基于改进RPN的Faster-RCNN网络SAR图像车辆目标检测方法
2021-02-22史润佳蒋忠进
曹 磊 王 强 史润佳 蒋忠进
(东南大学毫米波国家重点实验室, 南京 210096)
近年来,深度学习迅猛发展,被应用到军事、地探、医疗等各个领域,并取得了很好的效果[1].其中,卷积神经网络(CNN)[2]以其在图像处理方面优异的检测与识别能力受到了普遍的重视.CNN不仅大量用于光学图像处理,也在SAR图像自动解译中表现出色[3-8],能够高效准确地进行目标检测与识别[9].
Girshick等[10]提出了基于区域卷积神经网络(R-CNN)的目标检测框架.自此,目标检测由基于视觉特征和统计特征为主的时期进入基于深度学习的时期,并获得了快速的发展.从R-CNN到SPP-NET[11]、Fast-RCNN[12],再到Faster-RCNN[13],网络的性能越来越好,尤其Faster-RCNN是真正意义上的端到端深度学习目标检测算法.Faster-RCNN最大的创新点在于设计了候选区域生成网络(RPN),由RPN来提取特征和完成候选区域的筛选,并对目标进行检测和定位,然后将筛选出的候选框送至分类识别层进行目标分类操作,明显提高了目标检测与识别的效率.
近年来,Faster-RCNN逐渐成为一种重要的SAR图像目标检测和识别方法[14-16].在某些情况下,无需知道车辆目标的具体类别,只需完成目标检测即可,本文便是采用Faster-RCNN进行SAR图像中的车辆目标检测.在传统Faster-RCNN中,RPN模块仅采用图像的顶层特征完成目标检测,由于顶层特征比较抽象,对SAR图像的细节信息丢失较为严重,不利于目标与地物的区分.因此,本文以VGG-16网络作为基础网络提取多个特征层,并对RPN进行改进,将细节信息比较丰富的较低层特征与信息抽象的顶层特征进行处理和融合,用于SAR图像中的车辆目标检测,并取得了良好效果.
1 改进的RPN与目标检测
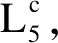

图1 传统RPN结构图
RPN网络主要学习2部分信息:①类别信息,根据候选区域特征信息计算候选区域类别信息,判断其中是否包含目标,若包含即为前景类,否则为背景类;②位置信息,即通过候选区域边框回归出目标位置边框.事实上,RPN并未直接对位置信息本身进行训练学习,而是学习候选区域边框相对于目标位置边框的偏移量.
传统RPN仅仅以最深特征层作为候选框提取层,这会导致经过多次下采样后,最深特征层里的图像细节信息损失较多,目标特征信息损失较大,带来一定的目标定位误差.
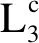

图2 改进RPN结构图
在测试阶段,每张测试集图片均会被检测出许多感兴趣区域(ROI),而每一个目标也会被不止一个ROI包围.本文采用非极大值抑制(NMS)方法去除冗余的ROI.首先将ROI按照目标辨识中所得到的分数进行降序排列,选中其中分数最高的ROI,并遍历其他ROI,若其他ROI与所选中ROI的IoU大于某阈值(本文实验中阈值设为0.8),则认定此ROI与所选中ROI是针对同一目标,将此ROI删除;然后为剩下的其他ROI重复上述去冗余操作,确保每一个目标只被一个ROI包围.
2 实验数据集的制作
由于包含军事目标的大场景SAR图像较为稀缺,因此本文在MSTAR数据集基础上,制作带车辆目标的大场景数据集,用于对卷积神经网络的训练与测试.MSTAR数据集是美国国防高级研究计划局(DARPA)提供的实测SAR图像数据集,其中包含了大量的车辆目标图像和少量的大场景图像.本文将这些大场景图像作为车辆目标检测的背景使用,由于大场景图像尺寸过大,为1 500×800像素,在制作训练数据时,将其分割成多个大小为300×300像素的小场景图像,如图3所示.

(a) 小场景1
(b) 小场景2
MSTAR数据集中共有10类车辆目标的SAR图像,图像大小为128×128像素.这些目标多是不同型号坦克、装甲车在0~360°方位角下的静止图像.本文挑选其中8类目标图像作预处理后,将其贴入小场景背景图像,生成训练数据集.图4展示了8类车辆目标2S1、BMP2、BRDM_2、BTR_60、BTR_70、T62、T72、ZSU_23_4的SAR图像样本.

