基于多模态特征融合的三维点云分类方法
2021-02-05刘纯平
顾 砾,季 怡,刘纯平
(苏州大学计算机科学与技术学院,江苏苏州 215006)
0 概述
近年来,三维物体识别是计算机视觉领域的研究热点之一。常见的三维图像表示方法有点云、网格、体素与多视角图像等,其中点云是结构简单且接近原始采集数据的方法,在自动驾驶及机器人学等方面具有广泛的应用前景。由于Kinect等廉价三维获取设备的快速发展使得点云数据更易获取,因此三维点云识别逐渐成为计算机视觉领域的主要研究内容。
点云分类是点云识别的一项重要前置任务,且传统的点云分类方法[1-3]通常采用人工构建的描述子提取其几何特征,通过将点云转换为体素形式[4],再使用二维图像中常用的卷积神经网络(Convolutional Neural Network,CNN)对特征进行提取,并用于完成后续任务。该方法具有较好的普适性,但是体素形式的数据表现精度依赖于体素分辨率,而高分辨率引起的庞大计算量将限制其发展。由于人工设计的限制,传统方法普遍存在精度瓶颈以及鲁棒性不足的问题,且随着神经网络在二维图像感知领域的快速发展,研究人员逐渐将其运用到三维点云上学习点云特征。文献[5]构建一种创新性模型,该模型可以直接对原始点云进行处理,且在分类和分割任务上均取得良好效果,但其缺乏提取点云局部特征的能力。针对该问题,文献[6-7]通过引入多尺度来优化局部特征的提取性能。文献[8]提出更为简单高效的点云特征提取PointCNN模型,使得分类精度得到大幅提升,但与采用多视角图像作为输入的MVCNN[9]、GVCNN[10]等模型相比,该模型的整体性能偏低,这主要是由点云数据的本身信息量有限导致的。
本文在多模态特征融合的基础上,设计一种三维点云分类模型。为解决点云数据信息量不足的问题,该模型引入投影图作为补充,同时使用点云与图像作为输入,利用点云与图像的特征提取模块得到其对应的分类特征,并对特征进行加权线性融合得到最终分类结果。
1 相关工作
传统的点云特征是针对特定需求而手工设计的,例如描述局部表面变化的点特征直方图(Point Feature Histogram,PFH)以及用于全局路径规划的方向区间柱图(Vector Field Histogram,VFH)。随着深度学习在三维领域的发展,研究人员开始尝试利用机器自动学习点云特征。PointNet模型具有开创性,该模型是首个直接将三维点云作为输入的模型,且在点云分类和分割任务上取得显著成果。后续涌现出很多点云深度学习模型,如PointCNN、Point2Seq等。除点云外,其他基于三维表示法的深度学习模型也发展迅速,如基于投影图的MVCNN、GVCNN以及基于体素的VoxNet。
点云深度学习的难点之一是点云数据的信息量有限,除了继续深入研究点云特征提取方法外,还可以考虑通过引入其他三维表示法的数据进行补充。以往研究多数选择体素和点云数据相融合,而体素是一种不能直接获得的三维表示方法,通常需要从点云数据开始转换,这意味着如果原始点云数据存在缺失,则体素对应部分也会缺失,因此不能很好地用作信息补充。
投影图表示法的优势在于图像特征提取技术与其他技术相比已经非常成熟,采用简单模型即可获得较好的效果,但一般需要利用多视角采集来克服遮挡问题,而点云数据可弥补该不足。因此,本文选择采用二维投影图对信息进行扩充,将通过PointCNN得到的点云特征和二维CNN得到的投影图特征在分类层上进行融合,从而提高模型的分类效果。
2 多模态特征融合模型
针对点云数据自身信息量不足的问题,本文依据文献[11]中从其他模态引入信息进行弥补的思想,提出将点云特征和图像特征相结合的分类算法,以提高分类精度。基于多模态特征融合的点云分类模型如图1所示。从图1可知,模型存在2个分支,一个分支用于提取点云数据的特征,另一个分支用于提取图像特征,且对每个实例同时输入点云和图像数据。点云特征分支的原始输入是一个包含N个点的三维点云,且每个点有其对应的x、y、z坐标。图像特征分支的输入是分辨率为n×n的投影图,且带有RGB特征通道。点云和图像通过对应的特征提取模块和logSoftmax函数得到各自的分类置信度矩阵,将2个矩阵进行加权线性融合,最终得到输入实例的预测类别。

