面向智慧生物实验室的弱外观多目标轻量级跟踪网络
2021-02-04宗佳平陈建强张琳娜岑翼刚
宗佳平,吴 妍,陈建强,张琳娜,张 悦,岑翼刚
(1.北京交通大学信息科学研究所,北京100044;2.贵阳市公安司法鉴定中心,贵阳550025;3.贵州大学机械工程学院,贵阳550025)
引 言
随着信息技术的发展,视频处理也越来越智能化,比如无人超市、车辆检测等。由于视频场景纷繁复杂,几乎没有视频分析算法能够适应所有的应用场景[1]。例如在生化、生物实验室中,工作人员进行实验操作有规范的流程和步骤,对实验室中仪器的使用也有规定的顺序和使用时间。然而由于缺乏实时的跟踪手段,若工作人员疏忽未按规定流程进行仪器操作,则可能造成实验结果不准确。因此,利用监控摄像头实现对室内工作人员的轨迹跟踪成为智慧实验室建设中重要的内容之一,其可以实现对进入实验室内多个工作人员实时运动轨迹的跟踪,并获取各个工作人员在每台机器前停留的时间,以便对工作人员的操作规范进行追溯。然而,由于工作人员统一的着装,使得在基于视频的目标跟踪中外观特征弱化甚至缺失,为准确跟踪带来一定的困难,容易导致漏检及人员ID 分配错误(例如多人同时走动相互遮挡时)。因此,本文重点针对智慧实验室建设中基于固定监控摄像头的弱外观特征下多目标检测及前端实现进行研究,提出基于归一化层权重评价的层剪枝算法,并结合了检测结果校正的轻量级多目标跟踪网络,使整体的跟踪算法能更好地运用于摄像头前端实现,最后将本文算法在NVIDIA Jetson AGX Xavier 嵌入式开发板上实现,从而使得在实际应用中,通过智能摄像头边缘计算能力极大地减少视频图像传输、存储以及中心服务器的计算压力。
传统的运动目标检测方法主要是通过帧与帧之间图像信息的变化实现对目标的检测,常用的方法有帧差法、光流法和背景差法等[2],一般分为3 个阶段:先在给定的图像上选择一些候选的区域;再对这些区域进行特征提取;最后使用训练的分类器进行分类[3]。但是,这类方法所采用的手工设计的特征对于目标多样性的变化缺少很好的稳健性[3]。随着深度学习技术的快速发展,越来越多的基于深度学习的目标检测算法[4-9]被提出。这类算法主要分为两类:(1)双步目标检测算法,如R-CNN[10]系列,将检测分为两个阶段,先使用区域候选网络(Region proposal net,RPN)来提取候选目标信息,再利用检测网络完成对候选目标的位置及类别的预测和识别;(2)单步目标检测算法,如SSD[11]、YOLO 系列[12-13]等,采用了端到端的运算,利用神经网络直接生成目标的位置与类别信息,具有更快的检测速度。
传统的多目标跟踪算法从外观模型角度可以将其归类为生成式模型,Mei 等[14]首次将稀疏表示方法引入到视频目标跟踪领域中,其核心思想是将跟踪转化为求解L1范数最小化问题[15]。它没有利用背景信息,仅仅是对目标外观数据的内在分布进行刻画,但是在遇到遮挡时,容易因为错误更新将噪声混入模型,从而出现误差以及漂移[5]。另外一种则是判别式模型,利用在线学习或离线训练的检测器来区分前景目标和背景,从而得到前景目标的位置[16],比如相关滤波算法等。通过深度学习训练网络模型,其卷积特征的输出表达能力更强[17-19],如果将该特征直接应用到相关滤波等方法的跟踪框架中,可以获取更好的跟踪结果。Wojke 等[20]提出的算法使用类似于GoogLeNet 网络来提取128 维的特征,并使用cosine 距离来度量表观特征[21]。Wang 等[22]提出的跟踪模型则是将目标检测和外观嵌入共享结构学习,将外观嵌入模型合并到单步检测器中,同时输出检测结果和相应的跟踪结果,实现端到端的运算。
