面板数据下区域农业干旱灾害风险的灰色C型关联分析
2021-01-29罗党李晶
罗党, 李晶
(华北水利水电大学,河南 郑州 450046)
旱灾是严重制约农业发展的自然灾害之一。随着全球气候持续变暖,我国农业旱灾的发生频率显著增加。在旱灾形势严峻的大背景下,旱灾风险管理逐渐兴起,而旱灾风险评估作为旱灾风险管理的核心,是旱灾研究的重要内容[1]。近年来,基于灾害系统理论的旱灾风险评估模型在实际中的应用逐渐成熟。如:秦越等[2]从抗旱能力、危险性、脆弱性和暴露性4个方面选取相应指标,通过旱灾风险综合指标模型,对承德市8个县2001年的农业旱灾风险进行了评估;金冬梅等[3]从危险性、脆弱性、暴露性和防旱抗旱能力4个方面选取指标,并基于2004年数据评估了吉林省9个城市的干旱缺水风险程度;吴迪[4]从脆弱性、暴露性、危险性及抗旱减灾能力4个方面选取15个指标,并基于2015年数据对我国13个粮食主产省的旱灾风险等级进行了划分。以上研究均从指标和样本两个维度对旱灾风险进行评估,因旱灾具有渐进性,即旱灾是由干旱对整个系统的不利影响逐步累积形成的,故在此基础上,考虑各地区年际间旱灾风险的动态变化(时间维度),对问题进行整体分析更贴合实际。此外,受认知水平等不确定性因素的影响,收集的数据难免存在不完全、不准确的现象。近年来发展迅速的灰色关联分析方法恰巧擅于处理此类问题。
灰色关联分析的基本思想是通过不同序列曲线图形之间的相似性来判断序列的联系密切程度。自邓聚龙教授提出邓氏关联度以来[5],B型关联度[6]、T型关联度[7]、C型关联度[8]、斜率关联度[9]等相继被提出。以上模型主要适用于截面序列与时间序列的灰色关联分析。随着研究的深入,基于面板数据的关联模型也有了一定的发展。如吴利丰等[10]利用黑塞矩阵定义凸度,构建了面板数据下的灰色凸关联度;刘震等[11]通过网格图形表示面板数据,提出了灰色网格关联模型;党耀国等[12]和罗党等[13]从时间和对象两个维度出发,解决了面板数据关联序随对象的排列顺序变化而变化的问题。但现有关联模型或者无法适应高维面板数据建模,或者无法很好地保证关联序不受指标排列顺序的影响。为针对性地解决这些问题,本文通过定义样本行为矩阵,构建了面板数据下的灰色C型关联模型,并将模型应用于豫北平原5个地区的旱灾风险评估中,以期为政府及管理部门制定防灾减灾措施提供理论支撑。
1 农业干旱风险评估
1.1 评价指标体系构建
农业干旱灾害风险是指干旱灾害对某一地区农业产生的影响,即干旱灾害后农业生产、农民生活和社会发展受到损失的概率。研究区域农业干旱灾害风险,有助于抗旱措施的具体实施[14]。
农业干旱灾害风险由孕灾环境暴露性、承灾体脆弱性、致灾因子危险性及抗旱减灾能力4个方面决定[2]。本文根据影响农业干旱灾害风险4个因子的特点,选取了12个指标构建评价指标体系,见表1。根据指标含义将其分为正向和负向两类,其中与农业旱灾风险成正比的为正向指标(+),反之为负向指标(-)。

表1 农业干旱灾害风险评价指标体系
1.2 指标标准化及权重计算
由于指标的意义、量纲各不相同,为方便计算,需对指标进行如下标准化处理。
对于正向指标:
(1)
对于负向指标:
(2)
