子句级别的自注意力机制的情感原因抽取模型
2021-02-02覃俊孟凯刘晶廖立婷毛养勤
覃俊,孟凯,刘晶,廖立婷,毛养勤
(中南民族大学 计算机科学学院&湖北省制造企业智能管理工程技术研究中心,武汉 430074)
文本情感分析一直是自然语言处理和文本挖掘领域研究的热点问题之一,因其广泛的应用前景而受到学术界和工业界的重视.文本情感分析领域中,情感分类[1]任务的目的在于确认文本所表达的情感,情感要素抽取[2]的目的在于分析文本所表达的情绪,而基于方面的情感分析[3]则旨在分析针对事物的某个方面所表达的情感.近年来,情感原因抽取也成为情感分析领域的一项重要子任务,其旨在识别在给定文本中某种情绪表达背后的潜在原因.有效识别情感产生的原因,能更好地帮助服务提供者改善并提高服务质量,提升用户体验.在公共安全领域,如舆情监控和政府决策层面,对情感原因的探究有助于更好地理解公众意见的形成的原因.因此,关于情感原因提取的研究近年来受到越来越多的关注.
早期的研究主要采用构建规则的方法从文本中抽取情感对应的原因[4-5],这些方法将情感原因抽取看作词级别的序列标注任务,其性能依赖于标注数据集的大小,而且移植性较差.一些研究[6-7]表明,考虑文档中子句级别的信息可以提高情感分析任务尤其是情感原因抽取任务的性能.近几年,在该任务上的研究取得了一定的成果[8-12].
图1展示了子句级的情感原因抽取的基准数据集[13]中的一个例子.被标注了“激动”的情感标签的文档中包含了8个子句,其中子句C3描述了该情感,被标注为“激动”情感子句.子句C2是情感子句C3产生的原因,被标注为C3的原因子句.因此,子句级的情感原因抽取任务可以看作一个子句分类问题.根据给定的情感标注,判断文档中的每个子句是否包含该情感的原因,从而确定该情感的原因子句.该数据集已经成为了情感原因抽取任务的一个基准数据集.基于该数据集,在深度学习和传统机器学习[13-14]上都有了许多的研究工作.

图1 例子:情感原因抽取Fig.1 Example:Emotion cause extraction
随着深度学习的发展,长短期记忆网络和注意力机制被广泛的应用于情感原因抽取任务.文献[8]提出了带有上下文感知的联合注意力神经网络进行情感原因抽取.文献[10]考虑了整个文档对情感原因子句的作用,利用多注意力机制从多个视角抽取文档特征从而加大对原因子句的关注.文献[15]基于双向长短期记忆网络,设计了一种联合注意力机制来捕捉每个候选原因子句和情感子句之间的相互作用.上述方法主要关注了情感原因子句中文档的上下文信息,忽略了情感描述子句和情感原因子句之间的语义关系.另一方面,由于数据集中标签不平衡,普通的子句远多于原因子句,使得寻找情感描述子句与情感原因子句的之间的语义关系十分困难.
因此,本文综合考虑了情感原因子句和情感描述子句之间的语义关系、情感原因子句和情感描述子句的位置关系,以及情感原因子句的上下文信息.提出了一个基于子句的自注意力多特征融合神经网络模型(SANN),本文主要贡献如下:
(1)融合了情感原因子句的上下文信息、情感原因子句和情感描述子句之间的语义关系以及情感原因子句和情感描述子句的位置关系特征.
(2)利用自注意力机制,融合位置关系特征,计算情感描述子句和情感原因子句之间的语义信息.
(3)基于文献[13]提出的当前最大子句级的中文情感原因抽取任务的数据集评估了我们的方法,实验结果表明,该模型在查全率R上优于目前的其他方法.
1 相关工作
早期研究将情感原因抽取任务定义为词级别的序列标签问题,提出了基于规则或机器学习的方法[7,16-17].例如SOPHIA[4]等基于语言学规则,最早针对新闻文本中的情绪表达抽取其对应的原因,同时提出了评测规范.文献[18]基于人工规则特征,使用支持向量机(Support Vector Machine,SVM)等传统机器学习方法去抽取情感原因.文献[5]将认知学中的模型引入情感原因发现,设计了新的抽取规则.一些研究方法[17]从其他领域导入先验知识和理论来推断并提取情感的原因.这些方法均基于有注释的数据集构建语言规则.在小数据集上能取得较好的效果,但随着数据集的增大,规则集的构建周期也会变长,而且移植性较差.
