Kirsch算子地质图像边缘检测算法并行化研究∗
2021-01-30田宸玮王雪纯杨嘉能钱育蓉
田宸玮,王雪纯,杨嘉能,钱育蓉†
(1. 新疆大学 软件学院,新疆 乌鲁木齐830008;2. 新疆维吾尔自治区信号检测与处理重点实验室,新疆 乌鲁木齐830008;3. 新疆大学 软件工程重点实验室,新疆 乌鲁木齐830008;4. 中国石油吐哈油田公司勘探开发研究院,新疆 哈密839009)
0 引言
近年来,飞速发展的数字图像处理技术普遍应用于各个领域,在地质勘探领域中也展现出巨大的潜力,用于检测及分析各种地质学信息[1,2].在视频图像处理领域,边缘检测也是较为基本的方法,常见的边缘检测算子包括Sobel算子、Prewitt算子、Roberts算子、LoG算子、Kirsch算子、Canny算子[3,4].Sobel算子和Prewitt算子在边缘定位方面有较好的效果,但是像素边缘容易产生过量[5−7];Roberts算子同样在定位边缘时有较高的准确度,但是在抗噪声方面表现较差[8];LoG算子在噪声抑制时会平滑较为尖锐的边缘,所以在弱边缘检测方面表现较差[9];Canny算子检测具有较高的检测准确率以及信噪比,且图像边缘的连续性和完整性较好,但是伪边缘的存在、抗噪声能力较差等问题依旧存在[10,11];Kirsch算子的边缘连续性和完整性较差,优点在于能较好的抑制噪声[12].因此,本文提出CUDA(Compute Unified Device Architecture,计算统一设备架构)下基于自动阈值的Kirsch算子边缘检测算法.
Kirsch算子通过对原始图像进行8个方向的边缘检测,对这8个方向的噪声具有一定平滑的作用.该算法需要对每一个像素进行相应的计算[13],属于典型的SIMT(Single Instruction Multiple Threads,单指令多线程)计算模式.考虑到边缘检测算子需要计算整个图像、处理效率不理想的问题,使用CUDA用于设计和优化并行算法.