基于改进Adaboost算法的SCR脱硝系统多模型集成建模
2021-02-03邢波涛赵文杰孙志英
乔 源,邢波涛,赵文杰,孙志英
(1.华北电力大学 控制与计算机工程学院,河北 保定 071003;2.华北电力大学 电气与电子工程学院,河北 保定 071003)
0 引 言
火电机组在实际运行过程中,常处于变负荷状态,造成SCR脱硝系统入口烟气参数波动频繁,导致了SCR脱硝系统的喷氨量控制难以取得满意的效果。建立准确的SCR脱硝系统模型是实施喷氨量有效控制的基础,对SCR脱硝系统的安全经济运行具有重要的意义。
鉴于SCR脱硝系统运行工况的复杂性,且SCR脱硝系统出口氮氧化物(NOx)浓度受较多变量的影响,其模型的建立方法成为人们研究的热点之一。单一模型的建模方法,如神经网络(Artificial Neural Networks,ANN)和SVM,在处理较大样本的多维数据时容易产生过拟合现象[1,2],文献[3]采用最小二乘支持向量机(Least Squares Support Vector Machines, LS-SVM)预测建模,通过反向传播(BP)神经网络进行变量选择,有效降低模型的复杂程度,但是单一的支持向量机建模不适用于大规模数据样本建模,面对多工况数据模型适应性较差[4];文献[5]提出了一种自适应多尺度核偏最小二乘方法,将多核学习方法与核偏最小二乘方法相结合,建立的系统动态模型具有更高的实时性,但对不同数据集测试发现模型面对复杂工况稳定性较差;文献[6]针对NOx排放量的预测,提出带有外部输入的线性和非线性自回归模型(GNARX),结果虽然有更好的准确性,但其模型结构复杂导致在测试集上表现不好,推广泛化性能差;文献[7]针对电站锅炉参数采用单一LS-SVM模型建立了预测模型,具有较好的准确性和泛化性,然而在工况发生变化时模型的预测精度有所下降。针对单一数学模型难以对复杂工况下的较大数据样本精确建模,国内外提出了多模型集成的方法来提高数学模型的预测准确度和泛化性能[8,9]。文献[10]采用更加复杂的模糊核聚类(Kernel Fuzzy C Means,KFCM)进行数据空间的划分,对分类后的数据集建立LS-SVM子模型,选择隶属度最大的子模型输出作为集成模型输出,结果表明集成模型比单一模型具有更好的性能;文献[11]利用Adaboost算法优化BP神经网络得到BP_Adaboost 模型,该模型具有较好的泛化性能但准确性有待提高。
本文结合Adaboost迭代算法,提出一种基于改进Adaboost算法的SCR脱硝系统多模型集成建模方法。首先,介绍了基于SVM的子模型建模算法和基于Adaboost算法的模型集成方法;然后,提出了对损失函数优化的Adaboost集成算法,算法中引入正则化因子和先验知识参数以提高模型的精确度,有效地降低模型复杂程度; 最后,以某电厂350 MW燃煤机组为研究对象,基于机组的实际运行数据,采用SVM子模型和改进Adaboost算法,建立SCR脱硝系统集成模型。结果表明,Adaboost算法可以自动调整运行数据的权重实现运行数据的分类,克服了样本数据不均导致建模精确度较低的问题,与单一模型和传统Adaboost模型相比,所建模型具有更高的预测精度,而且能够有效避免单一模型工况适应性差等问题。
1 SVM算法和Adaboost算法
1.1 SVM算法
支持向量机最初应用于数据的线性分类,具有泛化能力强、便于寻找全局最优等优点,且其训练时间较短适用于在线训练。将SVM由分类问题推广至回归问题可以得到支持向量回归(Support Vector Regression, SVR)[13,14],基于SVM回归算法建立SCR脱硝系统局部模型。
SVM中的超平面决策边界是SVR的回归模型:
g(X)=ωT·X+b0
(1)
对于回归模型,优化目标函数与分类模型相同:
(2)
回归模型的约束条件不同于分类模型,对于每一个训练样本上的点,需要尽量拟合在一个线性模型上:
yi=[(ω·Xn)+b]
(3)
在回归模型中,需要定义一个常量ε>0,对于某个样本点:
如果yi-[(ω·Xn)+b]<ε,则完全没有损失;
如果yi-[(ω·Xn)+b]>ε,则对应的损失为yi-[(ω·Xn)+b]-ε。
损失函数和均方误差不同,如果是均方误差,则只要yi-[(ω·Xn)+b]≠0 就会有损失。
与SVM分类模型一样,可以用拉格朗日函数将目标优化函数转化为无约束的形式:
L(ω,b,α∨,α∧,ε∨,ε∧,μ∨,μ∧)=
(4)
无约束的优化函数分别对ω,b,εi求取极小值,并消去ω,b,εi可得
C-α∨-μ∨=0
(5)
C-α∧-μ∧
(6)
将式(5)、(6)代入式(4)并取极小值,得到极小值得目标函数:
(7)
只要求出对应的αi,就可以求出回归模型系数ω,b。
1.2 Adaboost算法
Adaboost算法即具有自适应能力的Boosting算法,是基于Boosting算法的一种实现方法。Adaboost算法最早是应用于二分类问题的一种集成算法,由于弱分类器的分类性能较差,因此通过弱分类器的组合构造强分类器,使之具有较好的分类性能[15,16]。
在AdaBoost算法中,每个训练样本在学习弱学习器时都会使用一个权重。这个权重代表每个样本的相对重要性,并用于计算数据集上假设的误差。每次迭代后,对样本进行权重调整,未正确分类的样本将获得较大的权重。因此,随着建模过程的推进,学习的重点是最难分类的样本。Adaboost算法在训练过程中动态调整样本的权重值,最终得到的弱分类器也带有权重,因此通过Adaboost算法集成的强分类器具有较好的分类性能[17]。同样的,Adaboost集成算法可以应用于数据拟合,其主要思想是整合多个弱学习器得到强学习器的输出以做出准确预测。Adaboost集成算法在训练过程中对样本进行权重调整,拟合误差较大的样本将增大对应的权重值。弱学习器通过反复迭代运算得到关于预测值的函数序列,每个预测函数赋予一个权重,预测结果越好的函数,其对应权重越大[12]。多次迭代之后,最终强学习器由弱学习器函数加权得到。多模型Adaboost集成算法的运行流程如图1所示。

