基于深度强化学习的服务功能链多维资源优化
2021-02-22贺小雨陈前斌
王 晓,唐 伦 ,贺小雨,陈前斌
1.重庆邮电大学 通信与信息工程学院,重庆 400065
2.重庆邮电大学 移动通信技术重点实验室,重庆 400065
为了在同一物理网络上同时支持多元化的业务场景,“网络切片”普遍被业界认为是一种理想的网络模型。网络功能虚拟化(Network Function Virtualization,NFV)是支撑网络切片的关键技术之一。NFV技术利用云计算和虚拟化技术编排不同的虚拟网络功能(Virtualized Network Function,VNF),并将其映射在通用物理服务器设备上完成相应网络功能。一个完整的服务请求由多个VNF 有序连接而成,形成一条服务功能链(Service Function Chain,SFC),多个相同业务类型的SFC 组成一个网络切片[1-2]。如何在底层物理网络上部署SFC 是NFV 技术的关键问题。SFC 部署问题的实质是将VNF和连接VNF的虚拟链路分别在底层物理网络满足资源容量需求的服务器与物理链路上实例化,并将底层网络的物理资源(如计算资源、链路带宽资源)分配给SFC 的各个组成部分(VNF、虚拟链路),形成一条端到端通路,完成相应的用户服务请求[3-4]。网络资源是有限的,如何在保证用户SFC服务质量的前提下节约资源消耗,降低运营成本,对运营商来说至关重要。
目前,针对SFC 的研究并不完善,现有研究通常根据不同的服务需求和网络场景来设定一个服务功能链映射的优化目标,并设计启发式算法进行求解。如文献[5]考虑在保证资源限制的前提下优化SFC的部署成本,提出了一种基于动态规划的成本优化算法进行求解。文献[6]考虑动态网络功能部署和路由优化问题,联合优化可接受最大流速率(Flowrate)和能耗,建立了一个混合整数线性规划模型,设计了一种基于流补偿的近似分配算法进行求解。文献[7]考虑在内容分发网络场景下部署实现内容分发功能的SFC,在保证时延要求的前提下最小化部署成本,并将此优化问题转化为一个整数线性规划问题,提出了一种前摄性VNF 链部署算法进行求解。
以上研究均是针对SFC在核心网的部署,然而对于无线用户,在接入网端进行无线资源(如子载波资源、发送功率等)分配是完成端到端服务必不可少的一部分,因此,在NFV场景下,将无线资源分配与SFC部署进行联合优化还需进一步深入研究。此外,经证明SFC部署问题是NP-hard 问题[8],现有研究通常设计启发式算法来求出次优解,并且较少考虑到无线环境的动态性而在单时隙中优化网络性能。然而,面对复杂多变的网络环境,这样的启发式算法难以达到理想的优化效果。
针对上述问题,本文联合考虑SFC部署和无线资源分配,提出一种基于深度强化学习(Deep Reinforcement Learning,DRL)的SFC多维资源联合分配算法。主要贡献包括:
(1)针对无线用户的SFC 服务请求,构建一种基于环境感知的SFC资源分配机制,将用户可达的无线速率作为SFC部署的流速率,以此作为依据来分配SFC节点计算资源和链路带宽等资源;
(2)根据上述基于环境感知的SFC 资源分配机制,建立用户时延要求、无线速率需求以及资源容量约束下的SFC部署成本最小化模型;
