基于自归一化神经网络的低分辨率人脸识别
2021-02-04石正宇陈仁文
石正宇,陈仁文,黄 斌
南京航空航天大学 机械结构力学及控制国家重点实验室,南京210016
人脸识别具有巨大的应用前景,近四十年来被广泛研究,并且涌现出了众多优秀算法。近几年,一些基于深度学习的技术[1-2]在LFW数据集上的识别率已经超过了99%。然而,当涉及到监控系统时,由于采集到的人脸图片往往是低分辨率(Low-Resolution,LR)的,并且伴随着模糊、遮挡等,这些算法的性能大大下降。利用这些低质量的图片进行识别,被称为低分辨率人脸识别(Low-Resolution Face Recognition,LRFR)问题。
现有的LRFR方法可以大致上分为两类,其中一类是超分辨率重构法,即提高待测图像的分辨率再使用传统的人脸识别方法进行识别[3]。传统的超分辨率重构方法会模糊图像细节,比如纹理和边缘,因此Wang等人[4]使用深度神经网络,并巧妙地构造了损失函数,在监控数据集上验证了算法的有效性。尽管这些方法可以一定程度上恢复低分辨率图像,但深层网络结构往往会带来巨大的计算量和时间消耗,因此不适用于实际应用。此外,大部分超分辨率重构法的目标在于恢复LR 图片的视觉效果,而非针对模型的识别效果。因此,重构得到的图片中没有判别性信息的增加,甚至会带来冗余信息,从而降低最终的识别率[5]。
另一类方法是子空间法,相比于超分辨率重构法更直接,即采用映射函数将高低分辨率图片映射到统一的特征空间中,在这个特征空间里,不同分辨率图像特征之间的距离最小。基于线性判别分析,文献[6-7]提出了几种具有判别性的子空间方法;Ren等人[8]采用Gram核函数计算不同特征之间的差异性,并将其最小化,从而获得映射函数;Biswas等人[9]提出多维缩放方法(MDS),使得待测图像以及高分辨率(High-Resolution,HR)样本图像之间的距离与样本图之间的距离大致相等;为减少计算成本,Biswas 等人提出了更灵活的框架[10],在特征提取阶段不借助特征点标定;文献[5]基于判别相关性分析(Discriminant Correlation Analysis,DCA),将高低分辨率图片映射至同一特征空间,不仅解决了特征向量维度不匹配的问题,同时也使对应的HR-LR 图片之间相关性最大;Yang 等人[11]提出两种基于MDS 的方法(DMDS和LDMDS),除了不同特征之间的距离,还考虑到它们之间的相似度,并取得了很好的效果。
