粗糙集属性依赖度强化的应急数据挖掘模型
2021-02-04高天宇王庆荣
高天宇,王庆荣,杨 磊
兰州交通大学 电子与信息工程学院,兰州730070
在大数据时代,数据挖掘作为一种有效的数据处理手段,能够帮助决策者从数据中发掘有助于决策的信息[1]。粗糙集理论不需要先验知识,作为处理模糊信息的有效方法,在挖掘数据中的隐藏信息时有明显优势,常用于数据预处理或数据分析[2-3]。属性约简作为粗糙集理论中的重点方法,通过依赖度计算来去除冗余属性[3]。Raza 等[4]通过直接计算属性依赖度进行属性约简,比较经典方法,其精确度得到了提高;针对不同情况的样本数据变化情况,Shu 等[5]通过增量式计算给出了相应的约简算法;关于粒计算理论在数据处理及粗糙集的使用中,Liang 等[6]引入高斯核函数粒化数据,提高了大数据集的处理效率;Qian等[7]分析了从多粒度层面考虑问题的属性约简的有效性;张天瑞等[8]基于粗糙集与决策树的数据挖掘方法,给出了关于全断面掘进机的一种故障检测新途径;刘颖超等[9]基于一种新的粗糙集属性约简理论,挖掘了影响刀具磨损的关键因素;邵为爽等[10]结合粗糙集与BP 神经网络,给出一种新的煤炭物流中心选址方法。
分析震后经济损失与其影响因素的相关程度是合理经济损失预测及分析的前提,有效的地震直接经济损失评估,对救灾、财政、捐助、理赔等有重要意义[11]。刘如山等[12]通过建筑类型、数量、空间分布、结构易损特性以及地震烈度计算地震经济损失;陈尧等[13]选取震级和烈度对直接经济损失进行了评估;王伟哲[11]理性分析地震的致灾因子和承灾因子,选取了地震震级、震源深度、设计基本加速度、灾区面积、全国人均GDP和受灾人口的乘积,作为神经网络的输入变量及预测经济损失的影响因素;赵士达等[14]通过理性分析选取了震级、震源深度、受灾面积、受灾人口、设计基本地震加速度、地区人均GDP和产业结构比例作为影响因素;和仕芳等[15]选取震级、烈度、人均GDP、人均财政收入、农民人均纯收入作为影响因素,并从时间特征总结出,经济和人口差异是地震灾害之间经济损失明显差异的重要影响因素,从数据中发现各影响因素与经济损失存在线性关系。
