自适应分箱特征选择的快速网络入侵检测系统
2021-01-29刘景美高源伯
刘景美,高源伯
(西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071)
近来年,随着大数据、工业互联网、物联网等新型技术的发展,安全威胁和网络攻击也随之增多,网络安全面临着新的挑战,安全形势严峻[1]。因此,设计一套能够准确高效识别各种网络攻击的网络入侵检测系统,已成为现如今亟待解决的一个问题。
为提高网络入侵检测的准确率,研究者们在机器学习、深度学习中探索新的算法并将其应用于此[2-6]。然而,这些算法普遍存在训练时间和检测时间较长的问题,针对这一问题,很多研究者利用特征选择[7-14],将原始高维数据降为低维数据,从而减少训练和检测的时间。
文献[15]设计了一种基于多目标优化与logistic回归的封装器,有效提高了准确率,然而,这种算法以logistic回归模型的预测结果为优化目标,每一轮都需要重新训练模型,算法时间复杂度较高,时间较长。文献[16]利用基于信息增益的过滤器与深度学习模型设计的入侵检测系统,准确率相对较高,但是,在特征选择方面,由于入侵检测数据集同时存在连续型和离散型数据,且数据分布不均匀,采用基于信息增益的过滤器算法运行时间相对较长。针对这一问题,笔者提出了一种基于信息增益的自适应分箱特征选择算法,对入侵检测数据集中的连续型数据进行自适应分箱处理,从而降低计算复杂度,提高特征选择阶段的效率。
将提出的自适应分箱特征选择算法与LightGBM集成学习模型相结合,设计了一种快速网络入侵检测系统,在保证较高准确率的条件下大大降低了模型训练和入侵检测的时间。通过在网络入侵检测领域常用数据集NSL-KDD上测试,表明文中算法在准确率和训练时间上均优于随机森林、AdaBoost等现有算法。
1 基于信息增益的自适应分箱特征选择
信息增益是衡量通过得知特征X的信息从而对所要预测类别Y的信息的不确定性减少的程度;通过计算数据集中每个特征相对于类别标签的信息增益,从而得到各特征对预测类别的贡献程度,之后通过选取信息增益较大的特征生成新的特征子集,达到数据降维的目的,进而保证系统在较高准确率的条件下降低训练和检测时间。信息增益的计算公式为
IG(Y|X)=H(Y)-H(Y|X) ,
(1)
其中,H(Y)为数据集中类别Y的信息熵,对于含有n个类别的数据集,Y={y1,y2,…,yn},其计算公式为
(2)
其中,P(yi)为在数据集的所有类别中yi的出现的概率。H(Y|X)的计算为
(3)