式中:sij为xij量化后的标准化值;xij表示第i个样本地区的第j个指标值;max(xj)为第j项指标的最大值;min(xj)为第j项指标的最小值;i为样本地区的数量,i=1,2,…,n;j为指标个数,j=1,2,…,m。
熵值法是一种应用较广的客观赋权法[15]。本文采用该方法对指标进行赋权,具体步骤如下。
步骤1计算第i个样本地区第j项指标所占的比重:
(3)
步骤2计算熵值:
(4)
步骤3计算差异系数:
gij=1-eij。
(5)
步骤4确定指标权重:
(6)
1.3 旱灾风险评估模型
基于前述指标评价体系及权重计算过程,构建农业旱灾风险评估模型[16]:
(7)
其中:
式中:Ri为第i个样本地区的农业旱灾风险综合指数;Ei、Vi、Hi、REi分别为第i个样本地区的孕灾环境暴露性指数、承灾体脆弱性指数、致灾因子危险性指数、抗旱减灾能力指数。
根据以上模型可计算出样本地区每年的农业旱灾风险程度,但不能对样本地区年际间旱灾风险的整体趋势进行分析。为解决该问题,构建以下模型。
2 面板数据下的灰色C型关联模型
2.1 样本行为矩阵
时间、样本和指标是面板数据的3个维度,通过二维矩阵表示三维面板数据更有助于解决实际问题[17]。
定义1设xi(s,t)为面板数据中第i个样本地区的第s个指标在时刻t的观测值,称
为第i个地区的样本行为矩阵(比较矩阵),i=1,2,…,n;s=1,2,…,m;t=1,2,…,T。
定义2设x0(s,t)为面板数据中理想地区的第s个指标在时刻t的观测值,称
为理想地区的样本行为矩阵(参考矩阵)。
2.2 模型构建
定义3(位移关联度)设样本地区i和理想地区的样本行为矩阵分别为Xi和X0,称xi(s,t)和x0(s,t)分别为样本地区i和理想地区的第s个指标在时刻t的效果值,定义Xi和X0在t时刻的位移关联度为:
(8)
位移关联度体现了样本地区与理想地区年际间农业旱灾风险的总体接近程度,位移关联度取值越大,样本地区的旱灾风险值越低。
定义4(速度关联度)设样本地区i和理想地区的样本行为矩阵分别为Xi和X0,称x′i(s,t)和x′0(s,t)分别为样本地区i和理想地区的第s个指标在时刻t的一阶差商,定义Xi和X0在t时刻的速度关联度为:

(9)
其中:
|x′i(s,t)-x′0(s,t)|=|(xi(s,t+1)-xi(s,t))-
(x0(s,t+1)-x0(s,t))|;
速度关联度体现了样本地区与理想地区在单位年间农业旱灾风险变化的接近程度,速度关联度取值越大,样本地区的旱灾风险值越低。
定义5(加速度关联度)设样本地区i和理想地区的样本行为矩阵分别为Xi和X0,称x″i(s,t)和x″0(s,t)分别为样本地区i和理想地区的第s个指标在时刻t的二阶差商,定义Xi和X0在t时刻的加速度关联度为:

x″0(s,t)|)。
(10)
其中:
|x″i(s,t)-x″0(s,t)|=|(xi(s,t+2)-2xi(s,t+1)+
xi(s,t))-(x0(s,t+2)-
2x0(s,t+1)+x0(s,t))|;
加速度关联度体现了样本地区与理想地区在单位年间农业旱灾风险速度变化上的接近程度,加速度关联度取值越大,样本地区的旱灾风险值越低。