传统的地震经济损失分析中缺少对于相关影响因素的分析,影响因素的使用趋于主观选取,影响因素之间重要性研究较少。地震数据特点较复杂,挖掘影响因素的隐藏信息是分析影响因素间重要性的关键。基于粗糙集理论进行重要信息的挖掘较适合于地震数据分析,合理的数据分析将有助于预测、救援及经济市场的运作。属性约简作为粗糙集的核心[16],其约简原理主要依赖于条件属性对于决策属性的重要性的区别[2]。关于震后经济损失的相关数据,在传统的属性约简方法中,决策矩阵条件属性较多时,隐藏其中的低依赖度属性增多、属性值粒度较小,导致条件属性的重要性一致,造成约简困难。粒计算作为大数据分析的新方法,粒化准则的确定、分析数据的多粒度视角都有待进一步研究[3],常见的无监督离散化方法有等宽、等频、近似等频、密度、聚类等[17-18]。为解决约简困难给出一种依赖度强化方法,为将其合理化,结合多粒度粗糙集给出一种离散化方法。
给出一种数据挖掘模型,引入多粒度粗糙集,给出合理的粒化准则并从多角度分析数据。在数据挖掘模型中首先提出一种探索模型,确定粒化准则、探索粒度范围与属性组合范围。然后考虑粒度范围与离散量范围、粒化准则与离散量的关系,根据范围内不同的离散量离散化数据;考虑多种条件属性组合与决策属性的关系,在属性组合范围内全组合属性,计算组合的属性依赖度。最后强化属性依赖度,将不同属性之间的依赖程度从组合提取至属性本身。在本文搜集的国内5 级以上地震的数据中,成功挖掘了震后经济损失的重要、次要影响因素,且与传统方法相比更有效。
1 多个次要属性引起的属性约简困难
1.1 粗糙集属性依赖度
使用粗糙集处理信息时首先将处理的信息表示为一个四元组T={U,A,V,f}。其中,U={x1,x2,…,xn}为论域或对象集合,是全体样本的集合;A={A1,A2,…,Ac,Ad}为属性集合,其中包含条件属性C={A1,A2,…,Ac}、决策属性D={Ad},V代表了属性值的集合,V={a11,a12,…,and}。f代表一个信息函数,通过此函数来确定样本与属性所对应的属性值,即f(x,A)=V。条件属性等价类集合为条件类,决策属性等价类集合为决策类。