图1 基于多模态特征融合的点云分类模型Fig.1 Point cloud classification model based on multiple modal feature fusion
2.1 图像特征提取
CNN[12]是深度学习的代表算法之一,随着深度学习理论的提出和计算设备的更替,它得到了快速发展,并被广泛应用于自然语言处理、计算机视觉等领域。自AlexNet[13]开始,得到GPU加速支持的复杂CNN普遍用于提取二维图像特征,其中,最具代表性且使用最多的是VGG[14]、ResNet[15]模型及其改进算法[16]。
图像特征提取模块选择较为普遍使用的VGG11、ResNet50和ResNeXt101三种模型,采用其在ImageNet1K上的预训练模型对数据集进行微调,以提高分类精度。每个输入实例得到的是一个M为40维的分类特征矩阵,并统一记为Aimg。
2.2 点云特征提取
传统卷积算法是基于结构化数据(如图像、音频等)作为输入而设计的,然而三维点云是典型的非结构化数据,因此并不能将上述CNN直接作用于其点云数据上。文献[8]依据传统CNN思想提出基于点云的X-Conv操作,示例如图2所示。其中,点的数量表示对应的通道数目。X-Conv操作的主要思想是通过递归的卷积操作,将选定点邻域中其他点的特征聚集到该点上(9→5→2),使得选定点包含更多信息。

图2 X-Conv操作示例Fig.2 Example of X-Conv operation
PointCNN的输入是一个三维点云,可表示为F1={(p1,i,f1,)i:i=1,2,…,N1},即一组点集{p1,i,p1,i∈ℝDim}及每个点对应的特征集,C1表示初始特征通道深度。X-卷积算子的目的是将输入的F1转换为,其中,{p2,}i是从{p1,}i中选定的点子集,N2<N1且C2>C1,这说明经过X-卷积转换后的F2包含的特征点数减少,而对应的特征通道数增加。X-卷积如算法1所示。
算法1X-卷积算法

本文用p表示{p2,}i中的一个点,p对应的特征为f,N表示点p在{p1,}i中的k近邻集,则点p在X-卷积中的对应输入是一个无序点集S={(pi,f)i,pi∈N}。S可不失一般性地表示为k×Dim维矩阵P=(p1,p2,…,pk)T和k×C1维矩阵F=(f1,f2,…,fk)T,K表示可训练的卷积核。经过X-Conv后得到的输出Fp是输入特征在点p上的投影或集合。
X-卷积算子可简写为:
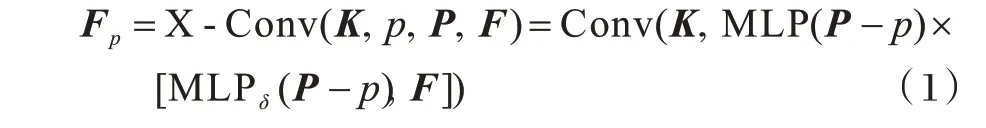
点云特征提取模块结构如图3所示,该模块由4个X-Conv卷积层和3个全连接层组成。N代表输入的特征点数,初始输入N为1 024,C为每个特征点输出时对应的特征通道数,K为计算时选择的近邻点个数,D表示空洞卷积[17]中卷积核的间隔数量。4层X-Conv卷积层的参数分别为:N1=1 024,C1=48,K1=8,D1=1;N2=384,C2=96,K2=12,D2=2;N3=128,C3=192,K3=16,D3=2;N4=128,C4=384,K4=16,D4=3。在每个X-Conv卷积层和前2个全连接层后均使用ReLU激活函数,并在第2个全连接层后加入参数值为0.5的随机失活,最终每个输入实例得到一个M为40维的分类特征矩阵Apc。