由于卷积神经网络(Convolutional Neural Network,CNN)的优良表现,Zeng等人[12]采用深度网络(RICNN),将HR 图片和上采样后的LR 图片混合,从中学习分辨率不变性特征表达。文献[13]指出,尽管RICNN提高了LRFR的精度,该方法对于待测低分辨率图片的分辨率变化十分敏感。为了解决这一问题,Lu等人[13]基于ResNet提出了深度耦合残差网络(Deep Coupled ResNet,DCR),该模型的损失函数与文献[11]是相同的思路,即类内距最小,类间距最大,同时特征空间中高分辨率及其对应的低分辨率图片之间的距离最小。
尽管DCR方法在SCface数据集上取得了很高的识别率,但同时深度网络也伴随着巨大的计算量,为解决这一问题,本文提出一种轻型判别性自归一化神经网络(Light Discriminative Self-normalizing Neural Network,LDSNN),在模型的训练阶段,网络从高低分辨率图片中提取特征并将其映射到子空间中。训练完成后使用SVM进行分类,本文的主要创新点如下:
(1)基于PydMobileNet[14]设计出高效CNN 结构用于特征提取。
(2)优化损失函数以扩大类间距,同时加入center loss[15]约束以缩小类内差异。
(3)引入缩放线性指数单元,加速网络的收敛。
多个数据集上的实验结果表明了本文算法相比于现有方法有一定提高。
1 LDSNN的模型结构
1.1 特征提取及耦合映射
由于其杰出性能,CNN 被广泛用于特征提取。在人脸检测与对齐阶段,采用了能较好地检测低分辨率人脸的MTCNN[16]。文献[4]指出,在低分辨率图片的特征提取中,深层网络结构以及过大的通道数会降低模型性能,因此本文采用了合适的卷积核大小以及通道数,设计出高效CNN,网络的基本组成是瓶颈状的残差结构,如图1所示。
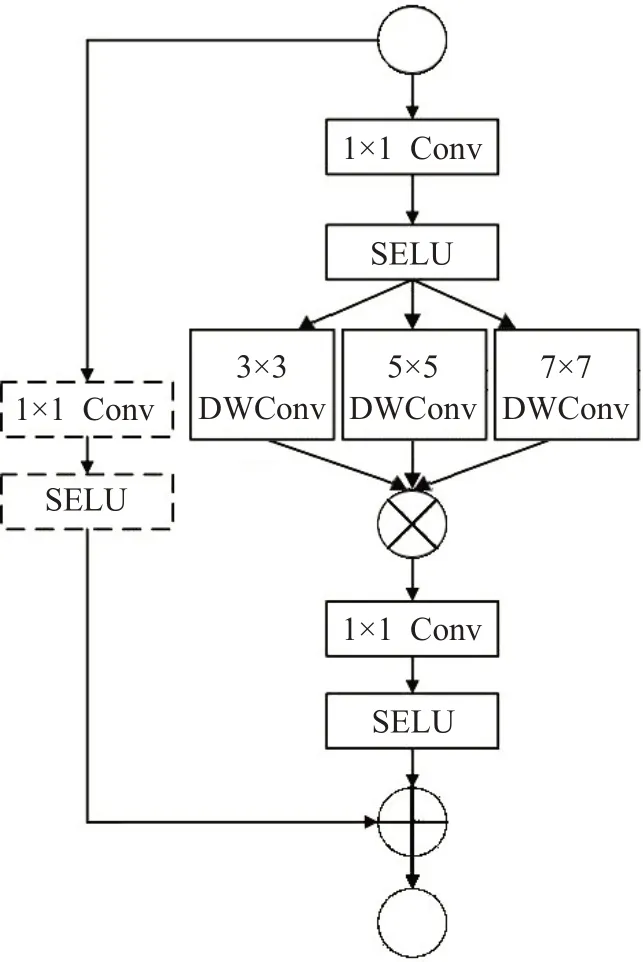
图1 残差模块
残差结构用于控制深度可分离卷积(Depthwise Separable Convolution,DWC)的维度,该结构中使用3个不同大小的卷积核取代传统的3×3 卷积核来进行DWC卷积操作,并将得到的特征图级联,相比传统3×3卷积而言能获得更多的空间语义信息。级联之后继续经过1×1卷积和SELU[17]激活函数得到模块的输出。左侧虚线表示当步长为1的时候不进行1×1卷积操作,步长为2 的时候进行,并与前面得到的特征图相加。以FERET数据集上的实验为例,具体的网络结构如表1所示,共包含6个残差模块。
每个卷积层都伴随SELU激活函数,定义如下:
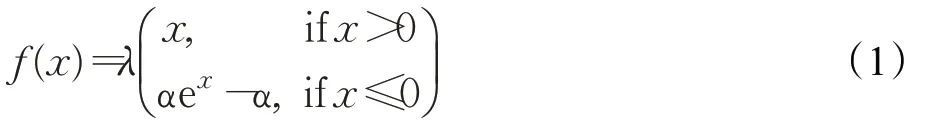

