存算解耦合的粗粒度可重构阵列访存结构设计
2021-02-05景乃锋
洪 途,景乃锋
(上海交通大学电子信息与电气工程学院,上海 200240)
0 概述
粗粒度可重构阵列(Coarse-Grained Reconfigurable Array,CGRA)[1-3]包含可配置的处理单元(Processing Unit,PE)并具有互联结构,在不同应用下能够形成高效的数据流驱动计算。该体系结构配置数据流驱动代替传统的集中式程序计数器(Program Counter,PC)和寄存器堆,兼具通用计算的灵活性和专用计算的高效性。在计算能力方面,当程序映射到CGRA上时,可以对PE进行软件流水化以及并行展开实现高计算吞吐量;在功耗方面,数据流计算通过数据可用性以及配置对PE进行驱动,能够有效减少指令和调度的能耗开销[4]。
尽管CGRA提供了一个实现高能效计算的新方向,但在实际应用中仍然存在访存性能不足以支持大量PE计算的问题。虽然CGRA可以通过互联网络形成高效的数据流直传而无需通过大量的内存读写来实现数据传递,但由于多核计算的高计算吞吐量,访存性能较差仍然是CGRA存在的一个严重问题[5-6]。本文设计一种基于存算解耦合(Decoupled Access Execute,DAE)的片上存储读写单元,以优化内存访问的性能并提高硬件利用率。
1 存算解耦合与研究现状
传统的内存层次结构在地址访问中难以避免缓存缺失问题带来的内存延时,且这一问题在访存不具有局部性时更严重。因此,在缓存缺失时如何掩盖内存延时成为体系架构研究中的一个关键问题。
在基于程序计数器和寄存器堆的中央处理器(Central Processing Unit,CPU)和图形处理器(Graphics Processing Unit,GPU)体系结构中,可以通过上下文切换来掩盖内存延时。而CGRA因其分布式软件流水的架构特征,缺乏足够的寄存器以及中心协同控制来实现大范围的线程切换。因此,针对现有的CGRA架构,需要寻找其他内存延时掩盖的方法。
存算解耦合[7]将核心计算与访存请求分离,通过这两部分在迭代执行进度上的解耦合实现延时的覆盖,其执行原理如图1所示。在传统的耦合模式中,由于编译后的汇编代码必须在加法运算执行完并写回后才能开始下一次迭代的内存访问,使得整个应用需要承担所有的访存延时。而在解耦合模式中,访存的触发不再依赖于执行的结束,而是将访存和计算的运行时间重叠来实现内存延时掩盖。

图1 存算解耦合示意图Fig.1 Schematic diagram of decoupled access execute
基于DAE的访存延时掩盖技术关键在于:1)去除访问与执行之间非数据相关的依赖性,使访存能够提前执行;2)需要一个存储空间用于存放提前预取得到的访问数据;3)访存与执行之间需要同步机制,在访存数据就绪时激发执行部分的运行。
目前关于DAE的研究较多。在CPU领域,文献[8]通过ARM big.LITTLE(大小核)实现了DAE,其利用小核进行地址计算与内存访问,利用大核执行核心计算。但由于大小核之间只能利用缓存一致性进行交互,因此导致性能受损。ASIC中的doublebuffer设计也通过访存和执行的迭代解耦对内存延时进行掩盖。在CGRA架构中,文献[9-10]都使用了DAE的方式进行访存和计算的解耦合。Plasticine[9]将阵列分化为地址计算单元、片上存储单元和核心计算单元,分别用于数据预取、片上内存管理以及核心计算。FPCA[10]通过专用的地址生成模块对内存进行访问,内部包含简单的循环迭代控制和地址计算电路。
上述研究都使用了分化的地址单元和计算单元,通过先入先出(First Input First Output,FIFO)机制连接地址计算和核心计算来传递数据[11],但显然这些设计的硬件利用率对应用的计算访存比很敏感(如Plasticine在所有应用中的平均利用率仅为39.27%),并且完全分离的执行和访存对程序员和编译器也提出了更高的要求,需要对两个部分分别进行编程和编译。此外,对于间接访问,由于访存得到的数据仍要作为地址进行计算,因此无法进行延迟优化。
2 基于存算解耦合的访存结构
由于现有CGRA架构中仍然存在硬件利用率低、编程抽象以及性能受限的问题,因此本文提出基于DAE的访存结构Load/Store Elemen(tLSE)。图2中以两个LSE结合成LSE对的形式给出了架构框图,实线与虚线分别表示数据通路和控制通路。

