基于深度学习的三维路面裂缝类病害检测方法
2021-02-22陈圣迪
郎 洪 温 添 陆 键 丁 朔 陈圣迪
(1 同济大学道路与交通工程教育部重点实验室,上海 201804)(2 上海海事大学交通运输学院,上海 201306)
路面裂缝是评价路面质量最重要的参数之一,是大部分病害的早期表现形式,直接影响公路使用寿命和行车安全.随着路面自动化检测技术的进步和发展,在大面积公路养护作业中,借助数字图像处理方式对路面裂缝快速识别和分类,将显著提高人工式或半自动式的病害检测效率.因此,路面裂缝自动检测已成为路面工程研究领域和道路养护管理部门的关注焦点[1].
我国道路检测普遍使用二维图像摄像测量技术,从采集的路面原始数据而言,检测系统大多能够获得路面高清灰度数据,但该技术对路面油污、阴影及光照不均等干扰因素较为敏感且难以给出精确的路面裂缝高程信息,一直制约着路面病害智能化管理水平.近年来,基于三维激光的扫描技术因其可测量出路表面的高程变化,较大程度上减少上述干扰因素的影响等优点越来越受到国内外学者的关注[2].其中,应用在路面检测中的三维数据获取方法有三维结构光扫描技术[3]、激光扫描仪技术[4]、双目视觉立体成像技术[5]、对焦测距[6]、散焦测距[7]、干涉测量法[8]等,但因三维激光扫描技术具有更强的环境适应性和更高的识别精度,激光扫描技术研究占主导地位[9].现有基于三维路面数据的裂缝检测方法通常是先找到高程较低的像素点,然后通过后处理过程去除噪声,如Jahanshahi等[10]设计的高程识别方法,Zhang等[11]提出的交互式裂缝检测方法,Sollazzo等[12]提出的混合裂纹检测进程,以及Zhang等[13]搭建的三维阴影模型.这些裂缝自动检测方法大多是基于简单的像素假设和传统的图像处理方法,因此对于复杂路况如路面纹理颗粒的大小、道桥接缝、标线边缘等干扰的影响,应用局限性较大[14].
深度学习,特别是卷积神经网络在图像辨识、视频跟踪、语音识别等领域取得了巨大成功.但经典的深度学习模型主要是针对较大尺寸、整体目标的分类模型或者识别模型,如AlexNet[15]、GoogLeNet[16]、Faster R-CNN[17]模型等.由于裂缝形态各异,且具有线性拓扑结构,如果直接将这些深度学习模型用于路面裂缝面元检测,极易造成漏检和误判.Li等[18]基于路面三维图像提出了一种卷积神经网络模型,该模型能将路面面元分类为无裂缝、横向裂缝、纵向裂缝、网状裂缝或龟裂.Zhang等[19]提出了一种卷积神经网络模型用来判断小尺寸二维路面图像中是否存在裂缝,并将其与传统的机器学习方法SVM、Boost进行对比,结果表明卷积神经网络更适用于裂缝检测.Cha等[20]提出了一种结合卷积神经网络模型与滑动窗口的裂缝检测方法,将路面二维图像划分为若干面元分别输入模型并将结果合并.实验结果表明,该模型受图像局部的光点、阴影、模糊等因素影响较小,但在复杂路况下算法的鲁棒性有待验证.
本文考虑路面复杂场景,对采集的不同区域路面三维图像建立数据集,提出一种基于深度学习的路面裂缝类病害检测方法,对自动识别到的裂缝面元和裂缝轮廓提取模型的准确度进行试验,并通过与人工数据对比评估了测试方法的有效性.
1 路面数据集
使用深度学习中的卷积神经网络进行路面裂缝检测,需准备大量带类别标签的路面裂缝数据.为确保数据集中的裂缝具有多样性,本文所使用的路面三维数据采集自山西G20高速、上海市境内和浙江省嘉兴市境内的多条国道路段,共筛选出1×104张路面三维裂缝图像,并制作了人工标记数据.
图像均在正午强光下获取,试验环境按照公路技术状况评定标准[21]设立,每张图像的分辨率为2048×2048像素,横向覆盖路面2 m,纵向采样间隔1 mm,检测时速在30~100 km/h之间.所建立的路面数据集包含了裂缝和路面表面纹理的多种变化,任何2张图像之间没有重叠,且来自同一路段的图像不超过100张.另外,所选用图像包含裂缝的多种类型,如龟裂、块状裂缝、纵向裂缝和横向裂缝等,还包含一些非裂缝类型如桥接缝和灌缝等.
为确保裂缝面元在像素级上是准确的,对人工标记数据进行了3轮检查:①几名训练有素的操作员在提供的全分辨率三维路面图像上手动标记裂缝面元;②其他几名训练有素的操作人员检查和复核裂缝面元,以减少数据标记的主观性;③专家对裂缝面元进一步检验,保证裂缝宽度和长度的标记误差在3 mm以内,并仔细检查裂缝的连续性,如果裂缝中断部分不超过10 mm, 则将其也标记为裂缝面元,否则视其为背景面元.在连续一年多数据制作的基础上,完成了裂缝面元和背景面元的制备全过程.图1展示了几个具有代表性的三维路面图像和相对应的人工标记数据.
从数据集中选取5000张路面三维图像,用于模型训练和测试.这些沥青表面图像代表不同的纹理和不同的混合料类,以高速公路和国省干道为主,包括热拌沥青(HMA)和温拌沥青(WMA).从5000张图像中随机选取200张作为测试数据,500张作为验证数据,其余4300张作为训练数据.