表1 网络结构
文献[17]中证明了取λ≈1.050 7 和α≈1.673 3 可以使得神经元输出逼近于零均值和单位方差,通过数层前向传播最终输出也会收敛到零均值和单位方差,这种收敛属性使学习更具鲁棒性。本文中λ和α的取值与文献[17]相同,SELU与ReLU函数的对比如图2所示。

图2 SELU和ReLU激活函数
如图3所示,相同的参数设置下,使用SELU激活函数的网络,loss值下降得更快,说明SELU激活函数相比传统的批归一化(Batch Normalization,BN)与ReLU 组合能更快地使网络收敛。

图3 两种激活函数的对比
将提取出的特征映射至160维的特征空间中,作为耦合映射阶段的输出,为了进一步稳定训练过程并减少在小数据集上的过拟合,本文还采用了L2正则化。
1.2 损失函数及优化
耦合映射阶段160 维的特征向量构成了损失函数的输入,具体结构如图4 所示(图中n表示输入样本的类别数)。
耦合传统的Softmax 损失函数并不能优化特征从而使得正样本有更高的相似度,同时负样本有更低的相似度。为了扩大决策边界,本文在损失函数中加入了CosineFace[18]约束,不同分辨率图片提取到的特征之间的类间距定义如下:

图4 损失函数的组成

约束条件为:
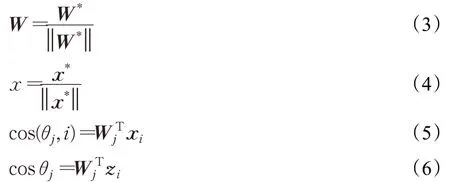
式中,xi和zi分别表示高低分辨率图片中对应着标签yi的第i个特征向量,n表示输入样本的类别数,N表示每一批的训练样本数。Wj表示第j类的权值向量,Wj与xi之间的夹角用θj表示。本文的实验中添加约束,m取值为0.5。
为了更好地利用类别信息,本文采用了center loss,从而最小化类内距,使得相同类别的特征之间更紧凑,定义如下:

为了保证HR 及其对应的LR 特征之间的一致性,本文添加了欧式距离约束,定义如下:

最终的损失函数定义为:

当loss不再下降时停止训练,将样本图以及待测图都输入到LDSNN 模型中以获得相应的特征向量,并采用SVM 分类器进行分类,本文中采用的核函数为线性核函数。
2 实验及分析
在所有的实验中,λ1和λ2都设置为0.001,并且将特征向量的维数设为160。由于训练数据中存在着低质量的图片,为了进一步减少过拟合,本文采用了Drop-Block[19]方法,实验表明最佳参数设置为block_size=3 以及keep_prob=0.8。本文深度学习框架使用TensorFlow,采用Xavier 参数初始化,初始学习率设置为0.01,总迭代轮数(Epoch)为300,每迭代75 轮学习率衰减为之前的0.1倍,权重衰减(Weight Decay)设置为0.000 1,输入批次大小(Batch Size)为64,采用动量(p=0.9)的标准动量优化法(Momentum)进行权重的更新。
关于LRFR的研究,由于缺少由监控摄像头拍摄到的低分辨率数据集,大多数研究都是基于高分辨率数据集比如FERET[20],将高分辨率图片降采样得到LR 图片,这显然跟实际中的监控情况有所差别[23]。在FERET数据集中鲜有模糊、遮挡的图片,因此有必要在更具挑战性的监控数据集上进行实验,比如UCCSface[21]和SCface[22],更接近现实情况。本文将提出的LDSNN 与现有的DMDS、LDMDS[11]以及RICNN[12]等方法进行了对比,实验表明本文的方法在三个数据集上的识别率均有较大的提升。所有实验结果中的识别率均为rank-1识别率。
2.1 在FERET数据集上测试
与文献[11]一致,本文的实验采用了FERET的一个子集,其中包括200类,有着不同的姿态、表情以及光照条件,如图5所示。

图5 FERET数据集中相对应的高低分辨率图片
随机选取50 类用于训练LDSNN 模型,剩余的150类用于测试,高低分辨率图片的分辨率分别为32×32和8×8。训练结束后,每类选取三张降采样至8×8 作为待测图,剩余四张作为样本图。在本文的方法中,通过对损失函数的改进可以逐步提高最终的识别率,如图6所示。
图中,横轴上从左往右对应的四个损失函数分别是:Softmax loss、CosineFace loss、CosineFace loss+center loss、CosineFace loss+center loss+Euclidean loss,可以看出随着损失函数的改进,模型的性能也在逐步提高。