图3 点云特征提取模块结构Fig.3 Structure of point cloud feature extraction module
2.3 多模态特征融合
对于每个输入实例,经过上述特征提取模块后得到2个分别对应于点云和图像分类的40维特征矩阵Apc与Aimg。使用logSoftmax函数对特征矩阵得到分类置信度进行线性融合操作,从而得到分类结果。Softmax函数主要用于多分类任务中,logSoftmax函数是Softmax的一个变种,具有更好的数值稳定性,可简写为:

输出值范围为[-inf,0),表示输入xi对应每个类的概率。
融合过程可总结为:
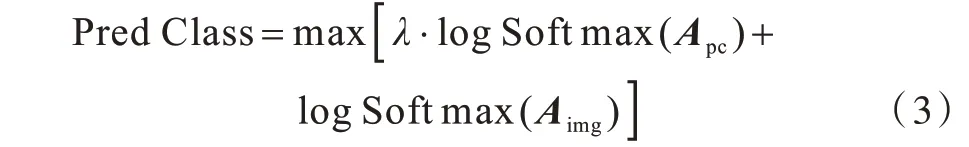
其中,λ表示融合时点云特征的权重,由实验得λ=0.4为最优值。
3 实验结果与分析
为评估模型在分类任务上的效果,本文采用由普林斯顿大学提出的ModelNet40数据集[18]及其扩展的投影图集。ModelNet40数据集共有12 311个人造物体的CAD模型,分为40类,其中,9 843个用于训练,2 468个用于测试。它扩展的投影图集来自马萨诸塞大学阿姆赫斯特分校的研究MVCNN-new[19],是对ModelNet40中的模型通过不同角度投影所得,分为12个视角,共147 732张图像。本文主要使用的是视角1,具体的实验环境与配置如表1所示。

表1 实验环境与配置Table 1 Experimental environment and configuration
对于点云特征提取模块,优化器为Adam,初始学习率为0.001,样本大小为32,共训练200个epoch;对于图像特征提取模块,优化器为Adam,初始学习率为0.000 1,样本大小为64,共训练30个epoch。
输入的三维点云数据是对ModelNet40数据集中原始物体模型的网格面上均匀采样1 024个点而得到的,并将其归一化到一个单位球面[20]。输入的投影图数据则是对原始物体模型在某个固定角度的投影,部分输入可视化结果如图4所示。

图4 输入数据示例Fig.4 Input data example
实验对本文模型在ModelNet40数据集上的分类准确率与其他三维模型分类网络输出精度进行对比,结果如表2所示。其中“,√”表示模型选择的输入“,—”表示模型未选择的输入。从表2可以看出,本文模型在分类任务上表现最佳,总体分类精度比基于点云输入的PointCNN和Point2Seq[21]提高4.7和3.8个百分点,比基于投影图输入的GVCNN和MVCNN提高3.3和1.4个百分点,这是因为本文模型同时选择了点云和图像作为输入,所以本文模型在ModelNet40数据集上的分类性能够有大幅提升。

表2 7种模型在ModelNet40数据集上的分类精度对比Table 2 Comparison of classification accuracy of seven models on ModelNet40 dataset %
实验考察了权重取值对点云特征在融合时分类精度的影响,结果如表3所示。从表3可以看出,随着权重的增大,本文模型的分类精度呈现先增大后降低的趋势,且当权重为0.4时分类精度最大。