图2 LSE对架构Fig.2 Architecture of LSE pair
LSE由控制块和轻量级的存储空间组成,存储空间可以在不同的需求中根据配置对不同类型的访存进行解耦合优化。控制块主要包含有限状态机、线程计数器以及请求缓冲区。LSE对中主控制块可以完成主从控制块之间的数据与控制协同,分别如图2中粗实线与粗虚线所示,在控制块所控制的存储空间可以接收主控制块的数据输入和控制输入。LSE对布局在PE阵列的四周,通过互联网络为需要进行访存的PE提供访存接口。LSE的布局图如图3所示。
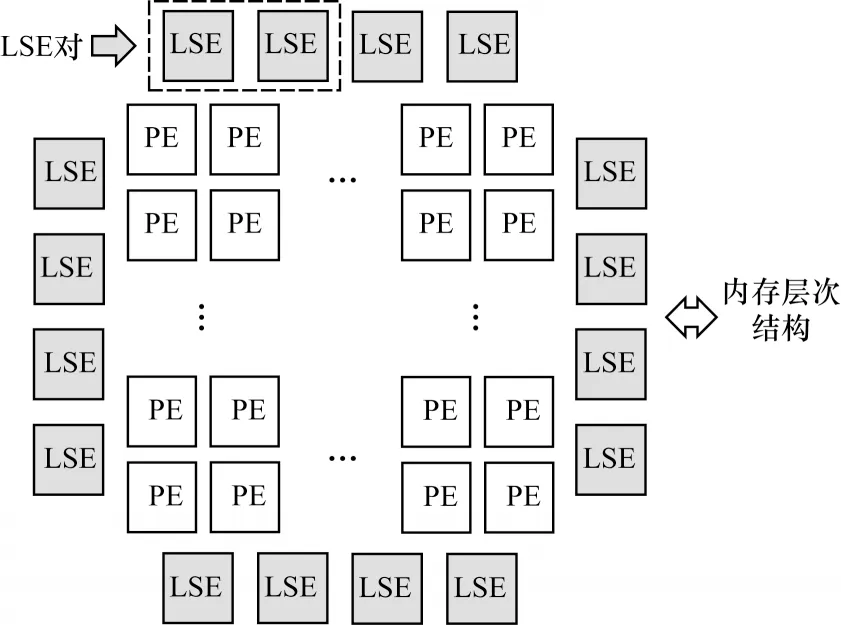
图3 LSE布局图Fig.3 Layout of LSE
2.1 仿射访问
通过循环迭代变量经过仿射变换得到地址进行的访问即仿射访问,其地址与迭代变量函数的最高次为1。这种访问类型(包括连续访问)空间局部性较好且具有无循环依赖的特征。通过单独的LSE即可对其进行如图4所示的映射优化,对PE阵列进行仿射变换计算得到地址并通过互连网络输入到LSE中,将LSE配置为FIFO模式,通过图2中的线程计数器为请求打上标记并发送到内存层次结构。线程计数器的计数大小与存储容量相等,每个计数标签对应存储中的一个条目,当数据返回时根据标签填充进对应的存储条目中。在FIFO模式下,LSE的输出由输出指针进行指定,输出指针总是指向先进入LSE的请求对应的存储条目。这种措施可在内存层次结构发生乱序时保证程序的正确性。