文献[8]指出,围绕情感关键词的上下文描述了情绪引起的线索.因此,由情感词以及与它相关的上下文组成的情感子句应作为一个整体进行查询.文献[6]证明了子句级别的特征可以提高情感分析任务的性能.因此,情感抽取的研究开始考虑文档中子句级别的信息,构建基于句级别语义的情感原因抽取模型.已有的研究工作[7,11,13,19]表明,从子句级别去考虑表达的情感和原因之间的关系,能够明显提高情感原因的抽取效率,基于Transformer[20]的模型[9]取得了较好的效果.
文档中不同内容的子句对特定情感有着不同的作用,文献[15]基于双向长短期记忆网络,考虑了情感原因子句和情感描述子句相互作用,设计了一种联合注意力机制来捕捉每个候选原因子句和情感子句之间的相互作用.文献[8]提出了一个带有上下文感知的联合注意力神经网络.利用联合注意力机制寻找情感描述子句和情感原因子句之间的关系,最后使用卷积神经网络对添加了联合注意力的子句进行分类.文献[10]考虑了整个文档对情感原因子句的作用,使用注意力机制对文档建模,从多个视角抽取文档特征从而加大对原因子句的关注.文献[21]基于中文微博多用户的特点,构建了一个多用户的中文情感原因数据集,发现了不同博客之间的情感原因关联,并使用SVM和长短期记忆网络(Long Short-Term Memory,LSTM)等方法去探测多用户的情感原因关联.文献[13]基于新浪城市新闻构建了中文情感原因数据集.该数据集针对的是基于子句级的情感原因抽取任务,目标是对给定的情感描述的注释,确认该情感的原因子句.这个数据集已经成为了情感原因抽取任务的一个基准数据集.
之前的研究工作主要忽略了情感原因子句和情感描述子句的语义关联.因此,本文综合考虑了情感描述子句和情感原因子句之间的语义关系以及原因子句自身的特点,利用自注意力机制的特性,同时结合情感描述子句和情感原因子句的相对位置特征,学习情感描述子句和情感原因子句之间的语义关系,然后利用卷积神经网络捕捉情感原因子句的局部上下文特征,从而学习情感原因子句的特征.在基准数据集上的实验表明,综合考虑了情感原因子句和情感描述子句的语义关系和位置关系,以及原因子句的上下文后,能获得较好的原因子句抽取效果.
2 基于子句的情感原因抽取方法
情感原因抽取可以转化为子句级别的分类问题[13].在子句级别的情感原因抽取任务中,对给出的每个文档D,根据标注的情感子句,从所有候选子句中找出引发该情感的原因子句,即判断子句是否是该情感产生的原因.本文充分考虑了子句间的语义和位置关系,首先,利用双向长短期记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)编码子句信息,并通过位置嵌入网络,将子句的位置信息融入到该子句的语义信息中.接着,利用卷积神经网络和自注意力机制,获得文档中每个子句的上下文信息以及该子句与情感描述子句之间的语义信息,最后结合以上子句特征对子句分类.整体网络模型如图2所示.
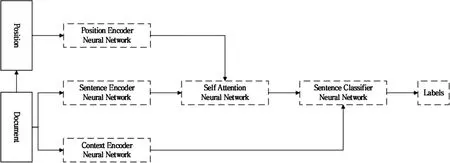
图2 基于子句的自注意力神经网络结构Fig.2 Clause-based self-attention neural network model structure
模型主要由5个部分组成:子句编码器网络、位置特征编码器网络、自注意力计算网络,上下文特征提取网络和原因子句分类网络.其中,句子编码器由Bi-LSTM组成(3.2节),用于编码子句从而获得子句的特征表示.位置特征编码器(3.3节)由位置嵌入和线性变换网络组成,用于位置特征的学习和提取.自注意力计算网络(3.4节)由多个线性网络层组成,用于计算情感原因子句和情感描述子句之间的自注意力计算.上下文特征提取网络(3.5节)由多个卷积神经网络(Convolutional Neural Networks,CNN)组成,用于抽取子句的上下文局部特征.原因子句分类网络(3.6节),将由各个网络学到的特征融合后,最后使用softmax网络层进行分类,获得最后的句子标签.