图6 损失函数与识别率的关系
不同的DropBlock 参数设置对识别结果的影响如图7所示,图中横轴表示不同的keep_prob值,可以看出当block_size和keep_prob分别取值为3和0.8时,模型性能最佳。文献[19]指出,当block_size=1 时,DropBlock就退化为dropout,显然该方法优于传统的dropout。
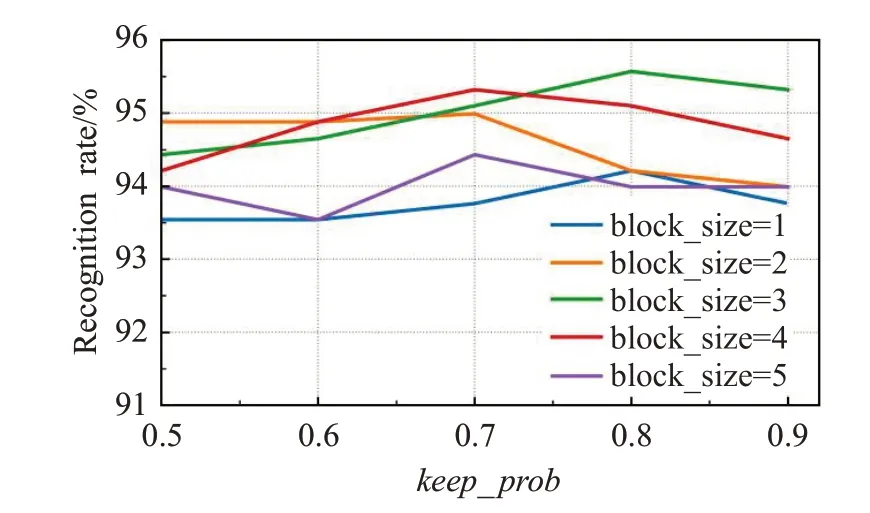
图7 不同参数设置对识别率的影响
本文也探索了特征空间的维度对识别结果的影响,并选取160作为实验设置,如图8所示。
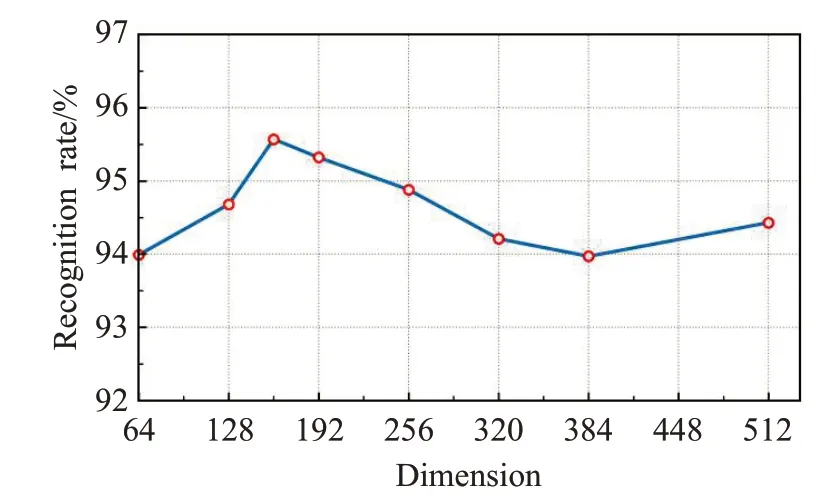
图8 特征空间的维数与识别率的关系
文献[15]指出,更大的特征维度相比小维度而言,会需要更多的训练迭代次数来达到最优,因此计算量更大。损失函数中超参数m对结果的影响如图9所示,当m取值从0.25 增加到0.4 时,识别率显著增加。可以看出,当m在0.4到0.5之间时可以取得最佳效果。
不同的m取值下,特征分布可视化效果如图10 所示。显然,随着m的增加,特证空间中不同类别之间的距离也随之增大,从而扩大决策边界,使特征更具判别性。
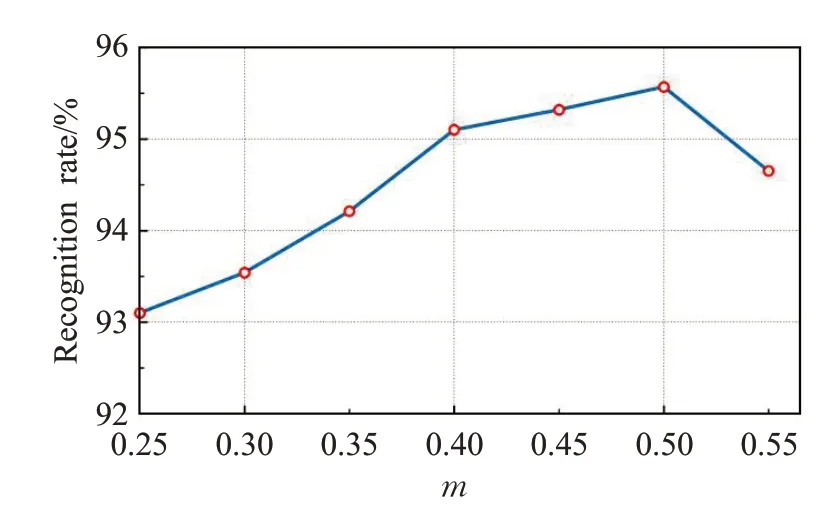
图9 超参数m 对识别率的影响
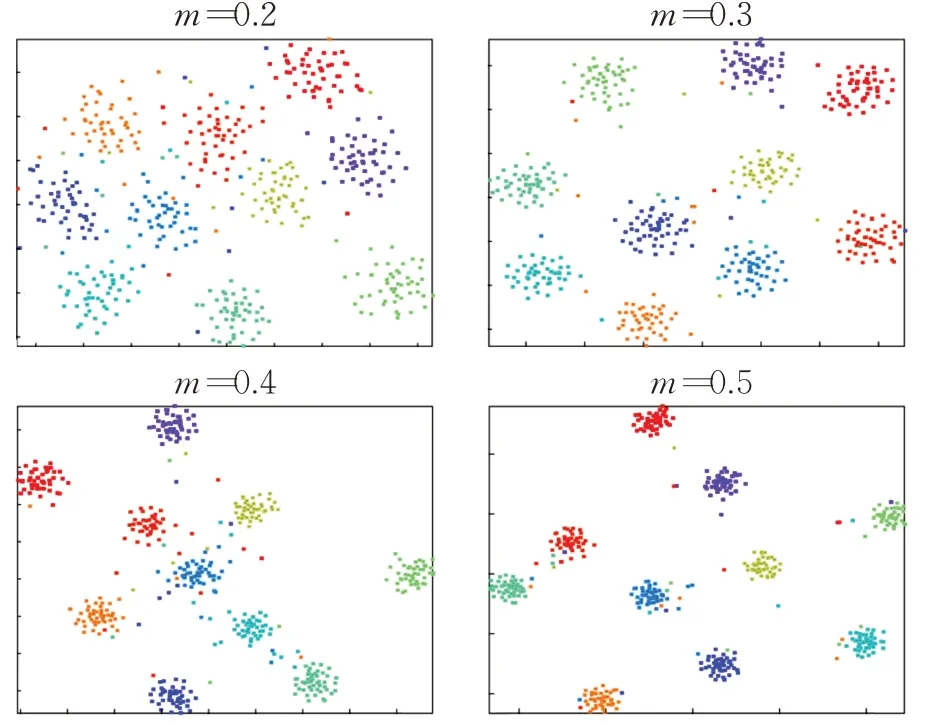
图10 不同的m 取值对特征分布的影响
