林 541004
2.广西师范大学 创新创业学院,广西 桂林 541004
随着计算机视觉技术的飞速发展[1],计算机在社会各领域的应用更加广泛和深入,逐渐成为人们日常生活不可或缺的一部分。人机交互(Human Computer Interaction,HCI)[2]作为人与计算机交换信息的过程,智能化成为其发展趋势。手势能够表达丰富的信息,是一种自然而又直观的人际交流模式,具有极强的信息表达与传递功能。手势识别被广泛应用于机器人控制[3]、智能驾驶和智能家居等领域。在人机交互中,与鼠标、键盘、触摸屏等图形用户界面相比,手势通信显得更加自然。人们尝试使用基于手套的设备来解决人机交互中的手势识别问题,但是基于手套的界面要求用户佩戴笨重的设备,限制了用户与计算机交互的自由度[4]。2010年,微软推出了一款名为Kinect 的3D 深度感应相机[5]。虽然Kinect 在增强现实、人体跟踪、人体动作识别等方面取得了很多成功的应用,例如能够很好地跟踪人类身体运动这样大型的对象,但由于Kinect 的低分辨率深度图,很难检测和分割具有低分辨率的小物体图像[6],在手势识别领域使用Kinect方法仍是一个有待优化和完善的问题。基于卷积神经网络(Convolutional Neural Network,CNN)[7]的手势识别方法,它不再依靠人工设计的方法来提取特征,通过组合简单的非线性模块,网络能够自主学习,逐步将原始数据转化为高层次并且抽象的表示。例如,Yamashita 等人[8]是第一个利用CNN 并将手势定位和分类一起处理的系统,他们提出了一种自底向上结构的深度CNN,包含一个特殊的层,用于提取可以分割手部的二值化图像。Li 等人[9]使用静态RGB-D 图像进行关节手势图像的特征提取,以端到端的方式训练一个基于注意力机制的CNN 模型,该模型能够使用单个网络自动定位手势并对手势进行分类。冯家文等人[10]构建了双通道卷积神经网络模型,通过使用不同大小卷积核的双通道卷积网络来提取图像特征并在手势识别上进行应用,取得了较好的识别效果。