表1为论文相关符号说明.
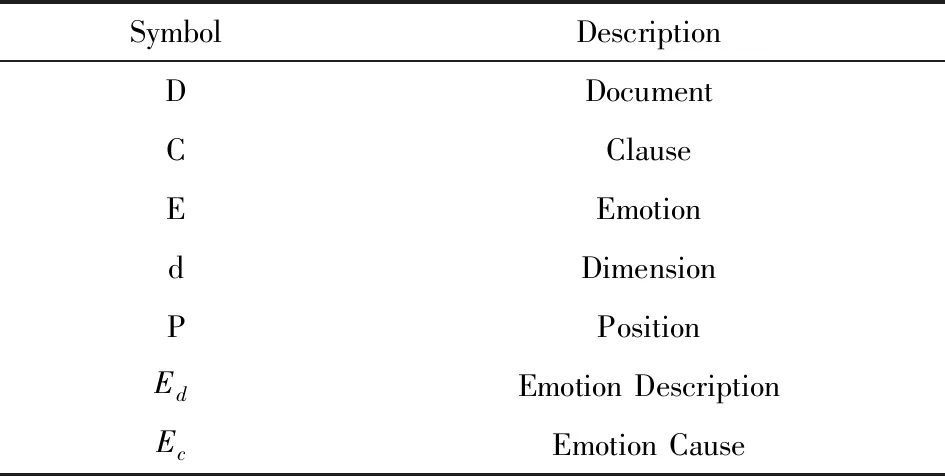
表1 相关符号说明Tab.1 Related symbol description
2.1 模型输入特征
文档D={C1,C2,…,Cn}由n条子句组成.其中,情感描述子句用Ed表示,引发情感Ed的原因子句用Ec表示.D中的每个子句Ci由m个词组成,即Ci={w1,w2,…,wm}.利用word2vec[22]技术将每个词映射为向量表示.情感描述子句Ed被转换由词向量表示的特征矩阵Ed={w1,w2,…,wm}.
为了便于训练模型,令文档中候选原因子句Ec和情感描述子句Ed有相同的L个词的长度.所有的子句都用一个lxd(l为句子长度,d为词向量维度)矩阵来表示,同时融入Ec和Ed的相对距离特征Pf.为了更加凸显情感原因子句特点,本文在训练过程中利用卷积神经网络融入了候选原因子句的上下文信息F.
2.2 基于Bi-LSTM句子编码器
相对于一般的循环神经网络(Recurrent Neural Network ,RNN),LSTM[23]不仅可以解决RNN的梯度消失和梯度爆炸问题,还可以依赖门控机制捕获更长依赖的语义信息.与LSTM相比,Bi-LSTM不仅能捕获正向的序列信息,还能捕获反向的序列信息.因此,为了更好的获得情感原因子句和情感描述子句的上下文语义信息,本文使用Bi-LSTM对句子编码,如图3所示.

图3 基于双向神经网络的句子编码器Fig.3 Sentence encoder based on Bi-LSTM
实验所使用的Bi-LSTM包含了两层ht的输出,即一个为正向LSTM的输出,另一个为反向LSTM的输出,将文档D={C1,C2,…,Cn}中的子句的词向量矩阵放进Bi-LSTM中,可以获得两个正反两个方向的输出,拼接两个输出获得最终的输出,如公式(1)所示.
(1)

2.3 位置编码网络
通过对数据集的统计,发现Ed和Ec的距离大多数情况下都是接近的,如表2所示,情感描述子句和情感原因子句的相对距离(Relative Position,RP)小于2的占比85%以上,相对距离大于2的子句对少于5%,表明了情感描述子句和情感原因子句存在位置上的关系.

表2 相对距离统计Tab.2 Relative distance statistics
因此,本文引入位置编码网络去学习Ed和Ec的位置特征,如图4所示.
本文用位置嵌入来描述子句之间的相对位置信息P.首先初始化一个符合正态分布的随机位置矩阵PE(Position Embedding),获得位置向量Pe,然后通过线性变换和ReLU激活函数来抽取位置特征,获得最后的位置特征Pf,在网络训练过程中调节位置矩阵PE,公式(2)-(5)给出了变换过程的定义.