图4 仿射访问优化示意图Fig.4 Schematic diagram of affine access optimization
在图4中,LSE起到了将执行部分(核心计算)和地址计算部分(仿射变换)在循环迭代进度上隔离的效果。执行部分在执行第1次和第2次迭代时,LSE中容纳了第3次~第18次迭代的请求,这些请求正在内存层次结构中进行内存访问并承受内存延时。地址计算部分非阻塞地执行第19次和第20次迭代。当存储空间足以覆盖内存延时时,执行部分将感受不到内存延时,因为访存请求是提前于核心计算被发出的。
LSE对的设计加强了CGRA对不同访存延时的适应能力,在内存访问较多、存储带宽紧张的情况下,LSE对可以通过主控制块对从控制块控制的存储空间加以利用,从而实现串联的效果。两倍的存储空间可以用来容纳更多次的迭代,通过进一步隔开执行和访存之间的迭代进度来适应更高的访问延时。LSE对在访存延时低时独立工作,在访存延时高时串联协同工作。
相比于其他DAE对仿射访问的优化,LSE通过数据可用性对执行部分进行驱动,即当LSE中头指针所指向的数据可用时才会使LSE输出数据并激活执行部分进行计算。这种细粒度的驱动方式一方面简化了访存和执行之间的同步,另一方面也大幅减少了所需的存储空间面积,可计算的数据将被立刻输出并释放存储空间用于下一个访存请求等待内存延时。
在软件抽象方面,LSE简化了程序员和编译器的工作,只需要在高级语言编译后的数据流图(Data Flow Diagram,DFG)基础上将访存替换成LSE即可完成DFG到CGRA配置的映射。这一点在分化的DAE策略中难以实现,因为访存和执行的完全分离,需要分别对其进行编程并完成同步。
2.2 写请求
作为PE阵列与内存层次结构的接口,LSE除了读请求以外还需要具备完成写请求的能力,从而在不同读写比例的应用中都保持较高利用率。
如图5所示,LSE对通过对齐的协作方式完成写请求,两个LSE分别暂存写请求的数据和地址。其中,从控LSE保存写地址,主控LSE保存写数据,主从控制块分别为输入的数据打上迭代标签。
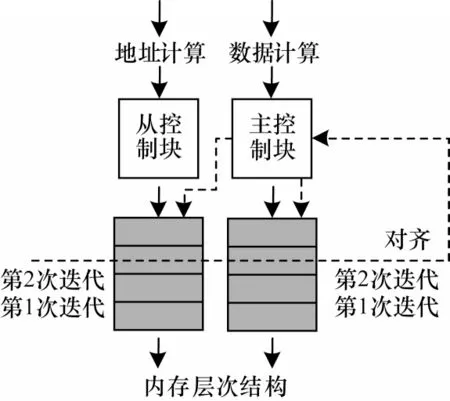
图5 LSE写请求示意图Fig.5 Schematic diagram of LSE write request
数据流图中的地址和数据来自两条并行的数据通路,因此,数据和地址很可能不会同时到达。在图5中,主控制块通过虚线箭头所示的控制通路对LSE对中的两块存储空间进行协同控制,此时LSE不再工作于FIFO模式下,而是根据条件进行选择输出。当同一迭代标签的数据和地址都凑齐时触发写请求的产生,LSE对将地址和请求共同发送到内存层次结构形成一个完整的写请求。LSE的存储空间也为地址和数据通路提供了解耦合的关系,当一条通路延迟较长时,通过存储空间为短路径保留更多的请求,从而防止短路径的堵塞。
现有CGRA的访存结构往往不兼具写请求的能力,因为写请求的地址和数据分别产生自地址单元和计算单元,而分化的地址单元和数据单元之间缺少协同。因此,CGRA通常需要专用的写结构用于写操作,这加剧了CGRA架构的硬件利用率问题。
2.3 间接访问
间接访问是现有CGRA存储结构中存在的问题,因为现有CGRA结构中访存得到的数据会作为地址继续进行内存访问,需要将地址计算再次分化为第1次访问和第2次访问来分别进行预取,这对数据通路和编程的灵活性提出了很高的要求,而分化的地址计算和核心计算不具备这一灵活性。另一方面,应用中存在很多间接访问(如在SPEC 2017应用集合中间接访问占据了所有应用总访存的15%[12]),这些间接访问仍然属于流式访问的范畴,即不具有循环间依赖特性,因此,其仍然具备优化的潜力。
间接访问的地址具有静态不可预测和地址随机分布的特性。前者导致难以执行很有效的预取,后者导致失去很好的空间局部性,两者对性能影响都很大。图6展示了利用LSE对优化中间接访问的过程。

