用于文本聚类的新型差分进化粒子群算法
2021-02-22胡晓敏王明丰张首荣
胡晓敏,王明丰 ,张首荣,李 敏,2
1.广东工业大学 计算机学院,广州 510006
2.广东工业大学 信息工程学院,广州 510006
聚类是一种无监督的机器学习任务,其目的是将数据集按照某种结构或者相似度进行分组,划分为若干数目的簇集,同时尽可能保证同一聚集内的数据样本尽量相似,而使属于不同类别的样本具有明显差别。随着文本资源的急剧递增,信息检索[1]、主题分析数据[2]和社交网络[3]等领域对文本挖掘与分析的迫切需求,文本聚类也越来越得到重视[4]。
K-均值(K-means)算法是最早用于聚类的无监督算法,该算法实现简单,收敛速度快,但也存在对聚类中心初始值十分敏感,并且容易陷入局部最优解的缺点。而文本作为一种特殊的非结构化的数据,具有维度高、特征稀疏和数据关联性低的特点,该算法应用于文本聚类时,其缺点则会明显凸现出来,最终造成聚类效果差、早熟收敛的结果[5]。
为了提高文本聚类的性能表现,很多学者利用基于元启发式的群体智能进化算法来改善聚类中心的更新方式。例如文献[6]提出一种特征选择方法用于粒子群优化(Particle Swarm Optimization,PSO)中提高文本聚类的性能。文献[7]提出基于自适应惯性权重函数的PSO与K-means结合的聚类算法,并在医学电子病历数据上取得较高的聚类准确率与执行效率。文献[8]提出利用随机样本的中位值来初始化聚类中心,并且划分子种群进行更新,然后再合并动态差分进化(Differential Evolution,DE)算法用于聚类。由于单一的进化算法无法在稳定性、收敛速度、搜索能力等方面都具备良好表现,尝试利用混合算法进行聚类成为一种可行的方案。文献[9]提出利用全局优化能力较好的遗传算法(Genetic Algorithm,GA)进行聚类,随后从最优个体划分各样本簇集中随机选择的样本作为个体聚类中心的初始值,再用量子PSO算法进行聚类的混合遗传量子粒子群(Genetic Quantum PSO,GQPSO)算法。文献[10]提出将种群中的个体按照适应度值进行排序,并且划分为两个子种群,随后在两个子种群中分别采用PSO 和GA 算法进行更新的遗传改进粒子群(Genetically Improved PSO,GAI-PSO)算法。
上述算法在初始聚类中心优化、更新方式、全局优化能力等方面进行改善,取得了一定成果。但在场景更普遍、维度更高的文本聚类方面鲜有应用,并且忽视了个体间各维度聚类中心排列的一致性问题,即聚类中心排列顺序完全随机的两个个体在同一维度上的聚类中心可能属于间隔较远的簇集,该现象在一定程度上会影响个体更新效率与学习效果。
