基于政策文本量化的国家间专利制度距离研究及实践
2021-01-29徐英祺刘裕茵
徐英祺 刘裕茵
(1. 中国科学院成都文献情报中心 四川成都 610041;2. 电子科技大学经济与管理学院 四川成都 610054)
海外知识产权制度研究是海外知识产权风险研究的重要组成部分。随着“一带一路”倡议的提出,我国在沿线国家的专利公开和授权公告数量均保持增长,2018年全年在沿线国家的专利申请公开数已超6 000件,公告数超3 000件。因此,研究这些国家与我国专利制度之间的差异性或者专利制度距离,对于我国在相关国家的知识产权风险防控具有重要意义。
目前,我国已经与130多个国家和国际组织签署了“一带一路”合作文件。由于国家和国际组织数量众多,给海外知识产权战略制定者的决策判断造成了一定的困难。传统的国家之间的专利制度差异研究主要侧重于母国与目标国的具体专利制度文本的对比研究,虽然能够详尽而完整地挖掘国家之间专利制度的不同点,但是对于多个国家的对比研究而言,这种方法显然效率较低,且对分析者的国际知识产权法律素养要求较高。因此需要开发一种能够同时、高效地针对多国专利法律制度开展对比分析,且对分析者的知识产权法律知识要求相对较低的研究工具和方法。
政策量化分析为同时对比研究大量国家的专利制度提供了一种方便高效的研究工具。早在上世纪90年代,研究者就开始了针对专利制度量化的研究。Rapp等(1990)提出了以美国知识产权制度为最高标准的RR指数[1],这个指标仅考虑某个国家是否建立了与美国知识产权制度相似的法律制度,分级也简单分成6级(0~5分),主观因素较多,容易影响分级结果。Ginarte和Park等(1997)在RR指数基础上提出了一种新的知识产权制度量化模型(Ginarte-Park模型)[2−3],该模型从保护范围、参与国际条约、无侵害条款、执行机制和保护期限5个维度,通过17个量化指标,对于一个国家的知识产权制度进行量化描述,除了保护期限以外,其他的16个指标数值均为布尔值,即用1或0表示该指标的属性。在得到各指标的数值后,通过对指标的加权加和获得“知识产权指数”,以该指数衡量一个国家的知识产权保护水平。该指数被广泛应用于与知识产权量化相关的研究计算,以及国与国之间的知识产权制度距离比较。