图1 Adaboost算法流程
Adaboost算法是一种前向分步学习算法,损失函数是指数函数:
(8)
算法模型是加法模型,最终强学习器的输出是由弱学习器最终加权相加得到,其加法模型:
(9)
Adaboost算法具体流程如下:
(1)输入弱学习器个数K,弱学习器算法,样本集:T={(x1,y1),(x2,y2),…,(xm,ym)};
(2)初始化样本权重:
D1=(ω11,ω12,…ω1m)
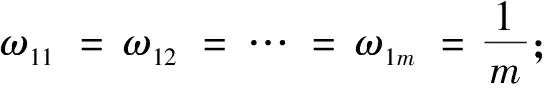
(3)循环,对k=1,2,…K,依次训练每个弱学习器:
(a)样本集权重化:Tk=T*Dk
(b)Tk作为训练集训练弱学习器;
(c)计算弱学习器输出对训练集样本的最大误差:
Ek=max|yi-Gk(xi)|
i=1…m
(d)计算每个训练样本的相对误差:
(e)计算训练集的误差率:
(f)更新弱分类器权重值:
(g)更新样本权重值:
(4)构建强学习器:
2 Adaboost算法的改进
当标准Adaboost算法应用于分类问题中时,通过训练多个弱分类器对待分类样本进行分类,并投票决定样本类别,利用弱分类器之间的互补性提高强分类器的分类精度,相比于单个分类器,在一定程度上提高了分类准确率;当标准Adaboost算法应用于回归问题中时,无法通过投票进行样本类别表决,而是采用弱学习器的输出进行函数加权相加得到最终的强学习器,但是这种强学习器集成方法也带来了一些缺点,不符合模型本身的机理意义导致集成算法精确度下降。
在面对复杂的数据时,强学习器有很好的表现。但是用比较复杂的模型作为子模型建模算法比如神经网络、支持向量机等,拟合数据的过程中容易出现过拟合现象,导致强学习器在训练集上表现很好,在测试集上精度较低,模型的泛化能力下降,因此在集成模型过程中通过正则化方法即加入正则化因子,以降低模型的复杂度从而使得模型精度上升;同时,由于SCR脱硝系统是火电机组运行系统的一部分,其数据样本具有明显的不均匀性,每一个子模型对应的数据样本可能存在明显差异导致建模效果较差,在子模型建立过程中根据经验分别加入先验知识以提升单个子模型的精度,从而使得集成模型更加准确。
因此本文提出一种基于对损失函数进行优化的Adaboost回归算法,引入正则化因子和先验知识参数,在回归问题上有良好的拟合效果。
Adaboost算法加法模型:
(10)
第k-1个强学习器:
(11)
式(10)、(11)相减:
fk(x)=fk-1(x)+αk*Gk(x)
(12)
(13)
由式(13)可知,exp(-yjαk*Gk(x))包含αk,Gk(x),是影响损失函数最小化的唯一因素。为解决Adaboost算法中强学习器存在过拟合的问题,本文加入正则化因子ν和先验知识参数λ,即
exp(-yjαk*Gk(x)*ν+λ)
(14)
其中,0<ν<1;
在损失函数中加入正则化因子后,强制让模型的参数值尽可能的小使得模型更加简单,同时对损失函数由一定的约束引导作用,在优化误差函数的时候倾向于选择满足约束的梯度减少的方向,使最终的解倾向于符合先验知识;先验知识参数的加入,使得损失函数更具有机理意义,弱学习器的权重更加简单化。
改进损失函数后得加法模型:
(15)
3 基于改进Adaboost算法的SCR脱硝系统建模
3.1 SCR脱硝系统
火力发电的过程中,燃料燃烧释放热能并产生烟气,烟气中包含有氮氧化物(NOx)、二氧化硫、飞灰含碳等污染物。其中氮氧化物(NOx)直接排放进入大气会引发空气细粒子污染和雾霾。针对这一问题,SCR脱硝系统被广泛应用于燃煤机组烟气NOx脱除过程中。SCR即选择性催化还原法,在催化剂的催化作用下还原剂(NH3)选择性地与NOx发生反应生成水(H2O)和氮气(N2)。
本文以某电厂600 MW燃煤机组为例,SCR脱硝装置采用高尘布置方式,反应器布置在锅炉省煤器和空预器之间,反应器内设“2+1”层催化剂(2层初装层+1层备用层)。SCR脱硝系统工艺流程如图2所示,来自供氨站的氨气与来自送风机的空气混合稀释均匀后,通过喷氨调节阀与烟气混合均匀进入脱硝反应器中。反应器位于省煤器和空气预热器中间,其中布置有多层催化剂,当氨气与烟气的混合气体进入反应器中并在指定温度下进行反应从而达到氮氧化物脱除的目的。