E为U中的一组等价关系,x∈U为条件类对象,X∈U为决策类对象,X关于E的上近似E*与下近似E*分别为:
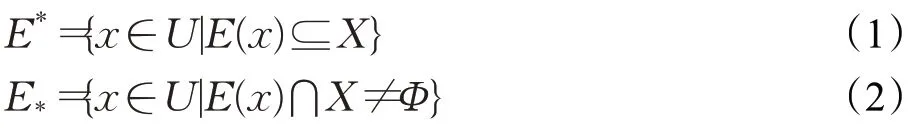
利用属性依赖度来定义决策属性与条件属性的关联程度,将依赖程度表示为以下表达式:

1.2 决策矩阵中隐藏多次要属性
根据粗糙集的四元组T={U,A,V,f},给出属性约简的决策表Td={U,A,C,D},属性集A中划分出条件属性集C与决策属性集D。判断某条件属性Ac∈C对于决策属性Ad∈D的依赖程度,计算Ac的剩余属性依赖度Ro(C,D|C-Ac),得到剩余属性依赖度集合R,当某属性对应剩余属性依赖度较低时,属性较重要,反之较次要。
在属性约简决策矩阵中,存在多个次要条件属性时,会导致属性值粒度过小,根据等价类的定义,此时易出现等价类过少,甚至没有等价类的情况。例如:某决策表中条件类为{{x1},{x2},…,{xn}},该类中无等价类,决策类为{{x1,x2,x3},{x4,…,xn}} ,选取{x1,x2,x3} 为决策集合,R中的值可能均为3n。过多的次要属性使得Ac的变化很难引起上近似集变化,若所有Ac对应剩余属性的依赖度均没有变化,则难以约简。
变精度粗糙集放宽对上下近似集的定义[19],模糊了粗糙集的边界,使得Ac的变化对于其剩余属性依赖度的影响更加敏感。
定义的变精度粗糙集上近似集为:
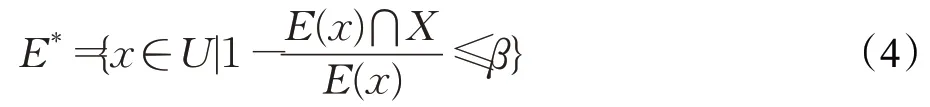
其中,β表示阈值时所求上近似集是严格的,当β=1 则会将所有的x纳入上近似集。所以β越小,最终的结果越有意义。
2 强化依赖度的分析方法
存在这样的情况,在引入变精度粗糙集的情况下,当β <1 时,β的任何变化不会引起上近似集的改变,其原因可能是多个依赖度过低的次要属性存在于决策表中。
由于属性依赖度对于各属性之间的依赖关系有重要意义[20],通过强化属性依赖度放大属性之间的依赖关系,挖掘次要属性。