多目标跟踪的具体流程可以分为以下几个步骤:目标检测、特征提取/运动预测、数据关联以及分配ID。首先对每一帧图像中出现的目标进行检测,检测结果的好坏会直接影响跟踪器的性能。因此,本文采用YOLOv3 算法进行目标检测时,结合前一帧的跟踪结果对检测结果进行修正,确保检测器的准确性。同时,利用ShuffleNet 网络,结合特征向量间的余弦距离及检测框与跟踪框的重叠度(Intersection-over-union,IoU),采用匈牙利匹配算法进行多目标跟踪,具体如图1 所示。当视频帧输入该系统后,先对其进行目标检测,采用非极大值抑制(Non-maximum suppression,NMS)法获取目标检测结果,并根据该结果对目标进行裁剪。将裁剪完成的目标输入特征提取网络,获取其对应的特征向量,对其进行目标轨迹间的关联匹配,以获取最终的多目标跟踪结果。此外,通过结构化剪枝对YOLOv3 网络进行网络压缩,最后在NVIDIA Jetson AGX Xavier 嵌入式开发板上实现剪枝压缩后的深度学习网络,对本文提出的目标检测和跟踪方法进行验证实验。
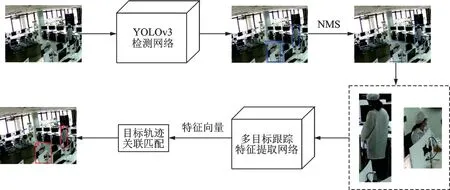
图1 系统框图Fig.1 System block diagram
1 目标检测
自YOLO 算法被提出以来,已经过3 个版本的更替,在精度和速度上均获得了巨大的提升,在Titan X 上检测速度可达到45 帧/s,是目前检测速度最快的目标检测算法之一[3]。然而,目前基于卷积神经网络(Convolutional neural network,CNN)的目标检测模型的训练与测试均依赖如Titan X 这样的台式GPU 计算平台,计算资源消耗大,难以向嵌入式平台移植,因此很难满足工业界对于目标检测实时性和便携性的需求[23-24]。因此本文提出了一种基于YOLOv3 的轻量型目标检测网络结构。在该结构中,对原有的特征提取部分的网络层数进行适度压缩。同时,为了弥补在单帧图片进行检测过程中由于置信度低而造成漏检的情况,利用前一帧的跟踪结果,对当前帧进行检测结果校正,确保当前帧目标检测的准确性。
1.1 YOLOv3 模型压缩
为了嵌入式平台上的目标检测网络能够达到实时性,需要设计轻量级的检测网络模型。因此,本文提出了一种基于归一化层权重评价层剪枝算法,实现对YOLOv3 现有的网络模型的剪枝压缩。
在剪枝压缩的过程中可以发现,模型的卷积核权重值的分布大部分处于0 的附近,如图2 所示。所以,本文先根据卷积核的权重来对网络进行通道剪裁,再根据网络结构中shortcut 层前面BN(Batch normalization)层的γ 权重进行层剪枝。通过图2 可以发现,卷积核的权重小于0.5 的占比较大,所以在进行模型剪枝时,设定网络裁剪率P,从卷积核权重中确定出其对应的数值,将其作为全局阈值T1,用来确定需要修剪的特征通道。此外,为了防止卷积层上的过度修剪并保持网络连接的完整性,需要确保每个卷积层中最大的一个卷积核权重大于全局阈值T1。如果出现某一个卷积层被裁剪掉,则保留其中权值最大的卷积核。
在YOLOv3 网络中,存在23 个shortcut 结构,为保证其结构的完整性,剪掉1 个shortcut 时会同时剪掉它前面的2 个卷积层。网络中的BN 层,即归一化层,其表达式为


图2 模型权重直方图Fig.2 Model weight histogram