因此本文提出一种自适应调整聚类中心排列顺序的方法用于改善种群个体学习效率,并首先利用多样性更好的DE算法进行初步聚类,然后当算法收敛停滞后,再利用PSO 算法进行更稳定的局部搜索。该混合聚类算法IDEPSO充分发挥了各算法在不同时期的优势,并提高了个体间的学习效率,有效避免了算法搜索的盲目性。通过在文本数据集上进行测试,验证了此算法是一种稳定高效的算法。
1 背景
1.1 文本聚类相关基础
在进行聚类之前,文本形式的非结构化的数据需要转换为计算机程序容易处理的格式。向量空间模型(Vector Space Model,VSM)是一种常用并且效果良好的转换模型[11]。在VSM 模型中,每个文本可表示为其包含的关键词组成的向量,向量的维度为整个文本数据集不同关键词的总数,每一维度的权重采用tf-idf计算,该权重综合考虑了每个关键词在其所在文档中出现的频率tf和在整个文本数据集中的分布情况idf这两个因素的共同作用。
文本数据集转换为tf-idf向量矩阵后,具有维度高、特征稀疏、空间结构复杂的特点,因此一般采用向量夹角余弦值来表示文本之间的相似程度。文本向量之间的夹角越小,余弦值越大,则文本之间的相似度越高。对于文本向量di和dj,其相似程度的计算公式如下:

1.2 粒子群优化算法
粒子群优化(PSO)算法[12]是一种基于群体智能理论的进化算法,其基本思想为:随机初始化一定数目的种群,其中每个个体代表待解决问题的一个潜在候选解,通过评价函数来衡量这个解的质量,然后个体通过自身的飞行行为和整个种群的飞行经验来更新速度,再结合速度调整飞行位置,最终朝解空间中的最优位置逐步逼近,直至最优解收敛稳定。PSO算法在第t次迭代对个体xi的速度和位置的更新公式如下:
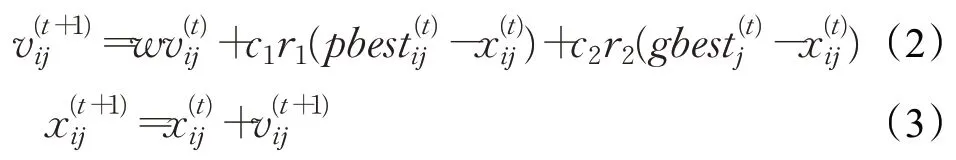
其中,w为惯性权重;c1和c2为加速因子;i=1,2,…,N,N代表种群规模;j=1,2,…,D,D为个体的维度;pbesti代表个体i自身找到的最优解;gbest为全局最优解;r1和r2为[0,1]间的随机数。
PSO 是一种实现方式和参数设置简单且快速高效的算法。但在优化目标过于复杂且有多个局部最优解,或搜索空间维度高、规模大时,随着时间的推移,种群中个体之间的差异逐渐缩小,种群个体在固定区间波动,最终使得算法陷入局部最优解并无法跳出[13-15]。经过多年的发展,在PSO 应用于数据挖掘的过程中,目前已有许多成熟的改善PSO 算法缺陷的方法。例如文献[16]采用一种社团划分的方法减少初始化过程中的冗余信息来提高初始化种群的质量;文献[17]在种群更新过程中加入混沌搜索和动态因子增加总群的多样性;而文献[18]则提出一种基于混合互信息和粒子群算法的自适应突变策略扰动种群,避免其陷入局部最优解的方法。