(a) 路面三维图像

(b) 人工标记的裂缝面元和背景面元
2 基于CNN深度学习的PCCNet分类模型及构建
2.1 三维数据预处理
预处理包括图像池化和高程校准2个步骤.为了减少计算开销,本文采用最小池化技术[14]将原始路面三维图像尺寸2048×2048像素缩小到512×512像素,池化后的三维图像仍能清晰地看到细微的裂缝,其中单个像素的高程值对应于原始三维图像的4×4像素子块.利用本文方法对5000张原始图像的裂缝进行了检测,并对其池化处理后的图像进行识别,裂缝面元识别的准确率大于92%,说明池化过程对检测精度没有明显影响.
在测量过程中,路面复杂程度、传感器性能、测试系统的机械震动以及人为因素都可能导致某些激光点不能反射回摄像机,从而造成横断面数据缺失[22].此外,三维路面表面可能不平整,从而导致不同横断面的高程整体水平呈现出较大差异.由于在卷积层使用共享权重来计算局部值的加权和,因此当三维表面不均匀时,不同位置的相似裂缝可能产生完全不同的响应,即网络在不平整的路面上学习局部特征将更加困难[14].因此,需要对三维图像进行高程校准.预处理过程如下:令采集的一组横断面高程向量X={X1,X2,…,Xn},其在三维图像上对应的像素向量Y={Y1,Y2,…,Yn},Yi=0 (i=1,2,…,n)属于激光异常点,Yi≠0 (i=1,2,…,n)不属于激光异常点.对于筛选出的异常值采用其左邻正常值或右邻正常值的插值进行修正,即
(1)
式中,n为横断面高程点个数;Xi为筛选出的异常值;Xi-1为异常值的左邻正常值;Xi+1为异常值的右邻正常值.
对激光点修正后的三维图像进行高程校准,步骤如下:
①计算三维图像(M×N)每行高程值均值,得到图像高程分布特征值,即大小为M×1的向量H,并通过计算行高程值H的均值,得到高程分布的整体水平Havg.
②计算高程分布特征值偏离整体水平的程度,得到高程校正系数矩阵W,即
(2)
③将图像中第x行第y列的像素点高程值Eorigin(x,y)校正为Enew(x,y),即
(3)
式中,W(x)为第x个高程校正系数.
2.2 PCCNet模型的建立
本文提出一种新的卷积神经网络来进行面元图像分类.该网络的前几层采用VGG(visual geometry group)网络结构,卷积核数量依次翻倍,所有卷积层都使用小尺寸的3×3卷积核.与VGG等传统分类模型不同的是,PCCNet将VGG中的全连接层改为卷积层,每个面元的分类结果与全局特征无关,使得网络成为一个全卷积结构,在捕获面元局部特征的同时,极大地减少了模型的参数量,提高了模型运行效率.现有的裂缝分类模型均利用滑动窗口将图像分割为若干子块,再逐一将子块输入模型得到分类结果,而PCCNet直接以整张图像作为输入,输出8×8的面元分类结果,分类效率更高,并且能够充分利用相邻面元的特征信息.