不同各种方法的rank-1识别率对比如表2所示。在相同的实验设置下,文献[11]使用了四次双线性插将低分辨率图片上采样到所需大小,本文提出的LDSNN 在图片预处理过程中仅采用了简单的双三次插值,相比文献[11]的方法大大简化,且识别率提高了超过2%,表明了该算法的有效性。
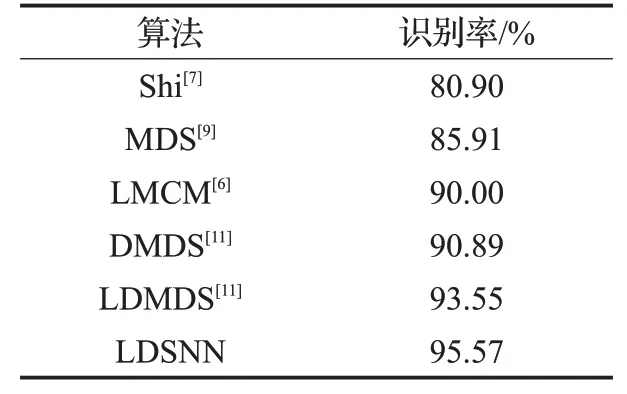
表2 FERET数据集上的识别率对比
2.2 在UCCSface数据集上测试
UCCSface数据集是由1 800万像素的摄像头在100~150 m 距离拍摄到的学生图片,该数据集有超过70 000个人脸区域,其中很少有正脸或者无遮挡的图片,是非限制场景下户外人脸识别领域新的基准数据集。本文的实验设置与文献[21,23]一致,共选出180 类,每类都不少于15 张图,其中10 张用于训练LDSNN 模型,剩余的5 张或更多图片用于测试。本文将裁剪出的人脸区域规范化为80×80,作为HR 图片,并将其降采样至16×16作为对应的LR图片。初始学习率设为0.01时训练集与验证集的loss和训练周期的关系如图11所示,可以看出训练集和验证集的loss曲线都在持续下降,走势基本相同,说明并没有出现过拟合现象。
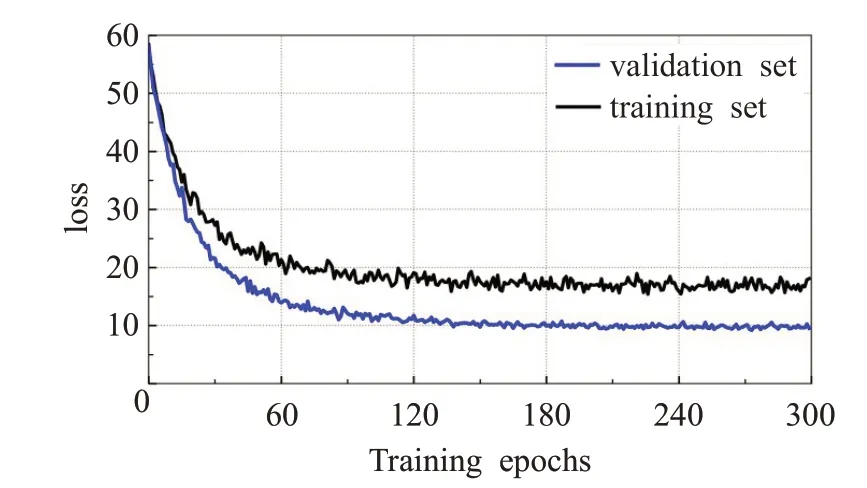
图11 训练集与验证集的loss和训练周期的关系
现有的性能最佳的方法是文献[23]中,rank-1 识别率达到了93.4%。不同方法的性能对比如表3 所示,可以看出本文提出的模型相比现有方法性能得到了一定的提升。考虑到DNN 模型在训练阶段使用了4 500 张图片,本文仅采用了1 800 张,计算量大大减小,这也表明本文模型能够处理现实中的监控图片。