1.3 差分进化算法
差分进化(DE)算法[19]是一种多样性较好的进化算法,它通过随机选择种群中的个体构造差分向量,然后基于某个个体或自身历史最优个体作为目标向量进行交叉融合构造后代,最后根据适应度值选择是否更好来更新个体产生新的种群。
DE算法通过向量变异、交叉、选择三个步骤产生新的个体。对于标准DE 算法,种群中的每个个体都是通过以下公式进行变异操作:
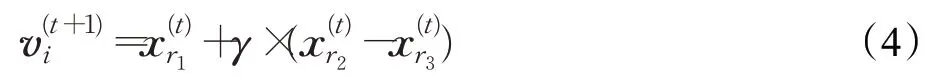
其中,i=1,2,…,N;r1,r2,r3∈{1,2,…,N}为互不相同且不同于i的随机数;γ为变异因子,控制差分向量的比重。然后根据以下公式对变异后的个体进行交叉操作得到临时个体
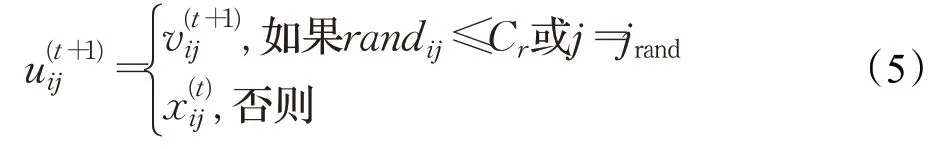
其中,i=1,2,…,N,j=1,2,…,D,jrand∈{1,2,…,D}为随机数,randij为[0,1]间的随机数,Cr为[0,1]间的交叉概率。最后通过竞争选择策略产生新种群中的个体:
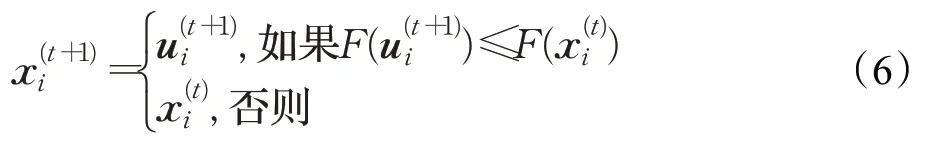
若交叉操作得到的个体不差于原来的个体,则替换原个体作为新一代的个体,否则新一代的个体仍为原个体。
2 IDEPSO聚类算法
2.1 问题定义与评价函数
进化算法采用基于划分的方式进行聚类时,种群每个个体表示一种划分方案。若文本数据集需要划分为K个类别,则每个个体xi包含K个聚类中心向量,可表示为xi=[mi1,mi2,…,mik,…,miK],其中mik表示第i个个体的第k个聚类中心向量。算法的优化目标为使各个簇集的相似度总和尽可能大,各簇集的相似度为该簇集包含的全部样本到其聚类中心向量的相似度总和,因此个体i的评价函数的计算方式为:
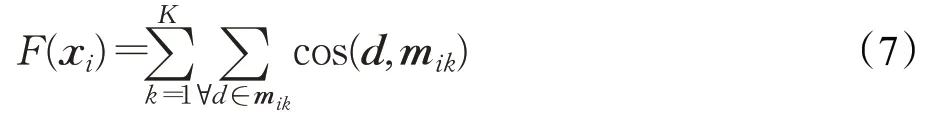
其中,d为该个体第k个簇集所包含的每一个文本向量样本。F越大表示聚类效果越好。
2.2 自适应调整聚类中心排列顺序
