基于优化融合的卷积网络显著目标检测*
2021-01-26马杉杉彭来献
马杉杉,彭来献
(中国人民解放军陆军工程大学,江苏 南京 210007)
0 引言
图像显著性研究的主要任务是让计算机视觉系统能够模拟人类的视觉能力检测并分割出一幅图像中最吸引人注意力的目标,被广泛应用于各种计算机视觉任务。显著性目标检测算法分为传统的显著性检测算法和基于深度学习的显著性检测算法两类。前者依赖于手工制作的基于颜色、强度、形状以及纹理等图像的基本特征描述显著性,忽视了丰富的上下文语义信息。当背景相似或图像结构较为复杂时,算法的准确度往往不尽人意。
目前,基于深度学习的方法被广泛用于图像显著性目标检测。Lee[1]等人提出了一个由两个子网络组成的显著性检测网络模型,同时获取全局和局部信息。全卷积网络FCN[2]的出现,使得显著性检测看作是图像语义分割任务。Liu 在FCN 基础上提出了DHSnet 网络[3],通过反卷积算法恢复缩小后的显著图的细节信息。Wang 和Borji 等[4]提出具有两阶段的循环网络结构,先提取图像粗糙的显著图,再使用金字塔池化结构生成较为清晰的显著图。这些模型中存在大量的卷积和池化操作,导致生成显著图时丢失了很多细节。所以,目前大多数的显著性分割模型能够大致定位到显著物体的位置,但是边界比较模糊。
本文通过深度学习算法提取图像中的显著性目标区域,并利用基于GMM 模型的颜色特征提取目标空间信息,最后通过一个优化模型融合空间信息和语义信息得到最终的显著性目标图。实验结果表明,在复杂环境下本算法具有较高检测准确度,证明了算法的有效性和鲁棒性。
1 研究基础
传统卷积神经网络提取的抽象特征对图像中目标粗略位置的定位很有效,但很难做到像素级的分割,不能准确划定目标具体的轮廓。全卷积网络FCN 通过对图像进行像素到像素的分类检测,突破了传统卷积神经网络在像素级分割的局限性。具体做法是去掉用于分类的全连接层和softmax 层,把最后卷积得到的特征图利用反卷积算法进行上采样操作,使输出图像和输入图像具有相同的分辨率,然后在相同分辨率的特征图上计算每个像素分类的损失,达到对每个像素都能进行分类预测的目的,解决了图像分割中目标边界位置不清晰的问题。FCN 主要由卷积层、池化层和上采样层3 部分组成。
2 显著性目标检测模型
2.1 模型结构
本文借鉴FCN 思想,采用VGG[5]深度神经网络模型用于目标检测,借鉴Long 的方法,保留该网络的前7 层结构,只在最后两层加入反卷积算法,通过上采用恢复特征图的分辨率。这样可利用输入图像和人工标准的显著图像素之间一一对应的关系进行网络训练,利用深层神经网络提取的显著性目标特征进行目标检测和分割。