强化属性依赖度过程如图1所示,计算不同的条件属性Ac之间的组合依赖度,再将属性组合的依赖度先从组合分离,后合并于每个属性,使得重要属性与次要属性分开,给出每个Ac关于Ad的依赖度,其中依赖度的强化主要体现在合并操作上。

图1 依赖度分离合并示意图
属性全组合方式为式(5),其中g表示组合的元素数,即对g个属性进行组合,记组合总数为m1,m2,…,mj,j为组合类型数。
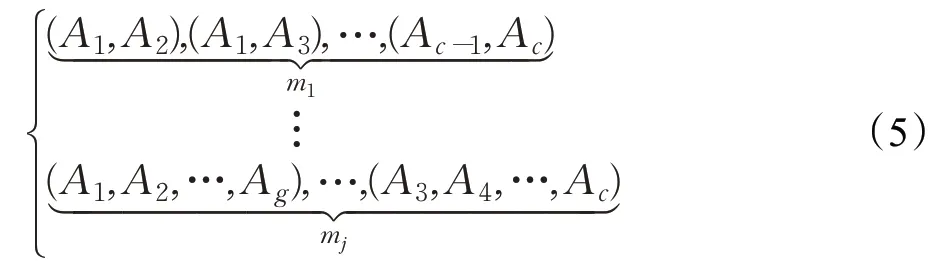
则可得对应的决策矩阵可为:

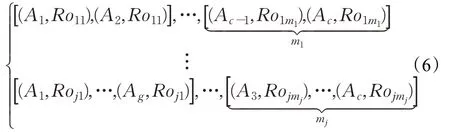
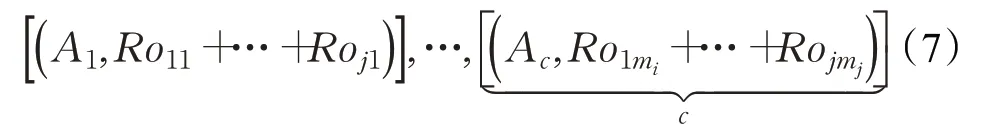
2.1 多粒度粗糙集与数据离散化方法
各属性组合进行计算较好地保留了属性之间的关系特点,但求解上近似集的过程中直接参与运算的是属性值,该模型数据的离散化对结果的影响很大,处理结果必须最大程度保留数据特点。强化属性依赖度过程中,考虑多个数据粒度可更大程度保留数据特点,粒计算是数据挖掘中的一个重点,相较于单粒度,多粒度视角的粗糙集对数据分析更全面、视角更广泛,通过融合多粒层的结果求得复杂问题的最终解[21-23]。
从不同粒度层面分析数据将更大程度地保留数据的特点,离散化数据时粒度与离散量成反比,若数据离散量越大,则粒度越小,反之越大。通过规定不同的离散量将数据离散化,待处理属性值其中δ为离散量,不同的离散量对应不同的粒度。
常见的离散化方法有等宽、聚类等[9],地震相关数据涉及面广,不同属性的数据特点不同,根据不同类型的数据使用不同离散化方法,针对本文数据给出判断公式,对量级差距大的数据进行动态的离散化。
根据离散量,处理不同类型数据的相对距离的流程如图2所示。
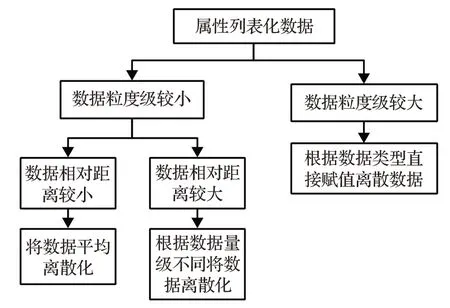
图2 对不同特点的数据进行离散化
数据粒度较大时数据本身已有归类与聚集,不做处理;数据粒度较小时,判断数据的相对距离后将数据离散化处理。为判断数据粒度大小,在2.2节给出探索模型。
根据式(8)判断数据的相对距离。

2.2 探索模型