图2 SCR脱硝系统反应机理
影响脱硝效率的因素较为复杂,主要包括SCR入口NOx浓度、氨气流量、氧气含量、反应温度等。此外,发电机功率、总风量、总煤量也对氮氧化物的脱除效率有间接影响。
3.2 建模数据准备
根据SCR反应机理选取SCR反应器入口NOx浓度(NOx_IN)、氨气供应流量(NH3_Flow)、氨气流量调节阀位反(VNH3)、SCR入口烟气O2含量(O2)、脱硝反应器入口烟气温度(Temp)、发电机功率(Load)、总风量(Wind)、总煤量(Coal)8个变量作为原始输入变量,脱硝反应器出口烟气NOx含量作为输出变量(NOx_Out)。本文选取某机组一天中的部分运行数据,采样周期为1 s,共计12 000 组数据(xi,yi)(i=1,2,…,12 000),其中xi是模型的输入,yi表示出口NOx浓度。样本数据被随机分为训练集和测试集,分别包含10 000组训练数据和2 000组测试数据。数据集包含该机组不同工况下的运行数据,具体数据如表1所示。

表1 SCR脱硝系统运行数据
3.3 模型输入变量选择
互信息是信息论中的一个基本概念,通常用于描述两个系统间的统计相关性,或者是一个系统中所包含另一个系统中信息的多少[18]。对系统模型建立所选取的数据进行综合分析之后,确定模型中所包含的每一种影响因素所占的信息量多少,从原始特征集中选取包含所有特征蕴含的全部或绝大部分信息的特征子集。SCR脱硝系统是一个复杂的过程,影响出口NOx浓度的因素有很多。许多变量都会影响出口NOx浓度,且这些变量之间存在着较强的相关性和时延性。可以采用互信息的方法进行数据特征量的提取,分别找到SCR脱硝系统模型中各影响因素的权重。
原始变量中每个变量相对出口NOx浓度yi均存在不同程度的时延,所以对每个变量Xi(t)进行相空间重构,重构加入时延的候选变量为:Xi=[Xi(t),Xi(t-1),…,Xi(t-15)]。根据经验,初选纯迟延时间范围为0~150 s,采样时间为10 s,故τ∈[0,15]。计算在不同时延条件下,各候选输入变量与输出变量之间的标准互信息:分别计算Xi中15个时延变量与输出变量yi标准互信息值,对15个时延变量对应的互信息值进行比较并选取最大的互信息值对应的时延变量,该时延变量是具有较多信息量的特征子集之一,每个时间序列所对应的时延,即为该变量的纯迟延时间。依次对所有8个输入变量进行互信息选择。
通过互信息法分别计算离散变量输入变量、输出变量的系统熵、两个系统的联合熵、两个系统的条件熵,通过熵值计算两个输入系统最终的互信息值。表2为4个影响因素较大的互信息值。