近年来,CUDA表现出很强的并行计算性能.GPU架构是围绕具有弹性的SM(Streaming Multiprocessor,流多处理器)阵列构建的,在边缘检测方面应用也较为广泛,如Adhir Jain[14]使用CUDA进行Sobel算子的边缘检测;Yam-Uicab R[15]使用CUDA加速霍夫变换;张晗[16]基于CUDA使用Prewitt算子检测地质图像边缘.本文通过验证算法的计算效率以及在并行传输开销方面对所提出算法进行测试.
1 改进后的边缘检测算法
Kirsch算子的边缘检测算法是对图像像素使用顺时针循环求梯度的方法进行边缘检测,将其中方向响应最大者作为边缘幅度图像的边缘.八个方向的卷积模板如下所示:
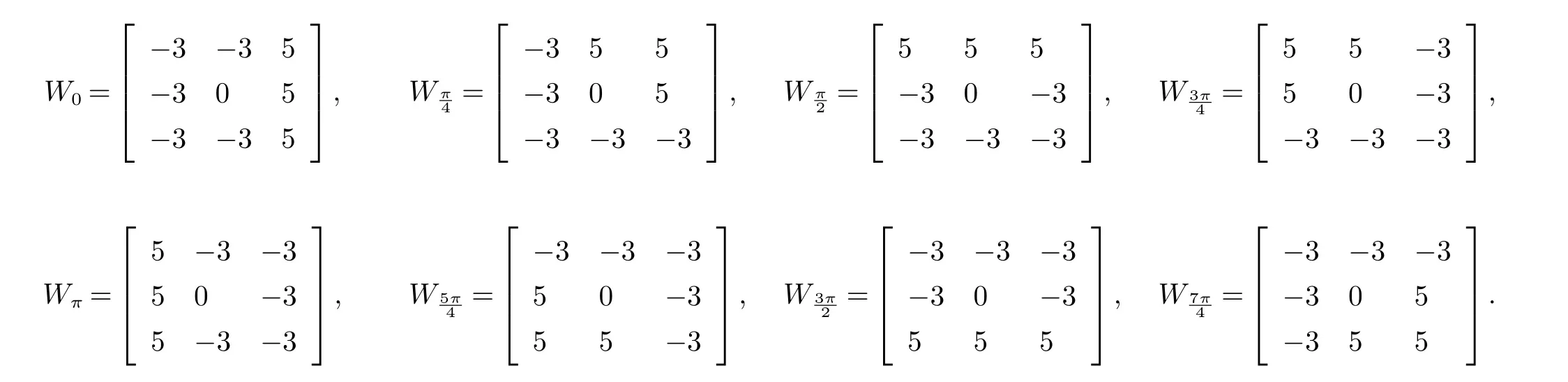
边缘梯度选取大小为:
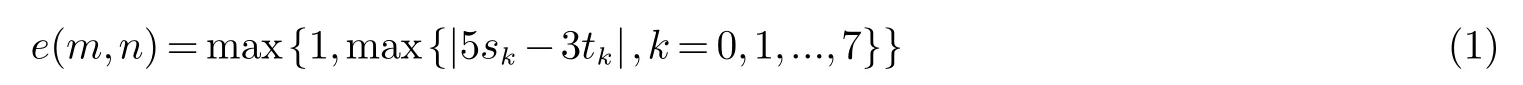
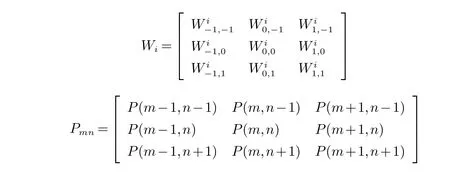
其中:i方向对应的模板为Wi;坐标(m,n)处的中心3∗3像素区域为Pmn.
Kirsch算子的边缘检测算法要对原始图像的每一个像素点进行卷积运算,故存在边缘问题(最外围一圈像素,周围像素个数不为8),使用扩展法来减少判断边缘的计算量,在图像边缘填充模板尺寸二分之一的像素边缘,根据式(1)可知,计算单个像素的响应度所需的总计算量为:加法56(7∗8)次,乘法16(2∗8)次,还有求比较最大响应的7次比较运算,计算一副图像像素为x∗y的图像计算量为:加法56(x∗y)次,乘法16(x∗y)次,比较运算7(x∗y)次,故不符合实时图像处理系统的要求.为减少计算量,通过模板Wi对每个像素区域进行卷积求和的方法,得出计算各个方向的二范数公式:
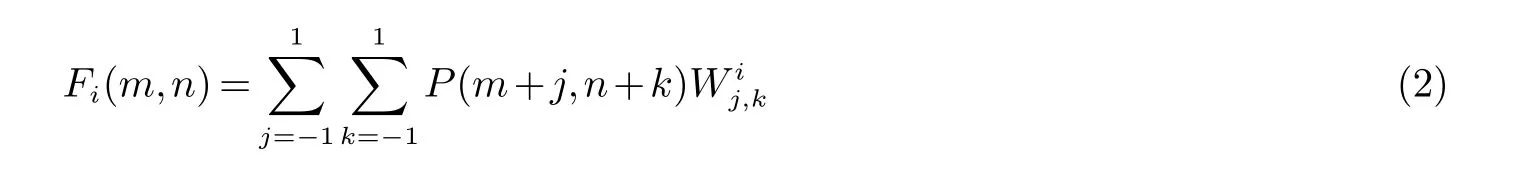
其中:Fi(m,n)为P(m+j,n+k)与Wij,k卷积运算得到的二范数;Wij,k为i方向对应模板坐标(j,k)处的元素;i=(0,π/4,π/2,3π/4,π,5π/4,3π/2,7π/4).
最后按照垂直组合的规则将8个方向结合成四组,分别计算梯度的二范数:

其中:i=(1,2,...8),ji=π/4∗(i−1), ki= mod((3π/2+π/4∗(i−1)),2π),取‖Gi‖2i=(1,2,...8)的最大值为该点像素的梯度,即:

传统的Kirsch算子在保持边缘细节和抑制噪声方面有很好的效果,但边缘连续性和完整性较差.针对Kirsch算子的缺点,使用整幅图像的平均灰度作为阈值对其进行二值化,阈值(TH)如式(5) 所示:

其中:M为图像宽度,N为图像高度.
遍历整个图像,将每个像素点与得到的阈值进行对比后更新,更新规则如式(6)所示:

分析(1)~(5)式可知,算法执行过程中对每一个像素点进行独立操作,故存在并行的可能性.设计较好的并行算法可达到减少计算时间、增大算法实时可能性的目的.
2 基于CUDA对改进后的算法并行分析
2.1 算法总流程
每一个像素使用单个线程进行计算,多线程可以实现大量像素的并行计算,极大提高了计算效率.阈值自适应的Kirsch算子边缘检测并行计算流程如图1所示.
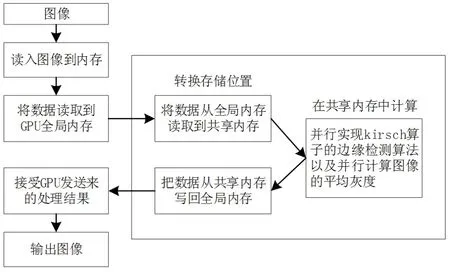
图1 算法总流程Fig 1 Algorithm process
Step1Host读入图像到内存;
Step2Host将数据发送给Device全局内存;
Step3Host启动Device核函数,此时Device多线程执行;
Step4 Device处理结果回传到Host内存;
Step5Host生成最终图像.
在Step3中,处理的数据为图像,图像是由二维点集构成的,根据图2所示映射结构创建二级线程模式,Grid为二维线程格子,Block为二维线程块.
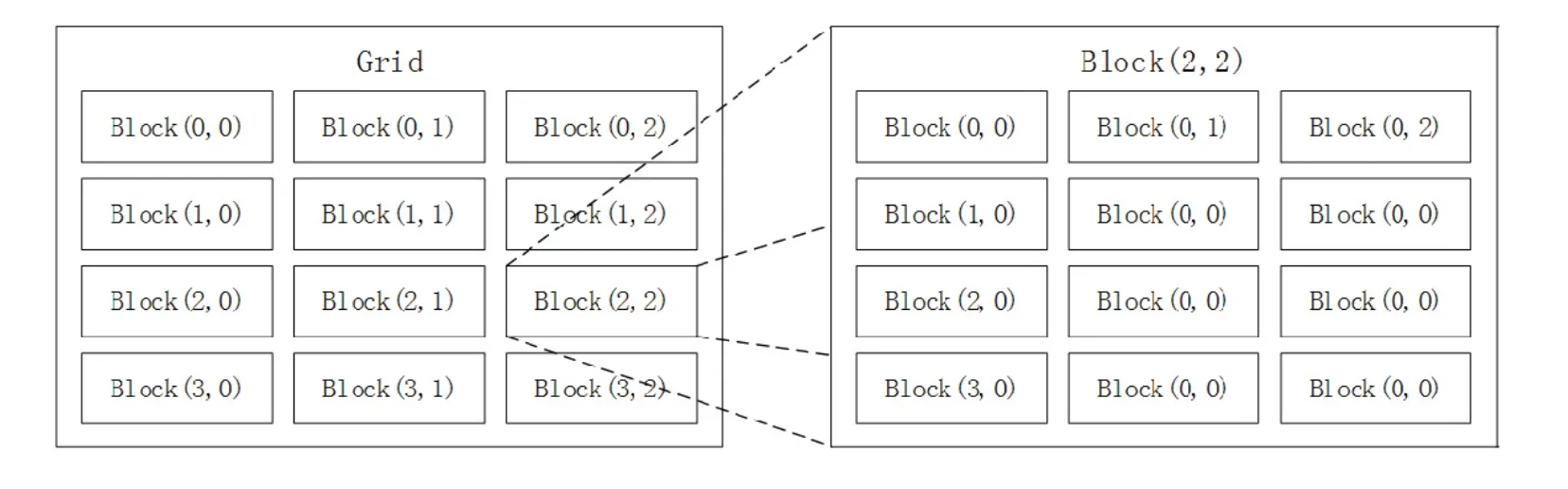
图2 二级线程模式Fig 2 Secondary thread mode