其中,m为特征X中的取值个数,P(xj)是特征X为xj的概率,P(yi|xj)是在特征X为xj的条件下类别Y为yi的概率。
对于传统的基于信息增益的特征选择,在计算P(yi|xj)时,要计算特征X取特征值时的条件概率。在入侵检测系统的数据中,同时存在连续型数据和离散型数据,对于取值较少的离散型数据来说,这种计算量并不大,但是对于连续型数据和取值较多的离散型数据来说,这无疑是一个巨大的计算开销。对于一个有m种取值的特征,其时间复杂度为O(m),以NSL-KDD数据集为例,该数据集中的特征“dst_bytes”共有9 326种取值;如果直接对其进行信息增益的计算,那么计算量是很大的,因此,对该特征不同取值进行分组成为了一个必然趋势。然而,由于网络入侵检测数据集中数据分布不平衡的特点,如果直接按数值或样本个数来平均分组,那么分组后的特征无法很好地表示原始特征的分布情况。为此,设计了一种基于信息增益的自适应分箱特征选择算法。
以含有n个样本点的特征X为例,该算法过程如下:
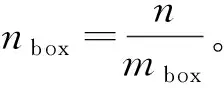
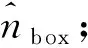
(3)按分箱后的结果将同一箱子中的样本记为同一特征值,计算各特征的信息增益。
这种算法与传统的基于信息增益的特征选择算法结果相近,但运算效率大大提高。这里的时间复杂度由原来的O(m)降至O(mbox),m为特征取值的数量,随训练集中特征取值的变化而变化;mbox是预先设置的分箱数量,为常数。因此,本算法将时间复杂度从传统算法的线性阶降低为常数阶。对于连续值特征,mbox≪m,以分箱数为20的特征选择算法为例,对于NSL-KDD数据集中的“dst_bytes”特征,时间复杂度从原来的O(9 326)降至为O(20),有效降低了运行时间,提高了程序的效率。
2 基于自适应分箱特征选择与LightGBM的快速网络入侵检测系统框架
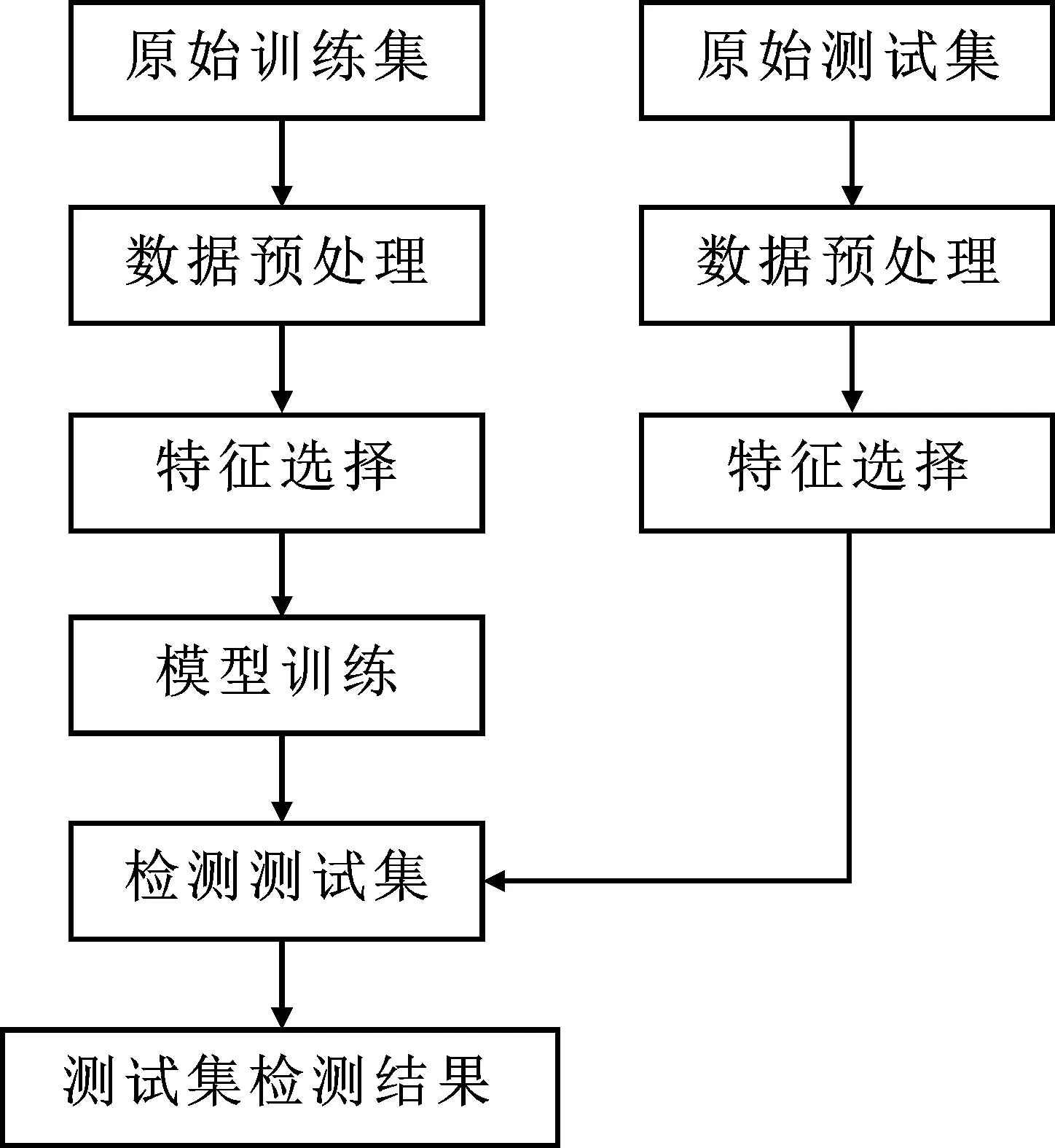
图1 入侵检测系统框架图
设计的基于自适应分箱特征选择与LightGBM的快速网络入侵检测系统整体框图如图1所示。对于原始训练集,首先进行数据预处理,将原始数据集标准化处理并去除无效特征;再通过基于信息增益的自适应分箱特征选择算法,对原始数据集的所有特征按照各特征的信息增益进行排序,选取信息增益较大的n个特征生成维度较低的数据子集;之后利用LightGBM集成学习对特征选择后的训练集进行训练,训练出所需的网络入侵检测模型。在系统性能验证阶段,将对测试集按照之前训练集中相同的预处理和特征选择方法进行操作;之后通过文中的入侵检测系统进行检测;将检测结果与真实结果相对比,从而计算出本系统检测的准确率等性能指标,全面评估本系统综合性能。