(3)将此优化模型转化为在离散时间下的具有连续状态空间、高维度动作空间的无模型马尔科夫决策过程(Markov Decision Process,MDP)模型,并提出一种基于深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)[9]的SFC多维资源联合分配算法,实现对SFC多维资源的联合优化。
1 系统模型
1.1 网络场景
本文的网络场景采用基于NFV/SDN(Software Defined Network)控制面与数据面相分离的架构,如图1所示。控制面的NFV管理编排器(Management and Orchestration,MANO)负责对用户的SFC进行部署和资源分配决策,数据面的NFV 基础设施(NFV Infrastructure,NFVI)为分布式高性能通用服务器,负责用户SFC中VNF的实例化和链路传输。
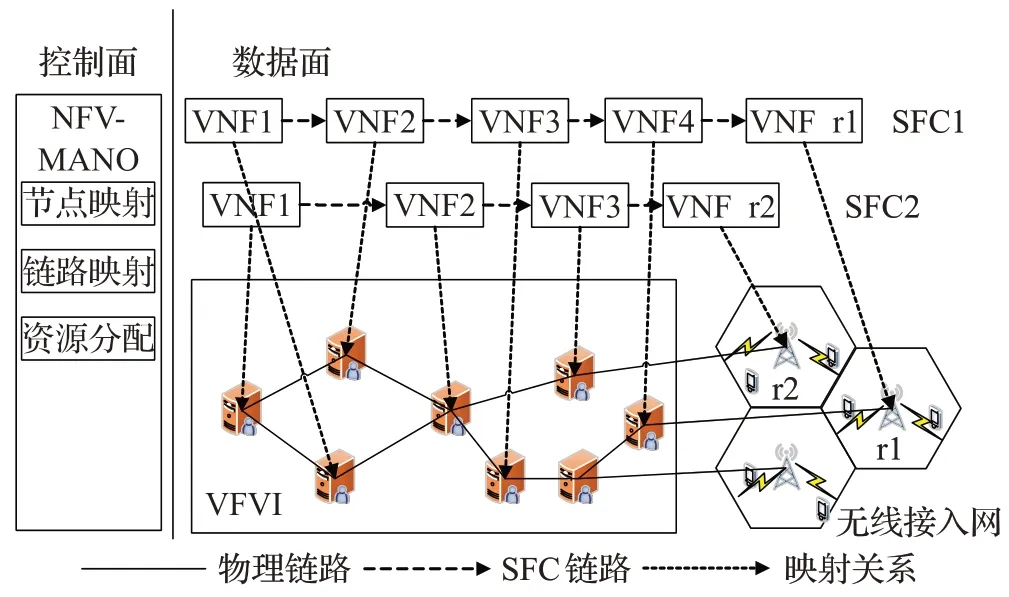
图1 网络场景
针对无线用户的下行SFC请求,要完成完整的端到端通信除了需要常规的VNF 部署之外,还需要在无线接入网端为用户分配无线频谱和发送功率等资源。在传统SFC 部署问题中,通常为一条SFC 指定一个流速率,或者为SFC 中的每个VNF 和虚拟链路指定所需的资源消耗[6],但由于SFC 在有线链路的流速率与最终用户可达的无线速率不匹配,导致核心网资源浪费。针对这一问题,本文构建了一种基于环境感知的SFC资源分配机制。所谓“环境感知”,即在无线端监测用户的信道状态,并分配相应无线资源,从而根据香农公式获得用户可达的无线速率,以此速率作为整个SFC 的流速率,进行相应VNF和虚拟链路的计算资源和链路带宽资源的分配。这样,以用户可达的无线速率作为依据来分配SFC 各部分资源,节约了核心网资源消耗,从而有效降低了SFC 的部署成本。本文的资源分配在核心网中考虑物理节点计算资源与有线链路带宽资源,在无线接入网中考虑子载波分配。
1.2 网络模型
底层物理网络用无向图G=(N,E)表示。其中N={n1,n2,…}为物理节点集合,由分布式的标准化高性能通用服务器组成,用Nr={r1,r2,…}表示无线接入网中小基站(Small Base Station,SBS)集合,有Nr⊂N;E={(ni,nj)|ni,nj∈N,Bi,j >0}为物理链路集合。用C1×|N|=[c1,c2,…]表示物理节点计算资源容量,其中ci为物理节点ni的计算资源容量;用B|N|×|N|=[Bi,j]表示物理节点的关联矩阵,其元素Bi,j表示节点ni和nj间的链路带宽容量,若两点间无链路则为0;用表示SBS的子载波资源向量,其中表示SBSri的子载波个数。
1.3 SFC请求模型
服务请求集合用F={1,2,…,f,…}表示。一个SFC请求为一个五元组f=<sfcf,Loadf,rf,Delayf,Cf >,其中sfcf表示f的SFC 逻辑链路,Loadf表示f的负载(单位:Mbit),rf表示发起该服务请求的用户所关联的SBS,Delayf表示f的时延要求,Cf表示f的无线速率要求。
1.4 部署变量