Hinton等人[11]提出胶囊网络(Capsule-EM),胶囊网络采用神经胶囊,上一层神经胶囊输出到下一层神经胶囊中的是向量,向量可以表示出组件的朝向和空间上的相对关系,以及高层特征与低层特征之间的位姿关系。莫伟珑[12]构建了基于胶囊网络的手势识别网络模型(ICapsule-EM),通过在胶囊网络中使用多尺度卷积核,在多角度手势图像上实现了较好的识别效果。
为了使卷积神经网络模型学习到更加丰富的特征信息,同时不改变输入数据量的大小,本文在上述工作基础上,提出了一种双通道卷积神经网络的特征融合与动态衰减学习率相结合的复合型手势识别方法。手势图像通过两个相互独立的通道进行特征提取,使用SENet(Squeeze-and-Excitation Networks)[13]构 成 的 第一通道提取手势图像全局特征,使用RBNet(Residual Block Networks)构成的第二通道提取手势图像局部特征,然后将全局特征和局部特征在通道维度上进行融合,使得网络学习到更全面的手势特征信息,实现手势图像的精确识别。同时,利用动态衰减的学习率训练模型,以提高模型的收敛速度及稳定性,仿真实验结果证实了本文方法的有效性。
1 理论方法概述
卷积神经网络是近几年图像处理领域最热门的技术,其强大的学习能力受到研究者们的青睐。与此同时也出现了一大批优秀的图像识别网络模型,如LeNet[7]、ResNet[14]、Xception[15]、EfficientNet[16]和 SENet 等。下面介绍本文涉及到的两个卷积神经网络模型ResNet 和SENet的基本工作原理与算法流程。
1.1 ResNet
卷积(Convolution,Conv)是卷积神经网络最重要且最基础的部分,其参数是卷积神经网络训练的核心,具有强大的特征提取能力[17-18]。在图像识别过程中,加深卷积神经网络的深度可以提高网络的学习能力,但随着网络层数增加到一定深度,会带来梯度消失的问题。为了解决梯度消失的问题,微软亚洲研究院在文献[14]中提出了残差网络(ResNet),这种简单的跨层连接方式,在几乎不增加参数量的前提下,有效地提升了网络的学习能力。该网络并不会受到网络层数的限制,可以通过加深网络层数提升网络性能。图1 为ResNet 中的残差结构,可以用如下公式表示:

其中,xl+1为l+1 层的输出,xl为l层的输出,Wl表示权重。F(·)表示待学习的残差映射。其性能主要归功于一种恒等映射的思想:假设在网络达到最优的条件下继续加深网络,只需让深层的网络能够保持恒等映射,则网络性能不会受到干扰而出现退化问题。
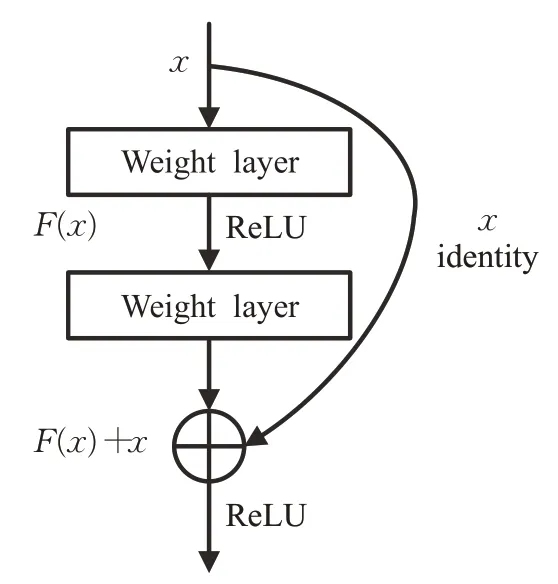
图1 ResNet残差结构
1.2 SENet
现有的多种图像分类网络是通过引入空间维度的创新来提升网络的性能,2017年,来自自动驾驶公司的Momenta 研发团队(WMW)在文献[13]中提出了SENet架构,其以2.3%的识别错误率荣获2017 年ILSVRC 挑战赛物体识别任务的冠军。该网络通过自动学习特征信息,获得特征图每个通道的重要程度,然后根据重要程度去增强有益特征并抑制无用特征,从而实现特征通道的自适应校准。图2 是SENet 模块,其映射关系可以表示为:
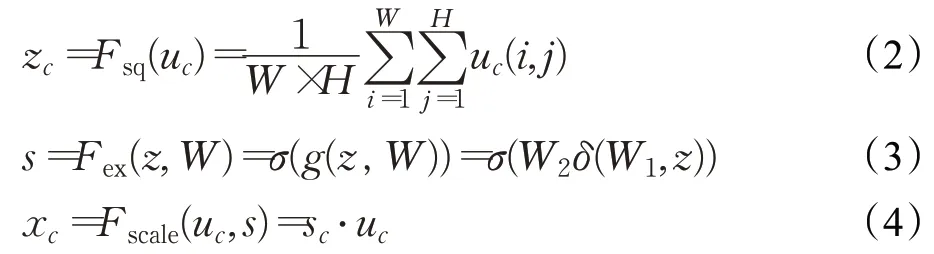
其中,Fsq(·)表示对特征进行压缩操作,Fex(·)表示对特征进行提取操作,Fscale(·) 表示对特征进行重标定操作。压缩所采取的方式是将原始特征图(SENet模块的Base layer)的一个通道uc的均值作为其特征表示,从而达到数据降维的目的,对应于图2中的全局平均池化(Global Average Pooling,GAP),将多通道的二维特征图转化为压缩特征向量zc后,通过两个全连接(Fully Connected,FC),权重分别为W1和W2,训练出对特征图具有选择能力的网络,在两个全连接之间使用激活函数δ进行非线性处理,激活函数δ为ReLU(Rectified Linear Units),最后通过归一化函数σ(Sigmoid),输出一个不同特征图的相对应的权重向量,并与原始特征图对应相乘得到最终输出xc。
