基于SGA+DWT的BiLSTM滚动预测优化模型
2021-02-14桑学锋常家轩
刘 鑫,桑学锋,常家轩,郑 阳
(1.华北水利水电大学水利学院,河南 郑州 450046;2.中国水利水电科学研究院水资源管理研究室,北京 100038)
0 引 言
水文预测在水库蓄水、城市供水调度策略及灌溉等工作中具有非凡的意义,是水利机构或其工作人员进行决策时的关键参考,因此能够精准预测显得十分重要。为了提高水文预测的精度和可靠性,很多学者从不同角度通过学科交叉,提出了很多先进的方法,如灰色[1-2]、人工神经网络[3]、回归[4-5]、时间序列[6-7]、深度学习[8-9]等模型。通过数据驱动的方式可以不受物理环境的影响,建立数据间潜在的特征关系;通过自学习自调参实现对过去规律延伸同时,还能通过模型自组织自适应特性,在预测时进行修正,从而使模型能够较好地预测未来。
但是在长期预测中,时间序列存在较大波动,加上噪声的影响,使得一些数据驱动模型在长期预测中的性能恶化,预测结果的误差较大;甚至有概率出现预测值全部在中位数附近波动,从而无法为决策者提供有价值的信息。通过大量研究及实验发现,模型在长期预测中泛化能力变差有以下3个重要因素:一,模型的初始化结果对模型整个训练过程及模型泛化能力的影响较大,可以说一个好的初始化可以大大减少模型的调参时间,甚至不需要很多先进算法的支撑就可以较好拟合。因此,有学者致力于模型的初始化过程,使用启发式算法进行预调参,优化初始化过程。但在模型训练过程中,寻优方向具有较大随机性从而并不能解决根本问题。二,模型在寻优的过程中,往往很难获得全局最优解,多数情况下输出的结果都是局部最优。通过增加神经元及隐藏层数量,或者以梯度、动量、多种激活函数等方法期望帮助模型跳出局部最优解,但是这样会大大增加模型的训练时间,同时也会使模型出现过拟合现象[10-11],仍然会导致模型泛化能力变差。因此,有学者尝试从不同角度融合多种方法,希望可以获得全局最优解的同时又能解决过拟合现象,遗憾的是结果并不理想。三,在长期预测时模型很容易受到噪声的干扰,使得输出的序列出现明显波动且波峰与波谷都被明显的拉长,虽然无限增加训练次数可以改善上述现象,但是也会导致严重的过拟合现象,使得模型测试时性能恶化。