本文的研究目标是在动态变化的无线信道环境中,为每个时隙的服务请求做出SFC 部署与资源分配决策。部署变量包括每个时隙的VNF部署变量及其计算资源分配、链路映射变量及其带宽分配以及无线接入网子载波分配。用二进制矩阵表示VNF 部署矩阵,其中表示在t时隙VNF部署在物理节点nj上,否则为0;用表示sfcf链路部署变量,在t时隙当sfcf中从vi出发的虚拟链路映射在物理链路(np,nq)上时,有否则为0,进而可用表示sfcf中所有链路的映射集合。当节点映射完成后,以SFC相邻节点间映射的物理节点的Dijkstra最短路径作为该虚拟链路的映射结果。如图2 所示,SFC 中一条虚拟链路(i,j)的相邻两个VNF分别映射在物理节点n1和n3上,则该虚拟链路映射即为节点n1和n3间的Dijkstra 最短路径n1→n2→n3。
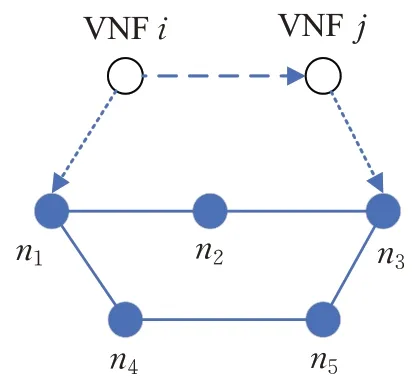
图2 链路映射示意图
用矩阵W(t)=[Wi,f(t)]表示SBS 子载波分配矩阵,其中Wi,f(t)表示在t时隙SBSri分配给服务请求f的子载波数量。用cpuf(t) 表示t时隙分配给sfcf中的VNF 的计算资源,用Bf(t)表示分配给sfcf的链路带宽资源。假设t时隙节点处理速率与所分配计算资源cpuf(t)成正比:

其中,φ为转化因子,根据本文所构建的基于环境感知的SFC 资源分配机制,节点处理速率和链路带宽Bf(t)应与用户可达的无线速率Cf(t)一致,即Bf(t)=Cf(t),则可得计算资源的需求量为:
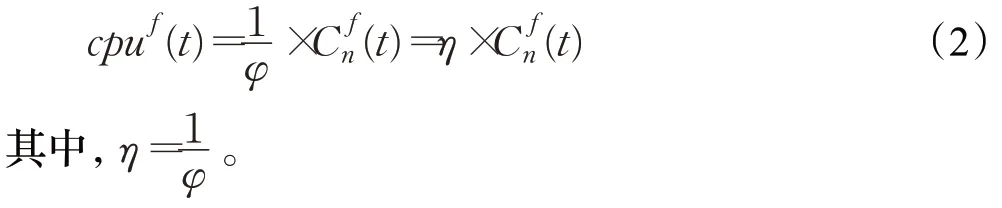
1.5 优化目标
本文的优化目标是在满足服务请求时延要求和无线速率需求的前提下,最小化SFC部署成本。根据本文构建的基于环境感知的SFC资源分配机制,首先要在每一时隙开始时监测用户无线接入网端的信号强度,SBS通过平均分配的方法对用户进行功率分配,从而得到用户的信干噪比γi,f(t),即:
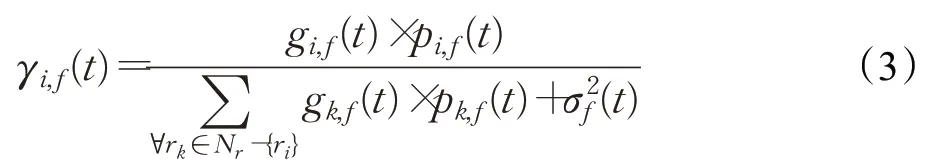
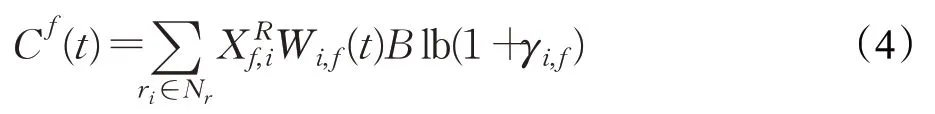
其中,B是单个子载波带宽。将此用户可达的无线速率作为该用户SFC的流速率,以此为依据对SFC进行资源分配。
本文考虑的部署成本由无线子载波资源成本、物理节点计算资源成本以及链路带宽资源成本三部分组成,可表示为:
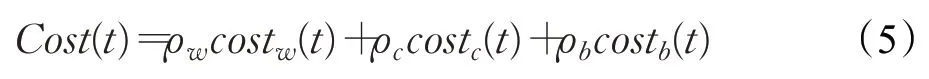
其中,ρw、ρc、ρb为三种成本权重因子,costw(t)为子载波资源消耗,costc(t)为物理节点计算资源消耗,costb(t)为有线链路带宽资源消耗,分别表示如下:
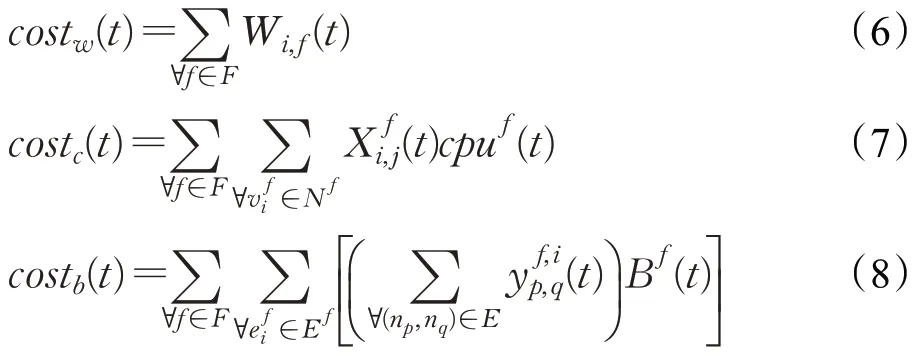
每条SFC 需满足由其自身服务特点所决定的时延需求。一条SFC的总时延D由物理节点处理时延Dc、有线链路传输时延Dl以及无线链路传输时延Dw组成。设节点处理时延与SFC负载Loadf成正比,与节点处理速率成反比,因此服务请求f的SFC节点处理时延为:

设有线链路传输时延与SFC负载Loadf成正比,与分配到的链路带宽资源Bf(t)成反比,因此服务请求f的SFC有线链路传输时延为:
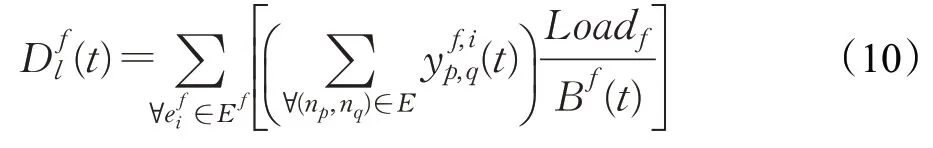
设无线传输时延与SFC负载Loadf成正比,与无线速率Cf(t)成反比,因此服务请求f的无线链路传输时延为:

由此可得,服务请求f的总时延为:
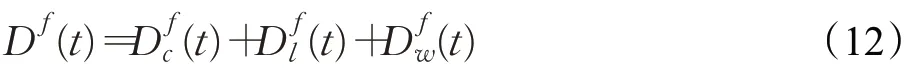
综上所述,本文的优化目标可归纳如下:

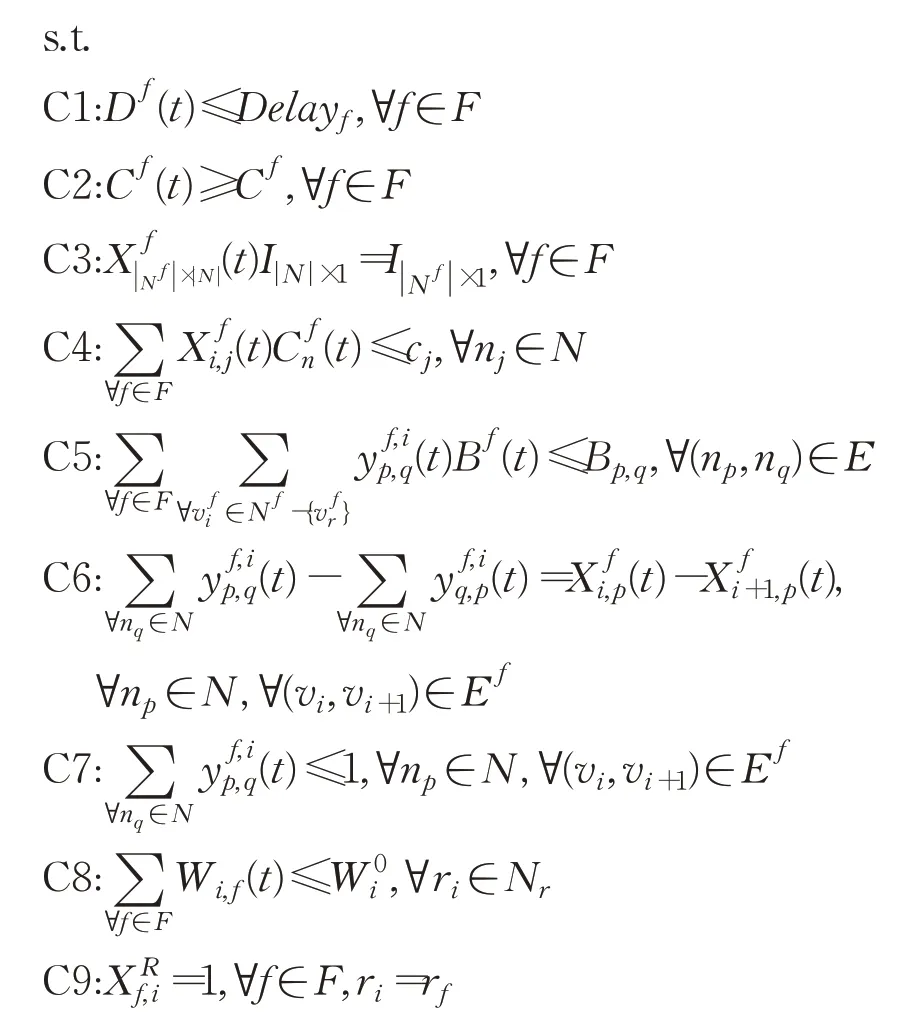
其中,C1表示各个服务请求的时延要求,C2表示各个服务请求的无线速率需求,C3 表示每个VNF 必须映射到一个物理节点上,C4 表示每个物理节点计算资源的容量限制,C5表示每条物理链路带宽资源限制,C6表示物理节点流守恒,C7表示SFC是一条不可分离流,C8表示SBS 无线子载波资源容量限制,C9 表示用户的vr必须映射到与之关联的SBS上。
2 基于DDPG的SFC多维资源联合分配算法
上述模型中的环境状态是动态变化的用户信干噪比,状态空间具有马尔科夫性且为连续值[10],同时,模型中的决策变量包括每个用户的子载波分配及其SFC 中每一个VNF 的部署,维度较高。马尔科夫决策过程(MDP)是序贯决策的数学模型,用于系统状态具有马尔科夫性质的环境,通过与环境的不断交互来获得更大的收益。因此上述优化问题可转化为具有连续状态空间和高维度动作空间的离散时间MDP模型。深度确定性策略梯度(DDPG)算法是一种基于行动者-评论家(Actor-Critic,AC)算法架构的深度强化学习算法[9],在智能决策问题中具有良好的性能优势。它利用神经网络从连续状态空间和高维动作空间中提取特征,并结合了深度Q网络(Deep Q Network,DQN)算法中“经验回放”(Experience Replay)和“固定目标网络”(Fixed Target Network)的思想,可以使算法在MDP 中达到理想的收敛速率和稳定性[11]。因此,本文提出一种基于DDPG的SFC多维资源联合分配算法求解上述优化模型。
2.1 问题转化
根据本文建立的SFC部署优化问题,将该优化问题转化为一个具有连续状态空间和高维度动作空间的无模型MDP模型。MDP由一个四元组表示<S,A,Pr,r >,S表示状态空间,A表示动作空间,Pr表示状态转移概率,r表示奖励函数。其中,状态空间S由时隙t各个用户无线端可能的信干噪比组成,因此时隙t系统的状态为:
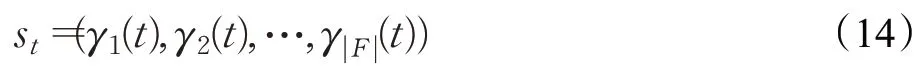
动作空间由用户无线端子载波分配和VNF映射矩阵组成,则时隙t的动作为:
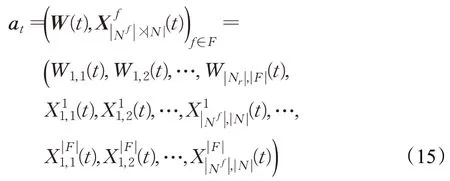
根据本文构建的基于环境感知的SFC 资源分配机制,以子载波分配W(t)所得到的用户可达的无线速率作为用户SFC计算资源和链路带宽资源分配的依据,并通过映射矩阵将 SFC 中各个 VNF 映射到满足资源容量约束的物理节点上,完成部署。
状态转移概率Pr可表示为:
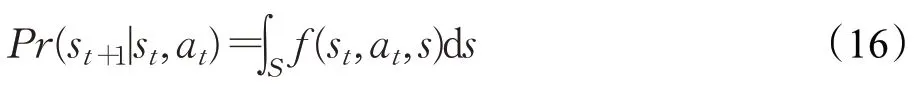
其中,f(·)为状态转移概率密度函数。由于本MDP 中状态空间为用户在无线环境中的信干噪比,无法直接量化其状态转移概率,因此将其视为未知概率。所谓“无模型”MDP,即状态转移概率难以求得,不依赖于环境的MDP模型。
当环境处于状态st时执行动作at,系统会进入下一状态st+1,并得到即时奖励rt,本文优化目标为SFC的部署总成本,因此将成本的相反数设为奖励函数,即:

动作a的来源为一个确定性策略π,由策略π可得到每个时隙的子载波分配和SFC部署决策,π为状态空间S到动作空间A的一个映射,可表示为:

动作值函数Q(s,a)表示从当前状态并采取某一动作后执行某一策略得到的累计奖励的期望值,即在一段时间k内的累积部署成本Cost(t)的相反数,因此在状态s根据策略π采取动作a的动作值函数可表示为:
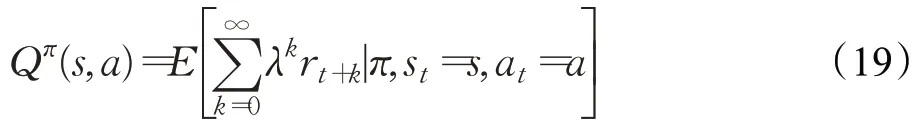
其中,λ∈(0,1)为权衡各个时刻回报函数的折扣因子。Q函数的迭代形式称为贝尔曼方程(Bellman Equation),如下式所示:
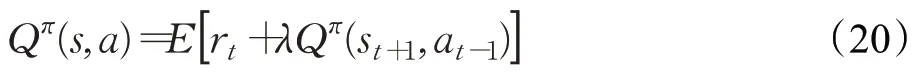
定义一个策略目标函数J(π)来衡量策略的性能表现,它表示为动作值函数的均值,如下式所示:
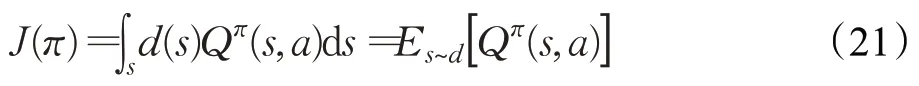
其中,d(s)为状态空间的分布函数。该MDP 模型的优化目标即为,找到一个子载波分配和SFC 部署策略π,使Q函数的期望值最大,从而达到本文最小化SFC部署成本的优化目标,即:

2.2 DDPG算法框架
本文需要在NFV框架下对无线用户进行子载波分配和SFC的部署,由式(14)和式(15)可知其状态空间和动作空间维度极大且状态转移概率Pr未知,无法通过式(20)的贝尔曼方程进行迭代获得Q值。由此,深度强化学习利用神经网络从高维空间中提取特征,从而输出Q值的近似值,解决了维度过高的问题。在各类深度强化学习中,DDPG算法在AC算法的基础上结合了DQN算法中“经验回放”和“固定目标网络”的思想,相比于AC算法提高了稳定性与收敛性。
DDPG算法架构如图3所示,其智能体(Agent)包括Actor 和Critic 两部分。其中,Actor 负责构建参数化的策略,根据当前状态输出动作,Critic 负责构建Q 网络,根据环境反馈的奖励值来评估当前策略,输出时间差分(Temporal Difference,TD)误差(目标Q 网络与在线Q网络输出之差)来更新Actor 和Critic 两部分的参数,使MDP的优化目标J(π)最大化。所谓“经验回放”是指设置一个存放状态转移过程<st,at,rt,st+1>的经验池,它将每一次与环境交互的过程记录下来,每次训练时从经验池中随机抽取小批量状态转移过程进行学习,其目的是为了打破学习样本中数据间的时间相关性,这样网络可以从过去更广泛的经验中进行学习而不仅仅局限于当前环境[9,12]。由于状态空间和动作空间的高维性,在Actor和Critic两部分智能体中,均使用神经网络来构建参数化的策略和动作值函数,而神经网络往往因其目标值的参数与估计值的参数同时变化,从而导致学习过程不稳定和发散。DQN中“固定目标网络”的方法可以有效解决这一问题,即在用一个神经网络估计值的同时,建立另一个神经网络作为目标网络,其参数在一定的迭代过程中保持不变,经过指定迭代次数后再用当前评估网络的参数替换该目标网络的参数,这种目标网络的更新方式称为“硬更新”(Hardupdate)。与DQN 算法不同的是,DDPG 采用“软更新”(Softupdate)的方式来更新目标网络参数,即每一步都会更新目标网络,但更新的幅度非常小,这样做使学习过程更接近于监督式学习[9,13]。研究表明,使用上述目标网络的方法可以使神经网络的收敛过程更加稳定。