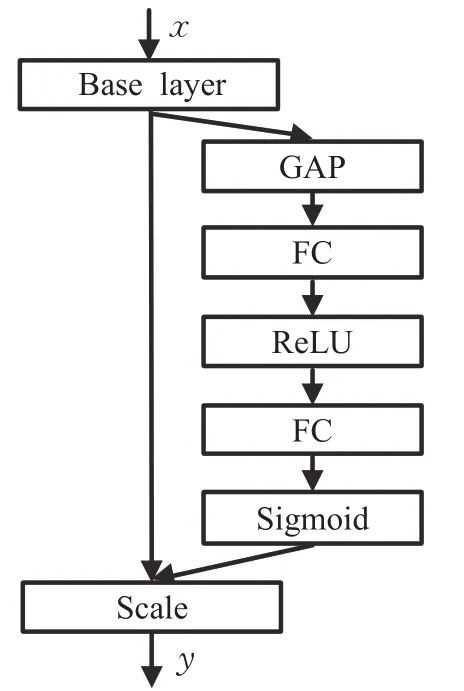
图2 SENet模块
2 双通道卷积神经网络的特征融合模型
本文提出的复合型手势识别方法,其双通道卷积神经网络的特征融合模型的具体结构如图3 所示。该模型将手势图像的全局特征和局部特征进行通道维度上的融合,使得网络学习到更全面的手势特征信息。
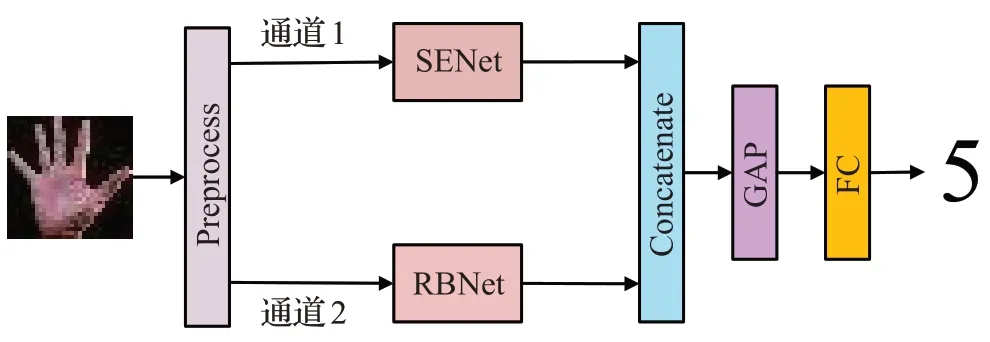
图3 双通道卷积神经网络的特征融合模型
为了增强卷积神经网络的特征提取能力,提高泛化能力,将输入数据为32×32×3 的手势图像,经过随机的亮度和对比度调整等预处理(Preprocess)操作,得到含有噪声的手势图像。
双通道卷积神经网络的特征融合模型由两个相对独立的通道构成。对于第一个通道,如图4(a)所示,在SENet模块之后添加第二个Conv+BN+ReLU层,以加强SENet模块的特征提取能力,从而提取手势图像的全局特征。
对于第二个通道,即RBNet模块,如图4(b)所示,包括顺序连接的第三个Conv+BN+ReLU 层、Stacked block(如图4(c)所示)、第四个Conv+BN+ReLU层、由3个相同深度可分离卷积(Separable Convolution,Separable-Conv)顺序连接构成的深度可分离卷积层和第五个Conv+BN+ReLU层。考虑到过深的网络结构虽然可以使图像的特征得到更好的拟合,学习到更高层次的纹理信息,但同时也可能由于层数过多而带来梯度消失、特征丢失等问题。RBNet 模块选择了ResNet 残差网络来进行改善,使网络更快更好地达到收敛。
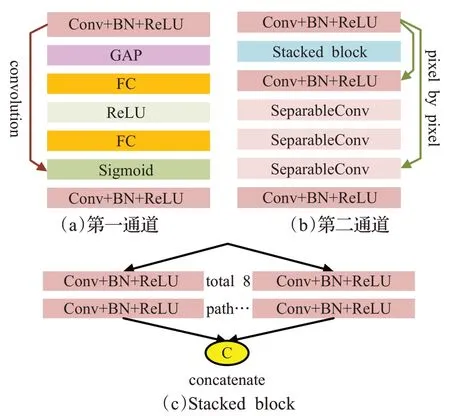
图4 双通道结构
第一通道和第二通道提取的手势图像特征进行通道维度上的融合,随后使用GAP,将融合后的特征展开为一维向量模式,最后添加一个FC进行手势图像的分类。