在进行层剪枝时,先对γ 添加L1范数正则化进行稀疏化训练,再针对每一个shortcut 前的一个卷积层、BN 层及激活层进行评价。对各层的最高γ 值进行排序,取最小γ 值对应层进行层剪枝,从而进一步减少网络的深度,提高网络推理速度。具体的剪枝方法如表1 所示。

表1 模型剪枝算法Table 1 Model pruning algorithm
压缩之后,网络参数量及推理时间等如表2 所示。实验时,使用的数据集是从公开数据集中随机提取的只含有person 类别的图片,训练集有5 000 张,测试集1 300 张。表2 中,当压缩比例为50%时,仅对网络模型进行了通道裁剪,其网络参数量减少了57%,推理速度提升了近66%,网络精度相比原模型也略有提升。压缩比例为95%时,对网络模型进行了进一步的通道裁剪,同时也对网络层数进行了裁剪。此时,网络参数量减少了将近99%,推理速度提升了70%,而网络精度也仅仅只是降低了8.5%。因此,当该网络部署到嵌入式设备上时,在确保精度的前提下大大提高了物体检测速度。

表2 通道剪枝与层剪枝前后效果对比Table 2 Comparison of effects before and after channel pruning and layer pruning
1.2 基于前一帧跟踪结果的检测结果校正
在进行实验室内的目标检测时,室内的人员数量较少,不会出现人员拥挤的情况。但是一般情况下,室内成员大都处于近乎静止状态。同时,室内遮挡也比较严重,比如机器、风扇等。当人员出现同时运动时,也可能产生一定的遮挡,导致检测出的目标置信度比较低,从而出现漏检的情况,造成目标的跟踪失败。因此,为了尽可能降低目标漏检情况的发生概率,结合实验场景的特殊性,本文针对检测结果进行了校正,在对每一帧图像检测完成之后,利用前一帧的跟踪结果与当前帧的检测结果进行对比,判断是否出现了疑似漏检的情况。如果出现该情况,在确保漏检目标确实在监控可视区域的情况下,即目标未曾离开该监控区域,结合前一帧的跟踪结果,对当前检测结果进行修正更新,尽可能提高检测结果的准确性,以确保后面的跟踪算法性能。具体如表3 所示。

表3 检测结果更新算法Table 3 Detection result update algorithm
假设在前一帧检测跟踪过程中,出现了m 个目标,用T 表示,当前帧的检测结果有n 个目标,用D 表示,视频帧大小为w×h,用[x1,y1,x2,y2]表示帧中的某一个目标所处的位置,而(x1,y1)和(x2,y2)则分别代表了目标所处矩形区域的左上角坐标和右下角坐标。首先需确保跟踪目标理论上仍然处于室内,并未离开可视区域,防止后面进行数据更新时一直将其默认为处于室内而造成的误检情况。因此,当目标处于边缘位置,即x1<3 或w-x2<3,在进行检测校正时,若作为漏检目标,则需确认其作为漏检目标时连续漏检帧数t。如果连续5 帧处于漏检状况,即t ≥5 时,该目标标记为离开实验室,不再参与结果校正更新过程;反之在漏检的后5 帧中出现某一帧再次检测出目标,则将t 置0,重新开始计数。遍历前一帧所有跟踪结果,与当前帧的检测结果进行比较,计算结果差用dx 和dy 表示。由于是相邻帧的数据进行比较,无论目标运动速度快慢,两帧中的同一个目标坐标差别不大,并且考虑到室内人员不多,所以如果dx <10 同时dy <10,则说明该目标仍然处于室内,并成功检测;反之说明该目标在当前帧被漏检了。因此,当目标被标记为漏检时,利用该目标在前一帧中的跟踪结果修正当前帧的检测结果,进行下一步的跟踪运算。数据修正之后,检测效果如图3 所示。