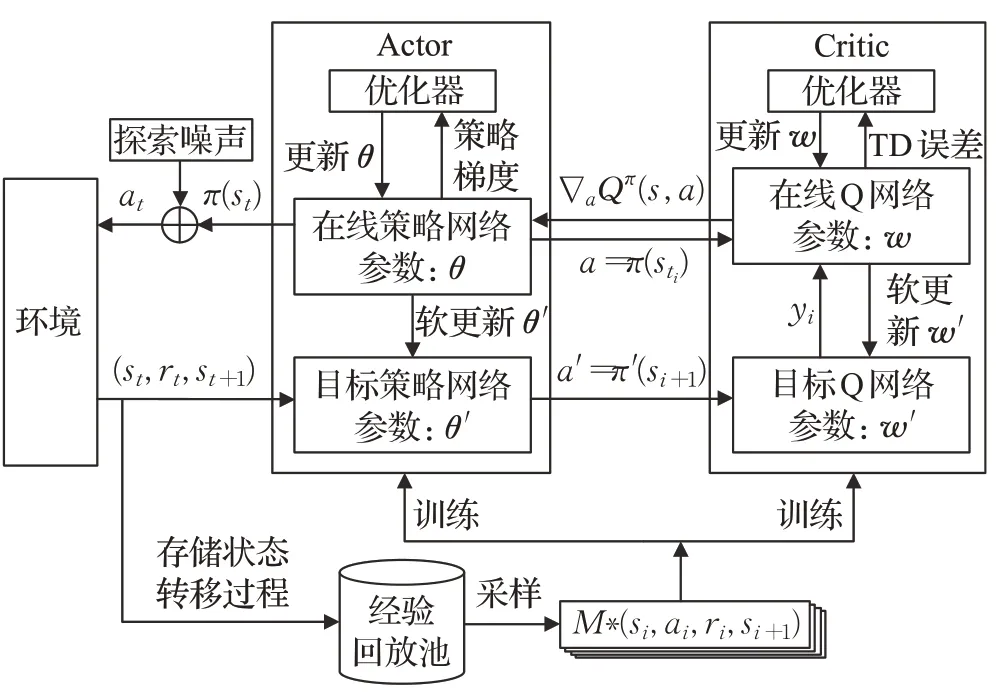
图3 DDPG算法架构
2.3 算法描述
2.3.1 Critic部分
在DDPG 算法中,Critic 部分利用两个神经网络来估计Q 值,从而评估当前策略。其中一个神经网络为“在线Q网络”,其参数设为w,在线Q网络的输出为动作值函数的估计值Qw(st,at),另一个神经网络为“目标Q 网络”,其参数为w′,输出为动作值函数的目标值yt,有:

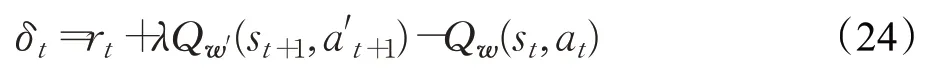
训练时,将从经验池中随机抽取M组状态转移过程<si,ai,ri,si+1>进行训练,根据损失函数来更新在线Q 网络的参数w,Critic 的损失函数L(w)定义为TD 误差的均方值:
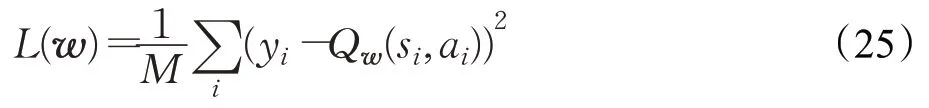
利用损失函数L(w)关于参数w的梯度,使用梯度下降法来更新在线Q网络的参数,使w朝着L(w)下降的方向进行更新,即:
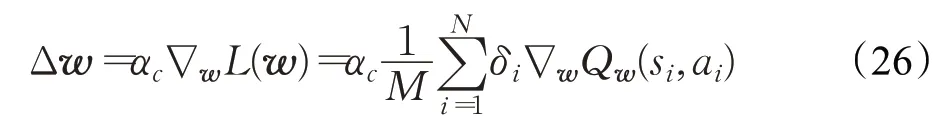
其中,αc为Critic 的学习率。同时,使用上述“软更新”的方式更新目标Q 网络的参数w′,设置“软更新系数”τ来控制每一步目标网络更新的幅度,则目标Q网络的更新方式为:

2.3.2 Actor部分
DDPG算法的Actor部分负责构建参数化的策略并根据状态输出动作。与Critic部分一样,Actor也使用了两个神经网络来构建参数化的策略,分别为“在线策略网络”和“目标策略网络”。其中,目标策略网络用于构建目标策略πθ′(s),其参数为θ′,其输出为目标Q网络提供动作a′=πθ′(s),用于式(23)计算动作值函数的目标值yt,从而计算TD误差;在线策略网络用于构建在线策略πθ(s),其参数为θ,为整个智能体输出动作a并与环境进行交互,其参数采用策略梯度算法进行更新[14]。由于在DDPG算法中,用神经网络来输出Q值,则可将式(21)中的Qπ(s,a)用在线Q网络的输出Qw(s,a)代替,则策略目标函数J(π)可改写如下:
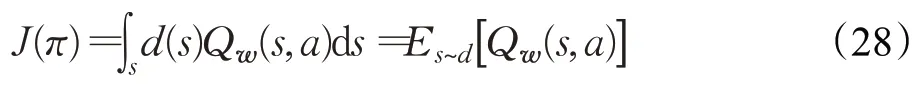
策略梯度是指策略目标函数J(π)关于参数θ的梯度,表示为:
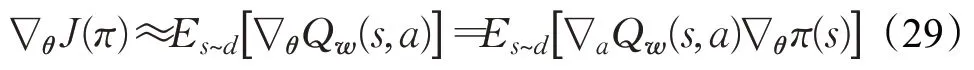
与Critic相同,Actor的训练样本也来自经验池中的M组状态转移过程<si,ai,ri,si+1>。于是,上述策略梯度可改写如下:
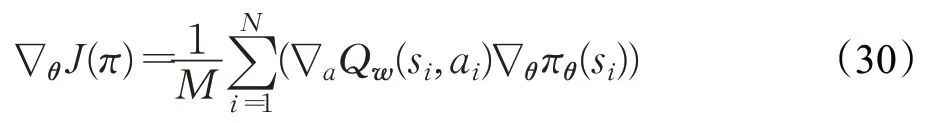
由此,可以得出Critic的参数更新公式为:

同样地,使用“软更新”方式对目标策略网络参数进行更新:

为了让智能体输出的动作有可能获得更大的奖励,为Actor 输出的动作增加探索机制(Exploration),即在在线策略网络输出的动作中加入一个随机的探索噪声noise,表达为:

探索噪声随着训练回合的进行不断减小,直到最终获得使奖励稳定且收敛的策略。
综上所述,可将基于DDPG的SFC多维资源联合分配算法归纳如下:
算法1基于DDPG的SFC多维资源联合分配算法


3 仿真与性能分析
本文通过 Python 3.0 和 TensorFlow、OpenAI gym等工具实现本文提出的基于DDPG 的服务功能链多维资源联合优化算法仿真,并使用Matlab绘图完成。为了评估本文所提机制及算法的有效性,现将其与文献[5]中的DP-COA启发式算法,以及其他两种强化学习算法策略梯度算法(Policy Gradient,PG)[14]和AC算法[10]进行性能比较。本文共设置10个物理节点,其中包括2个接入节点(SBS),每个物理节点拥有4个虚拟CPU(vCPU)资源,每个vCPU 的数据处理速率均为160 Mbit/s,每一条物理链路总带宽为300 Mbit/s,每个接入节点的子载波个数为50,每个子载波带宽为0.18 MHz[15]。3个成本权重因子分别设为ρc=0.4,ρb=0.2,ρw=0.4[7]。学习过程中,训练共进行500 个回合,每回合200 步,经验池大小M设为10 000,因此每当回合数进行到50 时,经验池填满,开始学习。
首先,对于强化学习算法,学习率是影响算法收敛速度和决策性能的关键因素。图4 描绘了当有10 个用户请求,且性能需求为无线速率需求为20 Mbit/s以及用户平均时延要求为20 ms时,在不同学习率下算法的收敛效果。从图4 中可以看出,当训练过程到达50 回合时,经验池填满,算法开始从经验池中批量抽取状态转移过程进行学习,SFC 部署成本开始迅速下降。当Actor 学习率αa为 0.001、Critic 学习率αc为 0.01 时,算法收敛快速稳定,且系统成本最低,表现出良好的性能优势。因此本文在后续的仿真中均选择αa=0.001,αc=0.01 为DDPG算法的学习率。
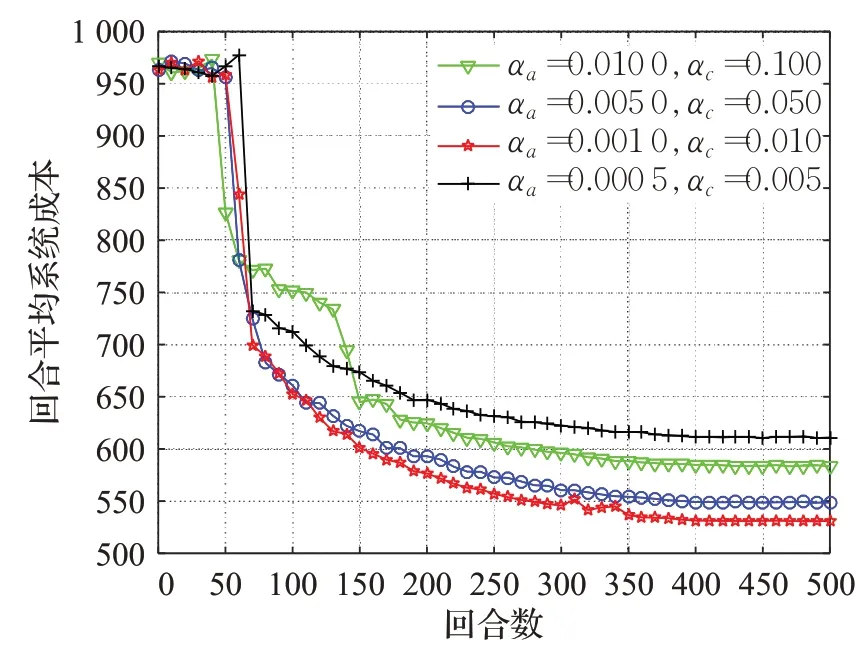
图4 不同学习率下DDPG算法的收敛效果
图5 描绘了三种基于策略的强化学习算法PG、AC以及DDPG 算法应用于本文模型的收敛效果和性能表现,三种算法均为可以解决高维度动作空间MDP 问题的强化学习算法。从图中可以看出,对于复杂环境,PG算法难以达到一个理想的收敛效果和性能优化,AC 算法在收敛速度方面也不及DDPG 算法。其原因为,PG算法是单纯的策略梯度算法,相当于DDPG 架构中的Actor部分,只能通过自身的策略梯度进行参数更新,缺少相应的评判部分(Critic)对其输出的策略进行评估,因此对于复杂环境,PG 算法的智能体难以找到正确的参数更新方向,导致其收敛过程不稳定。而AC算法的智能体包含Actor 和Critic 两部分,其中Actor 负责构建参数化的策略,根据环境状态输出相应的动作;Critic负责输出Q值,对当前Actor中的策略进行评估,帮助策略网络参数朝着可以获得更大Q值的方向进行更新,因此AC算法可以得到比PG算法更好的优化效果。然而AC算法由于其智能体包括Actor和Critic两部分,存在收敛过程缓慢的问题,DDPG针对这一问题,在AC算法架构的基础上结合了“经验回放”和“固定目标网络”的思想,训练时从经验池中随机抽取部分状态转移过程进行学习,打破了学习样本中的时间相关性,这样可以从过去更广泛的经验中进行学习而不仅仅局限于当前环境;固定目标网络可以为Critic 的训练提供稳定的目标Q 值,使得学习过程更加稳定,保证了Critic 网络输出Q 值的准确性,从而加快了Actor 中策略网络的收敛。因此,DDPG 算法的收敛效果强于PG 和AC 算法。
