融合语言特征的反讽文本识别模型研究*
2021-01-26白晓雷霍瑞雪
白晓雷,霍瑞雪
(国家计算机网络与信息安全管理中心河北分中心,河北 石家庄 050000)
0 引言
近年来,随着自媒体的迅速发展,微博等自媒体平台每日产生了大量网民发布的信息及其评论,对其进行情感分析具有极高的价值。目前,反讽识别的研究还主要集中在英文短文本方面,而中文的反讽识别研究仍处于探索阶段,且目前常见的微博文本情感分析主要用于区分积极、中性以及消极等,对于反讽这一特殊修辞手法的研究相对较少,而实际上反讽语句在全部微博文本中已经占有一定的比例。因此,本文基于微博数据对中文反讽识别进行研究。
1 反讽识别研究现状
国外Burfot 等研究人员主要通过使用词袋法来进行反讽识别。Konstantin 等研究人员[1]在各种分类模型下结合各种反讽特征进行研究,实验结果表明人工选取的特征在提高准确率的同时降低了召回率,加入词袋模型问题得到解决。国内山西大学卢欣等研究人员[2]基于深度学习的方法对中文反讽识别进行了研究。
2 微博反讽语言特征分析
通过对微博常见反讽语言进行汇总和分析,本文提炼了微博反讽语言的主要特征。
(1)固定搭配,如“很好……又”,例子“很好,又拒绝了一个”。
(2)特定副词,如“真有你们的”,例子“想了半天,都懒得骂了,只能说真行,真有你们的,不愧是你们”。
(3)特定的语气词,如“呵呵”等,例子“雪梨直播间卖的卫衣是假货,还删评论,呵呵,网销第一是这样来的”。
(4)网络梗。微博的用户以年轻人为主,含有大量年轻人熟知的网络梗,如“他一直是可以的”等。
3 模型训练及其结果
本文使用的模型主要思路如下:
(1)采集到包含一定数量反讽语句的数据集并对其进行标注,反讽为1,非反讽为0;
(2)人工选取反讽语句中常见的特征,并对这些特征进行卡方计算,选择分值较高的特征作为模型使用的语言反讽特征;
(3)将数据集中的语句使用词嵌入向量技术进行向量表示,生成词袋模型;
(4)将反讽特征使用嵌入向量技术进行向量表示,并与上一步的词袋模型相结合作为训练集,分别使用支持向量机、朴素贝叶斯、随机森林进行训练(即融合语言特征的反讽文本识别模型)得出结果并进行对比。
3.1 数据采集
目前,公开的达到一定数量的微博反讽数据集几乎不存在。因此,本文前期爬取了6 万余条微博的数据,包括评论内容、用户名、发表时间以及点赞数等相关信息。为了保证数据集中反讽文本所占的比例,本文以“NBA 复播”“春晚微吐槽”等话题和“好就好在”“把我牛逼坏了”等关键词作为重点爬取了涉及到的全部数据,部分结果如图1 所示。经过数据清洗后共40 000 余条,之后人工对其进行标注。标注方法仅区分反讽与非反讽(反讽标1,非反讽标0),不区分积极、中性以及消极等情感。标注完成后,统计其中有2 000 余条非重复的反讽语句。本文从反讽语句与非反讽语句中各抽取2 000条共4 000 条作为数据集。
3.2 特征选择
在文本分类中,特征的提取是核心内容。特征选择的质量直接影响分类性能,因此本文选择使用卡方检验[3]的方式进行特征选择。卡方检验是通过对特征进行打分后排序,最后选择排名靠前的特征来表示文本。

图1 爬取数据部分结果
卡方检验公式:

针对反讽数据集进行深入分析,人工提取了若干个特征,再通过计算这些特征卡方值得到的TOP5 如表1 所示。

表1 特征卡方统计值
3.3 词嵌入向量
词嵌入向量是指把一个词映射到成一个实值向量空间的过程。由于计算机无法直接对文本进行训练,因此需要将文本转化为词向量。目前,常用的词向量训练模型主要有CBOW 模型与skip-gram 模型。本文选择skip-gram 模型用于训练词向量。
skip-gram 即根据文本中心词预测前后m个词的概率,通过在一定规模的语料库中训练,得到一个从输入层到隐藏层的权重模型。该模型的目标是最大化文档的后验概率:
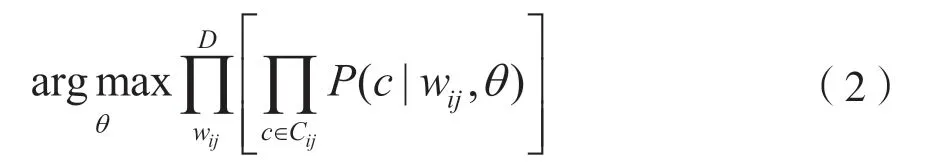
3.4 分类器选择
分类器分别采用支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayesian,NB)和随机森林(Random Forest,RF)。
3.4.1 支持向量机(SVM)
支持向量机(SVM)是一种有监督分类算法,分为线性可分与线性不可分,在分类问题中应用效果较好。
SVM 可以将数据从低维空间通过映射转变到高纬度空间中,选择核函数(核函数一定得满足Mercer 条件)进行求解,如:
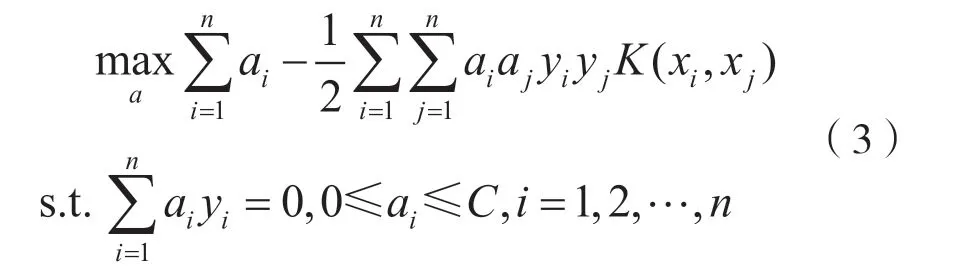
式中,K(xi,xj)表示核函数,最终分类函数为:
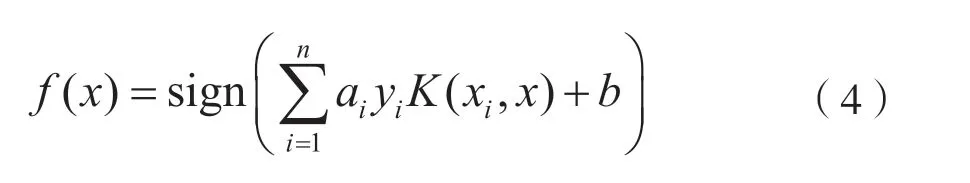
3.4.2 朴素贝叶斯(NB)
朴素贝叶斯算法的基本思想:对于需要分类的文本,求解在此文本出现的条件下各个类别出现的概率,最大概率的类别即为分类结果。基本步骤[4]如下:
(1)假设样本空间N={N1,…,Nd}共包含d个需要进行分类的样本,经过特征选择得到X={X1,…,Xk}共k个相互独立的属性集C={C1,…,Cm};
(2)根据贝叶斯公式:

3.4.3 随机森林(RF)
随机森林由很多无关联的决策树构成,相较于单棵决策树避免了过拟合问题,经常被用来处理分类与回归问题。在处理分类问题时,森林中的每棵决策树分别对新样本进行类别判断,被更多决策树选择的类别作为随机森林的最终分类结果。
随机森林算法步骤[5]如下。
(1)随机选取n个文本,θw为这些文本组成的词变量的集合。
(2)使用这n个文本构造决策树,h(χ,θw)为决策树,χ为预测样本。
(3)重复步骤(1)和步骤(2)构造m棵决策树:

(4)每个决策树分别对新样本进行类别判断,被更多决策树选择的类别作为最终结果。
随机森林的边际函数为:
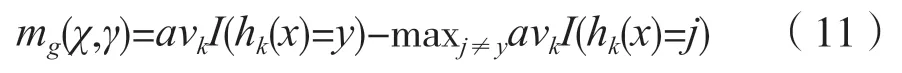
3.5 训练结果
融合反讽特征前后的词袋模型训练结果对比如表2 所示,反映了融合微博反讽特征的词袋模型相较于未融合微博反讽特征的词袋模型,反讽识别准确率和召回率均得到了一定改善。

表2 融合反讽特征前后训练结果对比
4 结语
本文主要研究了融合微博语言特征的词袋中文反讽识别模型,使用支持向量机(SVM)、朴素贝叶斯(NB)和随机森林(RF)等分类器进行训练,整体比单独使用词袋模型进行反讽识别的准确率有了显著提升。为进一步提高反讽识别准确率,在后续工作中考虑进一步扩充反讽训练集,并使用融合语言特征的卷积神经网络进行训练,最终形成一定数量的反讽语料库。