图3 检测结果修正Fig.3 Correction of test results
图3 中所显示的图片是视频中的第110~113 帧,图3(a)中的4 幅图像是检测器检测出的实际结果,但是因为检测目标置信度低,出现了漏检的情况;图3(b)中的4 幅图片则是结合了跟踪器的跟踪结果,对漏检目标进行修正并补充检测框。从图3 可以看到,经过本文算法的修正,补充的目标框较为准确,确保了后续多目标跟踪的准确性。
2 目标跟踪
与单目标跟踪不同,多目标跟踪会存在新目标进入与旧目标消失的问题。在单目标跟踪中,一般会根据给定的初始框,在后续视频帧中对初始框内的物体进行位置预测。但是在进行多目标跟踪时不考虑初始框,而是采用数据关联的方法进行跟踪,即对每一帧进行目标检测,并利用检测结果进行特征提取,再选用余弦距离作为相似性度量方法进行数据关联,进而实现多目标跟踪。
2.1 特征提取
目前,图像特征的提取主要有两种方法:传统图像特征提取方法和深度学习方法。其中,传统的特征提取方法依赖于手工特征设计,常见的特征提取算子有Harris、SIFT 和HOG 等[25]。相对于传统方法,利用深度学习提取的特征表达能力更强。它是通过一个卷积神经网络对样本进行自动训练,从而获取区分图像的特征分类器。提取特征的好坏会影响轨迹与检测框之间的分配结果,因此为了得到比较好的判别效果,并保证跟踪的准确性与实时性,本文选用ShuffleNet[26]作为基础网络用于提取目标特征。
在实验过程中,根据第1 节所提的目标检测网络对每一帧图像进行人员检测,利用检测结果从每一帧图片中截取各目标区域,将其统一变成256 像素×128 像素大小的图片,作为ShuffleNet 网络的输入图像。同时,将该网络最后的全局池化层和全连接层,替换成自适应池化层,使得输出宽高为(8,4),维度为1 024 的张量,然后使用L2正则化,将提取出的特征向量投影在单位超球面上面。
在进行网络训练时,训练集采用行人重识别数据集Market1501[27],该数据集包含在不同视角和不同场景下拍摄的1 501 个不同的行人目标,总共32 000 张训练图片,其中训练集有751 人,包含12 936 张图像,采用批量输入的方式进行训练。为了更好地区分正负样本,采用triplet loss 损失函数,每次从训练样本中挑选难训练样本进行训练,使得正样本之间的特征向量距离尽量小,负样本之间的特征向量距离尽量大。
2.2 相似性度量
在进行多目标跟踪时,目标特征由2.1 节所使用的ShuffleNet 网络生成,由于余弦距离能够包含经过长时间遮挡后的特征信息,因此在进行相似度计算时,对于每个边界检测框dj,本文计算特征描述符rj并进行归一化处理。通过余弦距离,对当前的特征向量与之前匹配成功的特征向量集进行相似性度量,具体相似度计算公式为
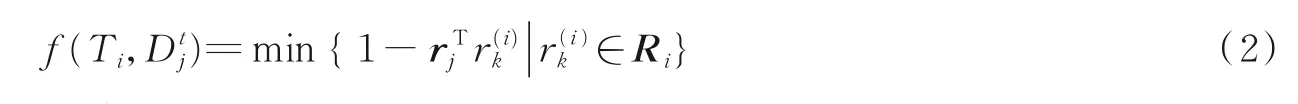
预测框与候选框之间的IoU 的计算函数为
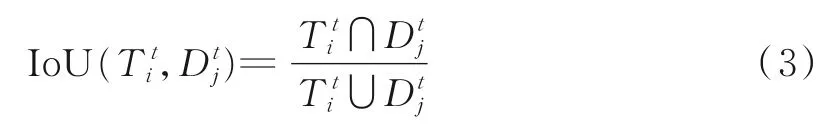
考虑到应用场景是实验室,室内人员较少,在处理候选框与预测框之间的关系时,优先使用目标特征对数据进行关联匹配。同时,为提高算法运行速度,针对先前成功匹配的目标与轨迹,采用IoU 运算对数据进行关联。具体的运算流程如图4 所示。
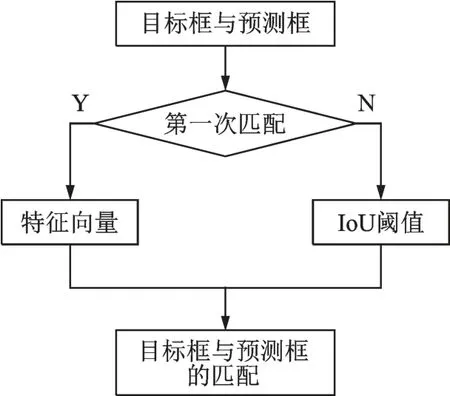
图4 数据关联流程Fig.4 Data association process
3 验证与分析