如图2所示,本文提出的PCCNet模型网络是一种7层全卷积网络,由7层卷积层(C1~C7)和6层池化层(P1~P6)组成,每个卷积层后面都有一个激活函数(ReLU).传统的深度学习模型在输出神经元之前会进行全连接,即将池化后的特征与正交编码后的目标类别矩阵建立映射关系,但针对裂缝这类目标其具有局部、线性拓扑结构,使用全连接将引入更多可能的特征映射组,增加了目标识别的复杂度,因此本文采用最后一层卷积层来代替全连接操作[14].PCCNet模型的输入是经过池化和高程校准的三维图像,尺寸为512×512像素,卷积层C1~C7均使用3×3卷积核.卷积层C1有32个卷积核,卷积层C2、C3、C4的卷积核数逐层翻倍,卷积层C5、C6保持256个卷积核,卷积层C7的卷积核数降为2.池化层P1~P6皆为2×2的最大池化层.采用Softmax激活函数计算路面裂缝面元和背景面元对应的识别概率值,argmax函数作为求参数集合的函数输出面元分类结果.
2.3 模型加速及优化
本研究的计算平台为一台移动计算工作站,利用NVIDIA GeForce GTX 1070 GPU对该模型进行加速训练.模型基于Python语言实现,采用PyTorch的深度学习框架,利用CUDA平台进行并行计算,并使用基于训练数据迭代更新神经网络权重的Adam优化方法.
所使用的验证集和测试集均不参与模型训练,从而可以在训练完成后更好地观察模型泛化能力.
PCCNet模型采用多分类方法,在样本标记阶段,将裂缝面元和背景面元分别标为1和0,并利用交叉熵损失函数,对预测值和真值之间的差异进行测量[14].
(4)
式中,Uloss为损失值;yc,ac分别为第c个面元的真值和预测值;q为一张图像上的面元总数,取64.
2.4 训练结果
准确率和召回率是评价裂缝检测方法的2个重要指标[23].准确率P是在预测裂缝面元时预测正确的比例,而召回率R为预测正确的裂缝面元占总裂缝面元的比例.既有图像检测研究常用F值评价模型优劣,F值越大模型越优.其计算公式为
(5)
(6)
(7)
式中,TP为正确检测出的有裂缝面元数目;FP为背景面元被判别为有裂缝面元的数目;FN为裂缝面元被误判为背景面元的数目.
试验中模型训练的部分超参数设置为:训练集遍历期数为30,批量大小为16,学习率设置为0.001.每迭代50次,对完整的验证集进行一次测试,计算损失函数、准确率、召回率和F值.训练结果如图3所示.由图可知,模型训练共进行了7500次迭代,损失函数随着迭代次数的增加呈下降趋势,F值呈上升趋势.经过3850次迭代之后,验证集损失不再明显下降,且F值达到最大,为92.9%,即图3(b)中圆形标记所在位置.但随着迭代次数的增加,训练集损失仍在下降,因此当迭代大于3850次时,模型出现过拟合现象,本文保留迭代3850次时的模型训练结果.

