模糊层次商空间的快速属性约简算法
2021-02-22李丽红
代 琪,李 敏 ,2,3,刘 洋,李丽红,2,3
1.华北理工大学 理学院,河北 唐山 063210
2.河北省数据科学与应用重点实验室,河北 唐山 063210
3.唐山市数据科学重点实验室,河北 唐山 063210
属性约简是粗糙集理论的重要研究内容,通过确定信息表达系统中条件属性的重要性,在保证信息系统性能不变的前提下,删除冗余属性,简化知识表达空间[1]。高媛等[2]针对较大样本集,提出了一种一致性样本约简策略,在满足一致性原则前提下,选择部分样本组成新的决策系统,提高算法的运算速度。孙妍等[3]通过构造极大相容块的辨识矩阵缩小矩阵的规模,简化计算属性约简过程,有效地节省计算时间和存储空间。米据生等[4]为了高效处理高维数据集,将图论与区分矩阵相结合,提出基于图论的粗糙集约简算法,有效地提高了运算速度及分类精度。Yu 等[5]提出两种基于最小元素选择树结构的属性约简算法,利用多种策略消除可分辨矩阵中的冗余元素,从而提高约简速度,降低运算成本。高阳等[6]为了减少算法时间成本,改进FHARA(Fast Hash Attribute Reduct Algorithm)算法,利用矩阵保留度量计算值的平方,将原本n维上的计算改进为1 维上的计算,从而降低了算法运算时间。Fan等[7]提出广义属性约简算法和广义正域计算算法,利用广义的不可辨性减少模型的粒度结构,构建多个不可分辨关系引起的定量度量,用于减少模型的计算成本。Fang 等[8]提出了在定性和定量标准下,基于三支决策和可辨矩阵的代价敏感近似属性约简算法,该算法将原始数据空间近似为一个低维空间,在低维空间上建模,提升了模型的运算时间。
传统属性约简算法的计算时间较长,难以应用于高维数据集,分析以上研究成果,学者们主要从两个角度对属性约简算法进行研究:一是,选择部分样本进行约简。文献[2-5]通过制定数据集提取规则,选取部分数据进行约简,在特定条件下提高了算法约简速度。二是,近似表示原始属性集。文献[6-8]通过设计定性或定量的计算标准,近似表示原始数据的属性特征。上述约简算法计算过程损失了部分数据或影响数据集分布特征,导致约简结果不能准确地表示属性间的重要程度,约简结果存在偏差。因此本文在不改变数据集结构的前提下,提出一种基于模糊层次商空间的快速属性约简算法(Fuzzy Euclidean Distance-Based Reduction Algorithm,FED-RA),缩短约简时间,提高算法计算精度。首先,结合隶属函数与欧氏距离,定义模糊欧氏距离;其次,利用模糊欧氏距离计算属性之间的相似程度,并应用层次商空间结构构建约简粒层空间;最后,以粒层空间聚类结果作为约简基础,实现样本集属性约简,并以KEEL 数据库中的公开数据集作为实验数据,验证算法的可行性及有效性。
1 基础知识
1.1 模糊欧氏距离
经典欧式距离主要是通过计算样本间的距离,度量样本的相似程度。
模糊集用于表示界限或边界不分明且具有特定性质事物的集合。模糊等价关系考虑的不是有无关系,而是关系的深浅程度。目前模糊集已被广泛应用到数据预处理中[9-11]。
定义1(模糊集)[12]设X是论域,X上的一个模糊集A是指 ∀x∈X,有一个指定的数μA∈[0,1],称为x对A的隶属程度,映射μA:X→[0,1],x→μA(x)称为A的隶属函数。
令T(X)表示X上一切模糊子集的集合,则T(X)实际上是μ:X→[0,1]这个函数组成的函数空间。
定义2(模糊欧氏距离)设一个数据集中有n个样本,μi(m)表示第m个样本在属性i上对应的隶属度,则定义属性i、j间的模糊欧氏距离为:

1.2 模糊等价关系的层次商空间结构
商空间理论是关于复杂问题求解的空间关系理论,其主要内容包括复杂问题的商空间描述、商空间的粒度计算、粒度空间关系的推理等[13-15]。
定义3[16]设U是一个有限域,是U上的一个模糊等价关系,D是的值域。集合称为的层次商空间结构。
推论1[16]在层次商空间结构中,关于U上的模糊等价关系,如果λ1>λ2,有
当λ增大时,层次商空间结构中的粒层空间逐渐细化,因此,以λ为基础实现样本聚类,当所有样本自成一类时,聚类结束。
2 模糊层次商空间的快速属性约简算法
2.1 学术思想
层次商空间是基于模糊集和商空间的多层知识空间表示。层次商空间的本质是采用模糊集思想将数据模糊化处理后,在不同的粒层空间上构建层次商空间结构,通过自底向上的方式描述属性或样本之间的等价关系,因此,利用层次商空间理论可以对论域进行不同划分,建立具有层次结构的商空间。然后通过分析空间中等价关系的结构或相关性,获取论域中的知识表示,从而实现知识与粒层结构之间的转化。
基于上述分析,层次商空间结构有利于从不同的粒层空间中分析属性之间的相关程度。本文提出的快速属性约简算法,采用模糊欧氏距离度量属性之间的相关程度,距离越小,属性相关程度越高。在层次商空间中,依次从相关程度较低的粒层空间中剔除属性,实现数据集的属性快速约简。但目前仍然是依靠专家经验选择隶属函数,根据数据结构或分布选取隶属函数有利于数据模糊化处理及属性快速约简,但也限制了模型的泛化性能。
2.2 算法流程
该算法的流程图如图1所示。

图1 算法流程图
算法具体计算步骤如下:
步骤1由于样本原始属性值存在量纲不同、取值范围不同等问题,选取柯西分布函数作为算法的隶属函数,对样本属性值模糊化处理。

其中,a是样本集中各属性的最小属性值。
步骤2利用模糊欧氏距离公式(1)计算属性间的模糊距离,根据粒层空间上各属性的等价关系,构建模糊关系矩阵。
步骤3构建属性间的层次商空间结构,根据层次商空间结构获得不同等价属性的粒层空间Ω1,Ω2,…,Ωn。λ值越小,商空间粒度越细,空间中包含的属性等价类个数越多[17]。
步骤4以层次商空间形成的粒层空间作为计算基础,选取λ值实现样本集的属性约简。
2.3 模型构建
在不同粒层空间上,应用CART(Classification And Regression Trees)决策树建模,分析分类结果,获得最佳粒层空间上的属性约简。
步骤1研究不同粒层空间中属性之间的等价关系,选择λ值获得不同的粒层空间。
步骤2在不同粒层上,属性总数是相同的,但空间中存在不同的属性等价类,因此,根据粒层空间中不同的等价类实现属性快速约简。
步骤3用属性约简后的样本集构建CART决策树,构造过程如下:
以约简后的数据子集Di作为模型的数据集,构建CART 决策树,如果样本个数小于阈值或没有特征,则返回决策子树,当前节点停止递归。
根据式(4)计算数据子集Di的基尼系数,如果基尼系数小于阈值,则返回决策子树,当前节点停止递归。
在分类问题中,数据集中类别数目为m,样本属于第i类的概率为pi,则该样本的基尼系数为[18]:
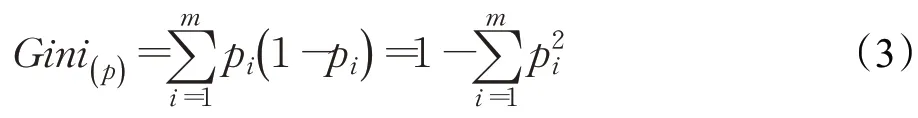
样本集S的基尼系数值为:

其中,|S|表示集合S的总样本数,|Di|表示集合S中属于第i类的样本数,基尼指数表示集合S的不确定性。
如果集合S中,属性A的值等于a的所有样本所形成的子集为S1,余下的为S2,则集合S在属性A的条件下得到的基尼指数为:
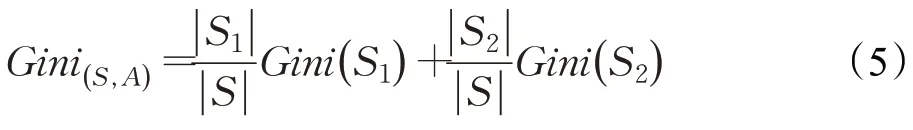
基尼指数Gini(S,A)表示集合S的不确定性,基尼指数越大,样本集的不确定性也越大[19]。
计算当前节点各特征值对数据子集Di的基尼系数。
选择基尼系数最小的特征A和对应的特征值a,根据最优特征和最优特征值,将数据子集划分为两部分,同时建立当前节点的左右节点,对左右的子节点递归生成决策树。
3 实验仿真与性能分析
3.1 算例示例
本文选取UCI 数据集中混凝土抗压强度的部分数据进行计算,共选取20个样本,原始数据表如表1所示,表中决策属性为压强,单位为MPa。
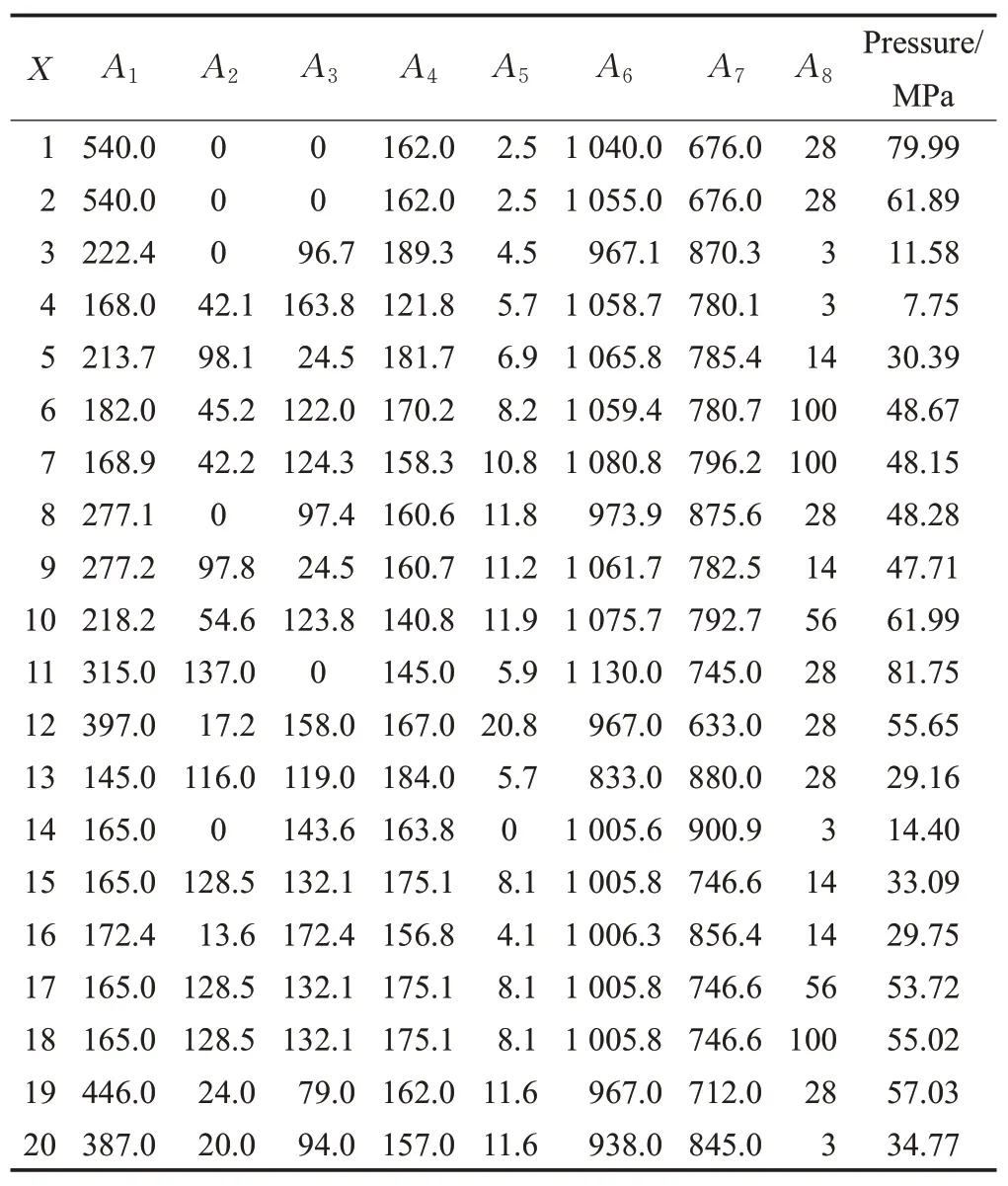
表1 样本原始数据表
(1)利用式(1)计算各属性间的模糊欧氏距离,建立所有属性的模糊相似矩阵。