在强化依赖度的数据挖掘模型中,属性全组合与不明确的粒度范围将增加方法的复杂度。为确定多个粒度的范围及每个粒度的粒化准则,去除无效的组合方式,提出一种离散量与属性组合探索模型,其中粒化准则确定了离散量,粒度范围为离散量范围。
确定待处理数据的结构,建立大量与其结构相同的随机矩阵,通过计算平均依赖度,观测依赖度变化与离散量及属性组合的关系。为使随机数处理更接近待测数据,建立模型的流程如图3所示。
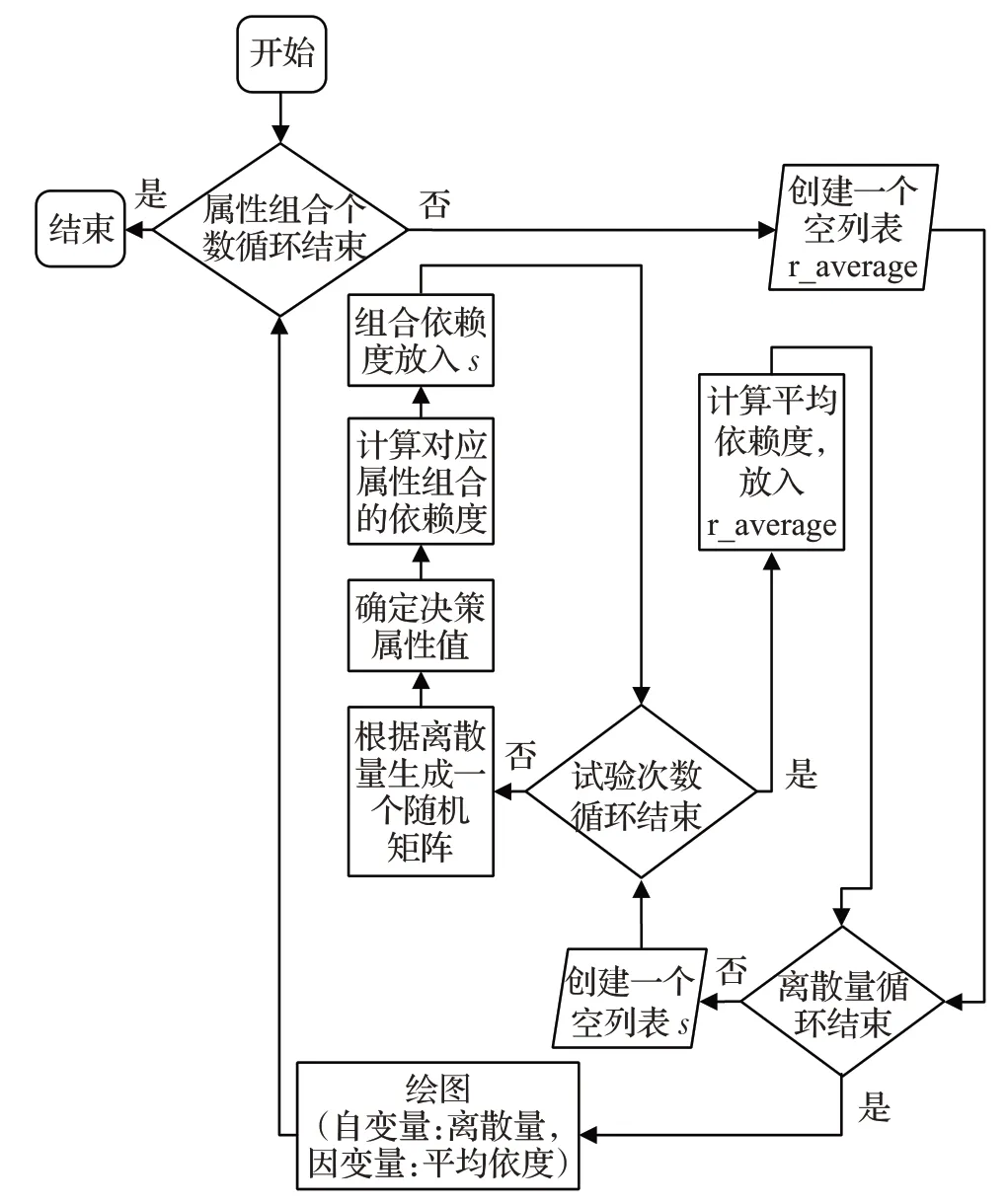
图3 探索模型程序流程
2.2.1 数据随机
在对随机矩阵的属性进行随机数赋值时,根据离散量δ产生随机数如式(9):

式(9)中,anc为属性值。此处数据随机的结果与待测数据的离散化形式一致,在一定程度上模拟了待测矩阵离散化后的数据结构。
2.2.2 属性组合随机
在使用待测数据进行计算时,各属性数据具有对应情景的数据特点,而探索模型中根据离散量产生的随机数据,数据特点一致,在测试属性组合数时不需考虑全组合情况,组合结果满足式(10):

对比依赖度分析方法中的全属性组合,合理的离散量范围与属性组合范围取决于决策矩阵本身的结构,而不是属性间的关系,因而此处组合结果更简单,且能达到探索模型的目的。
2.3 数据挖掘模型流程
融合上述方法为本文数据挖掘模型,如图4 所示,依赖度过低的属性过多,不易从决策矩阵中挖掘,提出依赖度强化方法。引入多粒度粗糙集对数据预处理,动态的离散化数据,从多个角度提取数据特征;使用探索模型给出离散量范围与属性组合范围,将数据预处理进一步合理化。
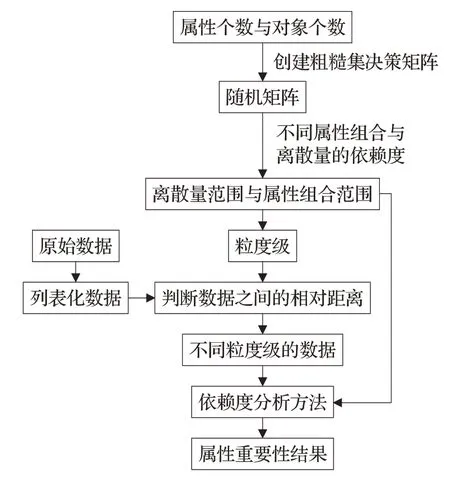
图4 数据挖掘模型
探索模型与多粒度视角处理数据均是为了提高依赖度分析方法的合理性。
3 实验和分析
3.1 数据集
选取国内18 次地震作为研究样本,用以验证该方法的合理性、实用性。通过对以往地震案例的研究归纳明确了在应急预案中的几个重要影响因素。
首先确定影响因素有:人口密度、当地气候类型、季节、时间、往年地震情况、地震等级、当地地形。往年地震情况为当地或者当地对应省、市近50年内震级5级以上的年均地震次数。将经济损失作为决策属性,其他影响因素作为条件属性,原始数据如表1。