表3 UCCSface数据集上的识别率对比
2.3 在SCface数据集上测试
该数据集共有130类,每类包括了监控摄像头在三个不同距离4.2 m(d1),2.60 m(d2),以及1.00 m(d3)距离下拍摄到的共15张图(每个距离3张),以及一张高清正脸图。与文献[11]一致,将d3 距离下拍摄的图片规范化至48×48,作为高分辨率图片,将d2 距离下拍摄的图片降采样至16×16作为低分辨率图片。
随机选取80 类作为训练集,剩余50 类用于测试。如表4所示,LDSNN算法平均识别率达到了84.56%,比现有的最佳算法LDMDS提高了3个百分点。
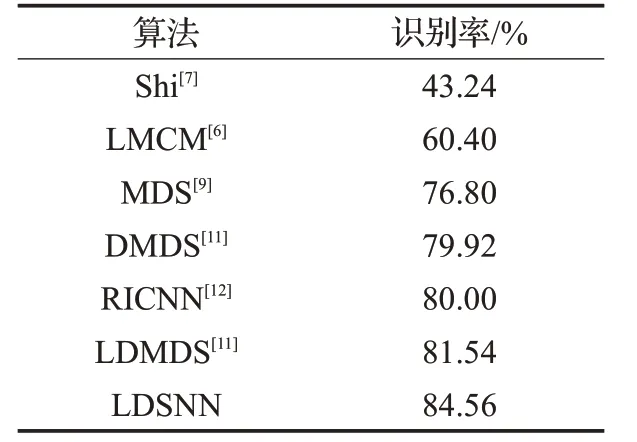
表4 SCface数据集上的识别率对比
2.4 实验结果分析
在3 个数据集上,LDSNN 的识别率相比现有算法均得到了提升。对比实验结果可以得出,尽管FERET数据集上的训练样本最少,但相对于现实场景中的模糊遮挡等情况,标准数据集中的人脸图片更易于识别。同时,UCCSface数据集上的训练样本最多,因此识别率也达到了较高的水平。
用LDSNN 模型从SCface 数据集中不同的LR 图片中提取特征,并计算特征间的欧氏距离,如图12,数值越小表明图片越相似。可以看出相同类别的图片之间欧氏距离较小,不同类别的图片之间欧氏距离较大,这表明本文的方法能够缩小类内距,扩大类间距,从而使提取出的特征更具判别性。