2.1 数据预处理
对于原始数据的数据预处理,主要采用了零均值标准化和去除无效特征的方法。
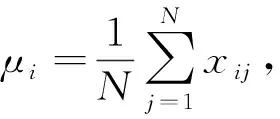
(4)
在去除无效特征阶段,将遍历所有特征,去除特征值惟一的特征。在NSL-KDD数据集中,由于特征“num_outbound_cmds”中所有的特征值均为0,因此该特征无法起到有效预测作用,所以删除该特征。
2.2 基于LightGBM的集成学习模型
LightGBM是一种基于梯度单边采样(Gradient-based One-Side Sampling ,GOSS)与互斥特征捆绑(Exclusive Feature Bundling ,EFB)的梯度提升决策树(Gradient Boosting Decision Tree ,GBDT)模型。针对之前的GBDT模型训练时间较长,且时间消耗主要在于最佳分割点确定上这一问题,LightGBM在决策树的特征选择与分割点确定方面,采用了直方图算法。这种算法将原来连续的特征值进行分箱处理,在之后的训练模型时使用这些分箱结果构建直方图,大大减少了对分裂点选择的时间,提高了训练和检测的效率[17]。
为减少每次迭代过程中样本的数量,并对预测效果不好的样本加强训练,LightGBM引入了GOSS算法。对于经过上一轮训练过后的样本,计算每个样本的梯度。每个样本的梯度可以表示该样本预测的错误程度。为此,通过GOSS算法保留所有梯度较大的实例,对于梯度较小的实例则采取按照一定比例随机采样的策略。
在计算每个样本的梯度方面,设O为决策树中某个固定节点上的训练数据集。定义该节点在点d处分割特征j的方差增益为
(5)
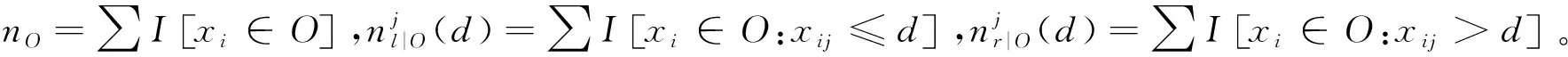
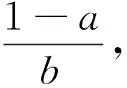
(6)
其中,Al={xi∈A:Xij≤d},Ar={xi∈A:Xij>d},Bl={xi∈B:Xij≤d},Br={xi∈B:Xij>d}。
在网络入侵检测领域,通常情况下数据集是相对稀疏的,因此有些特征会存在互斥特性,即不同时取非零的情况。针对这一情况,LightGBM还引入了EFB对数据中的互斥特征进行捆绑,从而进一步降低模型的计算复杂度。通过EFB可以将多个特征捆绑为一个束bundle,这样就将计算复杂度从原来的O(#data×#feature)降为O(#data×#bundle),从而进一步降低模型在训练和检测阶段的时间复杂度,提高运行效率。