本文实验中使用联想笔记本电脑进行实验,操作系统为Ubuntu16.04,显卡是GTX1060,显存大小为6 GB。在该电脑上对网络进行训练完成后,再将其部署到嵌入式平台NVIDIA Jetson AGX Xavier上面,用于搭建实时多目标检测跟踪系统。其中,Xavier 采用的是8 核ARM v8.2 64 位CPU,GPU 采用的是NVIDIA Volta 架构,具有512 个NVIDIA CUDA(Compute unified device architecture)核心和64个Tensor 核心。
3.1 检测结果对比
在目标检测的实验中,本文从公开数据集COCO、VOC 中提取了含有person 类别的图片,并从中随机选取6 300 张图片作为本次实验的数据集,其中5 000 张作为训练集,1 300 张作为测试集。训练时,采用pytorch 框架,将训练集中的图片统一变为416 像素×416 像素大小输入检测网络进行训练。训练完成后,先对该模型进行通道剪枝,接着对其稀疏化训练并层剪枝,剪枝完成后对网络再一次训练。最后在装有Ubuntu16.04 操作系统的笔记本电脑上对网络模型进行测试,测试结果如表4 所示。
表4 中,第1、2 行分别是现有的压缩版YOLOv3 模型和原本的YOLOv3 模型,第3、4 行分别是利用本文1.1 节所述的剪枝方法对YOLOv3 进行50%和95%压缩后的结果。其中,F1-Score[28]为查准率与召回率的调和平均数,即

从表4 中可以发现,本文针对YOLOv3 网络进行50%压缩率裁剪之后,其网络精度相对原本的网络略有提升,同时推理时间也提高了33%。当压缩率达到95%时,网络大小、参数量及推理速度大大减少,网络精度、查准率及召回率略有降低,但是与YOLOv3-tiny 相比,参数量减少了87%,推理速度提升了2.6 ms,精度提升了约12%,F1-Score 也提升了约8%。与原本的YOLOv3 网络相比,本文方法在推理速度大大提升的同时,其精度只是略有降低。
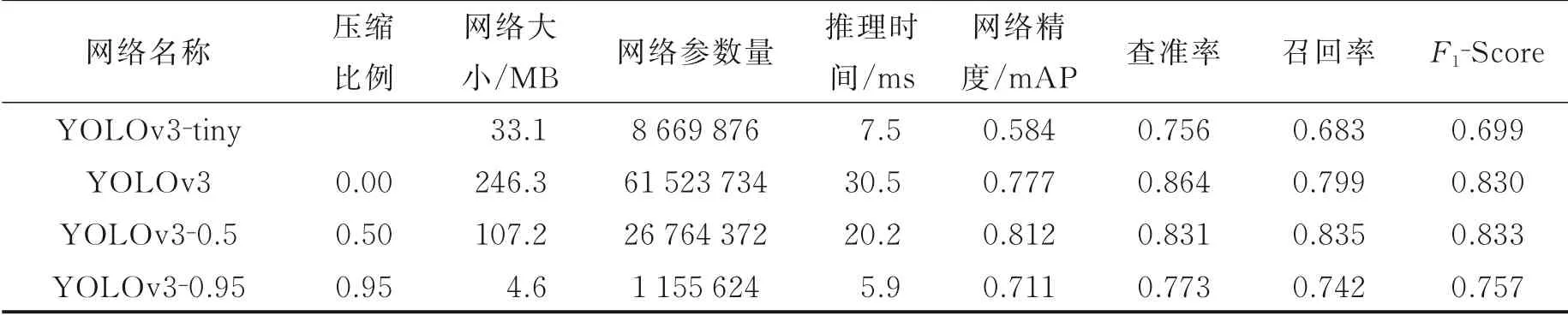
表4 目标检测网络裁剪前后效果对比Table 4 Comparison of effect of target detection network before and after cutting
3.2 跟踪结果对比
在多目标跟踪的实验中,对特征提取网络进行训练,训练集采用公开数据集Market1501,一共包含751 个类别。训练完成后,利用该网络提取检测到的目标特征进行多目标跟踪。在多目标跟踪算法测试的实验中,采用的数据集为2D MOT16,该数据集包含14 组视频序列,包含固定摄像头和移动摄像头两种拍摄方式。表5 是本文方法和现有的一些算法在数据集MOT16 上的实验结果,使用的是配有GTX1060 显卡的笔记本电脑,操作系统是Ubuntu16.04,在测试过程中所涉及到的相关对比算法,均是采用文献[21]提供的检测结果。表5 中MT(Mostly tracked)表示命中的轨迹占总轨迹的占比,ML(Mostly lost)表示丢失的轨迹占总轨迹的占比,FP(False positives)表示目标误检次数,FN(False negativate)表示目标丢失次数,IDs(ID switch)表示ID 改变的总次数,FM(Fragmentation)表示跟踪过程中轨迹中断次数,MOTA(Multiple object tracking accuracy)表示多目标跟踪准确度,MOTP(Multiple object tracking precision)表示多目标跟踪精度。