3 网络模型参数的动态衰减学习率
为提高双通道卷积神经网络的特征融合模型的收敛速度及稳定性,本文使用动态衰减的学习率进行网络模型训练,动态衰减的学习率公式为:

其中,α表示衰减系数,ηn表示当前的学习率,ηn-1表示前一个迭代次数的学习率,θ表示最小学习率。在网络模型训练过程中,当ηn >θ时,ηn=αηn-1,当ηn≤θ时,ηn=θ,当n=1时,η0即为初始学习率。
4 仿真实验
4.1 参数设置
本文主要实验环境:Intel Xeon Gold 6152,256 GB RAM,NVIDIA Tesla P40。实现的代码均采用python语言在tensorflow1.8-gpu框架下完成。利用CUDA和cuDNN提供的并行加速能力实现快速的训练和识别任务。
本文使用优化算法Adam(Adaptive Moment Estimation)进行训练。Adam优化器的参数为β1=0.1,β2=0.999。其中数据批处理大小为32,卷积神经网络的参数进行随机初始化,采用动态衰减学习率。在训练的初始阶段,利用初始学习率加快迭代更新的速度,随着迭代次数的增加,学习速率将以动态衰减的方式减小,以期望获取模型的全局最优解。采用此方法的目的是希望减弱迭代过程中收敛曲线的震荡,提高模型收敛速度与稳定性,得到全局最优解。
4.2 在ASL数据集上仿真实验
美国手语手势数据集ASL[19]由36种手势类别组成,包含26 种字母手势和10 种数字手势,图像总数量为2 515 张。设置2 165 张图像为训练集,350 张图像为测试集。数据集中的手势图像类别示意图如图5所示。
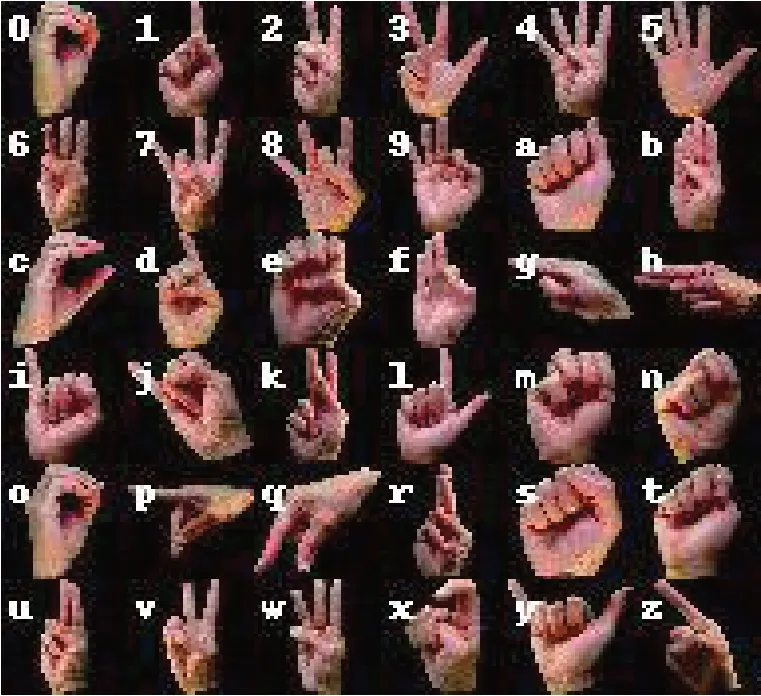
图5 ASL数据集上36种手势类别示意图
4.2.1 动态衰减学习率对网络性能的影响