3 实验仿真结果与分析
本实验操作系统环境为Windows 10,电脑硬件cup为i7-5 500 U,8 GB内存,在Python 3.7软件环境中编程实现。设置了特征选择的结果比较实验和整体系统模型的性能比较实验。
3.1 数据集介绍与分析
为有效验证网络入侵检测系统的性能,采用网络入侵检测系统领域常用的数据集NSL-KDD[18]。NSL-KDD数据集分为训练集和测试集,训练集共包括125 973条有效数据,测试集共包括22 544条有效数据。由于本数据集在不同类别样本之间的数量存在不平衡现象,在训练集中对部分少数类别攻击样本进行了随机过采样;之后,随机选取训练集中的90%作为训练数据,10%的数据作为验证数据从而训练模型。最后通过在测试集的检测结果验证本系统的性能。
在特征方面,NSL-KDD数据集中共包括41维特征和1维结果标签,在41维特征中,仅7维特征是离散型数据,其他34维特征均为连续型数据,该数据集数据数值的分布特点符合大多数网络入侵检测领域数据的特点,因此,如果直接对数据集进行基于信息增益的特征选择,则时间复杂度将会很大,严重影响了程序运行效率;而使用文中提出的基于信息增益的自适应分箱特征选择,时间复杂度将大大降低,在保证达到所需特征选择需求的条件下,有效提高程序的运行效率。
3.2 特征选择的结果比较实验
在特征选择性能比较实验方面,首先对提出的特征选择算法与传统基于信息增益特征选择算法进行对比,在NSL-KDD的训练集上进行实验。利用传统的基于信息增益的特征选择算法与分箱数量设置为20的文中算法,在NSL-KDD的训练集上信息增益排名前8的特征及结果如表1所示。结果表明,在信息增益排名前8的特征中,虽然有个别几个特征的顺序不是完全一致,但在排名前8的特征中,所选择的体征种类完全相同,仅存在部分信息增益差距较小的特征出现顺序不一致的现象。这种信息增益大体一致的结果,能够满足选择特征的需求。在运行时间方面,基于信息增益的特征选择运行时间为824.43 s,而笔者提出的基于信息增益的自适应分箱特征选择算法仅用时27.35 s,相比于传统的特征选择算法,所用时间减少了约96.68%,大大提高了程序的效率。

表1 两种特征选择算法结果比较
3.3 入侵检测系统性能比较实验