(2)
(3)
(4)
(5)
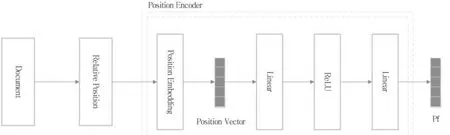
图4 位置编码网络Fig.4 Position encoder neural network
2.4 自注意力的计算网络
利用自注意力机制[19]可以计算词与词之间的相关程度的特性,本文使用自注意力计算子句Ed和Ec之间的关联性,如图5所示.

图5 自注意力计算网络Fig.5 Self attention neural network
计算自注意力需要q、k和v三个输入,Ec的输入用qc,kc,vc表示,Ed的输入用qd,kd,vd表示,hc和hd分别是使用Bi-LSTM编码得到的Ec和Ed的子句特征.Ec和Ed的自注意力计算如公式(6)-(13)所示.
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
其中wQ,wk,wV分别为查询矩阵,键矩阵和值矩阵,输入向量通过与这三个矩阵相乘获得对应查询向量q、键向量k和值向量v,公式(7)-(9)给出了计算过程.然后,本文在自注意力计算过程中利用q、k计算出对应的注意力分数,如公式(14)-(17)所示.βd和βc分别是Ed和Ec得到的注意力分布,最后通过与值向量v相乘获得,获得Ed和Ec的自注意力信息zd和zc.
(14)
(15)
(16)
(17)
2.5 基于CNN的上下文特征提取
文献[24]将卷积神经网络应用到文本分类任务,利用多个不同大小的卷积核提取句子中的关键信息,从而捕捉到句子的局部特征.为了更好的找到情感原因子句的局部特征,本文也利用卷积神经网络抽取每个子句的上下文特征F.如图6所示,利用三个不同的卷积核的卷积神经网络从不同维度提取特征.通常一个子句的语义与前后子句是相关联的,因此本文将每个子句的前一条子句和后一条子句作为子句的上下文.
1)卷积层.
(18)


图6 基于卷积神经网络的上下文编码网络Fig.6 Context encoder based on CNN
2)池化层.
获得卷积提取特征后,再通过最大值池化操作进一步对文本特征进行采样提取,从而获得每个子句的上下文特征,式子(19)表示了池化过程.将三个不同卷积核的卷积神经网络抽取的特征进行拼接,最后获得的子句的上下文特征表示F,如公式(20)所示.
(19)
(20)
2.6 原因子句抽取
首先将自注意力信息zd和zc融入到Ed和Ec的子句特征中,然后结合上下文特征获得最后的特征表示fcd,最后,我们使用句子分类器对子句进行分类,如公式(21)-(24)所示.
(21)
(22)
(23)
(24)
3 实验分析
3.1 数据集与参数设置
本文选取了基于新浪城市新闻的中文情感原因数据集[13],该数据集目前是情感原因抽取领域最大的中文数据集.数据集中包含了2105条新闻文档,总共包含11799条子句.其中,原因子句有2167条,平均每个文档至少包含一条原因子句,具体信息如表3所示.每个文档包含多个子句,其中可能存在多个情感描述子句和情感原因子句,模型的目标是找出文档中的原因子句.

表3 数据集信息统计Tab.3 Dataset information statistics
为了更好地评价模型的性能,本文采用查准率(P)、查全率(R)和F分数作为模型的性能指标.同时,参考了文献[20]的实验设置,将数据随机分为10份,其中,9份作为训练集,1份作为测试集,最后的实验结果由十折交叉验证实验结果求均值得到.实验使用了gensim模块训练词向量,词向量维度设置为200,位置嵌入矩阵维度为200,Bi-LSTM的隐藏层设为400,层数为1,卷积神经网络的卷积核大小分别为3、4、5.本文利用Adam优化器,在G200eR2上训练模型,每次学习64条数据,学习率设置为0.0001.
3.2 对比模型
本文选取了近年的情感原因抽取模型进行对比,对比模型的具体信息如下:
● RB 是一种基于语言规则的情感原因分析模型[4].
● CB 是一个基于知识的方法[17].
● RB+CB 是一个联合RB和CB的方法.
● RB+CB+SVM 是一个结合了规则和知识的基于SVM的方法[14].
● Multi-kernel 是一个基于多核的情感原因抽取方法[13].