3.2 对比实验改进的属性约简数据挖掘模型
3.2.1 探索离散量与属性组合范围
根据探索模型,确定实验数据中对象个数为18,条件属性为7,决策属性为1,在实验中给出最小的离散量为3。根据粒度与属性组合探索模型得出属性依赖度变化图,如图5所示。
图5 中曲线的自变量有两个,为粒度与属性组合。横坐标为自变量粒度,第一个粒度离散量为2,因实验发现粒度过大无意义,省去,从第二个粒度开始,实验中从第七个粒度开始依赖度随两个自变量的影响变小,自变量粒度选取第二至第七个,粒度Attribute granularity与离散量δ的关系:Attribute granularity=δ-1;各连续的曲线为自变量属性组合,实验选取全部属性组合。因变量为平均属性依赖度,即每个属性粒度对应不同属性组合所得平均属性依赖度,图5由500个随机8×18属性矩阵计算平均值得出。根据图5中5、6、7三种属性组合在本实验中明显聚集,区分能力较弱,首先去掉这三种组合,故均用实线表示。
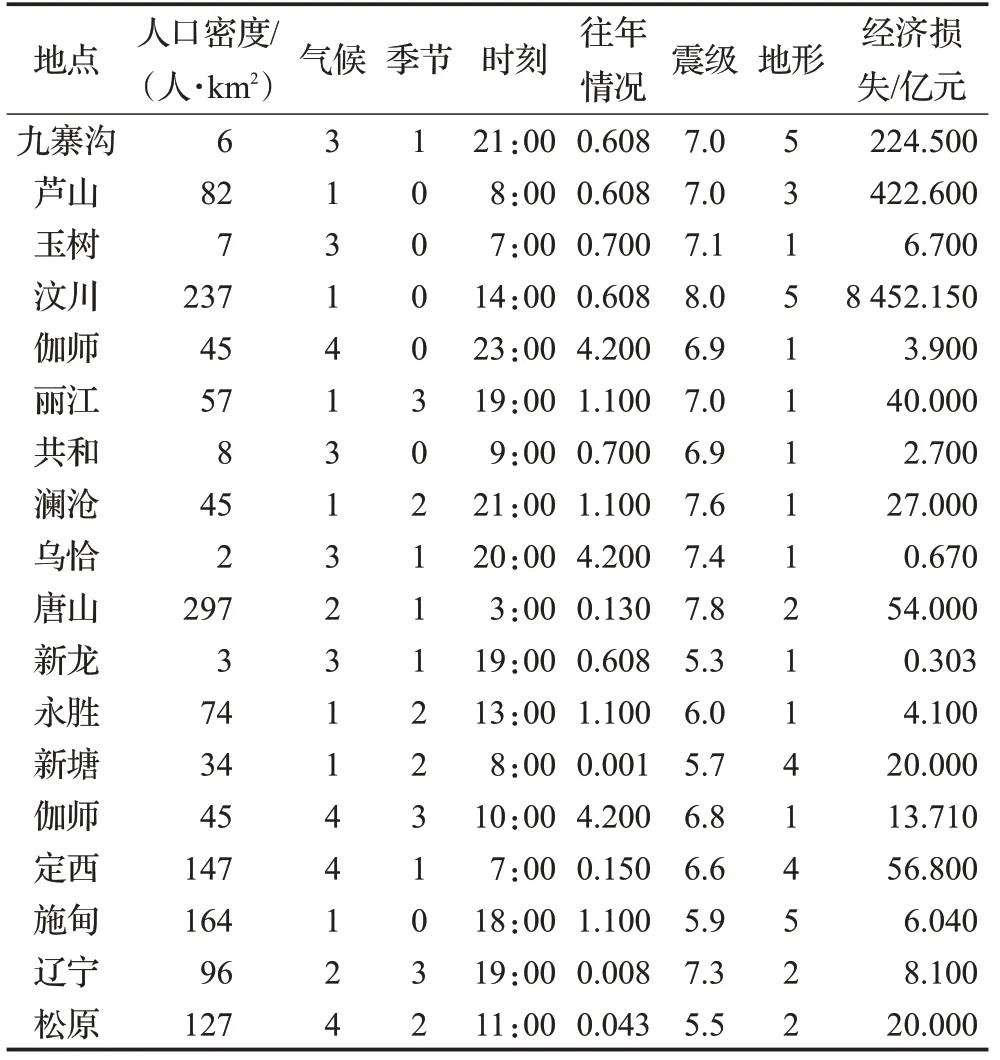
表1 地震经济损失及其影响因素
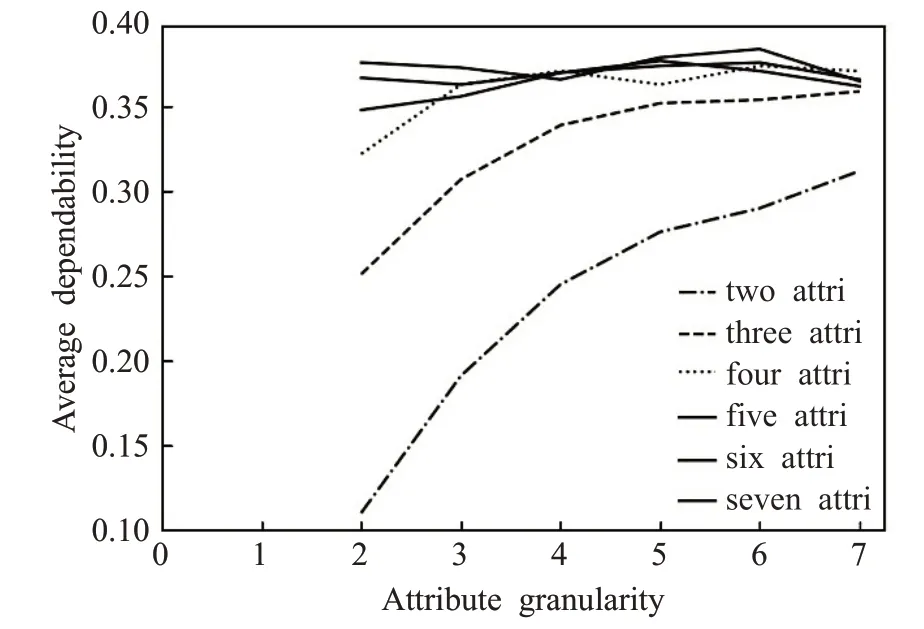
图5 依赖度随粒度与属性组合的变化
分析图5可知,当决策属性个数为1,条件属性个数为7,属性对象为18个时:在每个粒度层面,随属性组合个数的减少,属性依赖度差距变大,属性依赖度关于粒度变化的斜率变大。根据属性依赖度的差值与斜率挑选粒度与属性组合范围。选取差距较明显、斜率较大的情况,属性之间的依赖度差异较大,最有可能分离出重要属性与次重要属性。
3.2.2 数据处理
经济损失数据受年代影响较大,为消除这种经济发展变化造成的对比不均等现象,将经济损失与当年GDP的比值作为决策属性值。
挑选具有一定代表性的数据直方图,第一类数据如图6所示。
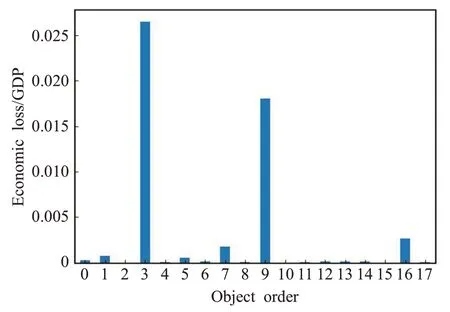
图6 决策属性的数据直方图