对于网络入侵检测系统方面的比较实验,首先对基于自适应分箱特征选择算法与LightGBM的入侵检测系统进行仿真实验。在设计的基于特征选择与LightGBM的网络入侵检测系统中,首先需要确定特征选择的数量。由基于自适应分箱特征选择算法计算的信息增益排名结果可以看出,前3个特征的信息增益均在0.28以上,远高于其他特征,且前8个特征的信息增益均大于0.1。为此,将主要研究选取前3个特征和前8个特征的特征子集。为全面研究不同特征的预测结果,并验证选取3个特征和8个特征的准确率情况,在利用自适应分箱算法计算的信息增益的排序结果中,按照排序顺序依次选取不同数量的特征进行实验。不同的特征选择在LightGBM分类器下的准确率如图2所示。由图可知,当选择特征数量大于3时,在验证集的准确率已经很高且趋于平稳。在测试集中,选用3个特征时准确率也相对较高;在选择特征数量为8时,验证集中已经处于较高的平稳水平,在训练集中准确率也相对较高。可以看出,选用3个特征和8个特征两种情况性能表现相对较好。
为进一步研究不同迭代次数时,选取的3个特征和8个特征的数据子集与原始数据集的性能情况,分别在验证集和测试集中对文中算法进行仿真验证。在验证集和训练集中,不同迭代数量的准确率结果分别如图3和图4所示。由图3可知,迭代次数在100到200之间,在验证集中的准确率大幅提升,当迭代次数大于200时,3种情况的准确率均提升缓慢,特别是当迭代次数大于500时,准确率曲线趋于平稳。为保证系统能够在保证较高准确率的条件下实现快速网络入侵检测,选取迭代次数为650。3种情况的详细性能比较如表2所示。
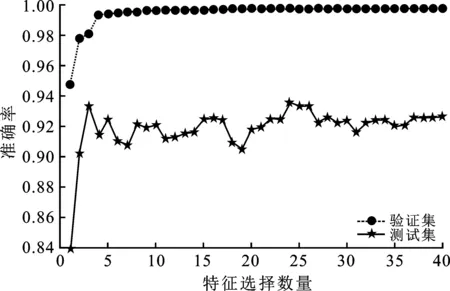
图2 不同特征准确率折线图
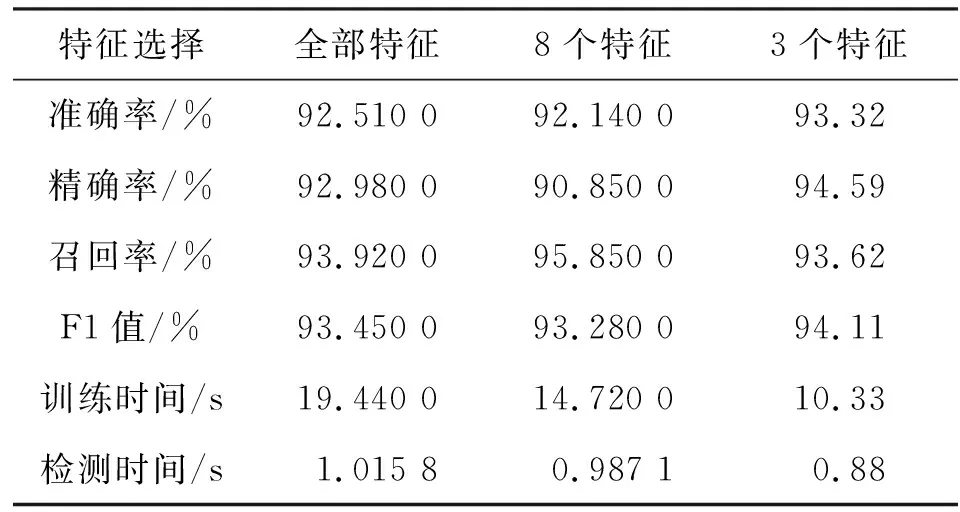
表2 不同特征性能对照表
在图3的验证集中,虽然原始数据集的准确率始终保持高于其他两种情况,但是在图4的测试集中,通过特征选择的3特征数据子集准确率整体高于其他两种情况,这与3个特征集中的特征有关。原始数据集存在大量的冗余和噪声,在验证集中,通过多次迭代优化,会引导模型趋于有效区分验证集中攻击和正常样本的方向训练。然而,此时所选取特征和特征值的划分点很有可能只满足验证集的数据分布特点而不满足整体数据集,这将导致模型过拟合;虽然在验证集上的准确率很高,但泛化能力不强。而选用的3特征数据子集,三个特征的信息增益远高于其他特征。这三个特征与类别标签的相关性较强,能够为检测类别提供可靠依据,以及为入侵检测系统有效区分攻击和正常流量提供可靠保证。

图3 验证集准确率迭代曲线图
通过表2中对三种情况的详细性能指标对比,选用3种特征的数据子集在准确率和F1(精确率和召回率的调和函数)值这两个核心指标上均优于其他两种情况。特别是在训练和检测时间上,选用3种特征的数据子集的训练时间仅约为原始数据集时间的一半,大大提高了模型训练效率,且测试时间也均少于其他两种情况,缩短了模型训练和入侵检测的时间。