2.2 累计灰度值以及计算阈值的并行化
该步骤主要设计思想是累加各个线程块计算所得到的局部阈值,最后汇总得到总的阈值.具体实现思路是先把Block内所有的线程从全局内存中将图像像素读取到共享内存,此时块内的线程需要进行同步操作来确保全部线程已经读取像素,最后通过累加各个线程块得到的局部阈值来确定最终的全局灰度阈值.
2.3 算法优化部分
二维卷积操作同样会遇到与一维卷积操作一样的边界问题.本文使用拓展法(如图3所示,选取到的二维像素点在周围添加卷积核大小二分之一的像素填充并赋值为0)来解决边界判断问题.使用此方法卷积操作无需考虑边界问题,但是需要调整计算索引.算法1展示了主要的处理流程.
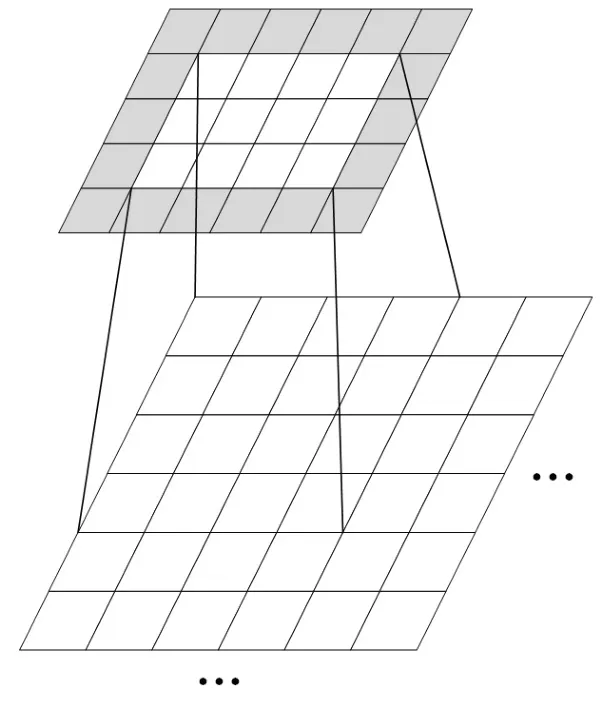
图3 填充边缘Fig 3 Fill the edge
算法1:
(1)设置共享内存空间
(3)获取线程块中线程坐标
(4)int tx = threadIdx.x;
(5)int ty = threadIdx.y;
(6)每个线程相对于所有线程的坐标
(9)使用拓展法,调整正确索引
(12)int size = width * height;
(13)for (循环图像的通道数) {
(14)读取每个像素点并将拓展的像素进行赋值
(17)}
(18)else{
(19)Data[ty][tx] = 0.f;
(20)}
(21)同步等待所有线程完成操作
(23)计算四对二范数,取最大值作为梯度值,完成后将结果写回全局内存
(25)}
3 实验结果与分析
计算机平台包含支持CUDA加速的显卡.主机系统配置为IntelCorei7-7820 HK,时钟频率2.90 GHz,内存大小16 GBRAM,GPU规格见表1.