综上,本研究提出基于自发式遗传算法(spontaneous genetic algorithm,SGA)+离散小波变换(discrete wavelet transform,DWT)的双向长短时记忆(bidirectional long short term memory,BiLSTM)滚动(rolling)预测模型(SDBiLSTMR)解决上述问题。通过GA[12-13]进行预调参同时设置监视器实现SGA,利用DWT[14]过滤噪声。同时,为了防止模型的训练时间大幅度增加,本研究将数据从内存调入显存,将模型训练时的核心从中央处理单元(central processing unit,CPU)迁移到图形处理单元(graphics processing unit,GPU)进行数据的并行计算,获得优化模型的同时减少建模时间。
1 方 法
长短时记忆(long short term memory,LSTM)模型(见图1及式(1)~式(6))具有一定的记忆能力,隐藏层除了输出计算结果外,还额外输出一个记忆,该记忆通过一个衰减因子不断地遗忘较远的记忆,更依赖于过去最近的记忆。即

图1 LSTM结构
ft-1=σ(Wfxx(t)+Wfhh(t-1)+If)
(1)
it=σ(Wixx(t)+Wihh(t-1)+Ii)
(2)
mt=φ(Wmxx(t)+Wmhh(t-1)+Ig)
(3)
ot=σ(Woxx(t)+Wohh(t-1)+Io)
(4)
st=st-1ft-1+itMt,ht=φ(st)ot
(5)
φ(x)=(1-e-2x)/(1+e-2x),σ(x)=1/(1+e-2x)
(6)
式中,W和I分别为权重矩阵和截距矩阵;ft-1为衰减因子;it为输入单元;mt为记忆单元;ot为输出单元;st为输出的记忆状态;ht为隐藏层输出。
BiLSTM结构见图2。由图2可以看出,BiLSTM融合了前向LSTM与反向LSTM,最终的输出也是由2个方向的输出拼接而成的。这使得模型的自学习能力得到增强,但是模型需要调节的参数增加了一倍,输出的维度也增加了一倍;所以,最后输出需要进行整流将维度还原。建模流程见图3。

图2 BiLSTM结构

图3 建模流程