图6 间接访问优化示意图Fig.6 Schematic diagram of indirect access optimization
如图6所示,本文通过LSE对之间的对齐和更大范围内的协同行为对间接访问进行优化。b[i]以及d[i]的访问属于仿射访问,LSE控制存储空间以FIFO方式隐藏第1次访问的内存延时。对数组a和数组c的访问属于间接访问,需要使用b[i]和d[i]作为地址进行访问。在正常映射的基础上,LSE对通过对齐的方式对a和c数组进行乱序访问。乱序访问时不再对访存数据执行先入先出顺序,而是像写请求一样,当LSE对中某一次迭代的两个数据都凑齐时,触发这一次迭代两个数据的共同输出。
为保证程序的正确性,需要使加法运算的其他操作数i和e[i]保持与乱序的LSE对同样的顺序。这一过程通过全局的标签FIFO实现,LSE对完成一次对齐后将数据输出到PE阵列并将对应的标签写入标签FIFO中对执行顺序进行记录。操作数i和e[i]对应的LSE此时需要根据各自在标签FIFO中的指针从标签FIFO中读取迭代标签并根据标签输出自身对应条目的数据。此时i变量虽然不需要进行内存访问,但仍需要经过LSE实现顺序跟随的行为。在此过程中,a[b[i]]和c[d[i]]称为对齐的操作数,a[b[i]]、c[d[i]]、e[i]和i称为相交的操作数(它们需要执行互为操作数的计算)。
在行为上,对第1次访问进行仿射访问的优化方式掩盖第1次访问的访存延时,从而保证b[i]和d[i]的吞吐量不受延迟影响。对于第2次的间接访问,除同样使用存储空间进行解耦合外,还需要通过乱序执行做进一步优化。其他相交的操作数则进行顺序跟随来保证程序的正确性。两次迭代隔离实现两级预取,间接访问的延时将不会影响阵列的计算吞吐量。
对间接访问进行乱序优化的原因是间接访问的空间局部性较弱,很可能其先发的请求缓存缺失而后发的请求缓存命中。在使用乱序执行时,先对齐的迭代可以先进行后续的执行而不必维持原有顺序,这不仅减少了后续PE的流水线停顿,同时也能尽早释放存储空间。
相比于FIFO模式,乱序执行引入了如图7所示的线程级并行方式,其中虚线框内的第4次迭代先集齐了操作数,可以先输出进行计算而不用等待之前迭代的执行。这一优化只使用在间接访问中,因为仿射访问的地址变换往往是单调的,内存缺失不具有随机性。这种乱序和跟随的行为实现了一种简化的记分板,由于间接访问具有更高的平均延时,因此以间接访问的匹配顺序作为循环迭代的执行顺序,而其他操作数进行顺序跟随。此模式可优化作为瓶颈的间接访问的性能,从而提高应用的整体性能。

图7 乱序执行的线程级并行示意图Fig.7 Schematic diagram of thread level parallelism of out-of-order execution
LSE将访存操作与轻量级存储空间进行耦合,针对所有访存请求的延迟进行迭代隔离,同时还通过串联、对齐、跟随的协同操作具备更强的控制灵活性,可以实现对各种访存类型(包括写请求)的优化。相比于现有的CGRA的访存结构,LSE对访存本身进行定制而不是对地址计算和核心计算进行分化,从而避免了对地址计算和核心计算的分步编程和同步。同时统一的存储接口有利于提高计算单元利用率,避免对应用的地址计算和核心计算比例的敏感性。
3 实验与结果分析
3.1 实验平台
本文在文献[13]的目标CGRA架构下通过替换LSE结构对访存结构进行优化。实验平台是基于C++编写的系统级模拟器。该模拟器包含周期精确的PE阵列以及周期近似的内存层次单元,同时包含32 KB的缓存以及地址合并单元[14(]coalescor)。本文在动态随机存储器(Dynamic Random Access Memory,DRAM)仿真模型中使用周期精确的DRAMsim2[15],以保证内存延时和带宽的准确性,同时在DRAM设备上将DDR3_micron_16M_8B_x8_sg15作为存储性能模拟的参数来源。以3×3卷积应用为例的实验流程如图8所示。