Ginarte-Park模型在应用过程中也暴露了一些缺陷。韩玉雄等(2005)已通过实证研究证明了该模型的知识产权指数被用于评价中国知识产权保护水平时会产生一些违背一般认知的分析结论,如1990年中国的知识产权保护水平就超越了部分发达国家[4]。基于此部分知识产权制度距离的相关研究也选择回避使用Ginarte-Park模型,转而使用不涉及制度文本内容本身的国家间知识产权距离模型,例如基于国外申请人在本国专利申请量的知识产权距离模型[5−6],该模型是更广义上的知识产权距离模型,而非知识产权制度距离模型。后续虽然有基于Ginarte-Park模型的改进[7−8],但基本都局限在构造类似于“知识产权指数”的综合专利评价指数的框架中,采用类似的绝对指数的差值来评价国家间专利制度差异,会产生和使用Ginarte-Park模型进行专利制度差异评价类似的问题。为了解决绝对指数所带来的认知悖论的问题,需要提出一种非依靠绝对指数参照系的相对专利制度距离的计算方法。
本文借鉴Ginarte-Park模型对制度指标量化处理的思想,在其基础上通过优化指标体系,即引入知识产权制度灵活性数据库中的相关指标,对指标体系进行重构,丰富了指标内容,使指标体系能更加详细、准确地对专利制度特征进行描述。此外,还对Ginarte-Park模型的指标后续处理方法进行改进,回避其构造综合“知识产权指数”的缺陷,提出基于制度文本内容差异本身的国与国之间相对专利制度距离计算方法。量化研究目前已被应用于“一带一路”沿线国家的制度差异分析[9],本文的实证研究也选择 “一带一路”部分沿线国家的专利法律文本为样本,通过提出的新量化模型和相对专利制度距离的计算方法,研究我国与“一带一路”沿线国家专利制度的差异。
一、研究数据来源
研究多国法律文本信息,面临的最大问题是语言障碍和法律专业知识障碍。由于各国的专利法律均由本国母语或官方语言著成,在不经过翻译形成统一语种文本的情况下是无法使用共词分析等研究方法对文本信息开展研究的。同时,因为涉及专利法律文本的海量性、专业性、语种丰富性,准确翻译全部国家的专利法律文本具有相当的难度。