(a) 损失函数

(b) 评价指标
为进行对比研究,结合PCCNet模型训练了3个备选网络PCCNet-A、PCCNet-B、PCCNet-C,这些网络的架构与PCCNet模型相同,但在每个卷积层使用不同大小和数量的卷积核.表1给出了用于3个备选网络的卷积核参数.备选网络的训练方法与PCCNet模型相同,均经过7500次迭代.图4显示出模型对裂缝面元识别的F值随迭代次数的变化情况.结果表明,迭代次数大于2500次后,PCCNet-A相比PCCNet在F值曲线上呈现下降趋势.
此外,与PCCNet和PCCNet-A相比,PCCNet-B和PCCNet-C检测性能显著降低,意味着增大卷积核尺寸会导致检测性能下降,F值曲线呈现一定程度的振荡,但经过3 500次迭代后也趋于稳定.综上所述,本文PCCNet模型由于使用的卷积核尺寸小、数量多,能更好地感知裂缝局部区域特征,在验证集上具有最高的F值.

图4 4种模型对裂缝面元识别的F值

表1 备选网络的卷积核参数设置
3 基于高程检查的裂缝轮廓提取方法
PCCNet深度学习模型实现了针对64×64像素较小尺寸的路面裂缝面元图像及路面背景面元图像的分类识别,排除了具有高程特征但为非裂缝面元的图像,如修补边缘、标线等.为了进一步提取裂缝面元内裂缝的完整轮廓,还需考虑三维图像中裂缝的像素级邻域特征.
本文在观察大量实际工程路面三维图像基础上,发现路面裂缝处的横断面高程曲线具有较大的阶跃,裂缝表现出较为明显的轮廓边缘,并且其高程与相邻非裂缝区域的高程差别较大.此外,裂缝种子具有较强的方向性,在特定的拓扑结构上呈现出较为连续的形态.因此,为了最终检测出路面裂缝的完整轮廓,本文方法还需要在PCCNet模型基础上,结合裂缝高程检查提取裂缝边缘轮廓,具体过程如下:
①对预处理修正后的像素值进行高程验证,在中心像素(i,j)两侧r个像素的邻域内,裂缝种子点应满足
(8)
E(i,j)≤KsEavg
(9)
式中,Eavg为中心像素两侧r个像素的邻域内所有高程值的平均值;(x,y)为像素坐标;E(i,j)为邻域内中心像素的高程值;Ks为动态阈值参数.
②为了验证裂缝种子的方向性,在中心像素的0°、45°、90°和135°共4个方向计算两侧r个像素的高程均值,若有显著跳跃,则种子方向性较强.
(10)
Mmax=max(Qv)
(11)
Mmin=min(Qv)
(12)
Mmax-Mmin≥T
(13)
式中,v=1,2,3,4,分别表示0°、45°、90°和135°四个方向;E(d)为第d个像素的高程值;fv为方向v的2r+1个像素中的最低深度值;Mmax,Mmin分别为最大、最小高程变化值;T为经验阈值参数,本文设置为4.
③通过PCCNet模型确定疑似裂缝区域和疑似裂缝相邻区域,利用步骤①和②,分别计算上述2个区域中的裂缝种子点数,随着Ks的增大,裂缝占比L也随之减小,因此本文利用二分方法[23]自动搜索Ks的最优解.
(14)
L≤Lk
(15)
式中,Ninside为疑似裂缝区域中裂缝点总数;Naround为疑似裂缝相邻区域中裂缝点总数;Lk为经验阈值参数,本文设置为0.9.
4 试验结果与分析
4.1 裂缝种子检测性能
为了更好地评估本文方法,将已训练好的PCCNet模型结合裂缝高程检查方法应用于测试集的三维图像.本文选取4个具有代表性的样本,如图5(a)所示,1#样本中三维图像左侧有竖直标线,2#样本中路面纹理颗粒较大,3#样本中存在高程变化区域但为非裂缝类病害,4#样本中包含桥接缝.图5(b)为PCCNet模型的识别结果,蓝色方框为自动识别的裂缝面元,黄色方框为裂缝面元相邻区域,其余区域为背景面元.图5(c)为裂缝高程检查方法检测结果,蓝色为已识别的裂缝轮廓,黄色为疑似的裂缝轮廓,红色为背景误差.将背景误差去除,融合PCCNet模型和裂缝高程检查识别结果,获得最终裂缝图像,如图5(d)所示.
从试验过程可发现,PCCNet模型对裂缝面元定位准确,有效地剔除了可能具有干扰因素的背景面元,单独依靠裂缝的高程检查方法对路面标线

(a) 路面三维图像

(b) PCCNet模型检测结果

(c) 裂缝高程检查方法检测结果

(d) 融合结果
边缘、路面纹理颗粒、高程变化区域和桥接缝的干扰因素较为敏感,会将这些非裂缝类病害误识别为裂缝.因此将PCCNet模型与裂缝高程检查方法结合,可有效地避免误判,提高方法的准确性.
4.2 方法验证
为了评估裂缝识别的准确性,分别应用本文方法、种子识别方法[23]和改进的Canny方法[24]对测试集所有200张路面三维图像进行裂缝识别,以裂缝单元格为处理单元,通过与人工描点结果进行对比.表2列出了这3种方法的准确率、召回率和F值,图6展示了3种方法在测试集上的对比结果.从图6(a)可看出,本文方法准确率最高(均值为87.8%),种子识别方法和改进Canny方法准确率稍低(均值分别为66.5%和63.4%).图6(b)表明