● CNN 是一个基于卷积神经网络的方法[24].
● Memnet 是一个将情感原因抽取任务看做一个问答问题中阅读理解任务神经网络模型[20].
● CANN 是一个有上下文感知的联合注意力神经网络模型[8].
● HCS 是一个基于CNN和RNN的层次神经网络模型[11].
● RTHN是一个基于RNN和transformer的层次网络模型[9].
● MANN是一个带有上下文感知的多注意力神经网络模型[15].
● COMV 是一个带有上下文感知的多视图神经网络模型[10].
3.3 实验结果分析
如表4所示,基于深度学习技术的方法整体上要优于传统方法,体现出深度学习方法强大特征抽取能力.在传统方法中,Multi-kernel模型由于其多核的设置,明显优于其他方法,能够抽取更多的文本特征.RTHN模型考虑了文档中全局子句之间的关系,与除了COMV以外的模型相比,R和F均有较好的提升.模型COMV由于考虑了文档中子句的上下文信息,使得整体指标明显优于其他模型,提升了1%左右,说明了每个子句的特征与其上下文有着紧密的联系.MANN模型使用互注意力机制,考虑了情感描述子句和情感原因子句的关系,而在查全率R上优于其他模型,提升了2%左右.
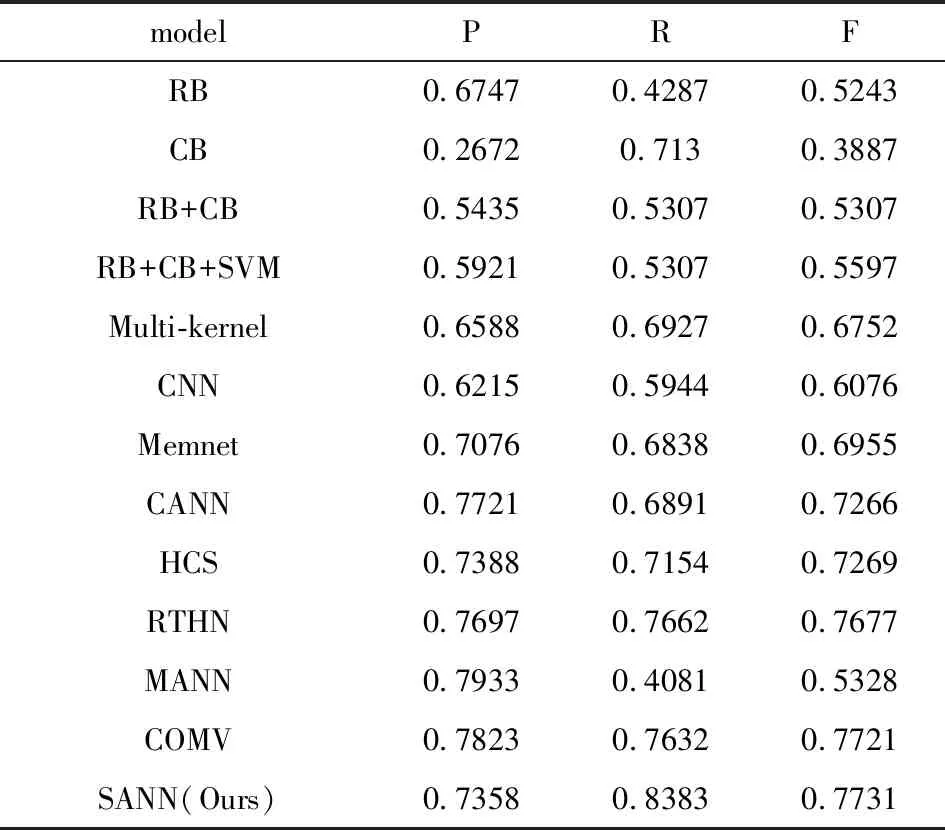
表4 模型结果对比Tab.4 Comparison of model results
从表4中可以看出,本文提出的子句级自注意力神经网络模型(SANN),在查全率R上有明显提升,达到了0.8383,而查准率P有小幅度下降,F分数与其他模型相比,略有提升.经分析,本文所提出的模型一方面利用子注意力机制,结合位置特征学习了情感描述子句和情感原因子句之间的语义关系,能更好的抽取情感原因子句的特征;另一方面,还考虑了情感原因子句的上下文特征,从而更加凸显情感原因子句的语义特性,使得模型可以更好的辨别情感原因子句和其他子句的差异,使模型有更好的查全率R.