1.1 SGA+AME+LS
遗传算法(GA)不需要确定的规则,通过选择、交叉、变异来产生比当前更好的下一代种群,让适应能力更强的个体保留下来从而完成进化,自动指导优化,自适应地完成对复杂空间的启发式搜索,找到全局最优解的概率较大。本研究除了使用GA进行预调参外还设置监视器,当模型连续两次的训练误差小于一定阈值时再次启动遗传算法实现SGA,进行启发式搜索寻找全局最优解。
自适应矩估计(adaptive moment estimation,AME)是一种自适应优化算法,能够随着训练迭代地更新,公式如下
fmt=m1×fmt-1+(1-m1)×gt
(7)
gt=ΔJ(Wt)
(8)
(9)
(10)
(11)
(12)
式中,fm、sm分别为一阶矩估计和二阶矩估计;m为动量的大小;g为梯度;fv、sv分别为对一阶及二阶矩估计的校正;P为模型的参数;η为学习率;ε取10-8;t为迭代次数。
最小二乘(least square,LS)[15]是数据驱动模型最常用且效果较好的求解方法,本文不再赘述。其公式为

(13)
式中,Y为实测值矩阵;E为估计值矩阵。本研究数据载体全部为矩阵,这样迭代一次等于逐元素计算迭代n次。
1.2 离散小波变换
噪声对模型的构建存在较大的影响,而小波分析是过滤噪声的有效手段。小波分析分为连续小波变换(continuous wavelet transform,CWT)和离散小波变换(DWT)。对于逐日数据而言,严格意义上是离散数据,虽然可以对数据进行插值连续化,但随着时间尺度的减小意味着无穷次的计算,因此本研究采用DWT。
时间序列一般存在低频分量与高频分量,根据以往大量实验发现,噪声多数是高频分量,实测数据多数为低频分量,而DB小波具有较好的正交性,对序列分解、修正、重构后,对高频分量的过滤效果较好。
1.3 滚动预测
目前,数据驱动模型中往往是单步预测,这种预测方式在短期预测中普遍适用,但是在长期预测中存在一定的缺陷。因为时间序列模型对较久远的数据会进行衰减,因此,模型更倾向于将最近的规律进行延伸。而一次延长较长的序列,离训练集越远的数据无法有效延伸。
本研究将预测滚动进行以解决上述问题。让模型每次只预测一个子序列,然后将该子序列融入训练集使模型再进行学习,然后再预测一个子序列,如此滚动预测直到预测完毕。
