基于Faster-RCNN的自然环境下油茶果检测研究
2021-01-29饶洪辉王玉龙李庆松王保阳刘木华
陈 斌,饶洪辉,王玉龙,李庆松,王保阳,刘木华
(江西农业大学 工学院/江西省现代农业装备重点实验室,江西 南昌 330045)
卷积神经网络可以自动提取特征,并分类检测,精度高,实时性强[1-4],成为果蔬目标检测的主流框架。而Faster-RCNN卷积神经网络经过RCNN、Fast-RCNN的不断改进,精度和检测效率都得到了进一步的提高。在卷积神经网络果蔬识别方面已经有大量的研究。西北农林科技大学冯亚利[5]使用改进的DY3TNet模型实现了田间猕猴桃果实的检测。闫建伟等[6]为了快速准确识别自然环境下刺梨果实,提出了一种基于改进的Faster-RCNN的刺梨果实识别方法。傅隆生等[7]为了实现田间条件下快速、准确地识别多簇猕猴桃果实,提出了一种基于LeNet卷积神经网络的深度学习模型进行多簇猕猴桃果实图像的识别。程鸿芳等[8]针对传统的基于内容的识别方法在特征提取方面存在的计算复杂、特征不可迁移等问题,对LeNet卷积神经网络结构进行改进,设计了一种基于改进LeNet卷积神经网络的苹果目标识别模型,并利用该模型对不同场景的苹果图像进行了识别与验证,综合识别率达到93.79%;与其他方法相比,该算法具有较强的抗干扰能力,图像识别速度快,识别率更高。中南林业科技大学张习之等[9]提出了一种基于改进卷积自编码机神经网络的油茶果图像自动识别方法,该改进算法100次迭代所需时间为166 s,平均识别准确率为90.4%。
目前在卷积神经网络识别油茶果方面的研究较少,尚无文献用Faster-RCNN卷积网络的方法识别油茶果。本文选用Faster-RCNN交替优化训练方法,并使用Faster-RCNN卷积神经网络对油茶果进行了识别。
1 试验环境及图像采集
1.1 试验环境
本试验在台式计算机上进行,处理器为Intel-i5-9400F,内存为32 GB,操作系统Windows 10 (64位)。考虑到GPU算力的需要,选用显卡NVIDIA GeForce GTX 1660,显存8 GB。Python的版本是3.6.4,在pycharm IDE上编译。深度学习框架选择Keras。同时为了提高训练速度,采用GPU加速方法,cuda版本是8.1,cudnn版本为7.6.0。
1.2 油茶果图像的采集
油茶果图像拍摄于江西省林业科学院国家油茶林基地。拍摄相机为索尼相机,像素为640×480。于2019年9月14~23日的晴天拍摄,采集了典青、赣兴46、赣抚20等34个品种的油茶果图像并保存成JPG的格式。图1为拍摄的部分油茶果图像。