图6决策属性为经济损失与当年GDP的比值,自变量0 至17 代表18 个实验对象。此类数据为第一类数据,内部量级相差较大,且存在多个数据量级,根据本文离散化方法,需要采用不同的τ;第二类数据,如往年地震情况中有较明显的聚集情况,设置其τ为1.25,而经济损失的τ为2;第三类数据,如时间、地震等级,其数据内相对距离较均匀,将其平均离散化;第四类数据,如气候、地形,此类数据本身较为离散,它们之间关系较不明确,直接赋离散值。
取部分结果举例,离散量为3的数据处理结果如表2 所示。对应决策表定义,表2 中a1至a8表示属性,对象p1至p18表示震发地点。

表2 部分处理后数据
在传统聚类方法中,如图6中的数据离散将会分离3 号、9 号地区,动态离散化方法中,当离散量为3 时,3号、9 号地区将不会分离,符合二者同属于大型损失的情况。
3.3 实验结果
3.3.1 依赖度强化方法
决策属性a8的值0、1、2 分别对应大、中、小三种程度的经济损失。离散量为3、4、5,属性组合为2、3、4,决策属性值为0、1、2的属性组合依赖度结果如表3。

表3 属性在组合中的依赖度
经统计,表3共得出546个依赖度结果,包括针对三种决策属性的结果,每种结果包括三种粒度,将三种粒度的结果累加。
根据决策属性不同,合并依赖度结果如表4。
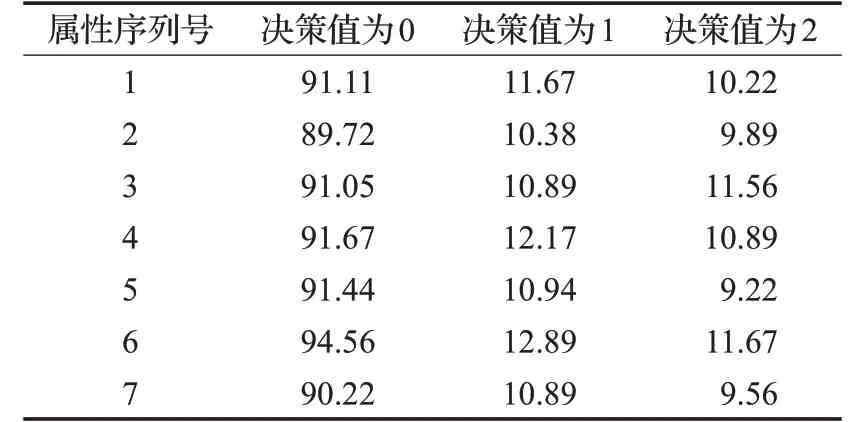
表4 每个属性的依赖度累加值
根据表4 属性依赖度结果大小将其对应属性序列号排序如表5。

表5 属性序列号从大到小排序
表5 中属性序列号依次对应7 个条件属性,条件属性对应到影响因素,属性重要程度排序如表6。从表6中可以得出,三种决策属性互为测试集,且三种排序结果较接近,体现出该模型的合理性。根据排序结果可看出,地震等级与时间在决策中较为重要,地形与气候较不重要。

表6 影响因素的重要度从高到低排序结果
3.3.2 传统属性约简方法
为证明本文方法的必要性,使用同样数据,通过传统的属性约简方法计算,结果如表7。
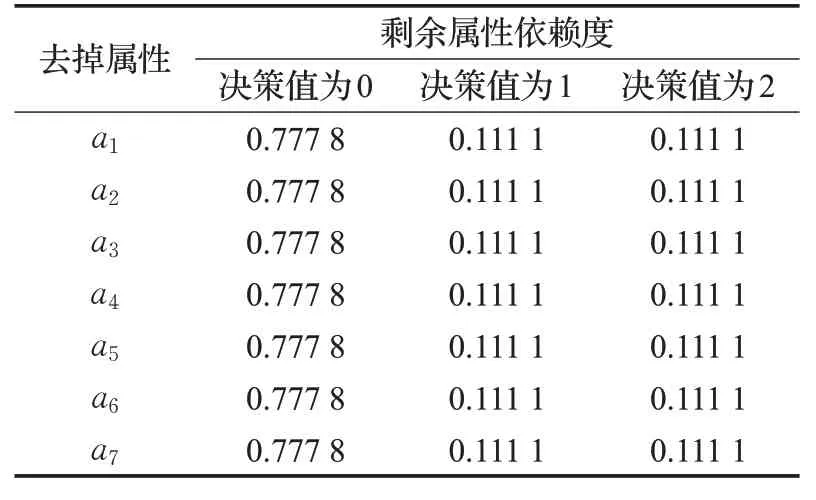
表7 传统属性约简依赖度结果