由于种群个体的聚类中心排列顺序完全随机,包含K个聚类中心,共有K!种排列方式。当个体间进行诸如pbesti-xi,gbest-xi这类交叉操作时,会出现不同簇集上差别较大的聚类中心出现在同一维度上的情形。例如有两个个体xi={a1,b1,c1},xj={b2,c2,a1}(字母相同表示聚类中心相似度最高)属于同一簇集,但这两组聚类中心向量的排列完全错开。在速度更新过程中,它们进行向量加减操作时,将无法为个体提供有效的搜索经验,从而影响个体间的学习效果,甚至误导个体朝着脱离最优解的方向搜索。
鉴于上述情形,本文提出一种基于个体间聚类中心向量相似度矩阵的自适应调整聚类中心向量排列顺序的方法。该方法基于相似度大小的双向选择与淘汰策略,尽可能将相似度最高的两个聚类中心向量排列在同一维度。以个体xi和xj为例,自适应调整聚类中心向量排列顺序的方法的步骤如下:
(1)假设以xj的聚类中心排列顺序为基准对xi进行调整,计算xi与xj各聚类中心之间的相似度矩阵M。
(2)分别统计M各行、列上相似度最大值的索引列表Lij和Lji,分别表示xi与xj期望与对方的聚类中心形成对应关系的列表。
(3)若Lij存在重复值t,则存在对应关系冲突,即xi存在两个及以上的聚类中心都对应于xj中同一个聚类中心此时由xj(t)从Lji中选择与自身最近的聚类中心xi(s)构建对应关系,确定的对应关系组合为(xi(s),xj(t))。
(4)将M第s行第t列除M[s][t]以外的其他相似度值都重置为最小值,防止其他聚类中心继续选择与它们组成对应关系组合。
(5)重复(2)~(4)直到Lij中不存在重复的值,即xi不存在两个及以上的聚类中心对应于xj中的同一个聚类中心,最后按照Lij调整xi中各聚类中心排列顺序。
下面给出调整前xi与xj各聚类中心之间的位置(图1(a))与相似度矩阵M(表1)的例子。图中颜色相同的聚类中心表示在同一维度。可以看出由于聚类中心排列的随机性,相近的聚类中心并没有获得相同的标号,在相似度矩阵上则体现在每一列的最大值不在对角线上。相似度值越大体现两个聚类中心位置越靠近。因此,通过调整聚类的排列,使得位置接近的聚类中心获得相同的聚类排列号。
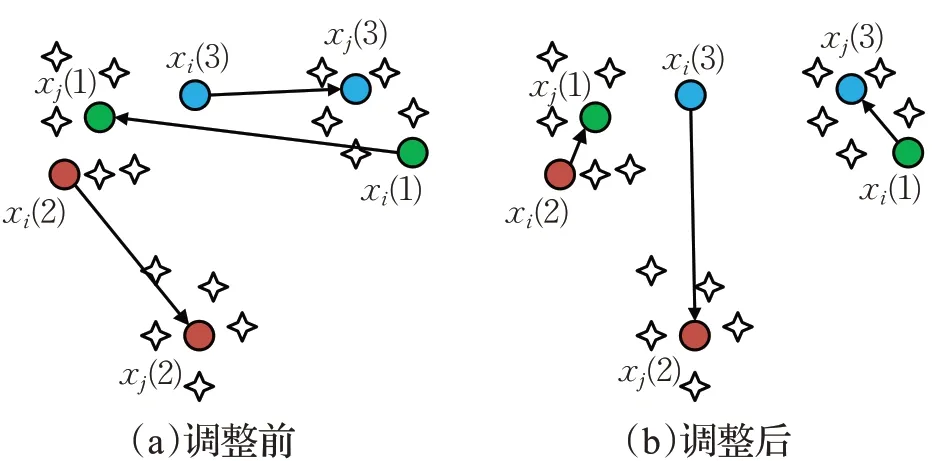
图1 K=3 时两个个体聚类中心调整前后示意图
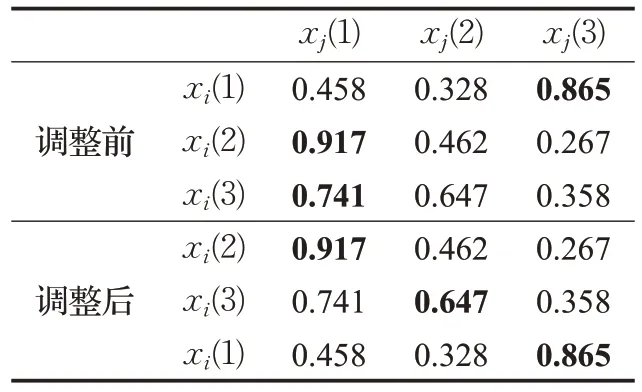
表1 聚类中心调整前后的相似度矩阵M