本研究选择知识产权制度灵活性数据库(Database on Flexibilities in the Intellectual Property System)[10]作为数据来源。该数据库是全球知识产权法律信息数据库WIPO Lex 的子库,由世界知识产权组织(WIPO)根据各WIPO成员国在CDIP第六届会议上的决议进行牵头建设,保证了数据的权威性和有效性。同时,该数据库法条信息均由PDF抽取转换成文本格式,由专业法律人员翻译成英文、法文等少数的WIPO工作语言,支持结构化检索。更加便利的是,该数据库构建了14个维度,包括强制许可与政府使用(Compulsory Licenses and Government Use)、侵权的刑事责任(Criminal Sanctions for Patent Infringement)、信息披露相关的灵活性(Disclosure Related Flexibilities)、植物发明的可专利性(Exclusion from Patentability of Plants)、权利用尽(Exhaustion of Rights)、知识产权局依照职权对许可协议中反竞争条款的管制(Ex-officio IP Office Control of Anti-competitive Clauses in Licensing Agreements)、自然界现存物质的可专利性(Patentability of Substances Existing in Nature)、软件相关发明的可专利性(Patentability or Exclusion from Patentability of Software-related Inventions)、药品监管审查例外(Regulatory Review Exception)、科学研究例外(Research Exception)、国家安全例外(Security Exceptions)、实质性审查(Substantive Examination)、药品专利的过渡期(Transition Periods)、实用新型(Utility Models)。
通过14个维度及其涵盖的50余项指标来描述各国专利法律制度的灵活性。该数据库的数据形式属于结构化与半结构化数据交杂,绝大部分指标通过简单的“是”或“否”来描述一个国家专利法律体系对于相关专利问题的态度,如强制许可与政府使用维度下的非实施专利的强制许可、从属专利强制许可、为纠正滥用专利权的强制许可、为公共利益的强制许可、政府使用的强制许可等指标均采用该形式对具体国家的专利制度在专利强制许可和政府使用方面的规定进行描述;少数维度和指标,如实用新型维度及其包含的3项指标,通过简单的非结构化的短句对指标内容进行描述。知识产权制度灵活性数据库极大地便利了对多国专利文本信息开展量化处理与分析研究工作。相比仅含17个量化指标的Ginarte-Park模型,灵活性数据库提供了更加全面的评价一个国家专利法律制度的指标集。