(2)根据模糊相似矩阵分层递阶结构的聚类算法,得到一个有序样本的层次商空间{D(λ) |0 ≤λ≤1} ,不同粒层上的商空间对应不同的属性聚类结果,如表2所示。

表2 有序样本的层次商空间
(3)选取λ值,实现样本集属性约简,由于篇幅原因,仅列出选取部分阈值的约简结果。
当阈值λ=0.134 时,冗余属性是A2、A3,约简结果是A1、A4、A5、A6、A7、A8、A9;
当阈值λ=0.132 时,冗余属性是A2、A3、A7,约简结果是A1、A4、A5、A6、A8、A9;
当阈值λ=0.117 时,冗余属性是A1、A6、A2、A3、A7、A8,约简结果是A4、A5、A9。
3.2 仿真系统与数据集
基于Python 实现算法仿真。本文使用来源于KEEL 数据集的15 组具有代表性的数据集进行对比仿真实验,以CART决策树为分类工具,构建分类模型,验证算法的可行性,数据集信息如表3所示。
硬件环境:CPU,i5-6500;RAM,8 GB。
软件环境:操作系统,Windows 10专业版;解释器,Python 3.7。
3.3 性能分析
所有数据集均按照训练集80%,测试集20%随机划分。该约简算法主要以各粒层空间上属性的近似程度作为聚类基础,实现数据集属性约简。由于传统约简算法主要是通过计算样本间的等价关系约简属性,当数据集样本数量较大时,计算量明显增大,不利于属性快速约简。与传统约简算法相比,该算法约简速度明显提升,且不受数据集中样本数量影响,能够实现数据集快速约简,运算时间优势明显。因此在对比实验中,以不平衡数据集作为实验样本集,以SMOTE+TL、ADASYN、XGBOOST 三种算法作为模型框架分别在各约简数据子集上构建分类模型,并分析分类结果,验证约简算法的可行性与准确性。实验结果如图2 所示。图中纵坐标表示分类模型的G-mean值,横坐标的K表示约简轮数。

表3 数据集基本信息
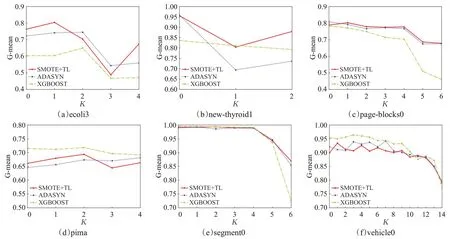
图2 属性约简后分类模型G-mean值
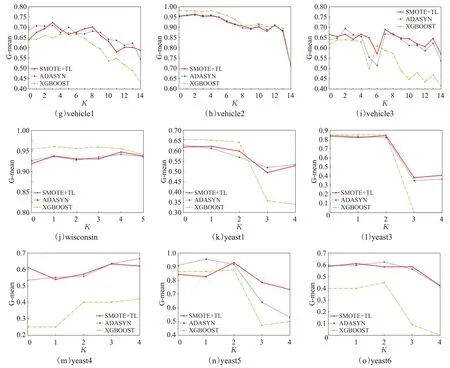
图2 (续)
分析图2 中各分类模型在约简粒层空间上的G-mean值可以看出,在SMOTE+TL、ADASYN、XGBOOST三种学习框架下,ecoli3、pima、wisconsin、yeast4、yeast5、yeast6六个数据集的约简过程中,主要剔除的是零值较多或对模型分类影响较小的属性,随着约简次数增多,分类模型精度提升明显,呈现出明显的上升趋势。在segment0、yeast1、yeast3三个数据集约简过程中,分类模型精度稳定,当约简至核属性时,分类模型精度下降明显,在此类数据集中,对决策属性影响较大的条件属性与影响较小的条件属性之间差异明显。通过计算属性之间相似程度有利于属性约简,且在约简数据子集与原数据集上分别构建分类模型,精度变化较小。因此,对于此类数据更应该约简后再构建分类模型,有利于提升模型精度及运算速度。当约简次数达到一定程度时,分类模型分类精度下降明显,因此,该点约简的剩余属性即为核属性。
在 new-thyroid1、page-blocks0、vehicle0、vehicle1、vehicle2、vehicle3六个数据集上,随着约简次数的增加,分类模型运算速度明显提高,精度有所下降,但精度下降并不明显,每次约简后精度下降2%左右,如果在精度较高的数据集上,可以牺牲一部分精度提升分类模型运算速度。这些数据有一个共同点,各属性之间的联系密切,条件属性权重相差较小,单纯使用模糊欧氏距离度量属性之间的相似程度,不能有效地区分影响力大小。因此,对于属性重要程度相近的数据集,可以通过样本计算属性间的近似程度,从而提升模型分类精度。
4 结束语
使用属性作为约简基础可以有效降低约简时间,降低样本数量变化对属性约简结果的影响。本文结合模糊欧氏距离及层次商空间理论,通过构建层次粒层空间,在各粒层空间上实现属性约简。仿真结果表明,基于模糊层次商空间的快速属性约简算法在保证数据完整的前提下,具有更快的约简速度,且不受样本集样本数量的影响,具有更高的稳定性。该算法在建模过程中,需要通过分析数据分类结果才能发现核属性,因此,如何自动获取最优核属性并建模是未来的研究方向。