当以xj各个聚类中心排列为基准,根据表1调整前xi与xj各聚类中心相似度矩阵列表M可知,各行各列的最大值索引列表分别为Lij=[3,1,1]和Lji=[2,3,1]。这说明xi(2)、xi(3)均期望与xj(1)配对,此时产生冲突,从表1调整前的相似度列表或Lji可以看出xj(1)与xi(2)相似度最大,因此选择与xi(2)配对。由于xi(3)竞争失败,开始选择与xj其他聚类中心xj(2)配对,Lij调整为[3,1,2](该过程在实际情况下可能会根据Lij产生冲突的次数反复进行)。最终Lij不存在冲突后,按照Lij调整xi各聚类中心的排列顺序为{xi(2),xi(3),xi(1)},与xj的相似度矩阵列表如表1调整后的表格所示,聚类中心分布情况如图1(b)所示。可见xi个体原来的聚类中心排列由(1,2,3)调整为(2,3,1)。可以看出调整后两个个体基本上在同一维度上的两个聚类中心相似度最大。调整后再进行个体间的交叉操作能使产生的差分向量更具有引导性。
2.3 算法实现流程
PSO是一种高效稳定的进化算法,但在搜索空间庞大的文本聚类过程中,随着迭代次数增加,种群容易陷入局部最优解。因此可以采用多样性更好的DE算法进行初步搜索,当算法在找到较理想的最优解并收敛停滞后,再利用PSO 进一步完善最优解的位置,尽可能优化出更理想的最优解。同时在种群迭代过程中,始终利用自适应调整聚类中心排列顺序的操作,提高种群的学习效率与收敛速度。该混合算法IDEPSO的实现步骤如下:
(1)构造数量为N的种群,对于种群中的每个个体xi(i=2,3,…,N),从数据集中随机选取K个样本对应的文档向量作为其初始值(mi1,mi2,…,mik,…,miK)。种群迭代次数t初始化为0。
(2)计算种群每个个体xi各聚类中心mik(i=1,2,…,N;k=1,2,…,K)与数据集中所有文本的相似度大小,然后样本归类至与其相似度最大的聚类中心所在簇集。
(3)计算每个个体的适应度值,设置每个个体xi的历史最优个体pbesti为当前个体,计算种群当前全局最优个体gbest。
(4)自适应调整参与种群更新的个体间聚类中心的排列顺序并采用标准DE 算法对种群进行更新,利用每个个体表示的一组聚类中心向量对所有样本进行划分,计算划分后每个簇集的聚类中心与适应度值,更新个体向量、种群的最优个体gbest。种群迭代次数t加1。重复该过程,直到gbest连续T代稳定不变。
(5)自适应调整参与更新的个体间聚类中心的排列顺序并采用标准PSO算法对种群进行更新,利用每个个体表示的一组聚类中心向量对所有样本进行划分,计算划分后每个簇集的聚类中心与适应度值,更新个体向量、每个个体xi的历史最优个体pbesti和种群当前全局最优个体gbest。种群迭代次数t加1。
(6)若步骤(5)找到更优个体则更新gbest,返回步骤(4);否则重复执行步骤(5)。当迭代次数t达到预设的最大迭代次数时,算法停止并输出最优个体的适应度值、聚类中心和样本划分的类别集合。