二、研究方法
(一)专利制度量化模型的构建
知识产权制度灵活性数据库为实现多国专利法律文本的量化分析起到了数据支持的作用。然而,要实现专利法律文本的量化分析,依然需要思考与解决以下问题。第一,知识产权制度灵活性数据库中的部分数据为半结构化数据,即在对指标内容的描述中,采用了大段的定性描述语言,而非具体数值或符号,需要将这些定性内容进行转化,以实现内容的完全量化。第二,法律文本较专利文本具有更强的情感色彩,即对于具体议题的态度倾向,是许可还是禁止,这些情感倾向正是海外专利战略制定者和决策者所需要获得的信息内容。第三,各国专利法律所调节的议题对象,具有一定的相似性,如都会讨论“什么不能被授予专利” “哪些情况不视为侵权”等。因此,对法律文本分析更加重视对于上下文、语义和情感的分析,而不是简单的关键词词频统计。
专利制度灵活性数据库的维度和指标十分丰富,但在构建专利法律制度特征的量化指标体系时,除了要考虑指标内容量化处理的问题,还要针对维度和指标设置的合理性与科学性问题进行分析,需要对现有专利制度灵活性数据库的维度、指标特点及问题开展分析,优化指标体系结构,以使其能更加准确、精炼地描述各国的专利制度特征。
专利制度灵活性数据库的维度、指标设置存在以下三个问题。第一,维度和指标过于分散,对于描述的法律概念不够聚焦。例如灵活性数据库对于我国《专利法》第75条所涉及不视为侵犯专利权情况这一概念用了权利用尽、药品监管审查例外(BOLAR例外)、科学研究例外等多个维度进行描述,同时这些维度下指标相对较少。因此,从维度、指标精炼化的角度考虑,将这类灵活性数据库中相对分散的维度、指标,通过三个新的维度概念,即“不视为侵犯专利权情况”“不授予专利权的情况”“相关信息披露”进行整合。