为进一步评估文中设计的网络入侵检测系统的综合性能,还设置了多种预测模型的综合对比实验。引入了现有网络入侵检测的主流算法K近邻(K-Nearest Neighbor,KNN)、决策树(Decision Tree ,DT)、Adaboost、随机森林(Random Forest ,RF)、支持向量机(Support Vector Machine ,SVM)、GBDT和XGBoost。将上一组实验中表现性能最好的选用3个特征的LightGBM模型与这些算法进行详细的对比分析,各算法详细的性能表现如表3所示。
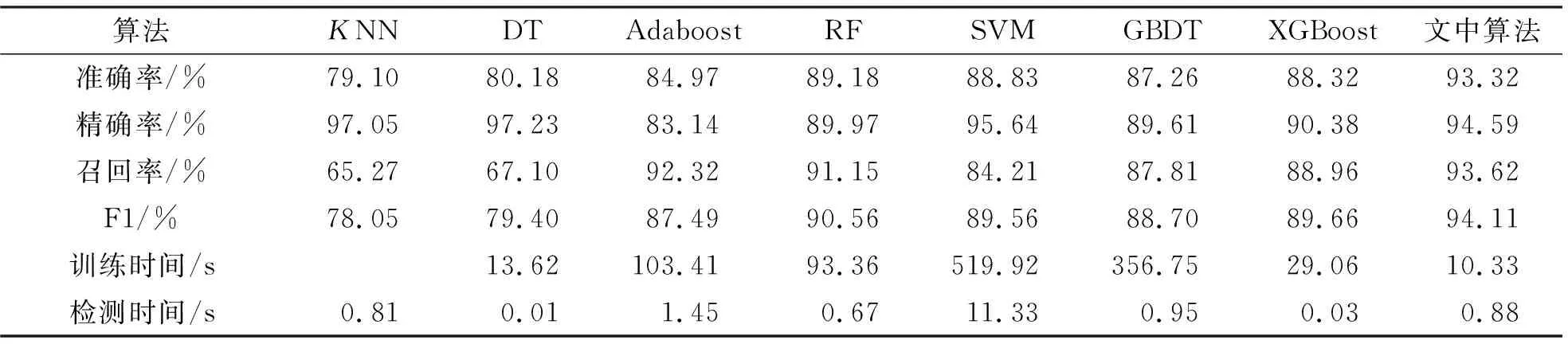
表3 不同入侵检测模型性能对比表
对于网络入侵检测系统来说,准确率和F1值是评判系统整体性能优劣的主要标准。在这两个指标的比较中,笔者提出的基于特征选择与LightGBM的入侵检测系统均优于其他算法。在精确率方面,KNN和DT两个算法相对较高,但是其召回率较低,如果将其应用于实际网络入侵检测环境中,将会对网络系统造成很大的损失。在训练时间方面,笔者设计的入侵检测系统的训练时间均小于除KNN外的其他算法(KNN无需学习新的模型),能够实现模型的快速训练。对于利用多种单一模型的集成学习来说,在提高准确率的同时会延长模型训练和检测时间。Adaboost和随机森林虽然在准确率方面较单一模型有所提高,但是其训练时间过长。对于SVM来说,由于其计算的复杂度较高,虽然准确率相对较高,但是其训练和检测时间过长,难以部署在实际场景中。通过以上性能对比分析,无论是在检测的准确率还是模型的训练时间方面,文中所述算法整体性能优于其他现有算法。
4 结束语
与传统基于信息增益的特征选择算法相比,笔者提出的基于信息增益的自适应分箱特征选择算法在保证结果与之前算法相近的条件下,大大降低了时间复杂度,速度更快。在NSL-KDD训练集的实验中,与传统算法相比,本算法时间缩短了约96.68%。笔者设计的基于自适应分箱特征选择与LightGBM的快速网络入侵检测系统,准确率更高且模型训练速度相对较快。通过在NSL-KDD数据集上的实验结果可知,该系统的准确率高达93.32%,且训练时间仅为10.33 s,对于22 544条的测试集样本,检测时间仅0.88 s,可用于网络入侵检测场景。未来,将进一步探索入侵检测领域各特征之间的潜在关系,研究更好的降维方式,在较快速度的同时,进一步提高入侵检测系统的准确率。