1.4 评价标准
本研究从不同角度选择了4个评价标准以综合评价模型的性能,他们分别是均方误差(mean squared error,MSE)、纳什系数(Nash-Sutcliffe efficiency coefficient,NSE)、平均相对误差(mean relative error,MRE)、Pearson相关系数(r),公式如下。
MSE=∑(yi-pi)2/n,i=1, 2, …,n
(14)


(15)
(16)
(17)

2 应 用
本研究利用深圳2015年1月~2019年12月共1 826 d的无空缺逐日供水数据按8∶2划分训练集与测试集,并与使用SGA+DWT优化的LSTM(SDLSTM)及BiLSTM(SDBiLSTM)的预测结果进行对比;同时,按7∶3划分训练集与测试集进行交叉验证。本研究数据来源于深圳市水务集团。训练集结果见表1。由表1可知,训练完毕后3个模型在训练集上都较好拟合。

表1 训练集结果
2.1 预测结果对比分析
8∶2划分训练集与测试集的预测结果和7∶3划分训练集与测试集的预测结果分别见表2、3。
由表2可知,3个模型的MSE、NSE、MRE及r从最优到最差排序都是:SDBiLSTMR、SDBiLSTM、SDLSTM,其中SDBiLSTMR的泛化能力最强。SDBiLSTMR的MSE最小NSE最大说明模型的误差最小拟合度最高,MRE最小说明模型的稳定性最好,系数r最大说明预测值与实测值的相关性最强。SDBiLSTM比SDLSTM的MSE减小了83.91%,NSE提高了39.06%,MRE减小了96%,r提高了11.76%,SDBiLSTM的4个指标都比SDLSTM的更优,可知双向网络的性能要更优;SDBiLSTMR比SDBiLSTM的MSE减小了13.04%,NSE提高了3.37%,MRE减小了25%,r提高了1.05%,SDBiLSTMR的4个指标都优于SDBiLSTM,说明滚动预测效果比单步预测精度更高。

表2 8∶2预测结果对比