本文网络结构如图1 虚线框所示,把深度神经网络的全连接层改为卷积层,把用于分类的softmax层改为反卷积层。
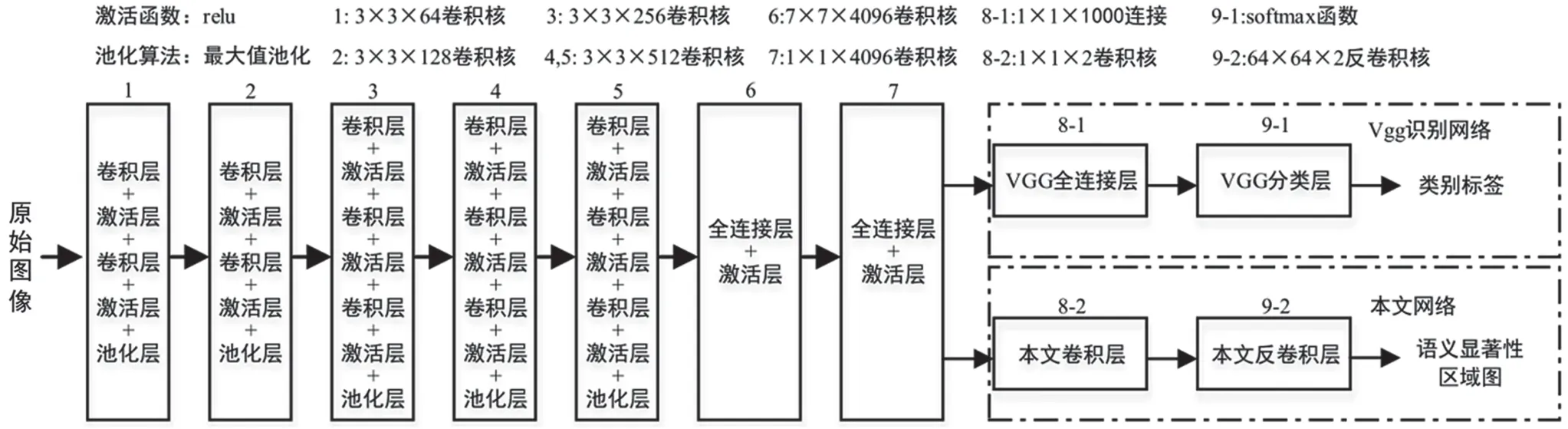
图1 基于VGG 的全卷积网络结构
本算法模型主要包括卷积、反卷积、池化和非线性激活等操作。其中,卷积运算用于特征提取;反卷积运算可以看成是上采样操作,本文采用双线性插值上采样;池化运算是取每个图像块中的最大值作为图像块的特征值,减少网络参数;非线性激活部分采用ReLU 函数,可以有效解决神经网络参数训练中的梯度消失问题。
2.2 模型训练
由于最后得出的特征图像和输入图像具有相同的分辨率,因此可以利用已有的人工标注数据集训练深度神经网络,利用随机梯度下降算法求解交叉熵损失函数的最小值,得到网络中各个卷积核的权重参数。根据实验经验,各种超参数设置如下:学习率为0.002,权重衰减系数为0.004,每组训练样本数为64。
网络参数的初始化对于网络训练的最终效果有很大影响。为了充分利用全卷积目标分割网络中已有的信息,本文网络中前7 阶段的参数用VGG 模型已经训练好的相应参数进行初始化,其他层用高斯分布的随机数进行初始化。
2.3 显著性信息优化融合
为了进一步解决显著性目标区域边界不准确、区域不完整的缺陷,引入空间信息进行优化。通常情况下,图像中前景和背景颜色不一致,且背景分布面积更大。基于这一知识将颜色分布特征定义为RGB 三通道的颜色方差之和,即利用颜色分布计算各个颜色所占的比重来检测显著性目标。本文采用高斯混合模型(Gaussian Mixture Model,GMM)建立图像中颜色信息模型,然后用条件概率计算出每个像素所包含的颜色所占比重如下:
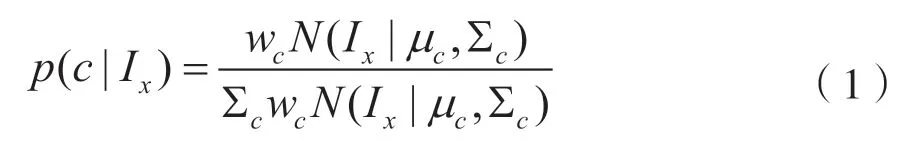
每一个颜色成分c空间位置的水平方差Vh(c)计算如下:
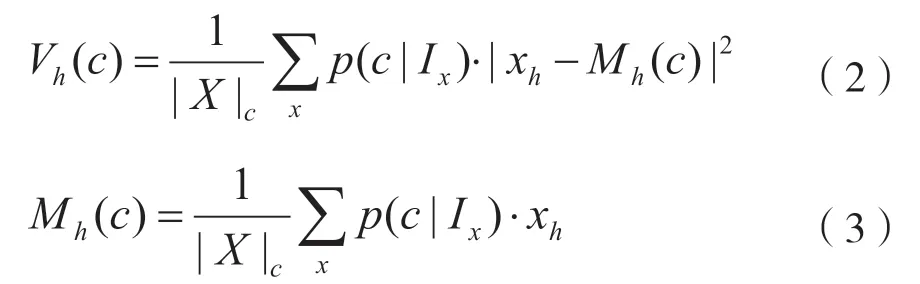
式中,xh是x像素的横坐标,且|X|C=∑xp(c|Ix)。颜色的垂直方差计算和水平方差类似。最后,第c个颜色空间方差为颜色成分的水平方差和垂直方差之和。图像中的所有颜色利用高斯混合模型计算出每一个像素的颜色所占的不同比重,颜色所占比重越小,说明其越有可能属于显著性区域的颜色。