定义6(综合关联度)设样本地区i和理想地区的样本行为矩阵分别为Xi和X0,定义Xi和X0在t时刻的综合关联度[18]为:
(11)
灰色C型关联分析模型通过商式的极限构建位移关联度、速度关联度和加速度关联度,其离散形式的适用范围有一定的局限性。本文根据指数函数下降速率快且函数值为正的性质,构建位移关联度、速度关联度和加速度关联度,可在不改变C型关联模型建模思想的前提下,对系统进行分析,故可称综合关联度为面板数据下的C型关联度。C型关联度体现了样本地区与理想地区在年际间农业旱灾风险动态变化的整体接近程度,C型关联度取值越大,样本地区的农业旱灾风险值越低。指数函数y=exp(-x)与分式函数y=1/(1+x)和三角函数y=cosx的下降速率对比情况如图1所示。
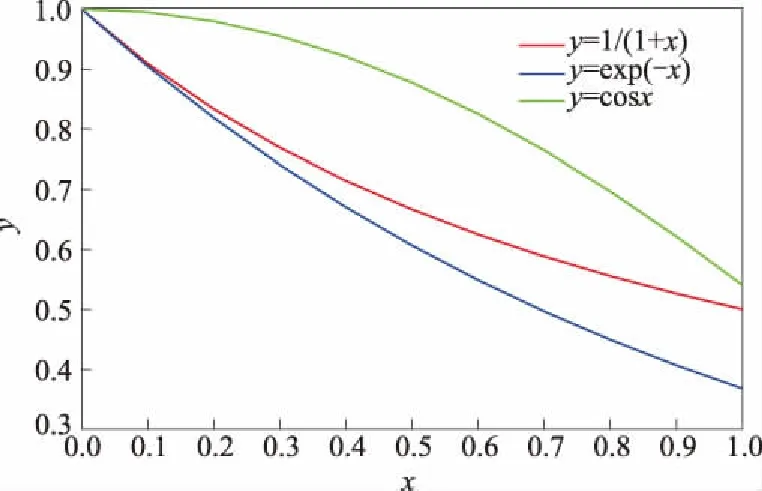
图1 不同函数的下降速率对比
2.3 C型关联模型的性质
定理1面板数据下C型关联分析模型满足以下性质。
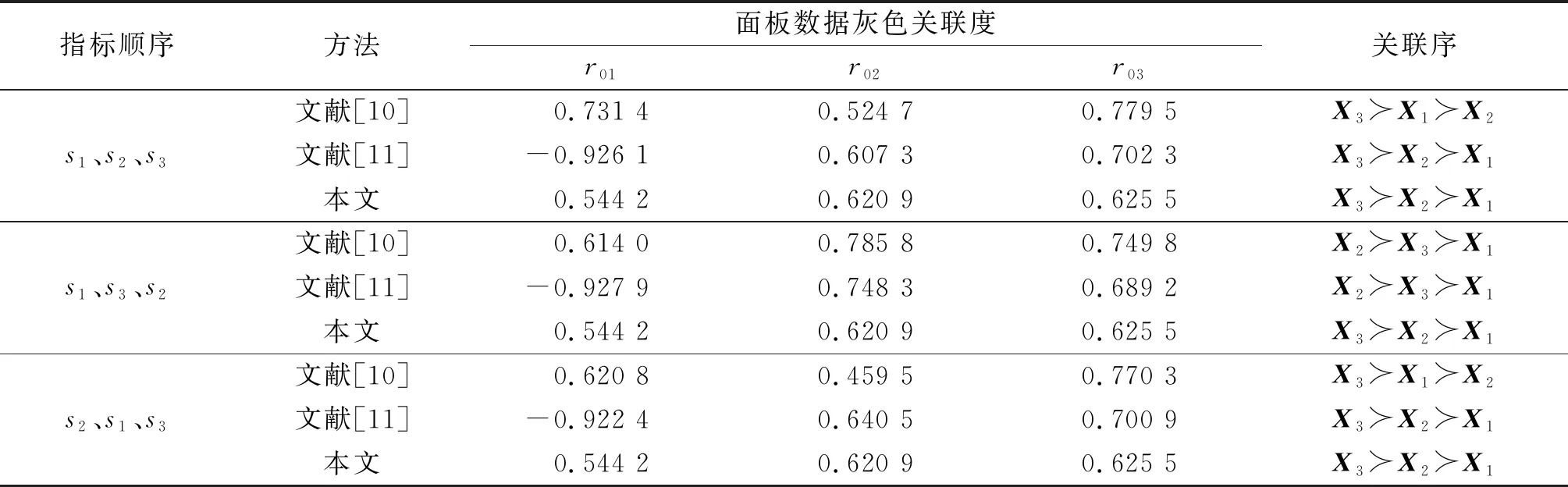
1)规范性:0 2)接近性:Xi和X0越接近,ri0越大; 3)对称性:ri0=r0i; 4)唯一性。 证明1)由指数函数性质可知 0 当且仅当xi(s,t)=x0(s,t)时, exp(-|xi(s,t)-x0(s,t)|)=1。 故位移关联度为: x0(s,t)|)≤1, 当且仅当Xi=X0时, 同理可证: 当且仅当Xi=X0时, 当且仅当Xi=Xj时, 故性质1得证。 3)对称性和4)唯一性显然成立。 给出4组面板数据: 式中:X0为参考矩阵;X1、X2、X3为比较矩阵。 在三维空间中4组面板数据如图2所示,采用本文模型计算面板数据间的关联度为: r01=0.544 2,r02=0.620 9,r03=0.625 5, 故 r03>r02>r01。 由图2可以直观地看出,面板数据X1与X0最不相似,X3与X0最为相似,故本文模型所求关联序与实际情况一致。基于本文研究内容,X0、X1、X2、X3为样本行为矩阵,行代表指标,列代表时间,改变样本行为矩阵的指标排列顺序,采用文献[10]和文献[11]及本文模型进行计算,结果见表2。由表2可知,本文模型所得关联序不随指标排列顺序的变化而改变。 图2 4组面板数据的三维图 表2 指标排列顺序对关联序的影响 豫北平原的焦作、鹤壁、濮阳、新乡和安阳5个地区的最大特征就是雨热同期,但由于地势靠北,日照充足,即使在雨季,干旱现象也时常发生。为使抗旱减灾工作更易实施,利用本文模型对5个地区2008—2016年的农业旱灾风险关联关系进行研究。 根据公式(1)—(7)计算5个样本地区2008—2016年的孕灾环境暴露性指数(E)、承灾体脆弱性指数(V)、致灾因子危险性指数(H)、抗旱减灾能力指数(RE)及农业旱灾风险综合指数(R),结果见表3。计算所用数据来源于河南统计年鉴和河南省水资源公报。 表3 2008—2016年豫北地区逐年农业旱灾风险指数 续表 利用表3对5个地区各年份的旱灾风险进行排序,因年份较多,以下仅以部分年份为例进行说明。