图8 卷积映射流程Fig.8 Procedure of convolution mapping
一段C代码程序通过编译形成DFG[16],在DFG中将访存操作替换为用LSE实现。生成带有LSE的DFG后,再根据图8所示的连接关系、算子以及访存类型将DFG转化为模拟器和硬件可识别的配置包,模拟器通过配置包对其包含的PE、互连结构和LSE进行配置,从而实现应用需求的计算功能。
3.2 测试应用选择
实验中从应用集MachSuite[17]选择以下5个典型应用进行测试:Stencil是标准的无依赖流式处理应用,可以测试DAE对连续访问的优化;稀疏矩阵乘(SPMV)、分子动力学(MD)和广度优先搜索(BFS)包含间接访问,且含有不同数量的相交间接访问;序列匹配(NW)具有一定的循环间依赖性并含有较多的条件分支判断。上述应用的计算、访存、分支指令占比如图9所示。可以看出,由于Stencil和MD属于计算密集型应用,因此访存指令占比较小,而SPMV、BFS以及NW分支和访存指令占比较大。

图9 各类指令占比Fig.9 Proportion of various instructions
在访存局部性上,本文所选择的应用也具有不同的特征,根据文献[18]计算各个应用的时间、空间局部性得分,如图10所示。可以看出,5个应用具有不同的时空局部性,其中具有间接访问的MD、BFS以及SPMV的局部性得分最低。

图10 时空局部性对比Fig.10 Comparison of temporal and spatial locality
3.3 实验结果分析
实验设置了不具有LSE、LSE维序优化和乱序优化的3个CGRA性能对照组,以及由gem5[19]根据文献[20]仿真的ARM A15的性能结果。
以不具有LSE的CGRA的性能作为性能基准,实验结果如图11所示。可以看出,在stencil和NW中,LSE能够带来平均2.72倍的性能优化,在3个具有间接访问的算法应用中,这一优化为1.25倍,在采用乱序执行对间访问优化时,乱序执行能再带来平均22%的性能优化。Stencil和NW由于不具有间接访问,因此不进行乱序执行优化。

图11 综合性能对比Fig.11 Comparison of comprehensive performance
除了综合的应用性能之外,分别探索仿射访问与乱序执行的性能随LSE的深度改变的变化,实验结果如图12所示。

图12 LSE存储空间大小对仿射访问与间接访问的影响Fig.12 Influence of LSE storage size on affine access and indirect access
以存储空间大小为4作为基准,测试LSE存储空间对性能的优化效果,如图12(a)所示,LSE到达拐点后能够达到4倍以上的性能优化。在图12(b)中以4深度的维序执行为性能基准,可以看出,在间接访问中,乱序执行相比维序执行能够达到平均21%的性能提升,并且能够以更少的存储空间开销实现更好的访存效果。
从硬件开销角度考虑,相比于在PE内实现多线程的文献[21]方案,只在LSE中进行线程级并行而不是在每个PE中进行,减少了PE内部的上下文存储面积;而从功耗角度考虑,相比于从DRAM预取到缓存,再从缓存读到PE阵列的传统内存延时掩盖策略,LSE具有更精准(不会被缓存颠簸影响)和数据搬移次数更少的特点,在功耗上具有优势。
4 结束语
针对粗粒度可重构阵列的访存问题以及现有解决方案的不足,本文提出了基于访存执行解耦合的CGRA访存结构LSE,其将控制逻辑集成在轻量级的存储空间中,通过单个LSE、LSE对间以及全局协同可以进行串联、对齐、跟随等操作,从而适应不同的访存场景。LSE在硬件利用率、编程抽象以及间接访问方面较传统结构性能均有所提高,实验结果也证明了其在整体应用及间接访问中的性能优化效果。下一步将实现寄存器传输级(Register Transfer Level,RTL)代码,得到更精确的硬件实验数据以及更接近实际流片后的结果。此外,还将研究基于C语言的编程模型和编译自动化方法,使基于访存结构LSE的解耦合CGRA对程序员更友好,适用范围更广。