第二,指标描述的内容过于特殊化,且存在概念交叠。由于专利制度灵活性数据库是针对世界范围内各国专利制度的普适性指标,因此考虑了少数国家的可能影响专利制度灵活性的情况,部分维度是针对这些国家专利制度灵活性的特殊描述。如药品专利的过渡期这一维度,针对的是印度等少数几个在专利制度中仍保留药品专利过渡期表述的国家,对绝大多数国家而言,药品专利过渡期是一个历史概念或者从未设置过。同时,专利制度是否承认药品过渡期与灵活性数据库中“强制许可与政府使用”维度下的“是否含有执行《关于实施TRIPS协议与公共健康的多哈宣言第六段的决议》的分别规定”指标有较强的相关性,即不承认该决议的国家一般设置有药品过渡期,因此可以删除药品过渡期维度,整合进关联指标之中。
第三,部分指标与国家内部的专利制度关联性不强。如“是否为PCT协议成员国”,该指标涉及法律为国际条约《专利合作条约》,而非具体国家的专利法,且该条约更多地涉及专利国际申请流程的简化,对具体国家的专利法律制度的影响不强,不像《关于实施TRIPS协议与公共健康的多哈宣言第六段的决议》这类国际条约会对国家内部的专利制度造成一定的影响,故将这类与国家内部专利制度关联性不强的评价指标剔除。
基于上述思考,对WIPO专利制度灵活性数据库所展示的维度和指标进行了调整,构建能够反映各国专利法律制度特征的量化指标体系。由于法律文本对待具体问题的态度一般是清晰而明确的,因此,参考Ginarte-Park模型指标体系的处理方法,将灵活性数据库中各指标的内容转化成二元判断问题。这样做的目的是将讨论不同议题的专利法条信息,转换成若干个判断问题,使反映法律文本特征的指标内容最终能够以布尔值的形式呈现,这种量化处理的方式为后续的信息处理与文本相似性分析计算提供了支撑。
完成上述量化处理后,最终形成了包含“强制许可与政府使用”“专利侵权的刑事责任”“相关信息披露”“不授予专利权的情况”“不视为侵犯专利权情况” “国家安全相关的专利申请”“实质审查”等7个维度、37项指标的专利法律文本量化指标体系,每个指标所对应值仅包括“是”(1)和“否”(0)两种情况,详见表1。
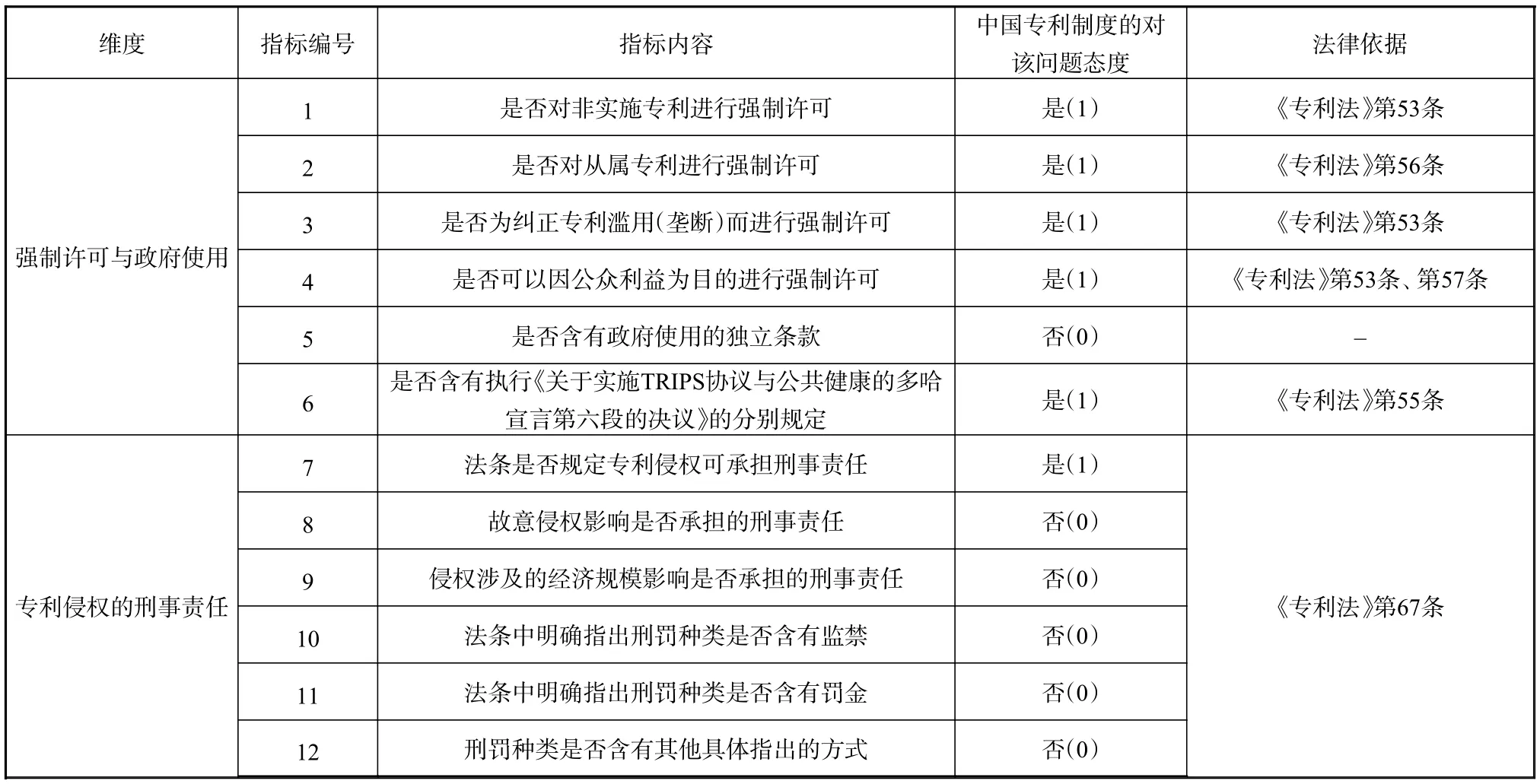
表1 专利制度量化指标体系

续表 1
不同于现有对于专利法律制度或知识产权保护水平进行量化或测度的研究,本文构建的指标体系中并不用于计算绝对的综合“知识产权指数”来评价一个国家知识产权水平的高低。政策量化的指标能否用于主观性较强的知识产权保护水平高低的评价是一个值得商榷的问题,因此在使用这些指标进行专利制度差异性分析时需要回避这个问题,指标是用于研究国家间具体专利制度的差异,而不去衡量知识产权保护水平的高低。