表3 不同权重下本文模型的分类精度对比Table 3 Comparison of classification accuracy of the proposed model under different weights %
为更好地对本文模型的各模块作用进行评判,以及更深入地挖掘点云特征和图像特征间的关系,本文采用不同的图像特征提取模块进行消融实验,结果如表4所示。其中,“—”表示未选择的该模块或权重。从表4可以看出:仅采用PointCNN点云特征提取模块时,得到的初始精度为91.6%,当加入图像特征提取模块后,模型的整体性有大幅提高,且模块的总精度随着图像模块精度的提升而逐渐增大;采用ResNext101提取图像特征时,模块的最高总精度为96.4%,通过引入权重来优化模型,具体表现出2个模块对最终结果的影响,即模块之间形成互补关系,且以图像模块为主、点云模块为辅。
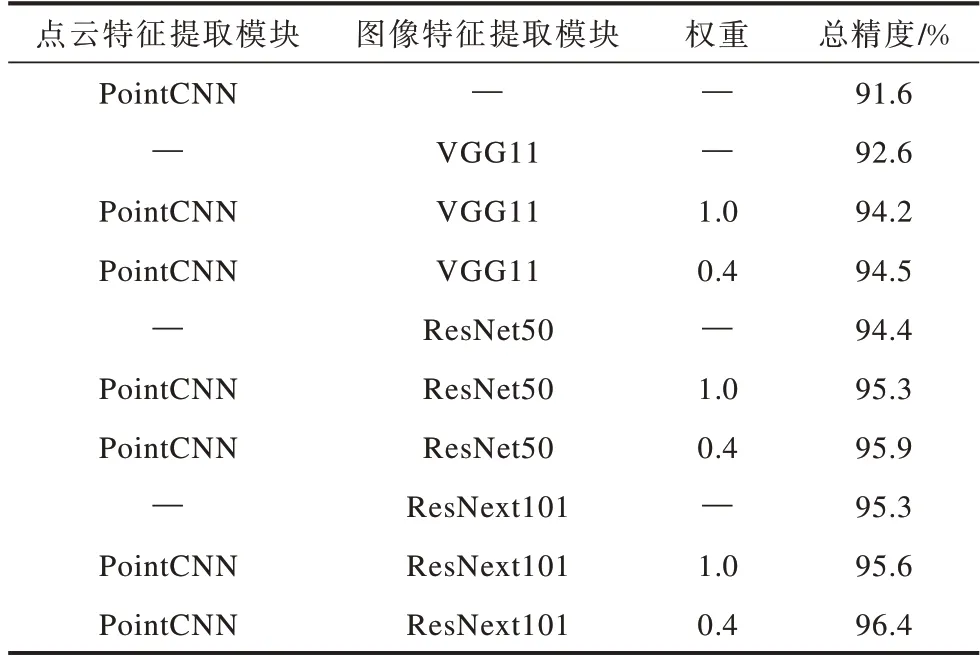
表4 消融实验结果Table 4 Ablation experiment results
图5是本文模型在ModelNet40数据集上取得最高精度时的混淆矩阵。由图5可知,除花盆(flower_pot)类之外,本文模型在其他39类上都取得良好效果,花盆类多数被错判为植物类(plant)和花瓶类(vase),这主要是由该数据集本身导致的。
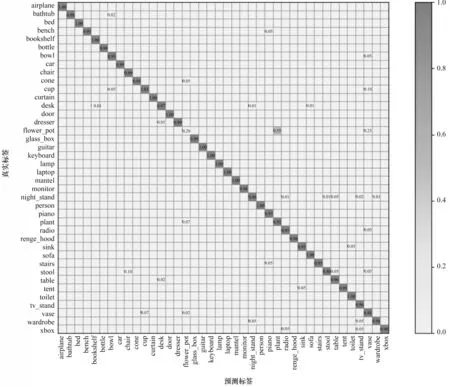
图5 本文模型的混淆矩阵Fig.5 Confusion matrix of the proposed model
4 结束语
本文设计一种基于多模态特征融合的三维点云分类模型。该模型同时以点云数据与图像数据作为输入,分别采用其各自的特征提取模块提取分类特征,并对提取的分类特征进行加权线性融合得到分类结果,以提高模型的分类准确率。通过ModelNet40数据集上的实验评估来选择最优图像特征提取模型,并验证了该模型相比其他模型的分类性能与精度均有大幅提升。下一步将引入图卷积神经网络对点云特征提取模块进行优化,以得到更为完整的局部特征,从而增强本文模型的特征表征能力并提高其分类性能。