3.4 多头注意力参数分析
在Transformer原始结构中,自注意力计算可以进行多头的并行计算,从而获得词在不同子空间的语义,从而获得更好的注意力表示.因此,本文对子句级的自注意力的有效性也进行了验证.
从表5可以看出,在有子句级别的自注意力时,模型的查全率R和F分数明显高于没有自注意力的情况.另一方面,模型各个性能指标并没有随着head的数量的增加而有明显的变化,只有微弱的浮动,说明在本文的模型中,多头注意力只学习了有限的情感原因子句和情感描述子句之间的语义关系.
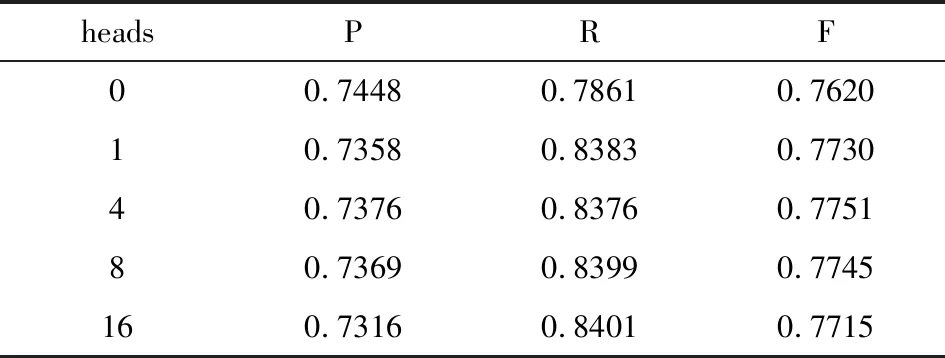
表5 多头注意力的结果Tab.5 Results of multi-head attention
3.5 位置特征
为了验证位置特征抽取网络的有效性,本文进行了在没有位置特征情况下的试验,实验结果如表6所示.从表6可以看出,在没有位置特征的情况下,模型的各个性能指标均发生了明显的下降,达到25%左右.实验结果表明,位置特征对自注意力网络学习情感原因子句和情感描述子句之间的语义特征十分重要;本文提出的位置特征抽取网络能够有效学习到子句的位置特征.

表6 位置特征比结果Tab.6 Comparison of location features
3.6 超参数分析
为了找到模型的最优超参数设置,本文进一步分析了不同超参数对模型收敛速度和各个性能指标的影响.
如图7展示的是模型收敛的速度与批数据大小的关系,从图中可以看出,模型在训练70轮左右时,模型基本收敛,批处理数据越小,模型收敛的速度越快.在批处理大小为16时,模型收敛得最快,同时,随着批处理数据越大,模型收敛的速度越快.但是,在寻找最优值时,批处理数据越小,越容易在最优值附近波动,使得模型不容易找到最优收敛值,相反,批处理数据偏大,模型收敛慢,但是容易找到最优值.

图7 模型收敛与批大小关系Fig.7 Relationship between model convergence and batch size
图8展示了词向量的维度与模型各性能指标的实验结果.从图中可以看出,在词向量维度为200的情况下,模型的整体性能最好,最高的查全率R为0.8383.虽然不同维度的词向量对模型的性能有一定的影响,但各性能指标差异在1%以内.

图8 词向量维度对模型性能的影响Fig.8 Influence of word vector dimension on model performance
4 结语
为了更好地抽取情感原因子句和情感描述子句之间的语义关系,本文提出了一个基于子句的自注意力机制的情感原因抽取方法.首先利用双向长短期记忆网络编码情感原因子句和情感描述子句信息,然后利用自注意力机制,融入位置特征的去抽取情感原因子句和情感描述子句之间的语义关系,最后结合卷积神经网络提取的子句上下文局部特征,去识别情感原因子句.实验结果表明,本文提出的方法能够有效学习情感原因子句和情感描述子句之间的关联特征,从而有效识别原因子句,使得模型的查全率R明显优于其他神经网络模型.
在未来工作中,将尝试引入预训练语言模型,在抽取情感原因子句的同时,进行情感的抽取,并进一步探究情感原因子句的其它特征.