由表3可以看出,交叉验证集上,模型性能排序从最优到最差依然是:SDBiLSTMR、SDBiLSTM、SDLSTM。SDLSTM在延长预测长度后,性能出现恶化,MSE增加了30.77%,NSE降低了43.75%,MRE增加了10%,r降低了11.76%,模型的误差、拟合度、稳定性及相关性都变差了。而从双向网络的4个指标可以看出,模型仍然表现出了较好的性能,说明双向网络在延长预测长度后依旧可以有效进行预测。其中仍然是SDBiLSTMR的泛化能力最强。与SDBiLSTM相比,SDBiLSTMR模型的MSE减小了16%,NSE提高了4.76%,MRE减小了25%,r提高了2.15%,在交叉验证中滚动预测仍然比单步预测的效果更好。

表3 7∶3预测结果对比
2种划分方式的拟合结果及误差条见图4。由图4a、4b可以看出,模型的误差主要体现到后半段,前半段3个模型的表现都较好。但当预测长度增加到一定程度时,SDLSTM模型的曲线明显偏离实测值,误差及拟合程度都较差;而SDBiLSTM与SDBiLSTMR曲线与实测值偏离较小,模型依旧保持较好的性能。由此也可以证明,BiLSTM的泛化能力强于LSTM。其中,SDBiLSTM虽然误差也较小,但是后半段的曲线纵向延伸度不够;而SDBiLSTMR模型在后半段曲线纵向延伸度较好,与实测值的拟合度最佳,模型最接近无偏估计。为了更加直观地看出误差,图4c、4d展示了测试集后150个数据的误差条。由图4c、4d可以看出,在2个测试集上SDLSTM预测曲线差别很大且误差条很长,代表模型的误差非常大;2个双向网络的预测曲线变化很小且误差条较短,说明模型的误差较小,其中SDBiLSTMR的误差最小。
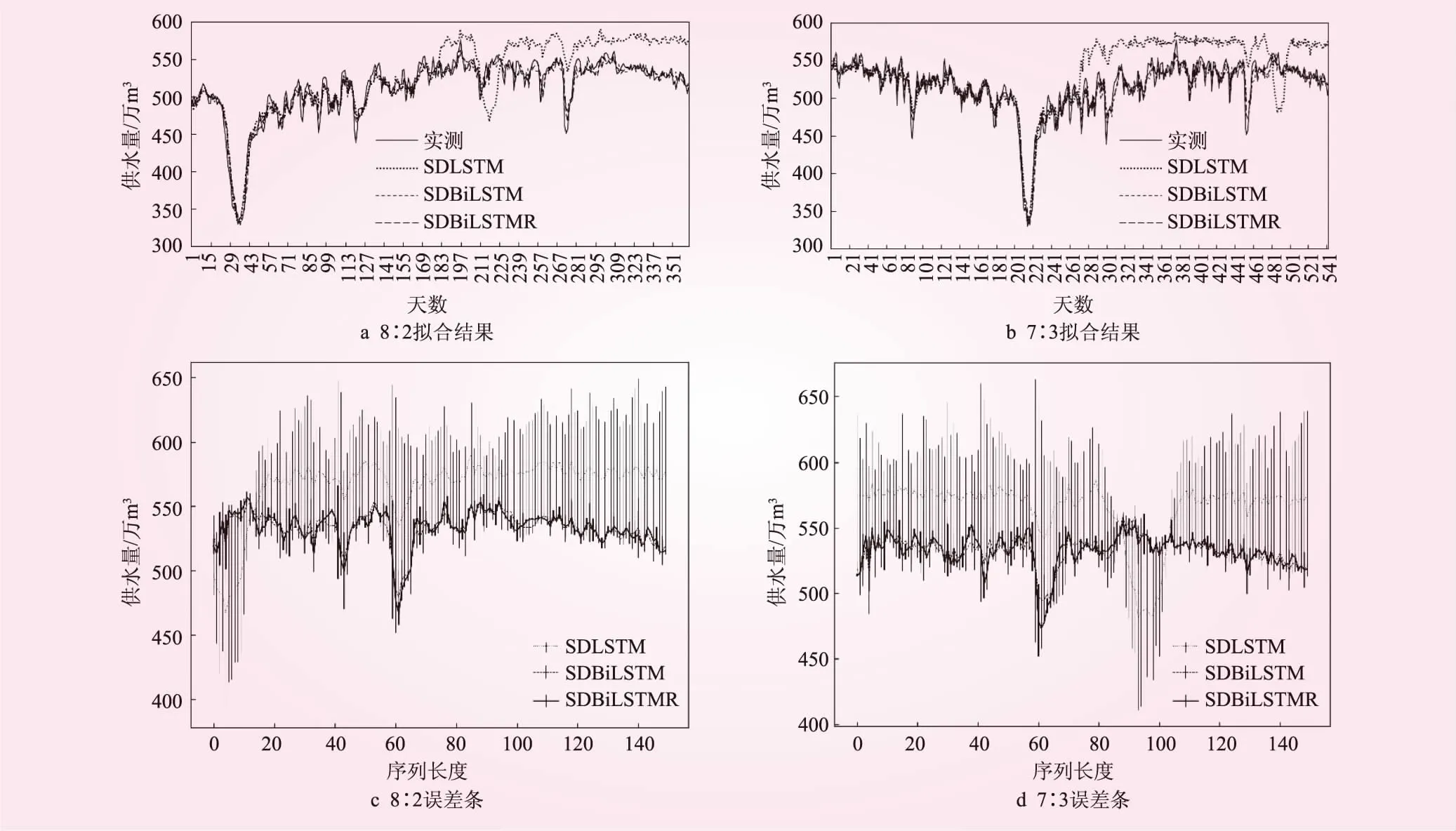
图4 拟合结果及误差条
MSE只是模型预测值与估计值的最终对比,只能说明最终结果的好坏,而不能体现模型是否足够可靠。因此,本研究进一步使用式(18)计算每个预测数据的相对误差(RE),通过全部预测数据的RE来验证模型的可靠性。即
RE=|(yi-pi)/yi|
(18)