a:正常情况下的油茶果; b:油茶果被遮挡; c:油茶果环境光线弱; d: 油茶果成簇出现。图1 油茶果的部分图像
2 数据集的优化
本试验选取在江西省林业科学院国家油茶林基地采集的2800张油茶果图像进行训练,在验证集上对油茶果图像进行测试,发现对遮挡和光线暗淡、过度曝光等油茶果图像的检测结果不佳。为了提高检测效果,对训练集图像进行优化,增添1020张光线过弱、过度曝光、油茶果被遮挡等各种环境下的油茶果图像,将训练集图像数量扩充到3820张,使卷积神经网络学习到各种情况下油茶果图像的特征(若训练数据集中没有包含多样化的样本,则会导致机器学习不足,识别结果置信度降低)。
3 识别过程
本试验的卷积神经网络使用VGG16骨干网络提取油茶果图像的特征,一共有5个卷积层,5个卷积层的大小分别是64、128、256、512、512。卷积核的大小是3×3。VGG16网络滑动窗口自动提取油茶果和背景的特征,共享卷积;之后产生RPN,RPN网络生成带有置信度的矩形检测框,通过softmax分类器判断属于油茶果还是背景;再利用边框回归修正锚框获得精确的候选区域。运用最大池化层方法采样,对于每一个通道,选取其特征图的最大像素值作为该通道的代表,从而得到一个N维向量。激励层使用的是Relu函数,Relu由于非负区间的梯度为常数,因此不存在梯度消失问题,使得模型的收敛速度维持在一个稳定状态。学习率是0.001,动量为0.9,迭代次数为40000次。图2为Faster-RCNN的结构图。
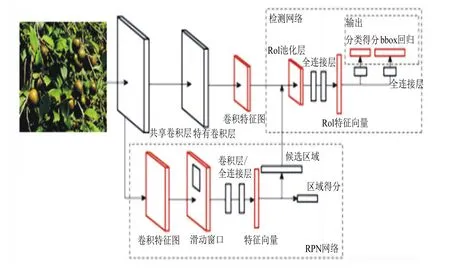
图2 Faster-RCNN的结构
4 锚框参数的优化
在对油茶果的图像进行分类检测之前,RPN接收任意尺寸的油茶果图像作为输入,输出一系列有置信度的矩形候选检测框,这些检测框用于后续Faster RCNN的分类和检测。在原始Faster RCNN卷积神经网络中,每个锚点3种面积尺度分别为128、256、512像素,3种长宽比{1∶1、1∶2、2∶1},它们相互组合,每个Anchor生成9个锚框[10,11]。将图像送到卷积层之后,得到特征图(Feature Map),然后用1个小网络在特征图上进行滑动,以特征图上n×n的区域作为输入,输出1个低维度的特征(VGG中每一个点是512-d),输出的特征分为box回归层和box分类层。然而原始面积尺度和长宽比被设计适用于PASCAL VOC数据集中的20种大小不同的物体的检测,不适合油茶果图像的检测,因此需针对油茶果图像本身的特点优化面积尺度和长宽比,根据拍摄的油茶果图像的像素面积和长宽比特点,改进面积尺度为8、16、32像素和3种长宽比{1∶2、1∶1、2∶1}。
5 检测结果评价与分析
5.1 模型评价指标
油茶果图像测试结果有下面3种情况:TP,预测为油茶果,实际为油茶果; FP,预测为油茶果,实际为背景; FN,预测为背景,实际为油茶果。
模型评价指标主要用到平均识别率(map)、准确率(P)、召回率(R)和F1值。其中平均识别率是正确识别的油茶果个数占油茶果总个数的比例,其计算公式为:平均识别率(map)=正确识别的油茶果个数/油茶果总数。准确率表征对正样本的预测准确程度,其计算公式为:准确率(P)=TP/(TP+FP)。召回率表示在原始样本的正样本中,最后被预测为正样本的概率,其计算公式为:召回率(R)=TP/(TP+FN)。准确率主要考察模型对目标找得对不对,准不准;而召回率主要考察模型对目标找得全不全。F1值是模型的综合评价指标,它调和准确率和召回率,其计算公式如下:F1=2PR/(P+R)×100%。
5.2 油茶果图像的检测结果
对油茶果数据集进行训练,训练完成后生成权重文件;调用权重文件对油茶果图像进行测试。随机选取不同环境下的100幅500×375像素的油茶果图像进行测试,计算结果如下:
平均1幅图像检测耗时0.21 s,图3为部分检测出来的油茶果图像。
5.3 油茶果识别失败情况统计与分析
为了探究油茶果图像检测失败的原因,对100幅图像中识别失败的油茶果进行了统计分析,得到表1,将识别失败的原因进行分类和统计。识别失败的原因为:果实遮挡占56.6%;油茶果粘连成簇出现占9.4%;树叶或油茶花蕾误识别占13.2%。在正常情况下,未被识别的油茶果占9.4%;油茶果图像较小占11.3%。在图4中,画圈部分为识别失败的油茶果图像。

图3 油茶果图像检测结果

表1 油茶果识别失败原因的分类统计结果

图4 油茶果识别失败的图像
6 多特征提取卷积层可视化
为了直观观察卷积层特征提取的过程,将卷积层多特征提取过程可视化,得到图5卷积层可视化特征图。卷积神经网络在提取特征的过程中,在第一层倾向于提取油茶果的颜色特征等浅层特征;随着卷积层的增加,能够逐渐提取到油茶果的边缘形状特征、纹理特征等;到最后一层能提取油茶果图像的更加抽象的特征。

图5 油茶果特征图的可视化
7 结论
卷积神经网络可自动提取油茶果的多特征并加以识别。本文利用Faster-RCNN卷积神经网络对3820幅油茶果图像进行训练,分别对数据集和锚框参数进行优化,并在100张油茶果图像数据集上进行了验证。检测结果表明:平均识别率为92.39%,准确率为98.92%,召回率为93.32%,F1值为96.04%。平均每幅图像识别时间为0.21 s,能满足油茶果实时检测的要求。