表1 NVIDIA GeForceGTX 1070 规格Tab 1 NVIDIA GeForceGTX 1070 parameter
3.1 线程块索引与数据传输开销分析
调整线程块索引主要针对数据在共享内存时使用,为了降低线程的发散程度,表2所示分别在全局内存和共享内存上做了对比,说明本算法使用共享内存是更好的选择.主要原因是:1.硬件方面,共享内存位于设备上,而使用全局内存计算需要频繁地在主机和设备之间执行拷贝操作,这无疑大大增加了算法执行的时间;2.软件层面,通过线程索引的调整降低了线程的发散程度.

表2 全局内存和共享内存读取时间对比Tab 2 Global memory and share memory read time compare
3.2 线程规模对计算性能的影响
NVIDIAGeForce 1070中,由于每次都需要计算幅度值以及方向,故在单个线程块中需要使用三个区域,其中两个保存上个任务的处理结果和本次的处理结果,另一个用来保存梯度方向.所以每个拓展块的容量不能超过16 KB.如表1所示,GPU硬件规定warp大小为32,故选择线程块大小为16×16,包含16×16个线程.

表3 文献[17]并行与串行算法执行时间(ms)与加速比(倍)Tab 3 Parallel and serial algorithm execution time(ms) and acceleration ratio (times) in literature[17]

表4 文献[18]并行与串行算法执行时间(ms)与加速比(倍)Tab 4 Parallel and serial algorithm execution time(ms) and acceleration ratio (times) in literature[18]
为验证算法并行处理的优势,选取不同尺寸图片对比CPU串行执行时间和GPU并行执行时间,并与文献[14]、文献[15]的实验对比,表明本文提出的算法可以较大缩短执行时间、提高检测效率,见表3~表5.
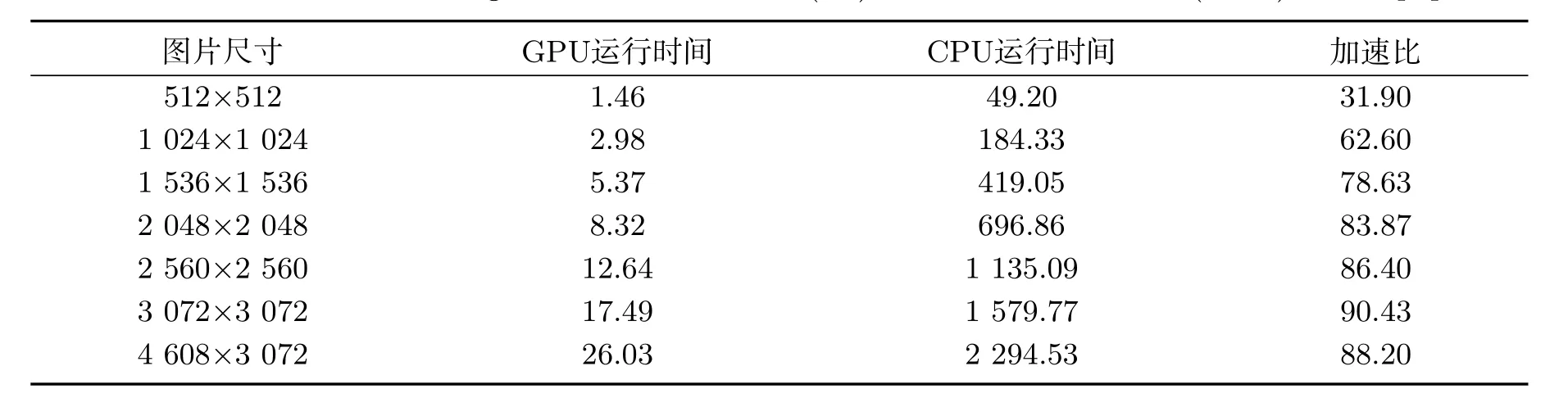
表5 本文并行与串行算法执行时间(ms)与加速比(倍)Tab 5 Parallel and serial algorithm execution time(ms) and acceleration ratio (times) in this paper
所用实验数据选取不同分辨率的遥感图像测试并行算法的检测效果,如图4所示.本文提出的算法能够清晰的分辨出地质的纹路.

图4 遥感地质图像Fig 4 Remote sensing geological image
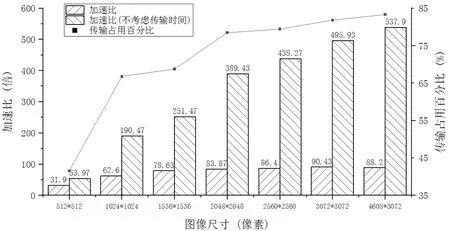
图5 算法加速效果与传输时间Fig 5 Algorithm execution effect and transmission time
4 结束语
本文主要完成了CUDA下自适应性阈值Kirsch算子边缘检测算法并行优化研究,对优化传统Kirsch算子的边缘检测算法分析,使用拓展法节省边缘判断计算所消耗的时间,将原有8个方向的计算减少为计算4个方向的二范数;其次,使用平均灰度作为二值化阈值避免人工设定阈值随机性较大的问题.并行方面从线程块大小的设置以及传输开销方面分析算法瓶颈.实验验证如图5所示,针对图像尺寸大于2 048*2 048的地质图像,在考虑传输开销的情况下算法的加速效果保持在80倍以上,不考虑传输开销可保持在300倍以上.可见使用CUDA加速的部分瓶颈在于主机与设备的传输开销所占用时间比例过大,之后会对CUDA的传输开销做进一步研究.图像的处理获得了较为满意的结果,提高了算法的执行效率,适用于大规模地质图像的边缘检测.