表2 互信息值
由表2选取互信息值较大的变量,相关变量筛选之后共有4个,分别为:总风量,脱硝反应器入口NOx浓度,氨气流量,入口烟气温度。
表3为加入时延的候选变量分别与输出变量计算标准互信息值最大的时间序列所对应的时延时间。

表3 变量时延
故加入时延时间的模型输入变量为:总风量X1(t-13),脱硝反应器入口NOx浓度X2(t-2),氨气流量X3(t-7),入口烟气温度X4(t-4);输出变量为:反应器出口NOx浓度Y(t)。
3.4 模型建立
通过互信息对加入时延时间得原始变量进行选择,并将前一时刻的模型预估出口NOx浓度也作为模型输入。因此,模型输入变量为:总风量X1(t-13),脱硝反应器入口NOx浓度X2(t-2),氨气流量X3(t-7),入口烟气温度X4(t-4)和前一时刻的模型预估出口NOx浓度Y(t-1)。根据模型输入变量和输出变量进行模型建立,得到模型结构如图3所示。

图3 Adaboost_SVM模型结构图
取试验数据的前10 000组作为训练数据,后2 000组作为测试数据,利用支持向量机作为子模型对训练集数据进行训练,每一个子模型训练完成后,将训练样本按集成算法进行权重更新,放至下一个子模型中进行NOx预测,并在迭代计算中得出各个子模型的权值。最终通过改进的Adaboost集成算法对建立的各个支持向量机子模型进行集成得到SCR脱硝系统集成模型。
精度指标为了衡量模型的训练和测试效果,使用控制理论中具有代表性的平均绝对误差(MAE)和均方根误差(RMSE)作为评价指标。如式(16)、(17)所示:
(16)
(17)