3 实验设计与数据分析
3.1 数据集与参数设置
本文实验部分选取文本挖掘领域通用的Reuters-21578 标准语料库(http://kdd.ics.uci.edu/databases/)和CMU 小组收集的 WebKb4 语料库(http://www.cs.cmu.edu/~TextLearning/datasets.html)作为实验测试数据集。这些测试数据集的具体信息如表2 所示。其中算法测试的聚类数量K的值为表中的主题数。
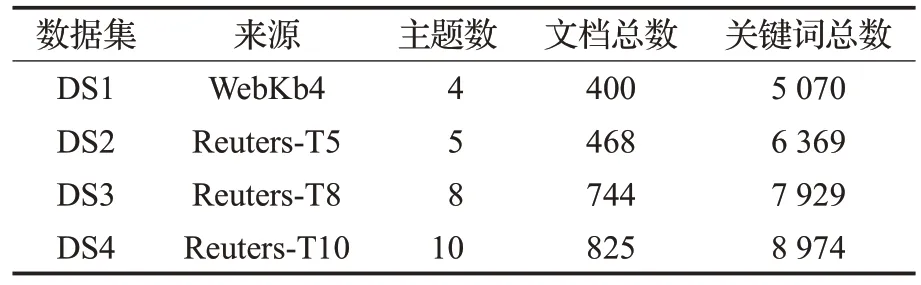
表2 测试数据集
本实验比较未添加聚类中心排列调整的DEPSO算法和添加了该操作的IDEPSO 算法,与传统PSO、DE、GQPSO[9]、GAI-PSO[10]算法在4 个文本数据集上的聚类结果。本文算法采用的参数设置均为标准PSO 和DE算法的推荐取值[20-21],对比算法的参数按文献给出的取值设置如下:w=0.9,c1=c2=1.495,γ=2.0,Cr=0.7 。所有算法的默认种群规模为20,种群的最大迭代次数为150。为了减少初始种群的随机性对算法比较的影响,实验中对于同一次独立测试,各个算法采用相同的随机初始种群。所有算法独立运行20次。
3.2 聚类评价标准
聚类算法的聚类效果的评价标准可分为内部评价和外部评价。内部评价指标采用所有文本到距离它最近的聚类中心的余弦相似度的总和F(适应度函数),该评价指标能有效评估聚类的紧密程度。外部评价指标采用 ARI(Adjusted Rand Index)和 FMI(Fowlkes-Mallows Index)。
ARI是在兰德系数基础上考虑样本随机划分的情况下的聚类评价模型,其计算方式为:
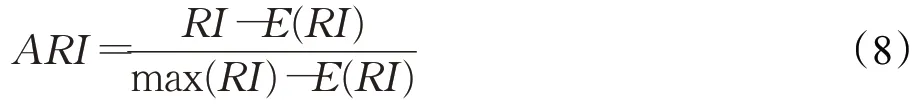
其中,RI为兰德系数,ARI取值范围为[-1,1],值越大则预测样本分布与实际情况吻合程度越高。
FMI是比较样本的预测类别和真实类别的一个有效指标,FMI定义为预测精度与召回率的几何平均值。
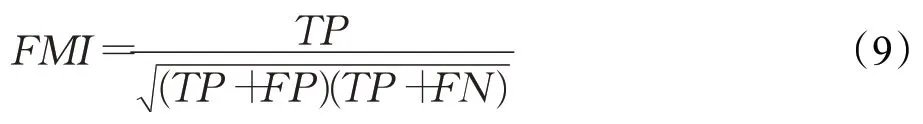
其中,TP表示真阳性,即预测标签和真实标签相同的样本数量;FP为假阳性,即预测标签中类别不相同而在真实标签中相同的样本数量;FN为假阴性,即在预测标签中类别相同而在真实标签中不同的样本数量。FMI的上限值为1,值越大表示与样本真实标签越匹配,FMI没有对簇的结构做出假设,非常适合用来比较聚类算法的性能。
3.3 实验结果与分析
3.3.1 种群规模对算法性能的影响分析