(二)基于空间向量相似度的专利制度距离的计算
借鉴自然语言处理中文本向量化的思想,构造空间向量Pi作为代表一个国家的专利法律文本的特征向量。以xi1,xi2,···,xin(n=1,2,···,37)作为反映专利制度文本特征的指标,则有:

采用曼哈顿距离dab来反映A、B两个国家专利法律制度Pa与Pb之间的差异。曼哈顿距离越大,则两者的差异性越大,制度距离越远。

为了方便后续计算和比较,可对制度距离进行归一化处理,A、B两个国家专利法律制度距离可以表示为:

Dab的值越小,说明Pa与Pb的相似性越高,A、B两个国家专利法律制度距离越短。当n=37时,反映的是各国专利法律制度整体的相似性。同时,也可以选择部分的特征指标来反映各国专利法律在某个维度上的相似性或者关于某个主题制度的相似性。
相较基于Ginarte-Park模型及其衍生模型的专利制度距离计算方法,本模型方法不用对各指标进行加权加和来计算评价知识产权发展水平的“综合知识产权指数”,而是以空间向量的形式,对各指标所展示的制度内容的相似度进行计算,直接得到相对的专利制度距离。不仅计算过程更简洁,同时也规避了基于“综合知识产权指数”计算得到的专利距离所带来的问题。同时,由于本模型方法计算得到专利制度距离是直接基于指标内容的相似计算的,因此可以灵活地对计算采用的指标进行选择,以从整体或者局部主题、维度来分析专利制度的相似性。
三、“一带一路”沿线国家专利法律制度差异性分析实证研究
(一)“一带一路”沿线国家与我国专利法律制度距离研究
实证研究选择东南亚、南亚、中亚和北亚、西亚和北非、中东欧、东南欧等六个地区的“一带一路”沿线63个国家的专利法律文本作为研究对象。采用专利法律文本量化指标体系模型,对于中国与63国的专利法律文本信息进行量化处理,将各国的专利法律文本转化成37个二元特征指标,并以此为基础构建各国的专利法律文本的特征向量,再进行特征向量的相似性计算,最终得到以中国专利法律制度为基准,其他63个国家专利法律制度与中国专利法律制度的相似度。
如表2所示,与中国专利制度相似度排名前三的国家分别为马来西亚、菲律宾、越南,与中国专利制度距离分别为 0.22、0.24、0.27。

表2 中国与“一带一路”沿线国家的专利制度距离