根据表7,每一列的依赖度结果均没有变化,根据变精度粗糙集理论进行计算,当β为0.9时结果仍不变,表示通过传统的属性约简无法挑出约简的删除对象。
3.3.3 测试数据结果
为证明本文方法的合理性,表8选取了50个较为传统的随机决策矩阵作为测试数据。
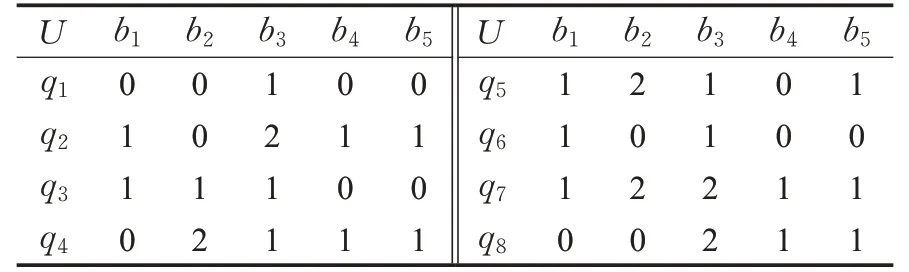
表8 测试数据1
该决策矩阵中有5个属性,8个对象q1~q8,离散量为3,决策属性b5,条件属性b1~b4。
首先使用本文方法,统计依赖度结果如表9。再使用传统属性约简方法,引入变精度粗糙集,取β为0.3(实验得:不使用变精度粗糙集时,存在两个属性的依赖度在约简过程中恒为0;且β取0.1、0.2均无变化),结果如表10。

表9 强化粗糙集属性依赖度的数据挖掘方法结果
根据表10 的属性约简结果可得,使用传统的粗糙集属性约简理论时,条件属性依赖度值的大小排名为:b2>b4>b3>b1。对比表9 的结果,则该测试数据中本文方法与传统方法的表现结果一致。
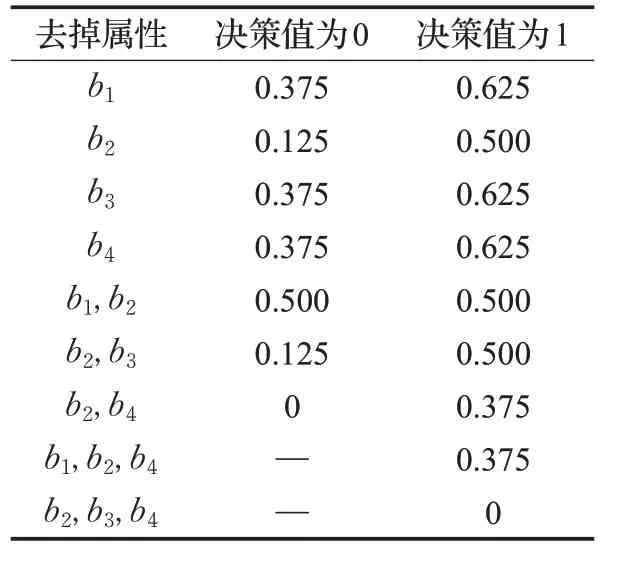
表10 传统属性约简结果
实验证明,两方法在50 个测试数据中有43 个表现结果一致,一致性为86%,故本文方法具有一定的合理性。
4 结束语
对于传统的属性约简方法中存在的过多低依赖度属性、过小粒度级导致的约简困难现象,本文以强化依赖度为主要思想,提出一种依赖度分析方法并构建了数据挖掘模型。在模型中,引入多粒度粗糙集,针对本文数据集给出了一种数据离散化方法,更大程度地保留了属性特点;构建探索模型,给出了一种粒度准则确定方法,合理缩小了属性组合范围与离散量范围,减少过量的计算;在选取决策属性时,从经济损失结果出发考虑了不同等级的经济损失程度。该模型综合考虑了不同属性组合的关系;从不同粒度层面分析了数据,成功挖掘出较重要属性与较次要属性。在实验数据中本文模型表现较好,在测试数据中本文模型与传统模型结果一致性较高,体现了本文数据挖掘模型的必要性与合理性。本文数据量较小,有待研究更多属性情况或其他领域下模型的合理性与鲁棒性,在更广泛领域的数据挖掘中有待进一步研究。