表2 3种方法评价指标统计结果

(a) 准确率

(b) 召回率

(c) F值
本文方法召回率最高(均值为90.1%),种子识别方法召回率稍低(均值为79.4%),改进Canny方法召回率最低(均值为44.7%).从图6(c)可看出,本文方法的F值均值为88.9%,而种子识别方法和改进Canny方法的F值均值分别为72.4%和52.4%.可见,本文方法优于种子识别方法和改进Canny方法.
图7给出了改进Canny方法、种子识别方法和本文方法在4个代表性样本(5#~8#样本)的测试图像上的裂缝识别结果.其中,5#样本包含纵向裂缝,缝隙较宽,三维图像整体比较平滑;6#样本裂缝类型为龟裂,图像左侧有局部噪声;7#样本裂缝特征表现为纵向和横向交叉且裂纹较细;8#样本中包含块状裂缝.研究发现,改进Canny方法识别出的裂缝种子存在大量的漏检,方法对裂纹宽度较为敏感,如图7(c)中7#和8#样本,较细的裂缝种子无法捕获,这种漏检解释了改进Canny方法召回率相对较低的原因.种子识别方法提高了召回率,但对局部噪声敏感,如图7(d) 中6#样本左侧区域出现的误判.与改进Canny方法和种子识别方法相比,本文方法在抑制噪声和检测细小裂纹方面具有更强的鲁棒性.
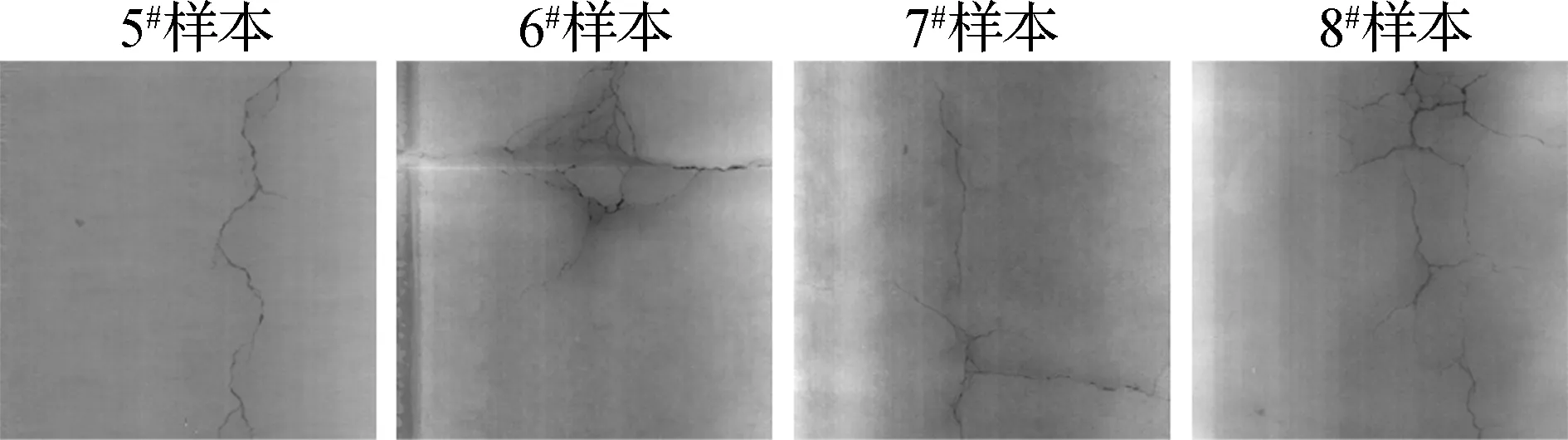
(a) 路面三维图像

(b) 人工标记结果

(c) 改进Canny方法检测结果

(d) 种子识别方法检测结果

(e) 本文方法检测结果
5 结论
1) 针对目前传统的图像处理和经典深度学习模型不能很好地检测路面裂缝的问题,本文采用卷积神经网络技术,提出了一种路面裂缝面元分类模型即PCCNet模型,并结合裂缝高程检查方法用于裂缝的自动识别.
2) 通过训练集4 300张高精度三维图像的训练,模型在3850次迭代之后出现过拟合,PCCNet模型在验证集上的总体F值最大,为92.9%,表明建立的网络能较好地区分裂缝类病害和非裂缝类病害.
3)将本文方法应用在测试集的200张三维图像上,准确率和召回率分别为87.8%和90.1%.与改进Canny方法和种子识别方法对比,本文方法在抑制噪声和检测细小裂纹方面具有更强的鲁棒性.在未来的研究中,该方法将用来解决更复杂的问题,如水泥路面破碎板和板角断裂等病害的识别.