本文测试了种群规模N为10、20 和30 时DEPSO算法和IDEPSO 算法在最大函数评价次数为3 000 时的目标函数F的平均值,如表3 所示。这里采用最大函数评价次数是为了使种群规模不一致时算法的计算量相对均衡,这个计算量与种群规模为20 时最大迭代次数为150 代是相同的。从表中的数据可以看出,种群规模为30 时得到的平均值结果最优,规模为10 时结果最差。
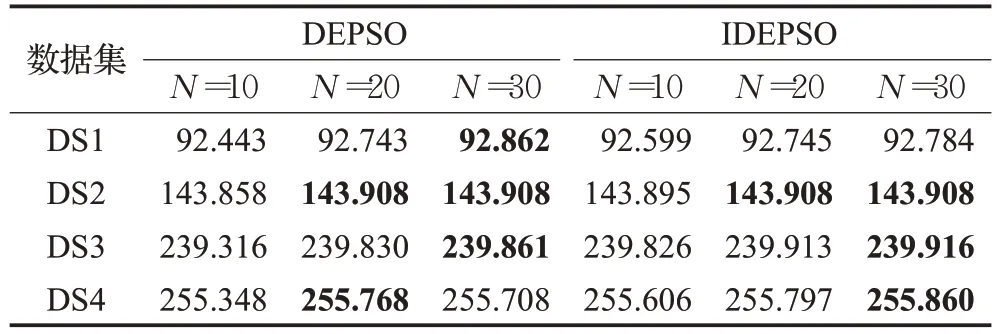
表3 DEPSO和IDEPSO算法在不同种群规模下F 平均值
图2 给出了这两个算法在不同种群规模时算法基于函数评价次数的平均迭代收敛曲线。种群规模越小,算法初始找到最优解的速度越快,但更容易陷入局部最优解而收敛停滞,最后得到的最优解质量较差。种群规模越大,初始收敛速度越慢,但随着迭代进行,容易跳出局部最优找到更好的解。另一方面,可以看出IDEPSO算法的收敛速度比DEPSO 算法快,可见调整聚类中心编号的方法提高了算法的优化速度。
3.3.2 内外部指标分析
表4给出了各算法聚类后的内部评价指标,即评价函数F的平均值。从结果来看,结合了差分进化与粒子群优化的DEPSO 算法在4个数据集上进行聚类后所得F值的平均值都比其他算法表现更好。说明在DE算法收敛停滞后再利用PSO算法进行改善,能找到更好的最优解。添加了聚类中心排列调整的IDEPSO 算法获得了最优平均解。因此整体而言IDEPSO 算法在内部指标上具有较明显的优化能力,特别是在大数据集中,聚类中心排列调整的操作起到良好的效果。
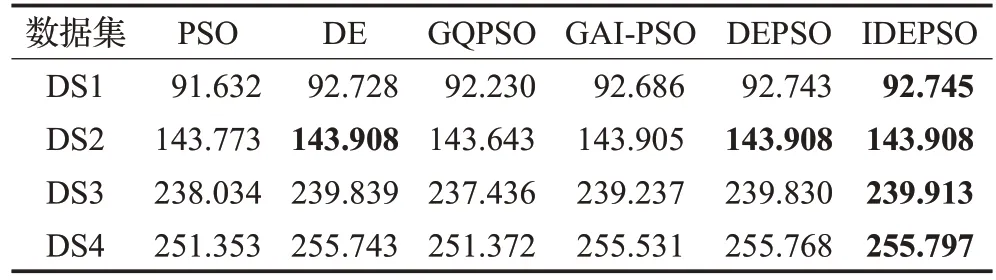
表4 各聚类算法在数据集上F 平均值
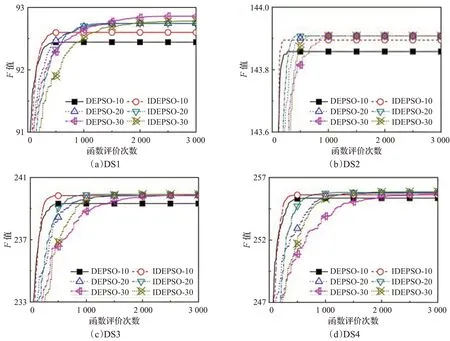
图2 不同种群规模下DEPSO和IDEPSO算法的平均收敛曲线
表5和表6分别给出了各算法在数据集上聚类后外部指标ARI和FMI的平均值。所有算法的结果与IDEPSO算法的结果进行W 检验,可以看出IDEPSO算法在外部指标上与PSO和GQPSO算法都有统计学的显著性区别,可以看出IDEPSO算法的结果更优。IDEPSO算法在外部指标上与其他算法的结果没有统计学差别。鉴于所有算法的优化都是基于F进行的,外部指标的结果反映聚类的结果是近似的。
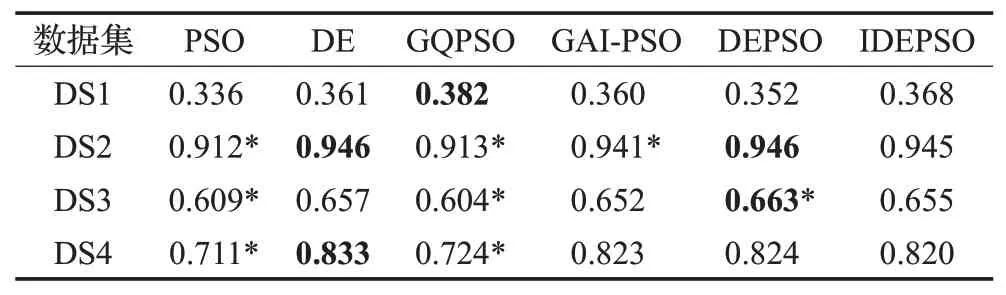
表5 各聚类算法在数据集上ARI 平均值
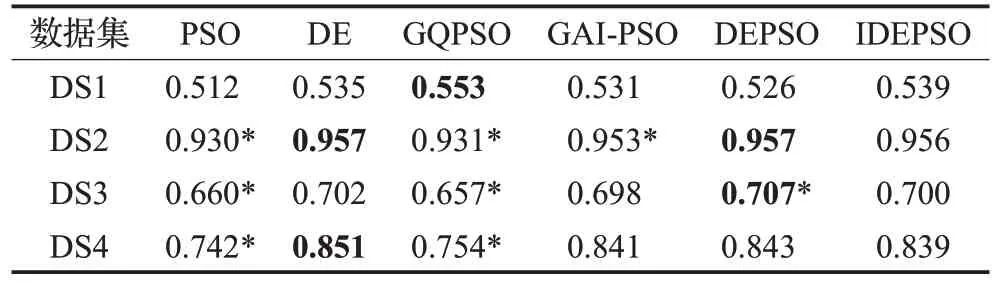