(a) 2S1

(b) BMP2

(c) BRDM_2

(d) BTR_60

(e) BTR_70

(f) T62

(g) T72
本文的贴图操作是由编写的程序自动完成,不需要手工介入,因此可以快速大批量地生成实验数据集.程序会自动将目标贴入坐标等重要信息写入标签,因此本文并未采用Pascal VOC数据集中标签的格式,而是自拟了一种更简洁的标签格式,格式中包含目标的种类、位置和尺寸等信息.图5展示了贴上目标以后的小场景背景图像,可以看出,背景与目标的融合效果很好.

(a) 小场景1
(b) 小场景2
在制作数据集时,在每张小场景背景图中随机贴2类军事目标,如图5(a)和(b)所示,共生成 20 294个训练样本和894个测试样本.为了验证改进RPN的目标检测性能,测试样本中不乏环境地物非常复杂的场景.
3 代码实现与实验分析
本文的目标检测代码基于Python语言和TensorFlow框架编写.为了缩短训练时间,用于提取图片特征的基础网络是已在ImageNet数据集上经过预训练的VGG-16网络.本文直接利用VGG-16网络的模型参数对所提出的改进RPN网络进行初始化,然后再利用MSTAR实验数据集进行训练.在目标检测代码中,本文为每个像素点设置了9个锚点,采用的长宽比包括 1∶1, 1∶2, 2∶1.操作系统是64位Windows 10,计算机处理器Intel(R) Core (TM) i7-8700 CPU @ 3.20 GHz,内存容量16 GB,显卡是NVIDA GeForce RTX2070 (8 GB).
训练中8类目标场景图、共20 294个训练样本前800次迭代的损失函数值见图6.由图可知,改进RPN的收敛速度比传统RPN更快.
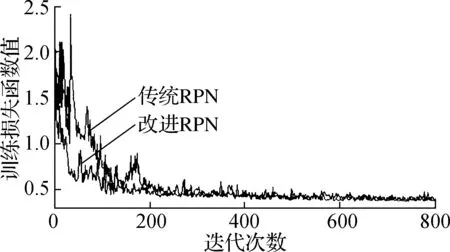
图6 训练中的前800次损失函数值
在评价指标方面,本文首先统计检出个数NTP、漏检个数NFN、虚警个数NFP等直观结果,然后采用查全率rR、查准率rP及查全率与查准率的调和平均数F1三个指标衡量检测效果,即
(1)
(2)
(3)
如表1所示,测试集中的目标总数共1 788个,传统RPN与改进RPN基本均不会漏检,查全率rR=100%.但是改进RPN在虚警方面有所改善,传统RPN的查准率rP=97.7%,而改进 RPN的rP达99.7%.传统RPN的调和平均数F1= 0.988,而改进RPN的F1=0.998.

表1 检测性能比较
图7展示了传统RPN方法检测结果图,这里的大场景图是第2节中检测后的小场景按照分割顺序和边界重新组合而成,其中2个虚警目标称为虚警1和虚警2.改进RPN方法检测结果如图8所示,同样的区域则未出现这2个虚警.因此,传统RPN对于复杂地域(如树林、石块区等地物分布复杂区域)的检测虚警率更高.

(a) 带有多个目标的复杂背景

(c) 虚警2放大图

(a) 带有多个目标的复杂背景

(b) 虚警1消失

(c) 虚警2消失
为测试改进RPN的泛化能力,本文采用8类目标中的5类目标场景图作为训练集,共13 453个样本,剩余3类目标的场景图作为测试集.该训练集均匀地包含2S1、BMP2、BRDM_2、BTR_60、BTR_70五类车辆目标,测试集则有1 206个,仅包含T62、T72、ZSU_23_4三类目标.传统RPN和改进RPN泛化能力测试的实验结果对比见表2.

表2 泛化性能比较
由表2分析可知,2种方法对于未训练过的车辆目标的检出效果差异不大,传统RPN与改进RPN查全率rR均超过99.9%,仅有4×10-6的差值.但改进RPN的虚警个数仅约为传统RPN的 1/2,两者的查准率rP分别为99.0%和98.0%.综上所述,改进RPN的泛化能力也相对更好.
4 结论
1) 与传统RPN相比,改进RPN在进行网络训练时具有更快的收敛速度,节省一定训练时间.
2) 2个版本的RPN在目标检测方面的性能相当,但改进RPN的虚警更少,将查准率由97.7%提高到99.7%.
3) 与传统RPN相比,改进RPN具有更好的泛化能力,针对训练范围以外的目标,能将查准率由98.0%提高到99.0%.