2008年,5个地区的旱灾风险综合指数由高到低的顺序依次为濮阳、焦作、安阳、鹤壁、新乡,其中濮阳和新乡两个地区的孕灾环境暴露性指数差距最大,说明2008年旱灾风险的主要影响指标为植被覆盖率、人口密度和农业总产值等;2014年,5个地区的旱灾风险综合指数由高到低的顺序依次为濮阳、新乡、焦作、安阳、鹤壁,其中濮阳和鹤壁两个地区的抗旱减灾能力指数相差最大,说明人均收入、有效灌溉面积及农村就业人口比例是该年份下旱灾风险的主要影响指标;2016年,5个地区的旱灾风险综合指数由高到低的顺序依次为濮阳、焦作、新乡、鹤壁、安阳,其中濮阳和安阳两个地区的致灾因子危险性指数相差最大,说明降雨量、地下水资源量和地表水资源量是影响2016年旱灾风险的主要指标。由以上分析可知,5个地区不同年份的旱灾风险排序结果存在略微差异,其中濮阳地区在9 a中的旱灾风险综合指数均为最高。因此,2008—2016年濮阳地区的整体旱灾风险最高,而其他4个地区的整体旱灾风险程度不易确定。 为进一步得到样本地区2008—2016年间旱灾风险变化的整体趋势,以表3中5个样本地区的E、V、H、RE、R为基础构造样本行为矩阵,称其为比较矩阵。取5个比较矩阵在对应时间下E、V、H的最小值和RE的最大值为理想值,根据评估模型构造以E、V、H、RE、R为指标理想地区的样本行为矩阵,称其为参考矩阵。改变比较矩阵和参考矩阵中E、V、H、RE 4个指标的排列顺序,分别采用文献[10]、文献[11]及本文模型对豫北平原焦作、鹤壁、濮阳、新乡和安阳地区2008—2016年的农业旱灾风险关联度进行计算,比较矩阵与参考矩阵的关联度值越大,相应样本地区的农业旱灾风险越低,结果见表4。 表4 2008—2016年豫北平原5个地区的农业干旱灾害风险关联序 由表4可知:运用文献[10]和文献[11]的方法计算所得的关联序皆会随指标排列顺序的变化而变化,而本文模型的计算结果不会出现此问题,2008—2016年5个地区农业旱灾风险的C型关联序恒为:鹤壁新乡安阳焦作濮阳。结合实际,可对5个地区9 a间的旱灾风险进行整体分析:濮阳地区2008—2016年的降雨量为4 910.2 mm,地下水资源量为47.7 亿m3,地表水资源量为17.1 亿m3,总的水资源量在5个地区中位居末位,与其他3个地区的差距显著,旱灾风险最高;鹤壁地区水资源量虽不丰富,但其植被覆盖率达52.6%,远高于其他4个地区的,旱灾风险最低;焦作地区、安阳地区和新乡地区的各项指标值均处于中间地位,且较为接近,其中水资源量、有效灌溉面积及农业总产值依次降低,因此旱灾风险程度依次降低。这与实际情况较为一致,进一步说明了本文模型的合理性及有效性。 本文针对现有关联模型在高维面板数据下建模时,无法保证关联序不受指标排序影响的问题,采用指数函数计算位移关联度、速度关联度和加速度关联度,进而构建面板数据下的灰色C型关联模型。该模型不仅充分利用了高维面板数据,增强了计算结果的合理性,还可保证关联序不受指标排列顺序变化的影响,丰富了灰色关联分析理论的研究。将模型应用于豫北平原5个地区的农业旱灾风险分析中。分析结果表明,5个地区的农业旱灾风险从小到大的顺序依次为鹤壁、新乡、安阳、焦作、濮阳,文中研究结果与实际相符。该研究可为抗旱减灾工作的实施提供一定的决策支撑。
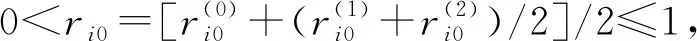

2.4 对比分析

3 实例分析



4 结语