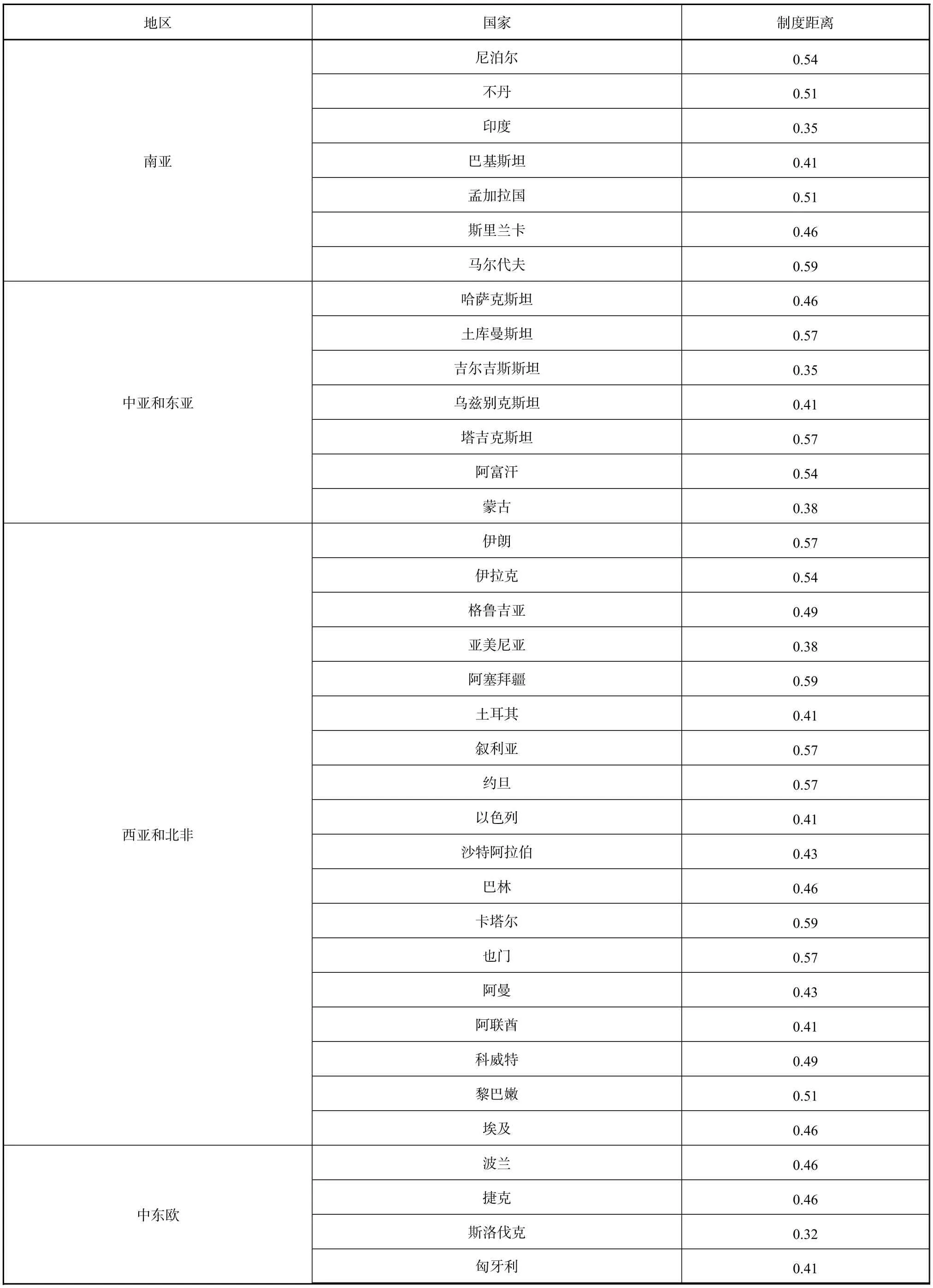
续表 2
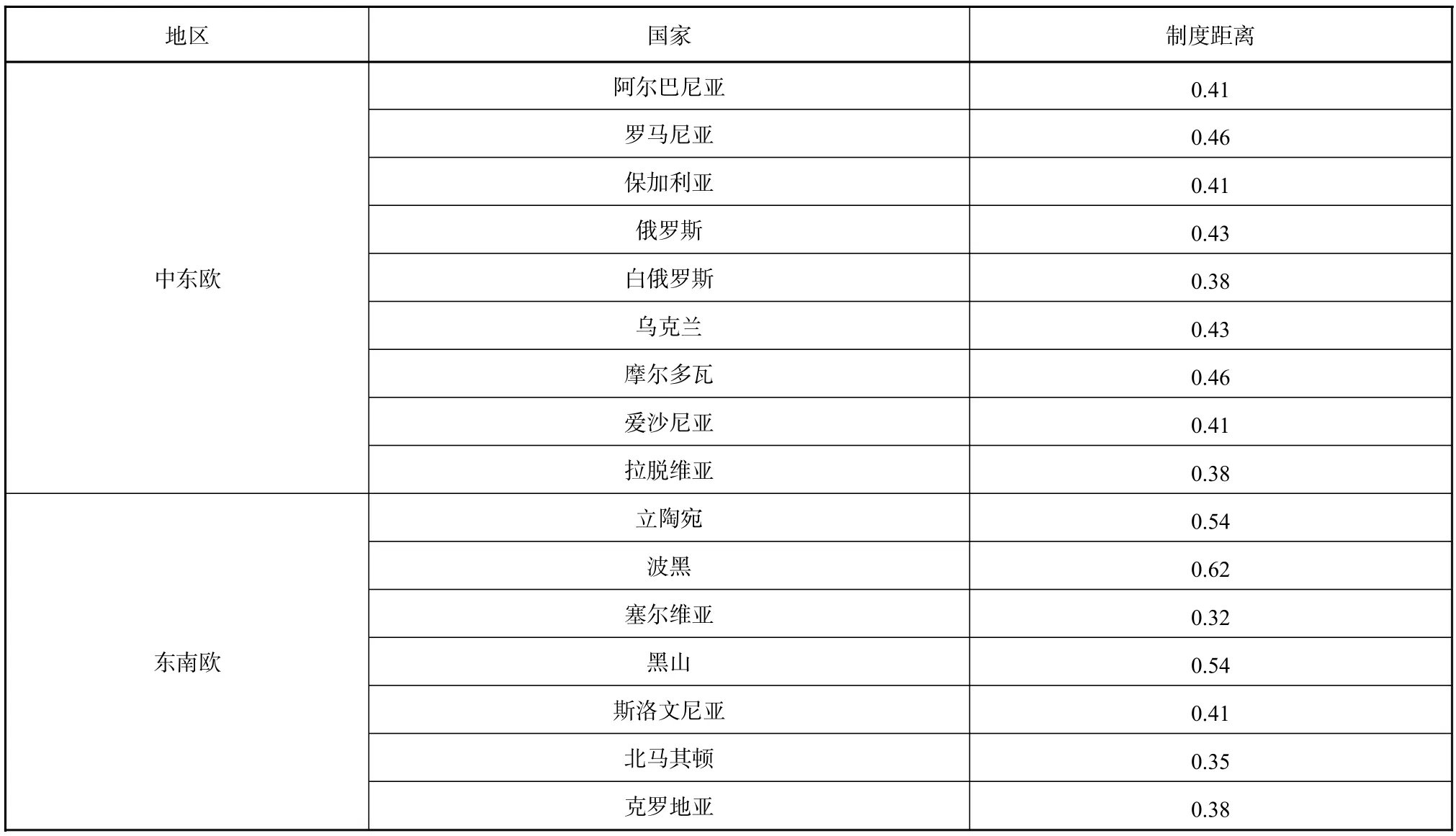
续表 2
结合表2和图1,63个国家的专利法律制度与中国专利法律制度的制度距离处于0.22~0.62之间,算术平均数为0.46,标准差9.29%,离散系数0.17。表3显示了中国专利制度与六个地区多个国家专利制度平均相似度情况。其中,中东欧国家的专利制度与我国的平均相似程度最高,且离散系数最小,说明该地区各个国家的专利制度基本都与我国的专利制度差异性较小。东南亚和东南欧虽然平均相似度较高,但离散系数较大,说明两极分化比较明显,一些国家与我国的专利法律制度相似性很高,如马来西亚、塞尔维亚等,而另一些则相对较低,如东帝汶、波黑等。
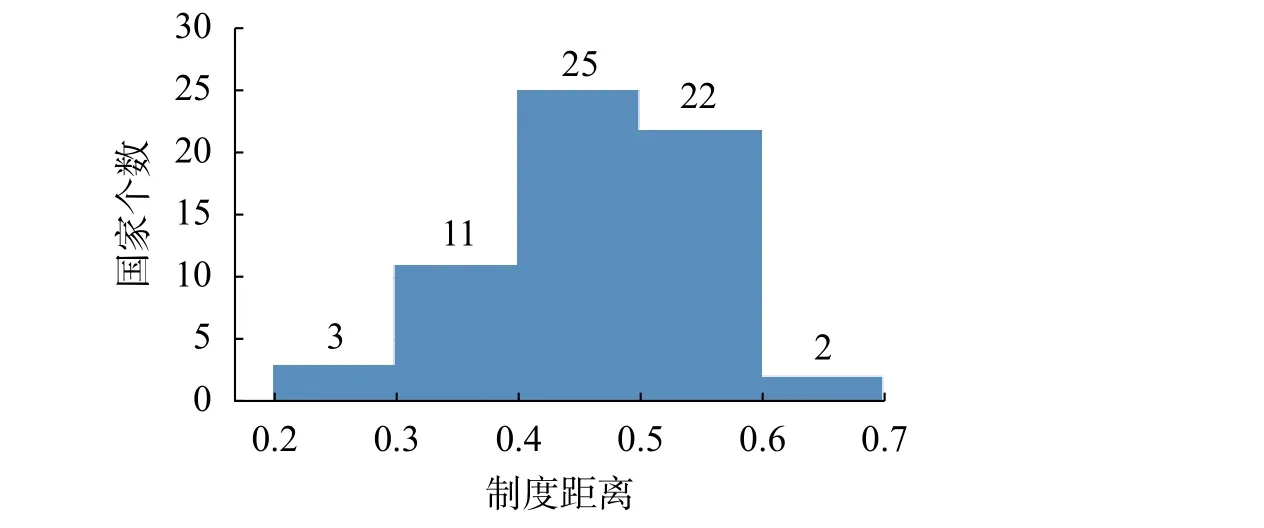
图1 中国与“一带一路”沿线国家的专利制度距离分布
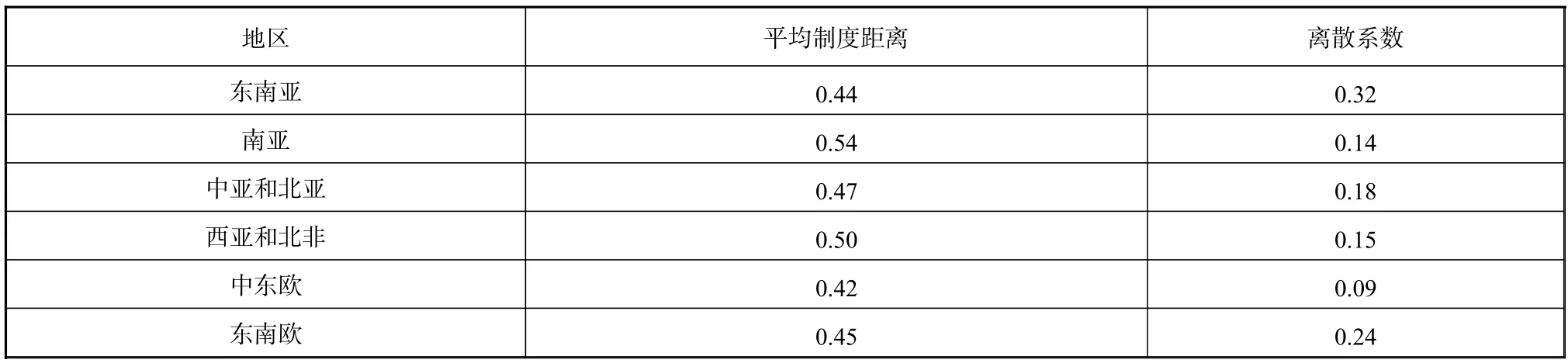
表3 中国与“一带一路”沿线地区的专利制度平均距离
(二)可视化的多维度视角下专利法律制度差异研究
东盟是“一带一路”沿线国家中与我国合作最紧密、经贸往来体量最大的地区,我国在该地区的知识产权保护重要程度不言而喻,因此有必要针对东盟十国与我国专利制度在不同维度下的差异情况开展具体的分析。图2的热力图显示了东盟十国在各维度和指标方面与我国的相似与差异情况,深色表示该国对于相应指标所讨论的专利制度议题与我国有着一致的态度,反之,浅色则代表态度相反。

图2 中国与东盟十国的专利制度差异热力图
研究发现与我国专利制度差异较大的国家有印度尼西亚、文莱、老挝、缅甸、柬埔寨等国。在专利强制许可和政府使用方面,缅甸、柬埔寨与我国专利制度的相似性较低。在专利侵权的刑事责任方面,马来西亚的专利制度与我国的专利制度在该维度下有着高度的一致性,菲律宾和新加坡的专利制度除了在“故意侵权影响是否承担的刑事责任”这一议题与我国专利制度有着不同态度以外,其它议题方面与我国专利制度的态度一致。在相关信息披露方面,东盟诸国各有2~3个议题与我国持相反态度,除了印度尼西亚的专利制度要求必须指明遗传资源的来源外(与我国一致),其它东盟国家的专利制度未强制要求披露遗传资源的来源。在不授予专利权的情况方面,印度尼西亚与我国专利制度的相似度较低。