首先验证学习率对手势图像训练集的准确率及loss曲线的影响,如图6、图7所示。当初始学习率η0设置为0.100,最小学习率θ设置为0.000 1,衰减系数α设置为0.99 时,由于初始学习率大,而网络权重更新变化小,导致训练集准确率及loss 曲线收敛速度慢,且震荡幅度较大。当初始学习率η0设置为0.100,最小学习率θ设置为 0.000 1,衰减系数α设置为 0.90 时,网络权重更新快,训练集准确率及loss 曲线收敛速度加快,但仍然有震荡。当初始学习率η0设置为0.001,最小学习率θ设置为 0.000 001,衰减系数α设置为 0.90 时,由于训练后期学习率过小,导致训练集准确率及loss曲线不收敛。当初始学习率η0设置为0.001,最小学习率θ设置为0.000 001,衰减系数α设置为0.99 时,训练集准确率达到最高,且训练集准确率及loss曲线收敛快,稳定性好。
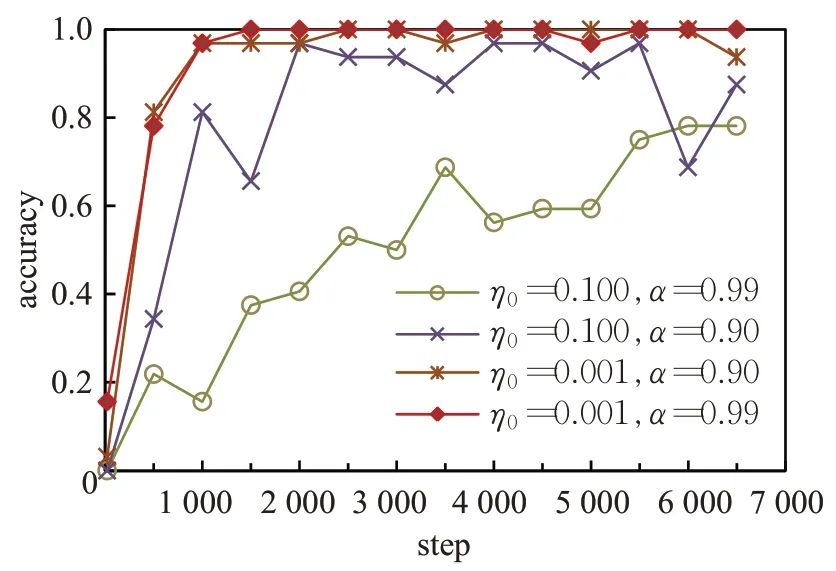
图6 ASL数据集上训练准确率曲线
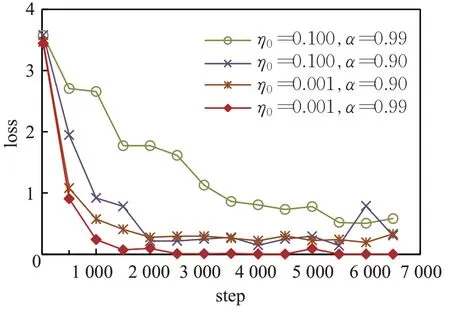
图7 ASL数据集上训练损失值曲线
然后验证学习率对手势图像测试集的准确率曲线的影响,如图8 所示。可以看出,学习率对测试集准确率曲线的影响与学习率对训练集准确率及loss 曲线的影响一致。由此,对于ASL数据集选取初始学习率η0=0.001,最小学习率θ=0.000 001,衰减系数α=0.99 作为最优的学习率参数。
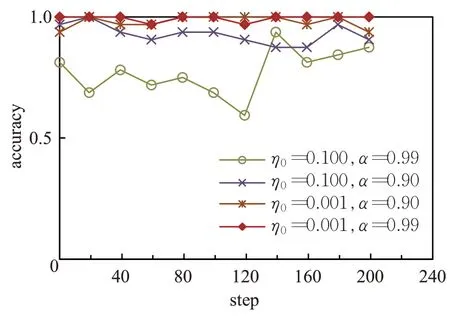
图8 ASL数据集上测试准确率曲线
4.2.2 手势图像特征提取可视化结果
为了使网络学习到更全面的手势图像特征信息,提高手势图像的分类准确率。双通道卷积神经网络的特征融合模型,对输入的手势图像,如图9(a)所示,使用SENet构成的第一通道提取手势图像全局特征,如图9(b)所示,使用RBNet构成的第二通道提取手势图像局部特征,如图9(c)所示,将全局特征和局部特征进行通道维度上的融合,如图9(d)所示,从而实现手势图像的精确识别。使用tensorboard 进行特征提取过程的可视化结果如图9所示。