模型训练结果如图4、图5所示。图4为基于改进Adaboost集成算法模型训练完成后,利用训练集作为测试数据,对训练集进行NOx预测,用于验证模型的学习能力。可以看出,集成算法模型预测值和真实值基本保持一致,且当SCR脱硝系统出口NOx浓度随时间变化时,模型预测值可以完全跟踪其变化趋势,证明改进Adaboost集成算法模型对原始训练数据具有良好的学习能力。
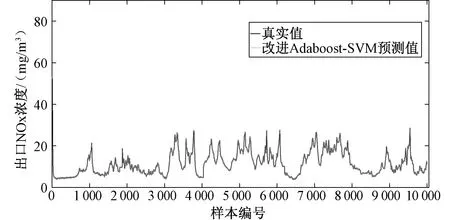
图4 Adaboost-SVM模型训练结果
图5为使用测试集数据测试模型的预测结果,验证模型的泛化能力。相对于训练集测试效果而言,测试集结果相对真实值有略微浮动,但预测精度总体较高。当SCR脱硝系统出口NOx浓度随着时间变化时,模型预测结果与真实值趋势基本相同。
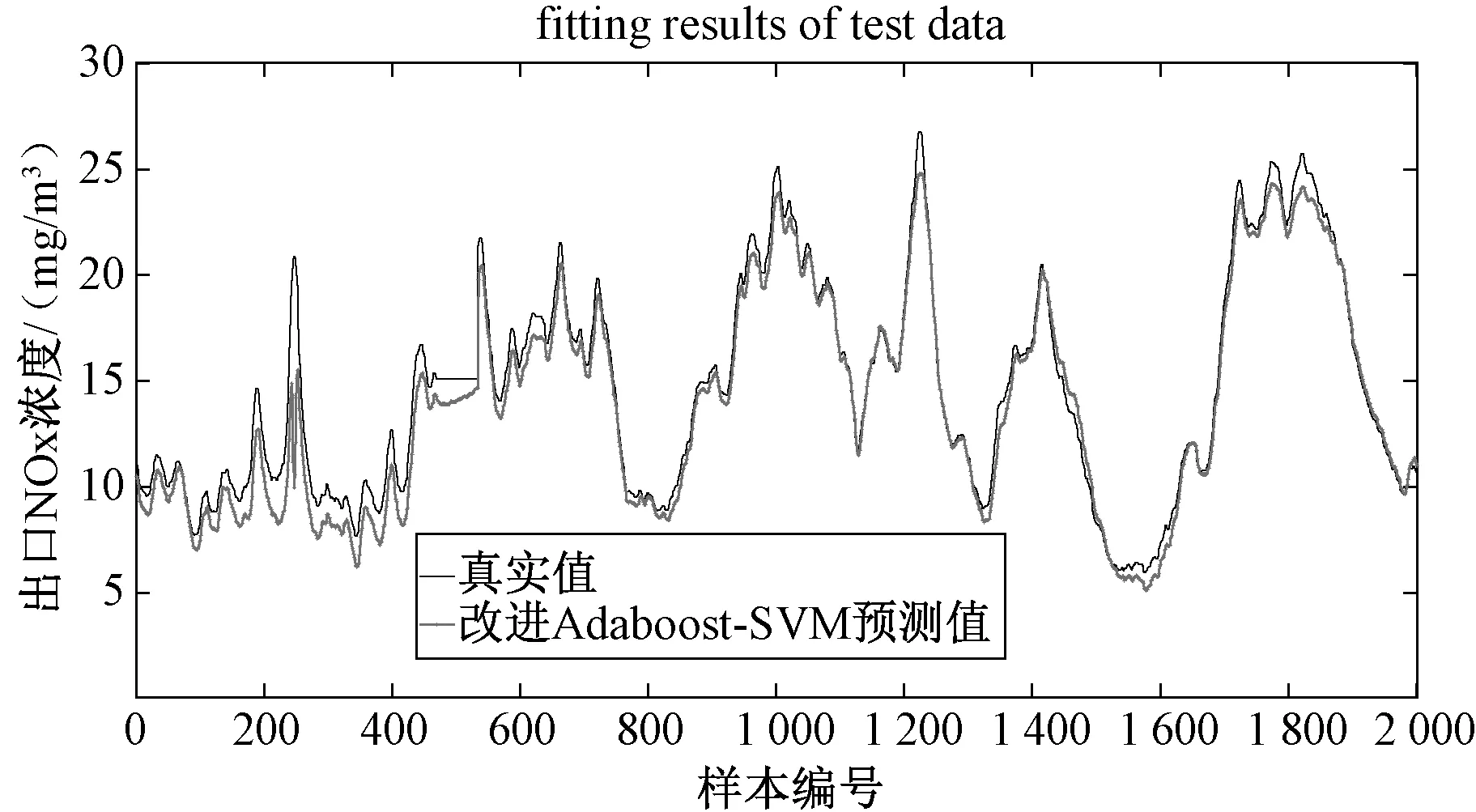
图5 Adaboost-SVM模型测试结果
为了更好的对预测效果进行对比,对单一支持向量机模型(SVM),标准Adaboost算法集成模型和改进Adaboost算法集成模型进行对比实验。选取数据集前10 000组作为训练数据,后2 000组作为测试数据。分别对不同算法进行训练得到其对应的模型,测试数据训练结果如图6。

图6 三种模型测试结果
图6表明改进的Adaboost算法集成模型精度较高,能更好的预测SCR脱硝系统出口NOx值,而标准的Adaboost算法集成模型和改进后的模型预测效果相近,稍次于改进的Adaboost算法集成模型训练结果,单一支持向量机模型则仅仅预测出了NOx变化的趋势,精度较差而且有着较大的滞后延迟。
分别对三种方法的测试集误差进行计算并绘图,可以看出集成模型的测试误差(图7)在0附近波动范围较小,集成模型预测结果准确;标准Adaboost算法集成模型测试误差略大于改进Adaboost算法集成模型测试误差;单一支持向量机模型(图7)误差波动范围较大,表示该模型的预测结果较差。

图7 Adaboost-SVM模型测试误差
三种SCR脱硝系统NOx排放预测模型精度指标对比如表4。

表4 不同模型预测精度对比
对比各项精度指标,改进Adaboost算法集成模型具有更准确的预测精度,而标准Adaboost算法集成模型由于其具有多个模型集成的优点,能够对SCR出口NOx的趋势变化进行预测,其精度仅次于改进的Adaboost算法集成模型;但单一模型精度则较低,主要由于网络简单,难以寻得全局最优值。
4 结 论
基于损失函数优化的Adaboost算法应用于SCR脱硝系统建模,能够自适应的确定样本集的权值并建立相应的集成模型,对不同的SCR脱硝系统具有较好的泛化能力。相对于传统的单一支持向量机模型,改进Adaboost算法针对数据分布不均的问题对较少工况的数据加大权重,使学习器更加关注难以拟合的样本以提高模型精度;与标准Adaboost算法相比,基于损失函数改进了集成算法的加法模型,建立了更高精度的SCR脱硝系统模型,表明基于损失函数优化的集成策略适用于复杂的多工况系统建模。