为获得更准确的显著性区域图,将两种显著性信息进行融合,提出了一个新的无约束优化模型,有效融合之前获得的语义显著性信息和基于颜色的空间一致信息。将两种显著性信息融合建模为一个目标函数最小化问题,目标函数的定义为:
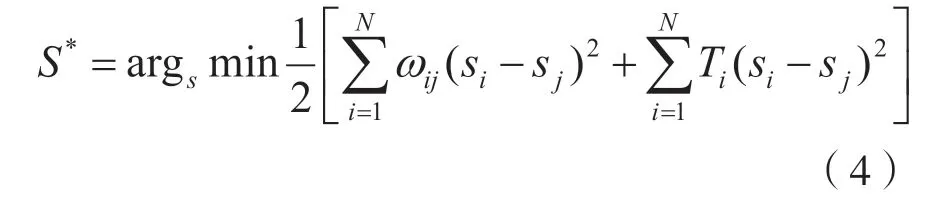
式中,表示图像中包含的像素个数,S*为优化模型为每个像素分配的显著性值。第一项包含空间信息,i、j为在空间上相邻的两个像素,ωij表示像素i、j的颜色相似性,利用相邻像素颜色值的颜色空间方差表示。空间一致约束项促使颜色相似的相邻像素获得相近的显著度值。第二项包含语义显著性信息,像素i的语义显著性值由像素的语义信息值表示。Ti表示选择像素的指示值,其值根据像素显著性值和预设的阈值之间的大小关系而定,值为1 或者0。该阈值是一个超参数,用经验值0.8代替。
3 实验结果与分析
为验证算法的有效性,实验选择了在4 个常用的显著性检测基准数据集ECSSD(1 000 张图像)、HKU-IS(4 447 张图像)、PASCAL-S(850 张图像)、DUT-TE(5 019 张图像)上做对比实验。目前,常见的评测指标为Max-F 和MAE。其中,max-F 通过设定准确率和召回率之间的比例可以进行综合计算评测,而MAE 为平均绝对误差,可以进行更加全面的比较。
表1 列出了本文显著性模型和6 种行业领先水平的方法在4个公开数据集上评测指标的对比结果,包括DHSNet、MSRNet、NLDF、RFCN 和UCF 这5种基于深度学习的检测算法和DRFI 这1 种传统检测算法。为了保持客观,其他算法的实验结果由作者提供的代码计算获得。
从仿真结果可见,基于深度学习的方法普遍优于传统显著性物体检测方法,而本文算法的Max-F指标和MAE 指标除了背景环境复杂且具有多目标特征的PASCAL-S 数据集外,在其他数据集测试中都位于前列。实验结果充分说明,在公开的数据集上,本算法具有较高检测准确度,证明了算法的有效性和鲁棒性。

表1 本文算法和其他6 种算法在4 种数据集评测指标对比结果
4 结语
本文提出的显著性目标检测算法通过改进深度神经网络VGG,建立了像素到像素级的显著性目标检测模型,可准确标注出图像中的显著性目标位置,并利用基于GMM 的颜色模型提取目标空间信息,最后通过一个优化模型融合空间颜色信息和深度学习显著性信息得到最终的显著性目标图。在公开数据集上和其他算法的对比的实验结果表明,本文算法能够实现准确度较高的显著目标检测结果,体现了算法的优越性。