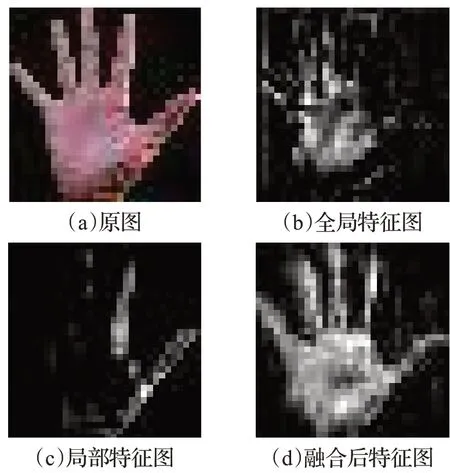
图9 ASL数据集上特征提取的可视化结果
4.3 在LIS数据集上仿真实验
为了进一步验证本文方法的有效性和适应的广泛性,使用LIS数据集进行仿真实验。
意大利手语手势数据集LIS由26种手势类别组成,包含22种静态字母手势和4种动态字母手势,每种手势分别从前、后、左、右和顶部5个不同的角度拍摄。本文使用的静态字母手势图像总数量为8 980张,设置8 080张图像为训练集,900张图像为测试集。数据集中的手势图像类别和5种不同拍摄角度的示意图如图10所示。
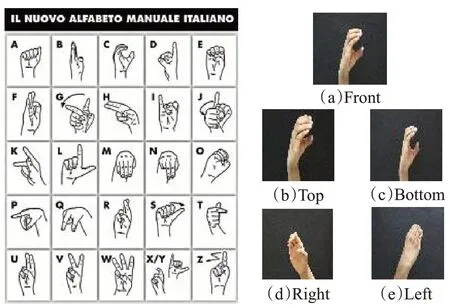
图10 LIS数据集26种字母手势类别和不同拍摄角度示意图
4.3.1 动态衰减学习率对网络性能的影响
对于LIS数据集,动态衰减学习率对网络性能的影响如图11~图13 所示,与ASL 数据集类似,也存在最优的学习率参数。当初始学习率η0设置为0.001,最小学习率θ设置为 0.000 001,衰减系数α设置为 0.99 时,训练集准确率达到最高,且训练集准确率及loss曲线收敛快,稳定性好。学习率对测试集准确率曲线的影响与学习率对训练集准确率及loss曲线的影响一致。
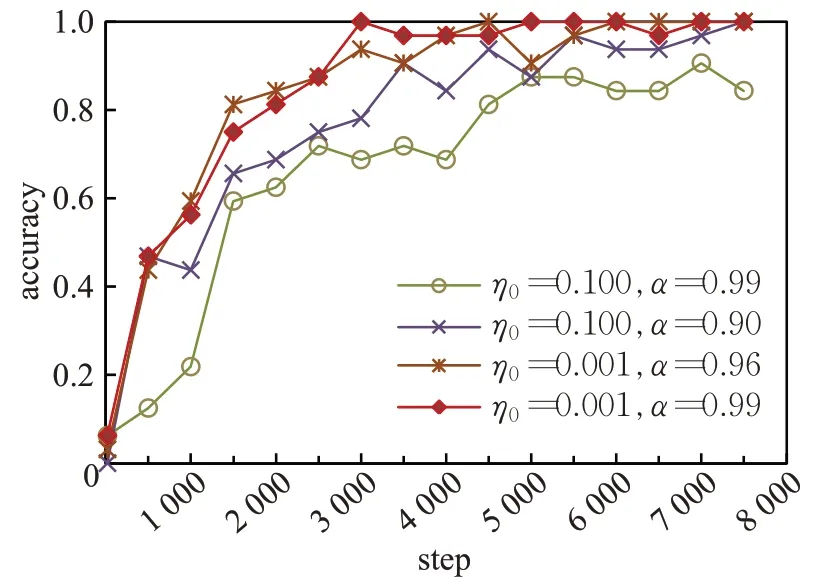
图11 LIS数据集上训练准确率曲线
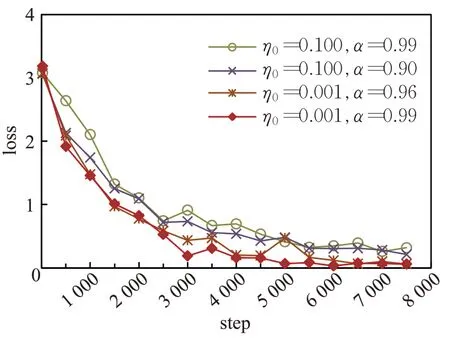
图12 LIS数据集上训练损失值曲线
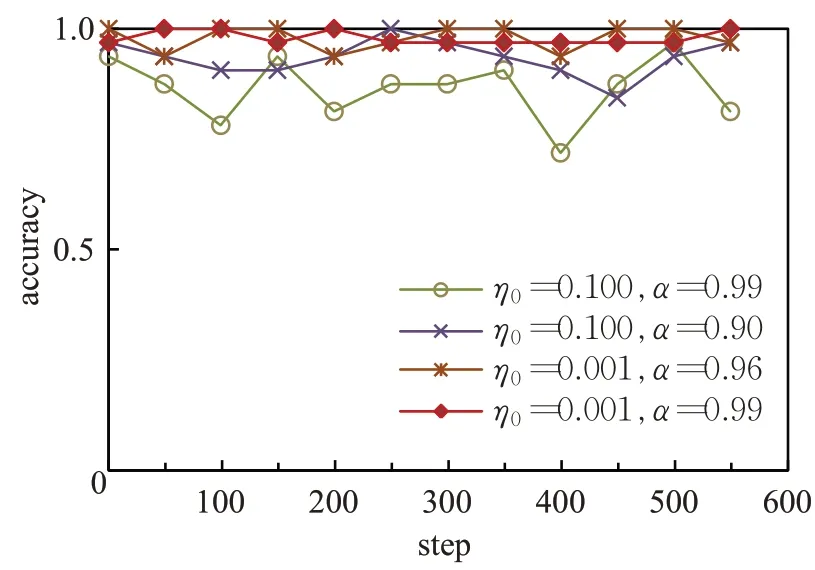
图13 LIS数据集上测试准确率曲线
由此,选取初始学习率η0=0.001,最小学习率θ=0.000 001,衰减系数α=0.99 作为最优的学习率参数。
4.3.2 手势图像特征提取可视化结果