RE箱图见图5。由图5可以直观地看出,2个测试集箱图的规律是一致的,RE的上限从大到小排序都是SDLSTM、SDBiLSTM、SDBiLSTMR,RE密度从低到高都是SDLSTM、SDBiLSTM、SDBiLSTMR。8∶2的测试集上,SDBiLSTMR模型箱图的上下限分别是4.71%与1.46%,上下限的距离最短,中位数和平均值最小,分别是2.9%与3.47%;7∶3的测试集上,SDBiLSTMR模型箱图的上下限分别是5.03%与1.2%,上下限的距离最短,中位数和平均值最小,分别是2.64%与3.45%,由箱图可知,SDBiLSTMR模型最可靠。
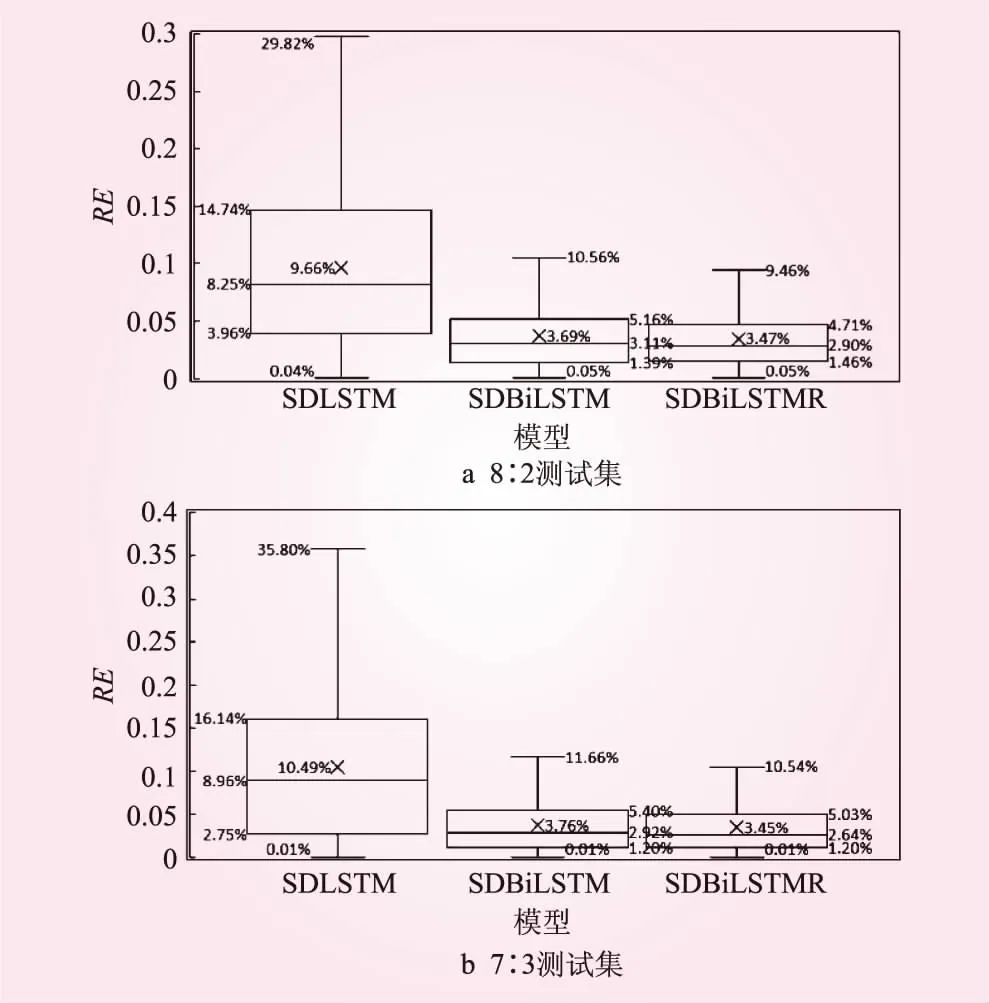
图5 RE箱图
当模型比较复杂参数较多时,使用矩阵作为数据的载体不仅可以减少迭代次数,还能在GPU上并行计算,较大程度减少建模时间(见表4)。本研究使用第八代intel酷睿i7处理器和GeForce 930MX实现CPU和GPU上的5 000次训练,本研究将SDBiLSTMR分3步预测,因此训练次数为15 000次。

表4 建模时间 s
由表4可以看出,3个模型建模时间较短,且在GPU上的训练时间明显少于CPU上的训练时间。SDLSTM、SDBiLSTM及SDBiLSTMR模型在GPU上的训练时间比CPU减少了21.96%、26.74%、27.5%。对于SDBiLSTM而言,网络的参数是SDLSTM的2倍,但是模型在GPU上的训练时间只增加了64 s,而在CPU上训练却增加了104 s。对于SDBiLSTMR而言,相当于构建了3次SDBiLSTM,在GPU上训练时间只增加了193 s,而在CPU上增加了270 s,由此充分证明了以矩阵作为数据载体的迭代效率非常高,此外网络越复杂参数越多,训练次数越多,GPU越能表现出强大的性能。
2.2 启示
通过实验发现,遗传算法虽然可以自发启动帮助模型跳出局部最优解,但是算法有一定的局限性,即存在误差下限,本研究提取种群大小为50迭代200次的结果(见图6)。
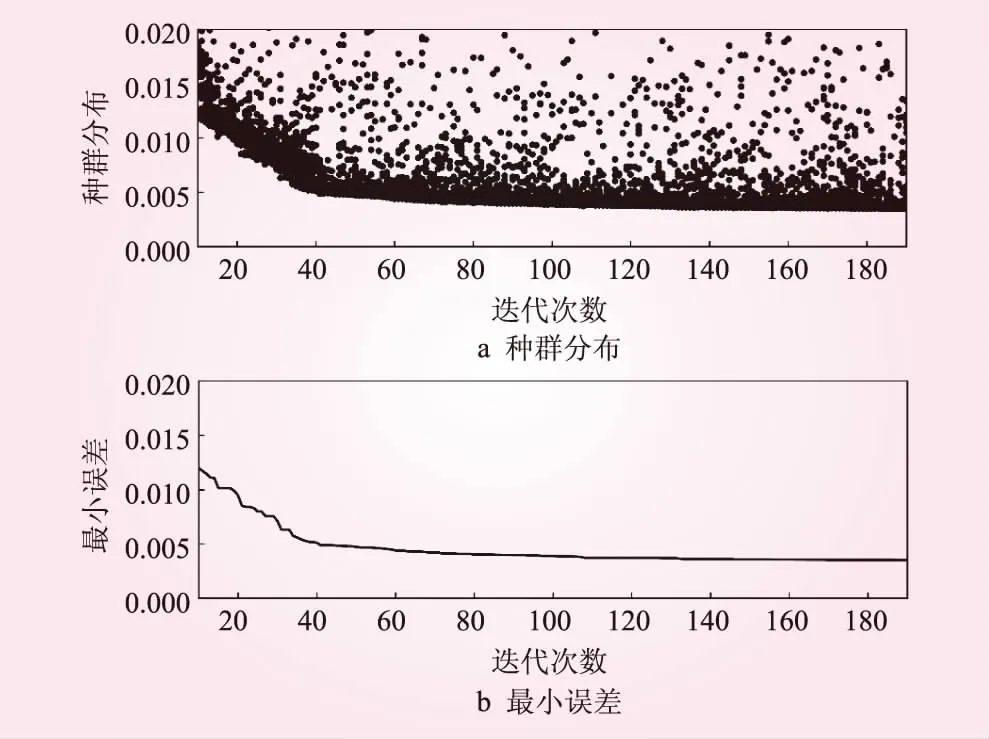
图6 种群分布及误差变化
由图6的种群分布可以直观地看出,遗传算法初期展示了很强大的性能,第20代时种群大多数个体都分布在误差0.01~0.02的位置,但是当迭代到60代的时候误差的减小速度趋近于0,当迭代到100代时,误差停留在0.005不能再减小。通过连续启动遗传算法,结合模型自身的优化器+激活函数才可以使模型在训练集的误差继续减小。这是因为种群的进化过程存在一些缺陷(见图7)。