图12 不同图片之间的欧氏距离(×10-9)
如图13 所示,从左到右分别表示8×8、12×12 以及16×16 分辨率下的特征分布可视化结果,由于LDSNN模型结合了高低分辨率图片中的信息,其特征分布抱团性良好,即使在极低分辨率的情况下(如8×8),其特征空间中的分布依然具有可分性,因此适用于低分辩率人脸识别任务。
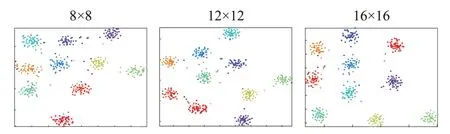
图13 不同分辨率下的特征分布结果
然而,在非限制场景下,监控设备捕捉到的人脸图片往往伴随着一定的遮挡或角度倾斜,如图14 所示为UCCSface 中的误判样本,由于遮挡造成低分辨率图片中有效信息减少,模型难以识别。应对这种情况,可以通过增加训练样本的数量来提高识别率。

图14 UCCSface数据集中的误判样本
3 结束语
本文提出了一种新的基于自归一化神经网络的耦合映射方法——LDSNN,可以从图片中学习到具有判别性的特征,并将其映射到子空间中。在子空间内,优化Softmax 函数使得不同的类别之间的特征更稀疏,并且引入类内距以及欧氏距离约束,从而使相同类别的HR及LR图片更紧凑。在标准数据集FERET以及两个监控数据集UCCSface 和SCface 上的实验结果表明本文的方法相比现有的算法有一定程度的提升,有实际应用价值。
尽管LDSNN 在多个数据集上的表现均优于主流算法,但当人脸图片带有遮挡或一定倾斜角度时,模型难以对其正确分类,这也是进一步的研究目标,实际应用中可以通过丰富训练数据等方法来提高模型的泛化能力。