双通道卷积神经网络的特征融合模型,对输入的手势图像(图14(a)),使用SENet 构成的第一通道提取手势图像全局特征(图14(b)),使用RBNet构成的第二通道提取手势图像局部特征(图14(c)),将全局特征和局部特征进行通道维度上的融合(图14(d)),从而实现手势图像的精确识别。使用tensorboard 进行特征提取过程的可视化结果如图14所示。

图14 LIS数据集上特征提取的可视化结果
4.4 模型的运行时间复杂度分析
将在最优学习率参数下的模型训练好后,分别使用不同数量的ASL 和LIS 测试集中手势图像做识别仿真实验,记录每次识别的时间,仿真结果如图15、图16 所示。从图中可以看出,在模型测试阶段,设手势图像数量为n,那么模型的运行时间复杂度基本为O(n)。
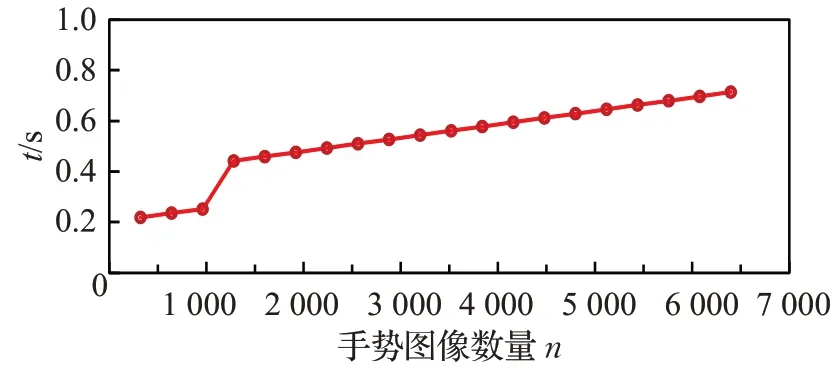
图15 ASL数据集上时间复杂度分析
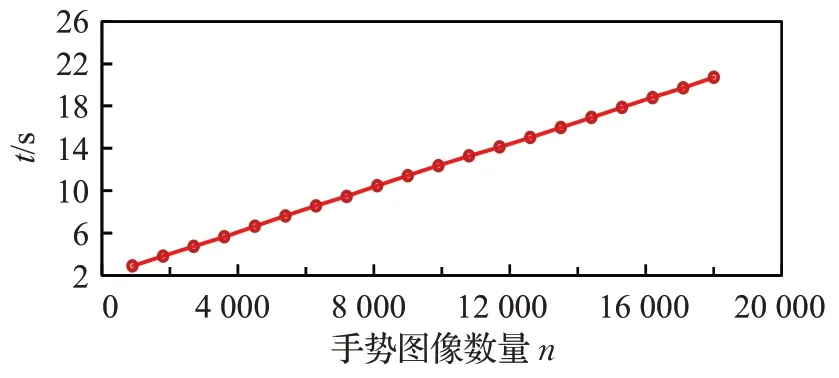
图16 LIS数据集上时间复杂度分析
4.5 不同模型的测试集准确率对比分析
为增加实验结果的完整性与说服力,将本文提出的方法与经典的四层CNN网络模型及文献[11-12]方法进行对比,结果呈现在表1 中。仿真实验结果表明,本文方法相较于其他方法在识别率上提升效果明显,且网络模型的参数数量少,体现了双通道卷积神经网络的特征融合与动态衰减学习率相结合的复合型手势识别方法在手势识别问题中的优越性。
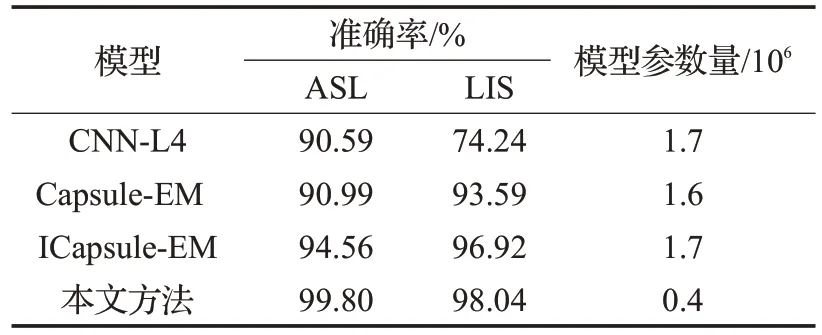
表1 不同模型的测试集准确率比较
5 结论
本文提出了一种双通道卷积神经网络的特征融合与动态衰减学习率相结合的复合型手势识别方法。本文方法通过两个相互独立的通道,进行手势图像的全局特征和局部特征提取,两个通道提取的手势图像特征进行通道维度上的融合,可以获得更加丰富的手势局部信息和整体信息。利用两个手势图像数据集,通过数值模拟的方法找到了最优的学习率参数。在最优参数条件下,本文提出的方法手势识别率高,参数数量少,且适应性广,在手势识别控制领域,有较好的应用前景。