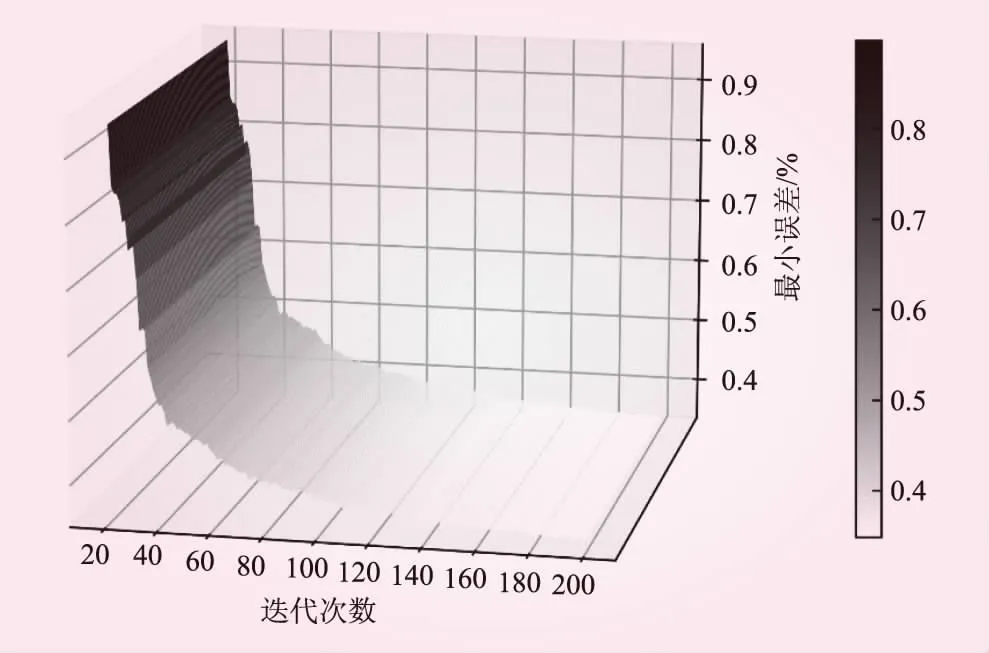
图7 种群进化过程
遗传算法通过选择、交叉、变异来产生更优的新一代种群。但从图7可以看出,种群在进化时经常会变差或者连续较多代没有产生更优化的后代,直到达到一定的迭代次数后才产生更优化的后代。主要原因是随机地迭代搜索对全局寻优的影响较大。算法初期设置较大的交叉变异概率可以加速全局寻优,后期减小概率能得到适应度值高的个体。因此,很多学者会设置自适应交叉变异概率,即设置一个衰减因子,算法刚开始时设置一个较大的概率值,随着迭代的进行不断对概率值进行衰减。但是这种方法的稳定性较差,因为种群中的个体在进化的同时,会产生较差的一代(退化现象),而退化的个体使得衰减的交叉变异概率无法保证算法的收敛,从而使得计算结果非常不稳定。综上,未来的研究方向应该是着重解决种群个体的退化现象。
3 结 论
在制订城市未来的供需水调度计划时,需要掌握尽可能准确的需水量才能合理地分配有限的水资源;因此,能够准确地进行长期预测,可为供需水计划的制订提供强有力的支撑。LSTM模型在预测达到一定长度时的误差明显增大,通过融合先进方法依然不能很有效地解决这个问题,主要原因是模型的学习能力不够。本研究提出了基于SGA+DWT的BiLSTM滚动预测模型SDBiLSTMR,将LSTM由单向变为双向,实现遗传算法的自发式调用;同时,将DWT引入过滤噪声,并采用滚动预测的方式,有效降低了长期预测的误差,提高了纳什系数,并得出以下结论:
(1)BiLSTM的学习能力比LSTM的学习能力更强。
(2)建模中,以矩阵作为数据载体可以更加高效地完成迭代。
(3)当模型越复杂参数越多、训练次数越多时,GPU展现出强大的并行计算能力,比CPU的建模时间有较大提升。
(4)SDBiLSTMR模型MSE最小,NSE最大,RE箱图上限较小、密度集中,预测曲线变化较小、误差线较短,比单步预测的精度更高,泛化能力更强,最接近无偏估计。
(5)遗传算法的个体在进化的同时,也可能存在退化。这将导致算法不稳定且有概率出现不收敛的现象,因此解决种群中的退化现象是后续研究的重点。