表6 各聚类算法在数据集上FMI 平均值
3.3.3 收敛速度分析
图3 给出了各算法在数据集上适应度值F的平均收敛曲线。从图中可以看出,PSO算法在四种数据集上的收敛曲线均十分陡峭,在短时间内就收敛至较差的适应度值,收敛速度最快,这印证了PSO 算法在高维度的聚类问题上容易收敛早熟,陷入局部最优解。GQPSO算法、GAI-PSO 算法的收敛速度也较快,最后取得最优解F比 PSO 算法稍好。DE、DEPSO 和 IDEPSO 这三个算法的F收敛曲线较接近,取得的平均适应度值F也最好,这说明DE 算法其多样性更好的优势适合高维度的文本聚类。但对比DEPSO算法与DE算法的收敛曲线,PSO算法在DE算法已取得的最优解的基础上做局部搜索,仍具有进一步的优化空间,这在样本数量更多、维度更高的DS4数据集上体现得更为明显。
而对比IDEPSO与DEPSO算法的收敛曲线,最终收敛稳定的最优解F值提高之外,其收敛速度比DEPSO算法更快,即在取得较理想的最优解的同时,所需的迭代次数和运行时间却更少,这较好体现了自适应调整聚类中心排列顺序的操作能提高种群的更新效率。因此对比各算法的收敛曲线图,证明了本文提出的新型差分进化粒子群算法更好地发挥了各算法的特点,将全局优化能力与局部优化能力充分运用在不同时期,并通过调整种群更新过程所参与的个体间的聚类中心的排列顺序,提高了算法的运行效率。
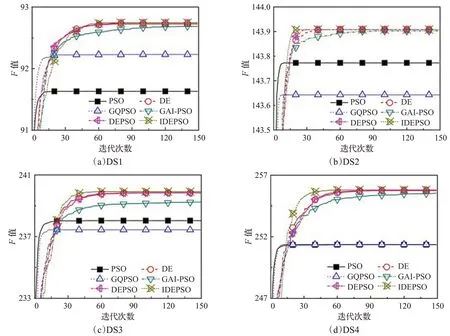
图3 不同算法在4个测试集上F 的平均收敛曲线
图4 给出了不同算法在数据集上测试的平均用时。可以看出DEPSO 和IDEPSO 算法的用时介于PSO和DE算法之间,GQPSO算法的用时最长,DE算法的用时最短。
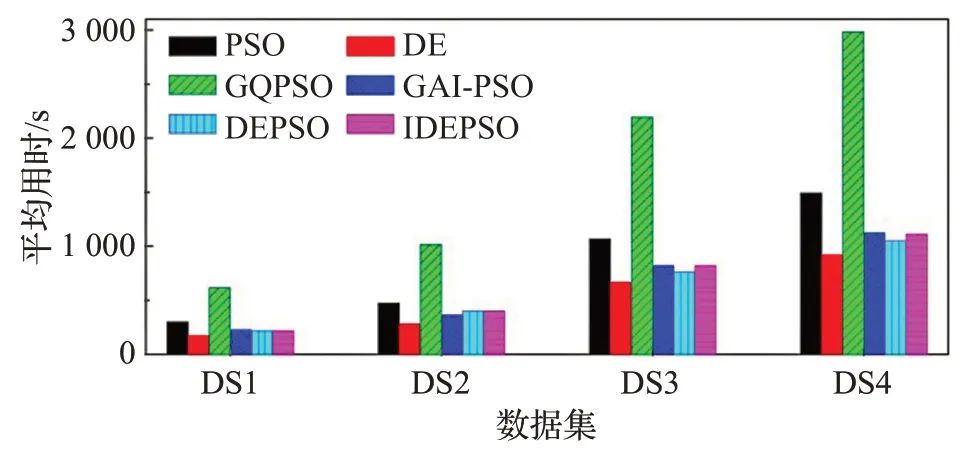
图4 不同算法在4个数据集上的平均运行时间对比
4 结束语
鉴于K-means 算法对初始聚类中心敏感但收敛速度快,PSO算法稳定可靠但在高维度搜索空间后期容易陷入局部最优以及DE 算法多样性较好的特点,本文提出一种混合DE和PSO的文本聚类算法,同时提出一种自适应调整聚类中心排列顺序的方法,用于改善个体的学习效率。该算法充分发挥不同算法在不同时期的优化能力和适用性,降低了初始聚类中心的影响,提高了个体学习效率,同时避免了陷入局部最优解。通过实验测试分析,这种新型聚类算法IDEPSO可有效解决大规模的文本聚类问题。本文参数设置、评价函数以及聚类中心初始化方式的设计只是依据通用的方案,因此在这些方面可做进一步研究,以创造出更有效的解决方案。