表5 多目标跟踪算法比较Table 5 Comparison of multi-target tracking algorithms
从表5 中发现,本文算法减少了ID 切换的次数,与Deep SORT[20]相比,IDs 从781 减少到614,减少了约14%,FN 减少了约32%;相比于EAMIT[26],FM 也降低至1 225。同时,本文提出的跟踪算法在装有GTX1060 显卡的笔记本电脑上的运行速度达到44 帧/s,达到实时性要求。
3.3 实时性对比
当网络训练完成之后,将多目标检测跟踪系统分别部署到上述带有GTX060 显卡的笔记本电脑和嵌入式设备Xavier 上进行测试。其中,输入的测试视频的分辨率为640 像素× 480 像素,帧率为24 帧/s,具体测试结果如表6 所示,其中Ubuntu 是指在笔记本电脑上的测试结果。从表6 中可以发现,本文对YOLOv3 网络进行压缩之后减少了模型占用空间,同时提升了模型推理速度。但是由于运行设备不同,在嵌入式设备上使用性能,其实时性能达到13 帧/s 左右。
在3.2 节中算法性能比较时,视频的检测结果已知,采用的均为文献[21]提供的检测结果,利用现有结果进行跟踪性能比较,所以其速度能够达到44 帧/s。在进行实时性对比过程中,本文采用的是在线跟踪,需要先获取每一帧的检测结果,再对这一帧进行跟踪。由于受到检测网络推理速度的影响,其速度目前最大只达到20 帧/s。
同时,该算法在作者自建的生物实验室数据集上进行了测试。在数据集中,目标均统一着装白大褂、白口罩及白帽子,具体的实验结果如表7 所示。表7 中的数据是采用表3 所描述的检测结果校正算法前后的对比结果。从表7 中可以看出,经过表3 算法的检测结果修正后,MOTA 能够保持在98%左右。具体的实验结果也可以从图5 中看出,其中:图5(a)两幅图像是视频中的第736、750 帧,目标5 进入测试区域并经过目标3 后,其各自的跟踪仍然保持不变;图5(b)两幅图片是视频中的第1 216、1 250帧,目标1 和3 互换位置,位置交换结束后其对应的跟踪结果仍然保持不变。
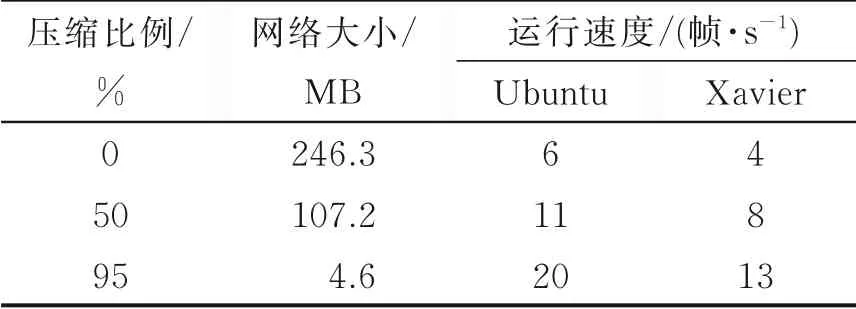
表6 嵌入式平台的模型性能对比Table 6 Model performance comparison of embedded platform
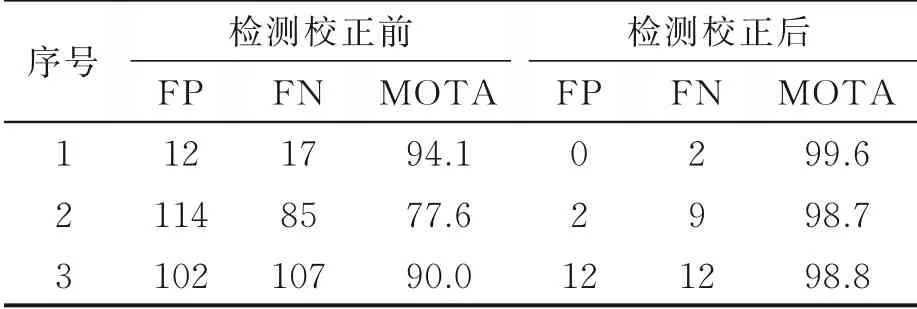
表7 检测结果校正前后算法性能对比Table 7 Comparison of algorithm performance before and after test results correction

图5 测试视频中的部分图像帧Fig.5 Some image frames in the test video
4 结束语
本文提出一种新的轻量级多目标跟踪算法,该算法通过对YOLOv3 网络模型进行剪枝压缩,在保证其检测精度的同时降低了模型占用空间,提升推理速度。再利用ShuffleNet 网络提取目标特征,结合了目标框与预测结果间的IOU 以及特征相似度,对结果进行数据关联。最后将多目标检测跟踪系统部署到嵌入式设备上。从实验结果可以发现,嵌入式设备上的模型推理速度相比于在GTX1060 上较慢,和网络剪枝之前的模型相比,速度虽提升3 倍,但还未达到实时性的要求。其中,网络运行时间大多是消耗在模块检测上,因此还需对检测网络进行进一步优化以达到实时性要求。