在不视为侵犯专利权情况方面,文莱、老挝、缅甸、柬埔寨在全部指标,即权力用尽规则、科学研究目的豁免、BOLAR例外等三个方面与我国专利制度完全不同,具体分析这些国家的文本后发现,是因为以上各国的专利法律中缺乏对于不视为侵犯专利权情况的规范描述。在国家安全相关的专利申请方面,仅菲律宾、泰国、文莱的专利制度认为政府推广使用可以适用于涉及国家安全的专利,与我国专利制度对此的态度一致。在实质审查方面,文莱、缅甸与我国制度差异较大。
我国企业和个人在上述国家进行科技与经贸活动时,应当从宏观层面了解部分东南亚国家的专利制度环境与我国差异较大的事实,尤其需要关注差异明显且与自身利益较为相关的维度部分,如不授予专利权的情况、不视为侵权的情况。对这些国家相关专利制度开展深入调研,邀请国际法专家对于特定国家相关维度的专利法条进行更为详细的解读,以达到知识产权风险防控的目的。
本研究利用政策文本量化的方法,在知识产权制度灵活性数据库所构建的专利制度灵活性评价指标的基础上,对维度和指标进行了改进与优化,提出了由7个维度,37个指标构成的专利法律制度特征量化指标体系。采用构建特征向量的方法,对于一个国家的专利法律制度进行了向量化处理,并利用向量相似度计算的方法,提出了国家间的专利制度距离的计算规则。
相较Ginarte-Park模型及其衍生模型的专利制度距离的计算方法,基于政策量化和空间向量相似度计算的专利制度差异性分析法可以快速而直观地提供更多宏观层面的信息,能更直观简洁地开展多个国家或地区之间的制度差异性对比分析以及制度距离的计算,同时,又能够进行具体维度、主题的制度内容的多国横向对比,对制度差异造成的具体风险点进行预警。由于是基于制度文本内容差异本身的相对制度距离的计算方法,因此规避了传统Ginarte-Park模型及其衍生模型带来的认知悖论的问题。
利用本指标体系和计算方法,对于“一带一路”沿线国家的专利制度与我国专利制度的差异情况开展了宏观层面的分析,计算并分析了“一带一路”沿线国家与我国专利法律制度距离,比较了不同国家、区域与我国的专利制度距离分布差异。以沿线国家中与我国经贸往来体量最大的东盟的10个成员国家为研究对象,通过可视化的热力图,对于东盟国家与我国的专利制度在不同维度下的差异情况开展分析,为我国在东盟国家的科技与经贸活动提供了有效的专利制度环境的情报支持。