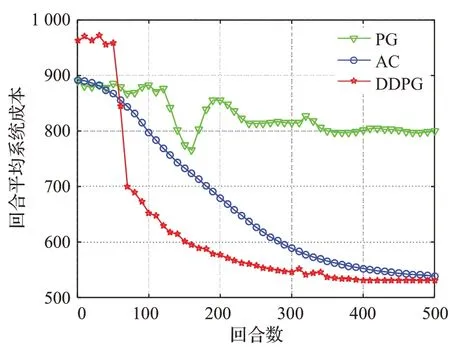
图5 不同强化学习算法的收敛效果
接下来对在不同服务请求数下的算法性能进行比较。首先比较在不同用户请求数下的系统成本,用户无线速率需求设为20 Mbit/s,如图6所示。可以看出本文所使用的DDPG算法在三种不同在线人数情况下,系统总成本均处于最低。AC 强化学习算法由于其收敛缓慢,随着用户请求数的增加,其性能表现逐渐差于启发式算法DP-COA。而DDPG算法由于在AC算法的基础上结合了经验回放和目标网络方法,因此保证了算法收敛的稳定性,并具有良好的性能表现。在时延优化方面,从图7可以看出,DDPG算法下的系统总时延在不同用户请求数下均处于最优。DP-COA为动态规划算法,它将每个时刻的SFC 部署按VNF 的顺序依次进行决策,面对复杂的网络环境,DP-COA 容易陷入局部最优。并且DP-COA算法考虑单纯的SFC部署问题,未将无线资源的分配联合考虑,对于无线用户没有完成完整的端到端服务。而DDPG 算法可以契合本文所构建的基于环境感知的SFC资源分配机制,从而解决无线用户SFC 部署与无线资源的联合优化问题。由此可见,DDPG 适用于更复杂的网络场景,在扩展性方面强于DP-COA启发式算法。
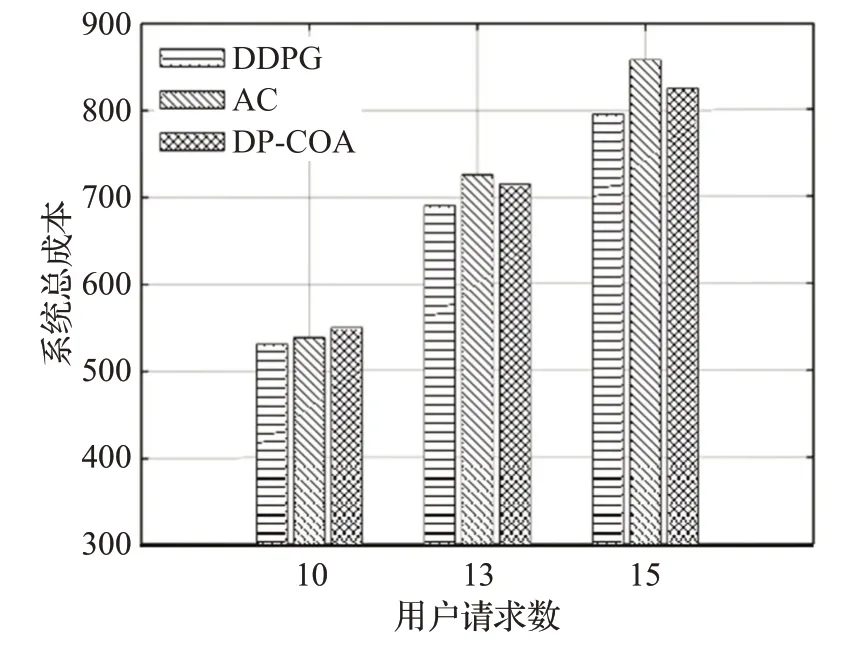
图6 不同用户请求下的系统总成本对比
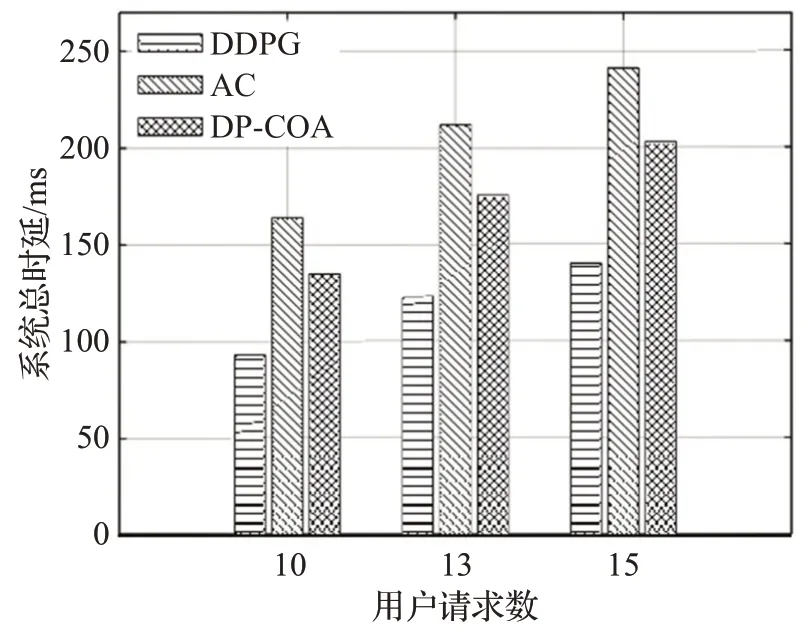
图7 不同用户请求下的系统总时延对比
图8 描绘了三种算法在不同无线速率需求下的性能对比,用户请求数设为10。如图8 所示,当无线速率需求较小时,三种算法在系统总成本上的性能表现相差不大,但随着无线速率需求的增大,DDPG 算法在该性能上的优势逐渐体现出来,且强化学习算法(DDPG、AC)对系统总成本的优化效果整体优于启发式算法DP-COA。图9 描绘了在不同无线速率需求下的系统总时延对比情况。可以看出,DDPG算法在三种无线速率需求下的时延性能优势较为明显,AC 算法由于其自身收敛缓慢,其时延性能表现不如启发式算法DP-COA,再次说明了DDPG 算法中的经验回放和固定目标网络方法的有效性。
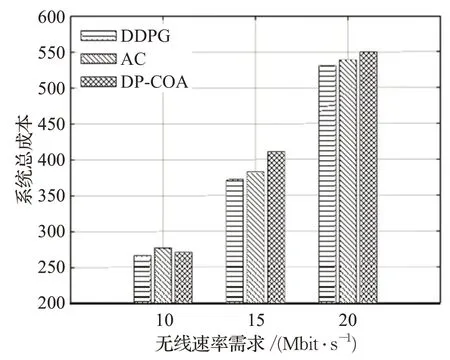
图8 不同无线速率需求下的系统总成本对比
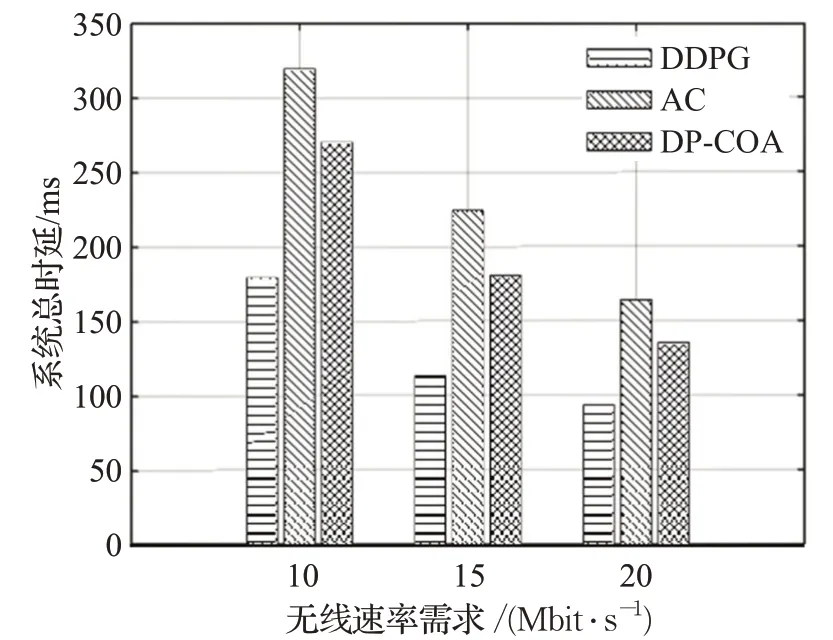
图9 不同无线速率需求下的系统总时延对比
4 结束语
针对NFV下的无线用户SFC请求的低成本部署问题,本文联合考虑SFC 部署与无线资源分配,构建了一种基于环境感知的SFC资源联合分配机制,并据此建立了在满足用户时延要求、无线速率需求以及资源容量约束下的SFC部署成本最小化模型,并将该优化模型转化为具有连续状态空间和高维度动作空间的无模型MDP模型,提出一种基于DDPG的SFC多维资源联合分配算法求解该优化问题。仿真结果表明,在上述SFC部署机制下,使用该算法进行求解,可在保证用户性能需求的同时,有效降低SFC部署成本和时延。
